

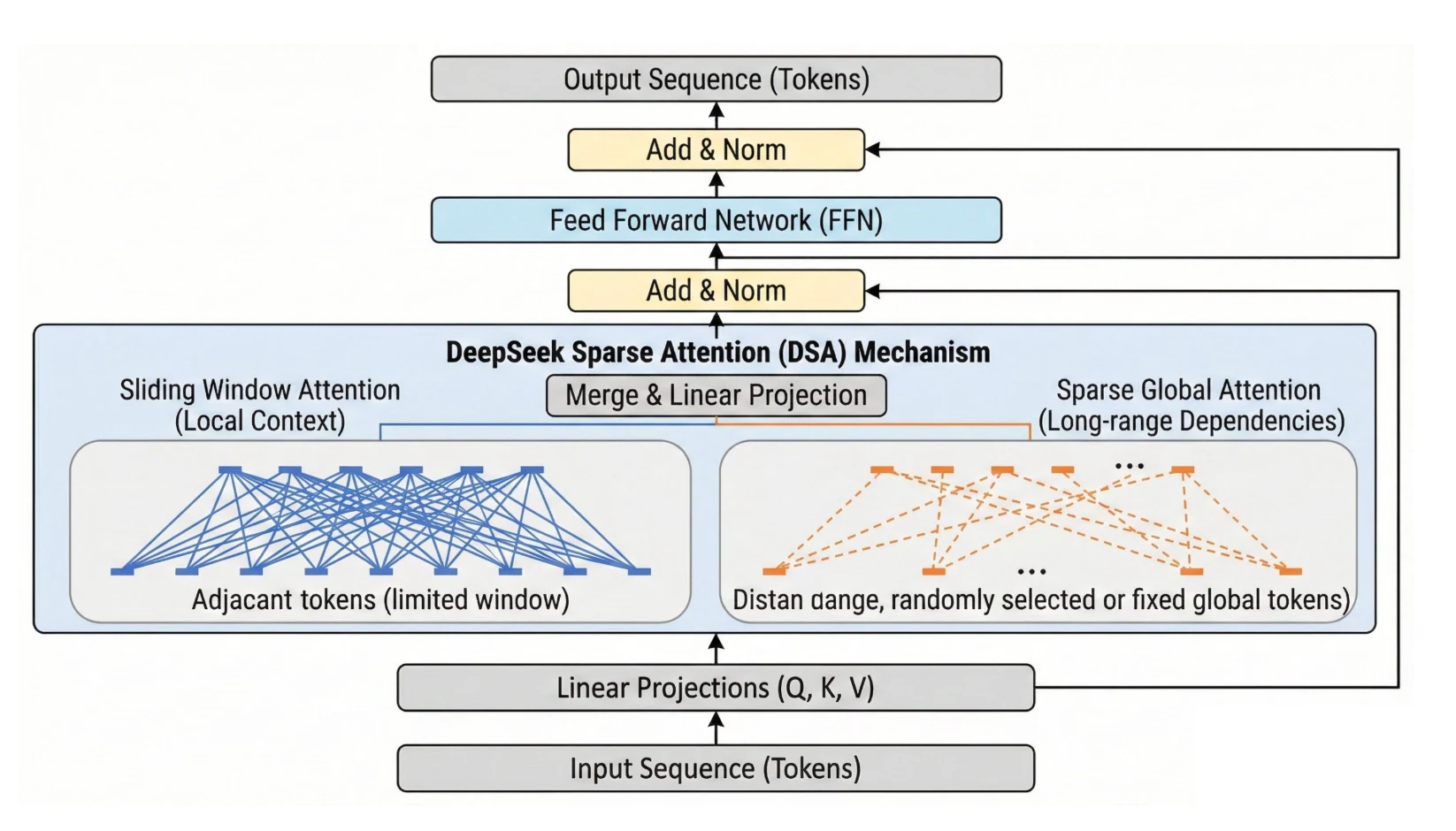
- أبرز ميزات بنية Deepseek V3.2
- تأثير ذاكرة الوصول العشوائي للرسوميات (VRAM) لـ DSA الخاص بـ DeepSeek V 3.2
- متطلبات ذاكرة الوصول العشوائي للرسوميات (VRAM) والأجهزة لـ DeepSeek V3.2
- كم تكلفة نشر DeepSeek V3.2 محليًا؟
- مقارنة التكاليف: وحدات معالجة الرسوميات (GPU) المحلية مقابل وحدات معالجة الرسوميات (GPU) السحابية لـ DeepSeek V3.2
- طريقة أفضل وأقل تكلفة لتشغيل DeepSeek V3.2 على وحدات معالجة الرسوميات (GPU) السحابية
- كيفية نشر DeepSeek V3.2 على Novita AI
تقوم Novita AI بإطلاق حملة “Build Month” الخاصة بها، وتقدم للمطورين حافزًا حصريًا يصل إلى خصم 20% على جميع المنتجات الرئيسية!
مع انتقال نماذج الاستدلال الكبيرة والنماذج العاملة بالوكلاء من مرحلة البحث إلى النشر في التطبيقات الواقعية، يواجه المطورون توترًا حاسمًا بين القدرة والتكلفة. يعد DeepSeek V3.2 مثالًا بارزًا على هذا التحدي: فبينما يوفر إنتاجية عالية للسياقات الطويلة، وموثوقية عالية لاستخدام الأدوات متعددة الخطوات، واستقرارًا محسنًا للتعلم المعزز، فإنه يقدم أيضًا متطلبات كبيرة للأجهزة وذاكرة الوصول العشوائي للرسوميات (VRAM)، خاصة في حالات النشر بدقة كاملة.
يتناول هذا المقال هذه الأسئلة من خلال فحص بنية DeepSeek V3.2، ومتطلبات ذاكرة الوصول العشوائي للرسوميات (VRAM) والأجهزة، وهيكل تكاليف النشر المحلي، والبدائل منخفضة التكلفة التي توفرها عروض وحدات معالجة الرسوميات (GPU) المرنة من Novita AI.
أبرز ميزات بنية Deepseek V3.2
يمكن فهم DeepSeek V3.2 على أنه ترقية “أولوية النشر” مقارنة بـ V3/R1: فهو يستهدف إنتاجية عملية للسياقات الطويلة، واستخدام أدوات عاملة بالوكلاء مع استدلال مستمر، ومكدس تعلم معزز (RL) أكثر مرونة يخلط بين المكافآت القابلة للتحقق والمكافآت المعتمدة على المعايير للمهام غير القابلة للتحقق، وهو ما يهم مباشرة مستخدمي واجهة برمجة التطبيقات (API) الذين يهتمون بالكمون، وضغط السياق، والموثوقية متعددة الخطوات.
| الطبقة | ما يضيفه V3.2 | ما يغيره لمستخدمي واجهة برمجة التطبيقات (API) |
|---|---|---|
| السياق الطويل (DSA) | انتباه DeepSeek المتناثر (DSA) مع مفهرس سريع + محدد الرموز (top-k). يقلل الانتباه المتناثر من حجم الانتباه. | تصبح الأوامر الطويلة اقتصادية من الناحية العملية: تكلفة هامشية أقل لكل موضع رمز إضافي في السياقات الطويلة، سرعة محسنة من البداية إلى النهاية في سيناريوهات السياقات الطويلة، عدد أقل من عمليات النشر “التي يجب تقسيمها إلى أجزاء”. |
| قدرات الوكيل | “التفكير في استخدام الأدوات” بالإضافة إلى إدارة السياق التي تحتفظ بمسارات الاستدلال عبر مخرجات الأدوات، وتوليف بيانات الوكيل على نطاق واسع (ملاحظات الإصدار الرسمية: أكثر من 1800 بيئة، أكثر من 85 ألف تعليم معقد). | معدلات نجاح أعلى في سير العمل متعدد الأدوات. تقليل الفشل الناتج عن إعادة اشتقاق الحالة في كل استدعاء أداة، ولكن أيضًا خطر أعلى لفيضان السياق إذا لم يتم إدارته. |
| RLVR + مكافآت متعددة | يستخدم التعلم المعزز المختلط (RL) مكافأة نتيجة قائمة على القواعد + عقوبة الطول + اتساق اللغة لمهام الاستدلال/الوكيل؛ نموذج مكافأة توليدي مع معايير لكل أمر للمهام العامة. تم استقرار GRPO مع تقدير KL غير متحيز، قناع التسلسل خارج السياسة، الحفاظ على التوجيه (MoE)، الحفاظ على قناع أخذ العينات (top-p/top-k). | محاذاة أكثر قوة للمهام المفتوحة بدون مدققات رمزية؛ استقرار أفضل للتعلم المعزز (RL) على نطاق واسع؛ قابلية تحكم أكبر في طول النص عبر عقوبات الطول. |
تأثير ذاكرة الوصول العشوائي للرسوميات (VRAM) لـ DSA الخاص بـ DeepSeek V 3.2
انتباه DeepSeek المتناثر (DSA) يقلل من تكلفة الحساب والذاكرة لطبقات الانتباه في السياقات الطويلة عن طريق تقليم الانتباه ليشمل فقط الرموز الأكثر صلة، مما يقلل بشكل عام من عدد العمليات الحسابية (FLOPs) وضغط ذاكرة الوصول العشوائي للرسوميات (VRAM) مقارنة بالانتباه الكثيف عند عدد كبير من الرموز. تعكس تخفيضات أسعار واجهة برمجة التطبيقات (API) التي تزيد عن 50% هذه المكاسب في الكفاءة في الممارسة العملية.
- يقلل DSA من تكلفة الحساب والذاكرة للسياقات الطويلة بنسبة تزيد عن 50% تقريبًا مقارنة بالانتباه الكثيف في سيناريوهات التسلسلات الطويلة، مع تدهور جودة ضئيل يمكن تجاهله.
- لا يغير هذا التخفيض العدد الإجمالي للمعلمات في النموذج (≈ 685 مليار) ولكنه يقلل من البصمة الذاكرية في وقت التشغيل للنوافذ الطويلة، خاصة استخدام ذاكرة التخزين المؤقت للمفاتيح والقيم (KV) ومساحة عمل الانتباه لكل رمز.
| طول السياق | الانتباه الكثيف (الاتجاه الأساسي) | تأثير DSA (انتباه DeepSeek المتناثر) (تقريبي) |
|---|---|---|
| 8 آلاف رمز | ذاكرة وحساب أساسيان | ذاكرة مشابهة أو أقل قليلاً — حمل إضافي ضئيل للتفرع عند الأطوال القصيرة |
| 32 ألف رمز | الزيادة التربيعية تصبح كبيرة | استخدام ذاكرة أقل بنسبة 30-40% مقارنة بالانتباه الكثيف عند أطوال سياق مماثلة (الاستدلال) |
| 128 ألف رمز | تصبح التكلفة والذاكرة مرتفعة جدًا | استخدام ذاكرة وتكلفة أقل بنسبة 60-70%، مع تخفيض تكلفة الاستدلال بأكثر من 60% وتخفيض استخدام الذاكرة بنسبة 70% تقريبًا مع DSA |
من Amitray
متطلبات ذاكرة الوصول العشوائي للرسوميات (VRAM) والأجهزة لـ DeepSeek V3.2
الدقة الكاملة (FP16/BF16)
في ظل نشر الدقة الكاملة القياسية (FP16/BF16)، يفرض الاستدلال باستخدام DeepSeek-V3.2 متطلبات أجهزة مرتفعة للغاية، حيث يتجاوز إجمالي ذاكرة وحدات معالجة الرسوميات (GPU) المطلوبة لأوزان النموذج والتنفيذ في وقت التشغيل حوالي 1 تيرابايت. في سيناريوهات BF16/FP16، تتضمن التكوينات المتبعة عادةً 8 إلى 16 وحدة معالجة رسوميات (GPU) من فئة H100 أو A100 بسعة ذاكرة وصول عشوائي للرسوميات (VRAM) تبلغ 80 جيجابايت لكل منها، ليصل إجمالي سعة ذاكرة وحدات معالجة الرسوميات (GPU) إلى ما يقرب من 1.3 تيرابايت.
مفاضلات التكميم وإلغاء التحميل
| مستوى التكميم | البصمة الذاكرية التقريبية |
|---|---|
| FP16 / BF16 | إجمالي 1.3 تيرابايت |
| 8 بت (w8a8) | إجمالي 670 جيجابايت |
| 4 بت | إجمالي 335 جيجابايت |
كم تكلفة نشر DeepSeek V3.2 محليًا؟
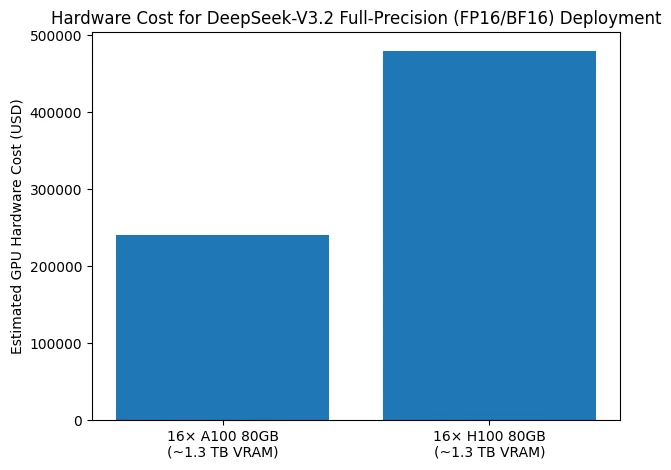
يوضح الرسم البياني بالأعمدة تكلفة الأجهزة المطلوبة لنشر DeepSeek-V3.2 في إعدادات الدقة الكاملة (FP16/BF16). لتلبية متطلب ذاكرة وحدات معالجة الرسوميات (GPU) البالغ 1.3 تيرابايت تقريبًا، تعتمد التكوينات النموذجية على 16 وحدة معالجة رسوميات (GPU) بسعة ذاكرة وصول عشوائي للرسوميات (VRAM) تبلغ 80 جيجابايت لكل منها. عند استخدام وحدات معالجة الرسوميات (GPU) A100 بسعة 80 جيجابايت، تبلغ تكلفة وحدات المعالجة الرسومية فقط حوالي 240 ألف دولار أمريكي، بينما تزيد التكوين المكافئ القائم على وحدات معالجة الرسوميات (GPU) H100 بسعة 80 جيجابايت التكلفة إلى roughly 480 ألف دولار أمريكي.
تسلط هذه المقارنة الضوء على أن DeepSeek-V3.2 حتى قبل حساب الخوادم، والوصلات عالية السرعة، والطاقة، وبنية التبريد، يفرض الاستدلال بدقة كاملة بالفعل مئات الآلاف من الدولارات الأمريكية في استثمارات وحدات معالجة الرسوميات (GPU) وحدها. لذلك يبرز الرقم الحاجز المرتفع بشكل استثنائي لتكاليف الأجهزة لنشر DeepSeek-V3.2 في وضع FP16/BF16، مما يفسر لماذا تقتصر عمليات النشر هذه إلى حد كبير على مراكز البيانات واسعة النطاق ولماذا تعتبر استراتيجيات التكميم وإلغاء التحميل ضرورية في الممارسة العملية.
مقارنة التكاليف: وحدات معالجة الرسوميات (GPU) المحلية مقابل وحدات معالجة الرسوميات (GPU) السحابية لـ DeepSeek V3.2
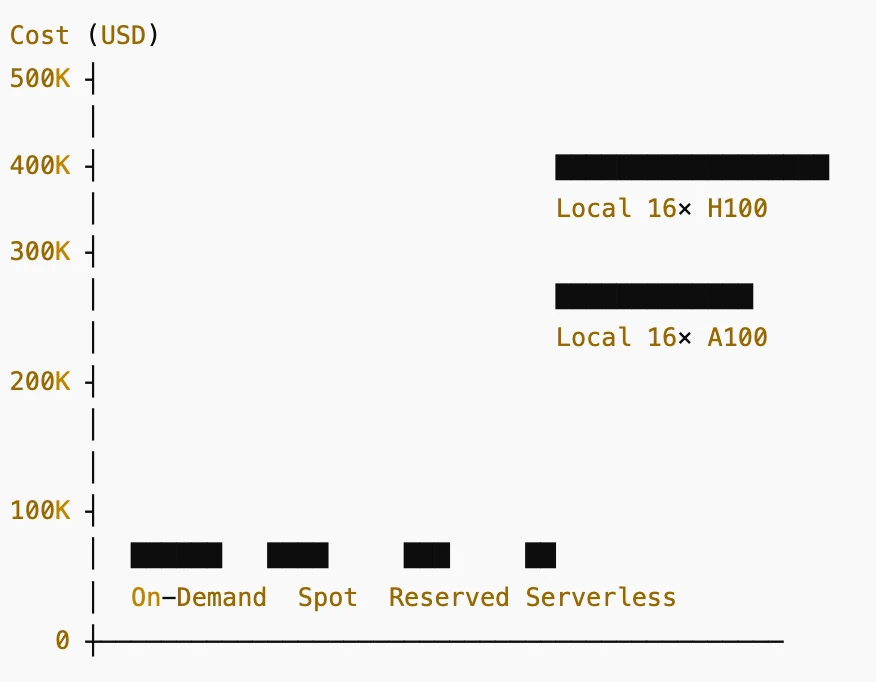
الأعمدة (من اليسار إلى اليمين):
- عند الطلب (On-Demand): ~26 ألف دولار أمريكي سنويًا
- الحالات الفورية (Spot Instances): ~13 ألف دولار أمريكي سنويًا
- مخططة/مشتركة (Reserved / Subscription): ~8 آلاف دولار أمريكي سنويًا
- فوترة وحدات معالجة الرسوميات (GPU) بدون خادم (Serverless GPU Billing): ~5 آلاف دولار أمريكي سنويًا
- محلي 16 × A100 80 جيجابايت: ~240 ألف دولار أمريكي تكلفة أجهزة
- محلي 16 × H100 80 جيجابايت: ~480 ألف دولار أمريكي تكلفة أجهزة
طريقة أفضل وأقل تكلفة لتشغيل DeepSeek V3.2 على وحدات معالجة الرسوميات (GPU) السحابية
توفر Novita AI أربعة نماذج فوترة لوحدات معالجة الرسوميات (GPU) لاستيعاب أنماط أحمال العمل المختلفة ومتطلبات التكلفة.
نموذج التسعير طريقة الفوترة توفر الموارد مستوى التكلفة خطر الانقطاع حالات الاستخدام النموذجية عند الطلب (Pay-as-you-go) تُفوتر حسب وقت التشغيل الفعلي (في الثانية أو الساعة) مرتفع، يمكن بدء الحالات أو إيقافها في أي وقت متوسط لا يوجد التطوير والاختبار، تصحيح أخطاء النموذج، أحمال عمل متغيرة أو غير متوقعة الحالات الفورية (Spot Instances) تُفوتر حسب وقت التشغيل بأسعار مخفضة متوسط، يعتمد على السعة الخاملة المتاحة منخفض (غالبًا حتى ~50% أرخص من عند الطلب) نعم، قد يتم استباق الحالات وظائف الدفعات، الاستدلال غير المتصل، تدريب متحمل للأعطال، أحمال عمل حساسة للتكلفة الخطط المشتركة/المحجوزة (Subscription / Reserved Plans) فوترة شهرية أو سنوية ثابتة مرتفع، موارد مخصصة وقابلة للتنبؤ متوسط-منخفض (مخفض مقارنة بعند الطلب) لا يوجد أحمال عمل مستقرة طويلة الأمد، أنظمة الإنتاج، تدريب أو استدلال مستمر فوترة وحدات معالجة الرسوميات (GPU) بدون خادم (Serverless GPU Billing) تُفوتر حسب الحساب الفعلي المستهلك في كل تنفيذ تتكيف تلقائيًا مع الطلب منخفض-متوسط (ادفع فقط مقابل ما تستخدمه) لا يوجد (تُدار بالكامل من قبل المنصة) استدلال مدفوع بالأحداث، حركة مرور متفجرة، تقديم نموذج قائم على واجهة برمجة التطبيقات (API)، حد أدنى من النفقات العامة للعمليات
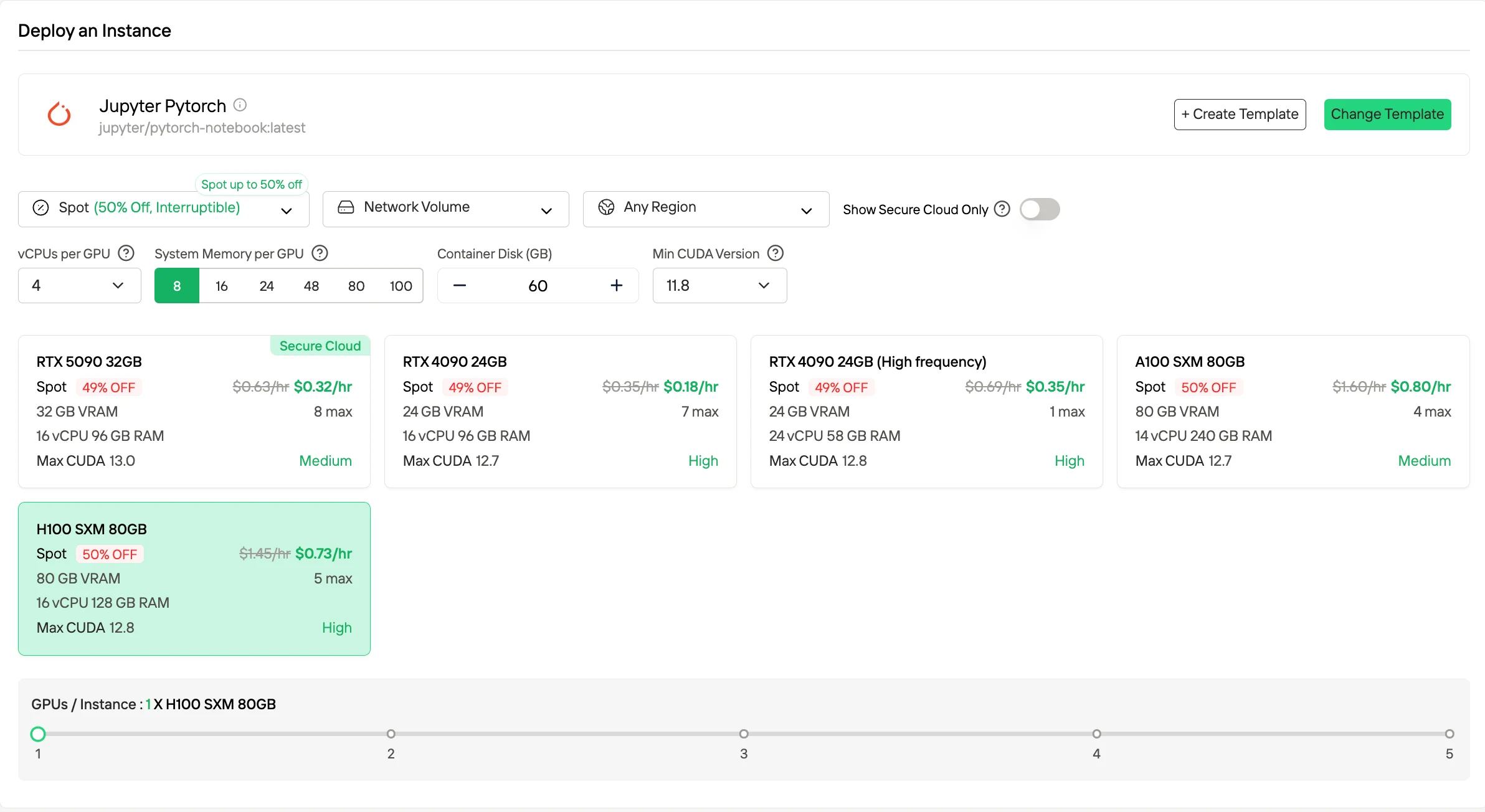
1. عند الطلب (Pay-as-you-go)
عند الطلب هو نموذج الاستهلاك القياسي الذي تُفوتر فيه حسابات وحدات معالجة الرسوميات (GPU) بشكل صارم حسب وقت التشغيل، عادةً في الثانية أو الساعة، دون التزامات أو حجوزات طويلة الأجل. يوفر أقصى درجات المرونة وهو مناسب جدًا لأحمال العمل المتغيرة، والاستخدام المتقطع، والتجارب في المراحل المبكرة، حيث يتم تحميل التكاليف فقط أثناء نشاط الحالة. تُفوتر الموارد التخزينية والمساعدة، بما في ذلك الأقراص والشبكات، على أساس الاستخدام.
جرب وحدات معالجة الرسوميات (GPU) السريعة والرخيصة الآن!
2. الحالات الفورية (Spot Instances)
تقدم الحالات الفورية أسعارًا بالساعة مخفضة بشكل كبير، غالبًا حتى 50% أقل من أسعار عند الطلب، من خلال استخدام سعة وحدات معالجة الرسوميات (GPU) الخاملة. قد يتم استباق هذه الحالات من قبل المنصة. تخفف Novita من هذا الخطر من خلال توفير نافذة حماية مدتها ساعة واحدة وإشعارات إنهاء مسبقة. يعد وضع التسعير هذا مناسبًا لأحمال العمل المتحملة للأعطال أو الدفعات التي يمكنها استيعاب الانقطاعات العرضية.
جرب وحدات معالجة الرسوميات (GPU) السريعة والرخيصة الآن!
3. الخطط المشتركة/المحجوزة (Subscription / Reserved Plans)
تتوفر الخطط المشتركة والمحجوزة بموجب شروط شهرية أو سنوية وتوفر موارد وحدات معالجة رسوميات (GPU) مخصصة مع توفر قابل للتنبؤ. مقارنة بتسعير عند الطلب، توفر هذه الخطط عادةً تكاليف وحدة فعالة أقل مقابل التزام طويل الأجل. وهي الأنسب لأحمال العمل المستقرة والمستمرة وبيئات الإنتاج التي تتطلب سعة حسابية متسقة.
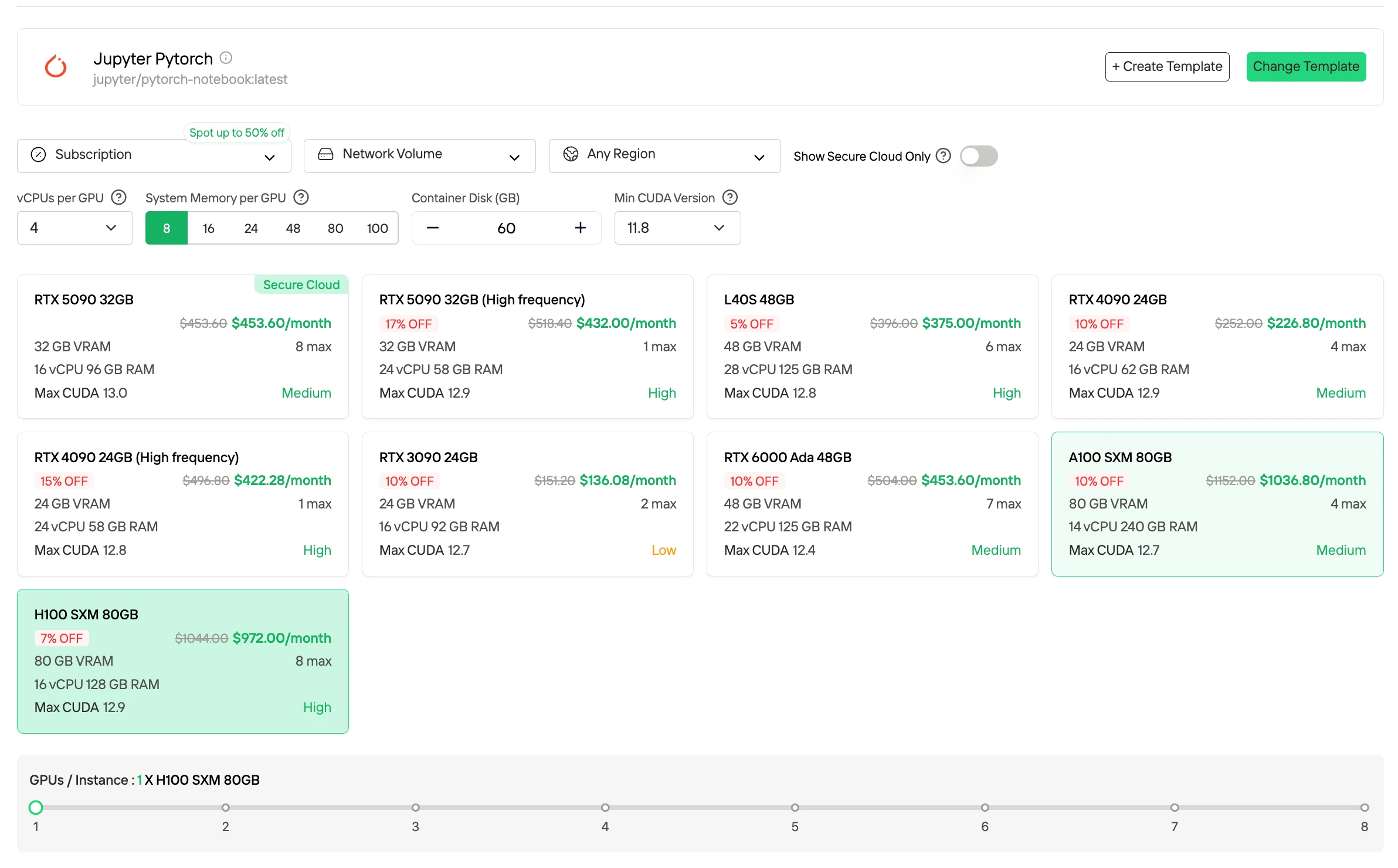
جرب وحدات معالجة الرسوميات (GPU) السريعة والرخيصة الآن!
4. فوترة وحدات معالجة الرسوميات (GPU) بدون خادم (Serverless GPU Billing)
تخفي فوترة وحدات معالجة الرسوميات (GPU) بدون خادم إدارة الحالات عن طريق تكييف موارد وحدات معالجة الرسوميات (GPU) تلقائيًا استجابةً لطلب أحمال العمل. يتم تحميل المستخدمين رسومًا فقط مقابل موارد الحساب التي يستهلكونها فعليًا بدلاً من الحالات الموفرة. يعد هذا النموذج مفيدًا لأحمال العمل المدفوعة بالأحداث أو ذات المرونة العالية جدًا، حيث يقلل من النفقات العامة للعمليات مع تحسين الكفاءة التكلفية.
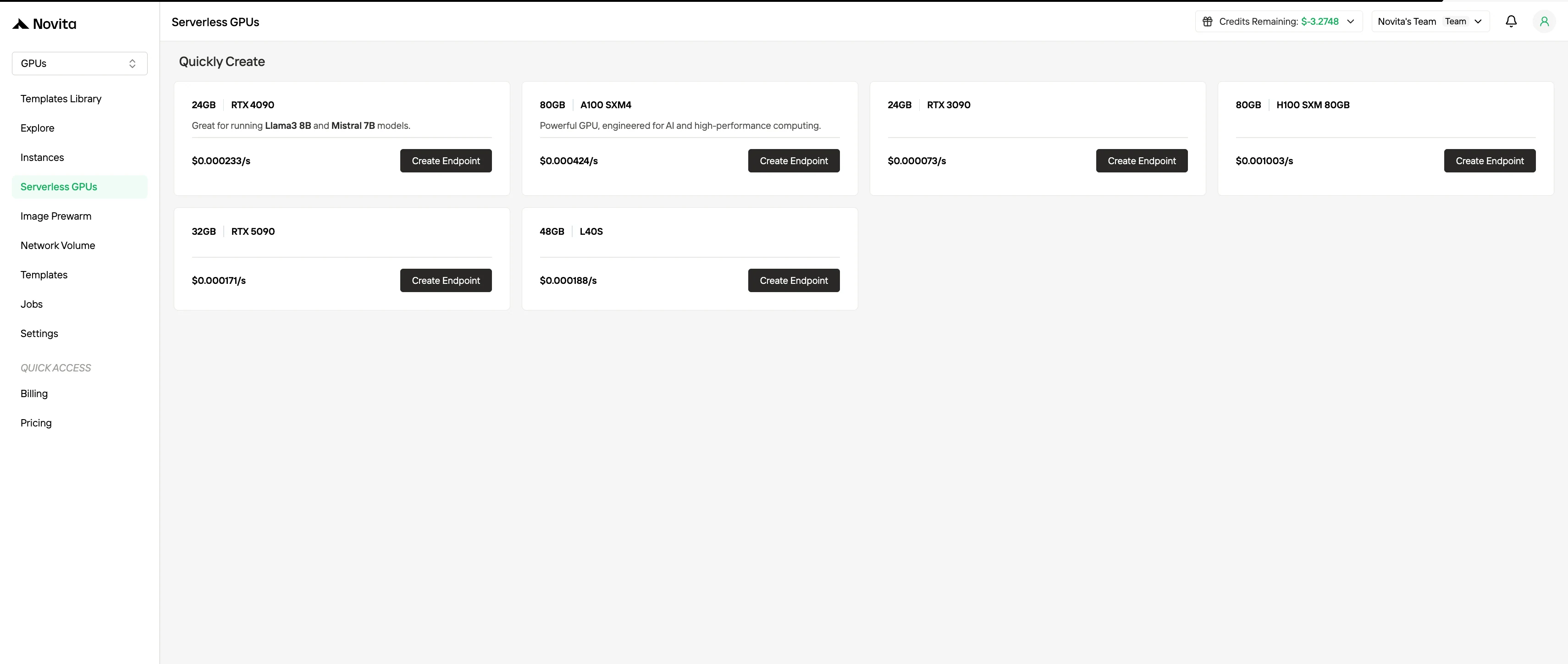
جرب وحدات معالجة الرسوميات (GPU) السريعة والرخيصة الآن!
تقدم Novita AI أيضًا قوالب، المصممة لتقليل بشكل كبير النفقات العامة التشغيلية والمعرفية المرتبطة بنشر أحمال عمل الذكاء الاصطناعي القائمة على وحدات معالجة الرسوميات (GPU). بدلاً من مطالبة المطورين بتجميع البيئات يدويًا من الصفر، يوفر نظام القوالب صورًا مهيأة مسبقًا وجاهزة للإنتاج تحتوي على نظام التشغيل، وإصدارات CUDA و cuDNN، وأطر التعلم العميق، ومحركات الاستدلال، وفي بعض الحالات حتى مكدسات تقديم النموذج السلكية بالكامل.
كيفية نشر DeepSeek V3.2 على Novita AI
الخطوة 1:تسجيل حساب
أنشئ حساب Novita AI الخاص بك من خلال موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “استكشاف” في الشريط الجانبي الأيسر لعرض عروض وحدات معالجة الرسوميات (GPU) الخاصة بنا وابدأ رحلة تطوير الذكاء الاصطناعي الخاصة بك.

الخطوة 2:استكشاف القوالب وخوادم وحدات معالجة الرسوميات (GPU)
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم اختر تكوين وحدات معالجة الرسوميات (GPU) المفضل لديك – تشمل الخيارات وحدات L40S القوية، أو RTX 4090 أو A100 SXM4، لكل منها مواصفات مختلفة لذاكرة الوصول العشوائي للرسوميات (VRAM)، والذاكرة العشوائية (RAM)، والتخزين.
الخطوة 3:تخصيص النشر وإطلاق حالة
خصص بيئتك عن طريق اختيار نظام التشغيل وخيارات التكوين المفضلة لديك لضمان الأداء الأمثل لأحمال عمل الذكاء الاصطناعي واحتياجات التطوير الخاصة بك. وبعد ذلك ستكون بيئة وحدات معالجة الرسوميات (GPU) عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي، أو العرض، أو الحساب الخاصة بك.
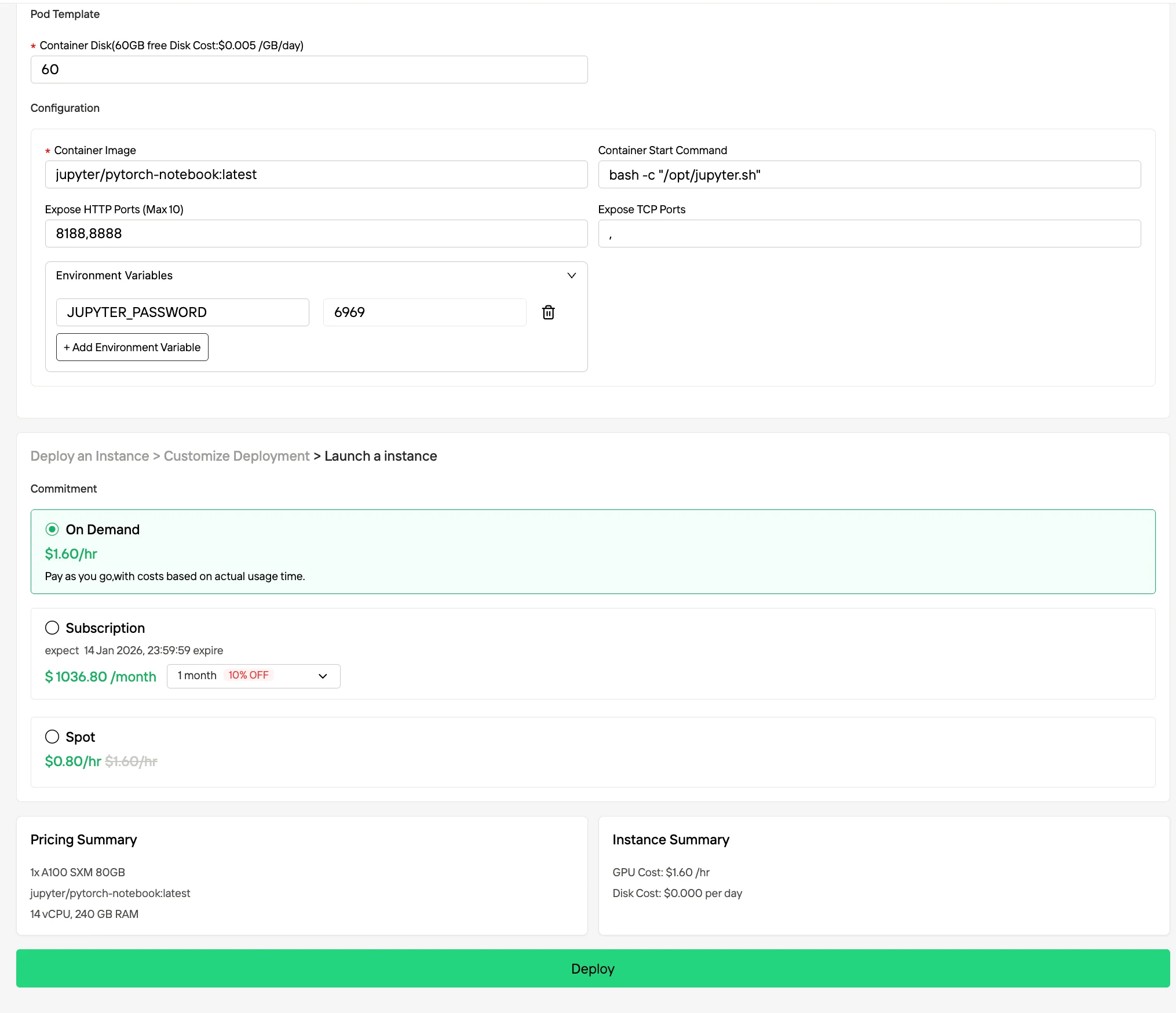
الخطوة 4: مراقبة تقدم النشر
انتقل إلى إدارة الحالات للوصول إلى وحدة التحكم. تسمح لك هذه اللوحة بتتبع حالة النشر في الوقت الفعلي.
جرب وحدات معالجة الرسوميات (GPU) السريعة والرخيصة الآن!
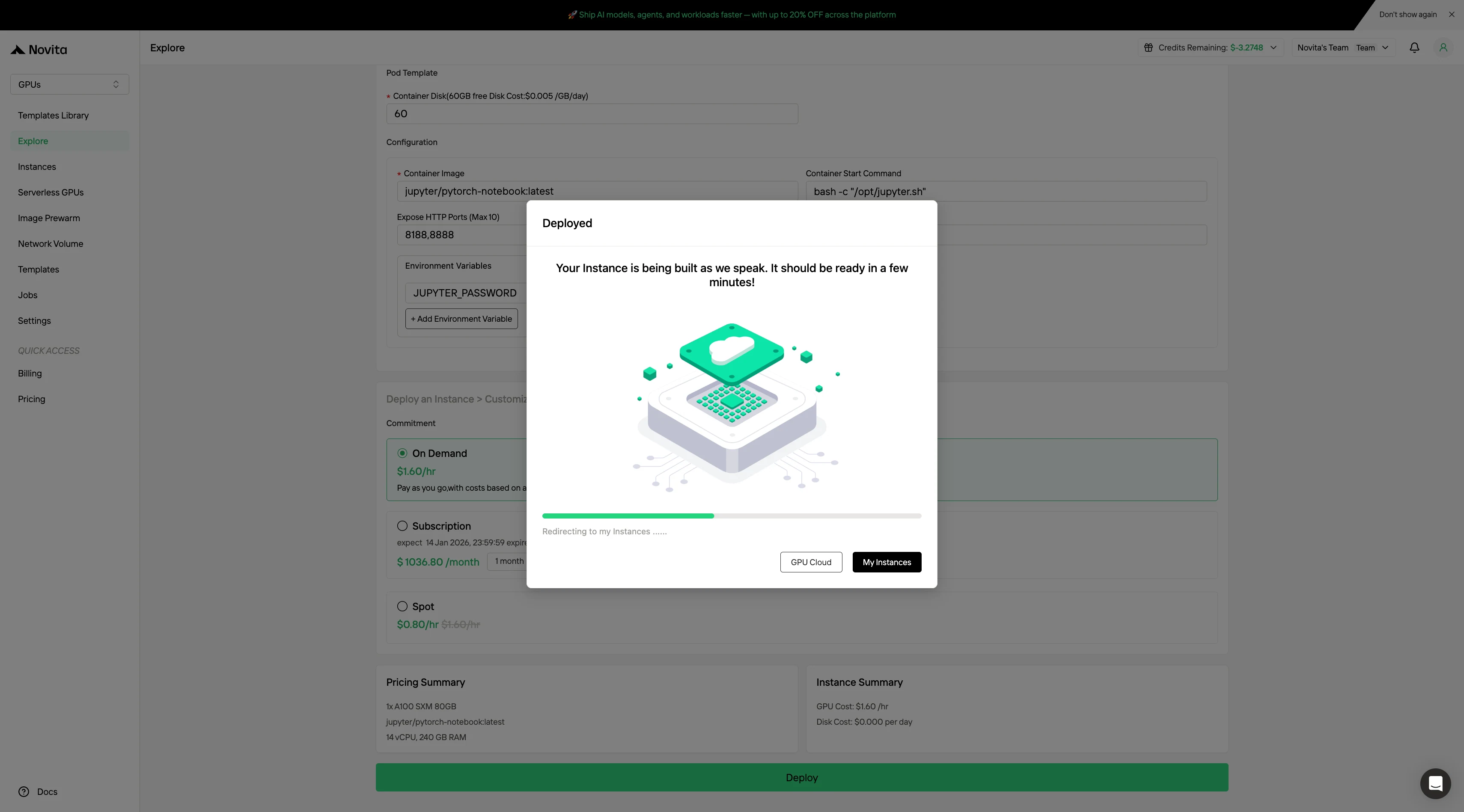
الخطوة 5: عرض حالة سحب الصورة
انقر على الحالة المحددة الخاصة بك لمراقبة تقدم تنزيل صورة الحاوية. قد تستغرق هذه العملية عدة دقائق اعتمادًا على ظروف الشبكة.
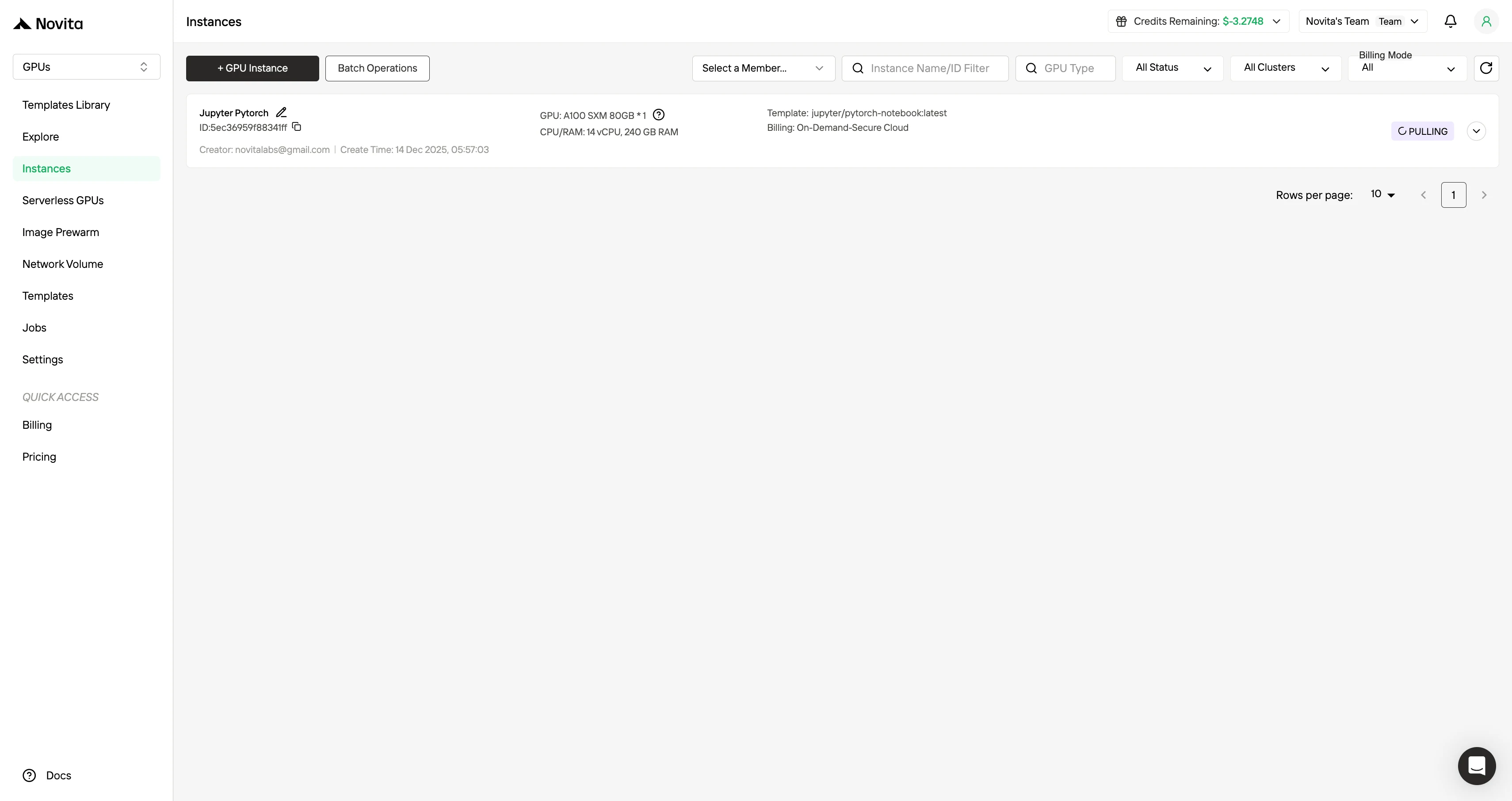
الخطوة 6: التحقق من النشر الناجح
بعد بدء الحالة، سيبدأ في سحب النموذج. انقر على “السجلات (Logs)” -> “سجلات الحالة (Instance Logs)” لمراقبة تقدم تنزيل النموذج. ابحث عن الرسالة
"Application startup complete."في سجلات الحالة. يشير هذا إلى أن عملية النشر قد اكتملت بنجاح.انقر على “اتصال (Connect)”، ثم انقر -> “الاتصال بخدمة HTTP [المنفذ 8000]”. بما أن هذه خدمة واجهة برمجة تطبيقات (API)، ستحتاج إلى نسخ العنوان.
لإرسال طلبات إلى نموذجك، يرجى استبدال “http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai" بعنوانك الفعلي المعروض. انسخ الكود التالي للوصول إلى نموذجك الخاص!
يمثل DeepSeek V3.2 تطورًا موجهًا للنشر لنماذج اللغة الكبيرة من نوع MoE، حيث يجمع بين الانتباه المتناثر، والاستدلال الواعي للوكلاء، والتعلم المعزز بمكافآت مختلطة لتحسين كفاءة السياقات الطويلة وموثوقية الأدوات المتعددة. ومع ذلك، في إعدادات FP16/BF16، يتطلب DeepSeek V3.2 ما يقرب من 1.3 تيرابايت من ذاكرة وحدات معالجة الرسوميات (GPU) المجمعة، مما يترجم إلى مئات الآلاف من الدولارات الأمريكية في تكاليف أجهزة وحدات معالجة الرسوميات (GPU) وحدها. يقلل التكميم وإلغاء التحميل بشكل كبير من ضغط الذاكرة ولكنهما يقدمان مفاضلات في التعقيد والأداء. على النقيض من ذلك، يوفر النشر السحابي على Novita AI مسارًا أكثر سهولة، من خلال الاستفادة من نماذج الفوترة المرنة، والقوالب المهيأة مسبقًا، والتوفير السريع لتخفيض الحواجز المالية والتشغيلية على حد سواء. معًا، توضح هذه الخيارات كيف يمكن نشر DeepSeek V3.2 بشكل استراتيجي بدلاً من أن يكون محظورًا بسبب التكلفة.
الأسئلة الشائعة
لماذا يتطلب DeepSeek V3.2 سعة ذاكرة وحدات معالجة الرسوميات (GPU) كبيرة جدًا في الدقة الكاملة؟
يتطلب DeepSeek V3.2 سعة ذاكرة وحدات معالجة رسوميات (GPU) كبيرة لأن معلماته البالغة ≈ 685 مليار، مجتمعة مع ذاكرات التخزين المؤقت للمفاتيح والقيم (KV) للسياقات الطويلة وأحواض التنفيذ في وقت التشغيل، تدفع عمليات النشر في وضع FP16/BF16 إلى ما يقرب من 1.3 تيرابايت من ذاكرة الوصول العشوائي للرسوميات (VRAM) المجمعة.
كيف يقلل DeepSeek V3.2 من تكاليف السياقات الطويلة مقارنة بالنماذج السابقة؟
يقدم DeepSeek V3.2 انتباه DeepSeek المتناثر (DSA)، الذي يقلم الانتباه ليشمل رموز top-k ذات الصلة، مما يقلل من حساب السياقات الطويلة واستخدام ذاكرة الوصول العشوائي للرسوميات (VRAM) بنسبة 50-70% مقارنة بالانتباه الكثيف عند أطوال سياق كبيرة.
ما هي الأجهزة المطلوبة عادة لتشغيل DeepSeek V3.2 في وضع FP16/BF16؟
يعتمد الاستدلال بدقة كاملة لـ DeepSeek V3.2 عادةً على 8 إلى 16 وحدة معالجة رسوميات (GPU) من فئة A100 أو H100 بسعة ذاكرة وصول عشوائي للرسوميات (VRAM) تبلغ 80 جيجابايت لكل منها، ليصل إجمالي سعة ذاكرة وحدات المعالجة الرسومية إلى ما يقرب من 1.3 تيرابايت.
Novita AI هي منصة سحابية شاملة تمكّنك من تحقيق طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات (API) متكاملة، بدون خادم، حالات وحدات معالجة رسوميات (GPU) — الأدوات منخفضة التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



