

- Destaques da arquitetura do Deepseek V3.2
- Impacto da DSA do DeepSeek V 3.2 na VRAM
- Requisitos de VRAM e hardware do DeepSeek V3.2
- Quanto custa a implantação local do DeepSeek V3.2?
- Comparação de custos: GPU local vs GPU na nuvem do DeepSeek V3.2
- Uma forma melhor e mais barata de usar o DeepSeek V3.2 em GPU na nuvem
- Como implantar o DeepSeek V3.2 na Novita AI
A Novita AI está lançando sua campanha “Mês de Construção”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
À medida que modelos de raciocínio em larga escala e agentes saem da pesquisa para a implantação no mundo real, os desenvolvedores enfrentam uma tensão crítica entre capacidade e custo. O DeepSeek V3.2 exemplifica esse desafio: embora ofereça alta taxa de transferência de contexto longo, confiabilidade no uso de ferramentas de múltiplas etapas e estabilidade aprimorada de aprendizado por reforço, ele também introduz demandas substanciais de hardware e VRAM, especialmente em implantações de precisão total.
Este artigo aborda essas questões examinando a arquitetura do DeepSeek V3.2, os requisitos de VRAM e hardware, a estrutura de custos de implantação local e alternativas econômicas habilitadas pelas ofertas flexíveis de GPU da Novita AI.
Destaques da arquitetura do Deepseek V3.2
O DeepSeek V3.2 é melhor entendido como uma atualização “priorizando implantação” em relação ao V3/R1: ele visa a taxa de transferência prática de contexto longo, uso de ferramentas agentes com raciocínio persistente e uma pilha de RL mais flexível que combina recompensas verificáveis com recompensas baseadas em rubricas para tarefas não verificáveis, o que importa diretamente para usuários de API que se preocupam com latência, pressão de contexto e confiabilidade de múltiplas etapas.
| Camada | O que o V3.2 adiciona | O que muda para usuários de API |
|---|---|---|
| Contexto longo (DSA) | Atenção esparsa do DeepSeek (DSA) com um indexador relâmpago + seletor de tokens (top-k). A atenção esparsa reduz a atenção. | Prompts longos se tornam economicamente viáveis: custo marginal menor por posição de token extra em contextos longos, velocidade de ponta a ponta aprimorada em cenários de contexto longo, menos implantações que “precisam dividir em blocos”. |
| Capacidade de agente | “Pensar no uso de ferramentas” além do gerenciamento de contexto que mantém traços de raciocínio entre saídas de ferramentas e síntese de dados agentes em larga escala (notas oficiais de lançamento: mais de 1.800 ambientes, mais de 85k instruções complexas). | Taxas de sucesso mais altas em fluxos de trabalho de múltiplas ferramentas. Redução de falhas por rederivação de estado a cada chamada de ferramenta, mas também maior risco de estouro de contexto se não for gerenciado. |
| RLVR + recompensa múltipla | O RL misto usa recompensa de resultado baseada em regras + penalidade de comprimento + consistência de linguagem para tarefas de raciocínio/agente; modelo de recompensa generativo com rubricas por prompt para tarefas gerais. O GRPO é estabilizado com estimativa de KL não tendenciosa, mascaramento de sequência fora da política, roteamento de manutenção (MoE), máscara de amostragem de manutenção (top-p/top-k). | Alinhamento mais robusto para tarefas abertas sem verificadores simbólicos; melhor estabilidade de RL em escala; verbosidade mais controlável por meio de penalidades de comprimento. |
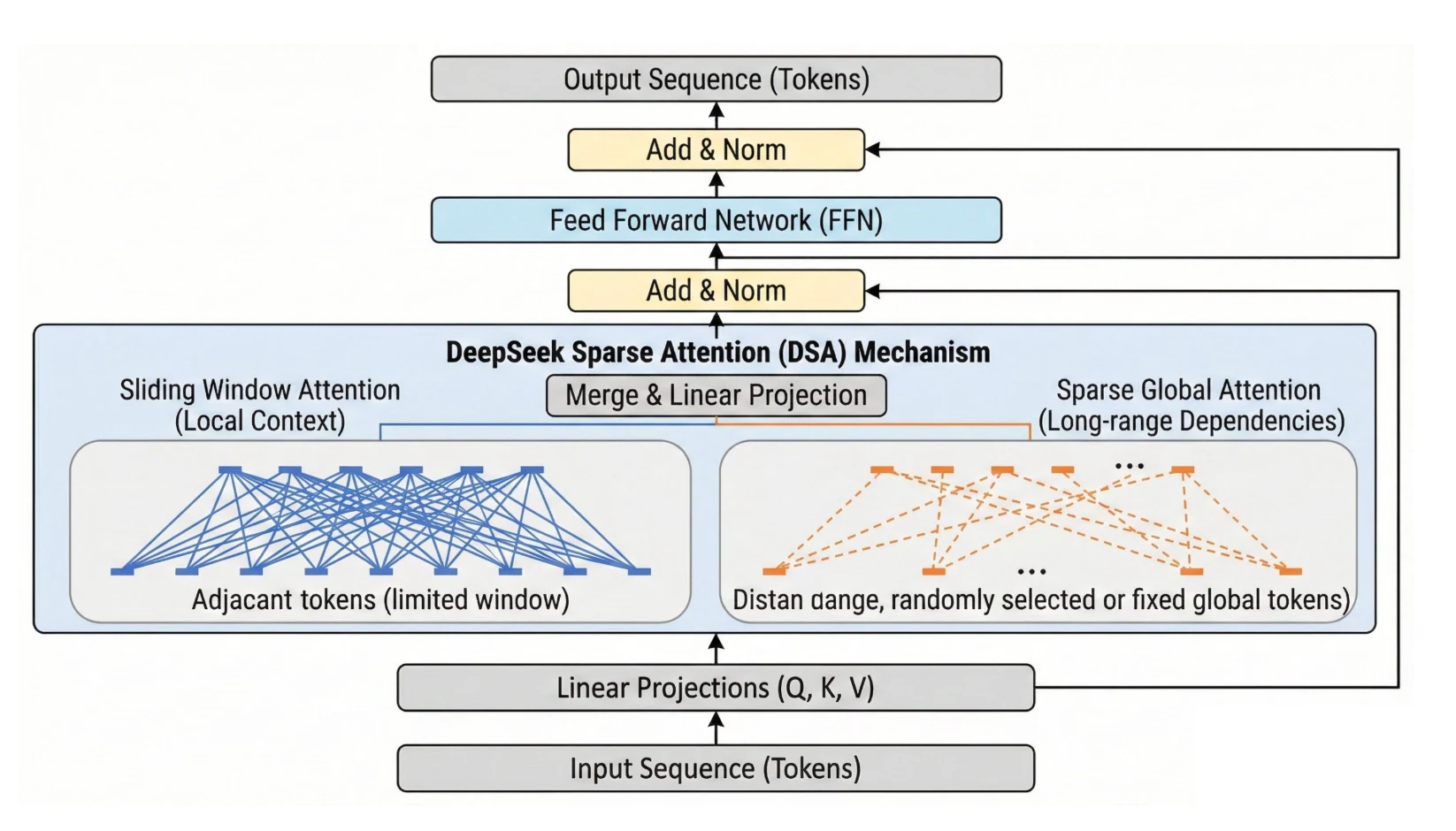
Impacto da DSA do DeepSeek V 3.2 na VRAM
A Atenção Esparsa do DeepSeek (DSA) reduz o custo de computação e memória das camadas de atenção para contextos longos, podando a atenção apenas para os tokens mais relevantes, reduzindo o FLOPs e a pressão na VRAM em comparação com a atenção densa em grandes contagens de tokens. Os cortes de preço de API de mais de 50% refletem esses ganhos de eficiência na prática.
- A DSA reduz o custo de computação e memória de contexto longo em cerca de 50%+ em comparação com a atenção densa em cenários de sequências longas, com degradação de qualidade insignificante.
- Essa redução não altera a contagem total de parâmetros do modelo (≈685B), mas diminui a pegada de memória em tempo de execução para janelas longas, especialmente o uso de KV por token e o espaço de trabalho de atenção.
| Comprimento do contexto | Atenção densa (tendência de base) | Efeito da DSA (Atenção Esparsa do DeepSeek) (aproximadamente) |
|---|---|---|
| 8K tokens | Memória e computação de base | memória similar ou modestamente menor — sobrecarga de esparsidade mínima em comprimentos curtos |
| 32K tokens | Aumento quadrático se torna grande | 30-40% de uso de memória menor vs. atenção densa em comprimentos de contexto semelhantes (inferência) |
| 128K tokens | Custo e memória se tornam muito altos | 60-70% de uso de memória e custo menor, com custo de inferência reduzido em mais de 60% e uso de memória reduzido em ~70% com DSA |
De Amitray
Requisitos de VRAM e hardware do DeepSeek V3.2
Precisão total (FP16/BF16)
Em implantações de precisão total padrão (FP16/BF16), a inferência com o DeepSeek-V3.2 impõe requisitos de hardware extremamente altos, pois a memória GPU combinada necessária para os pesos do modelo e execução em tempo de execução excede aproximadamente 1 TB. Para cenários BF16/FP16, as configurações comumente adotadas incluem 8 a 16 GPUs H100 ou A100 com 80 GB de VRAM cada, totalizando uma capacidade de memória GPU de quase 1,3 TB.
Compromissos de quantização e offload
| Nível de quantização | Pegada de memória aproximada |
|---|---|
| FP16 / BF16 | 1,3 TB no total |
| 8 bits (w8a8) | 670 GB no total |
| 4 bits | 335 GB no total |
Quanto custa a implantação local do DeepSeek V3.2?
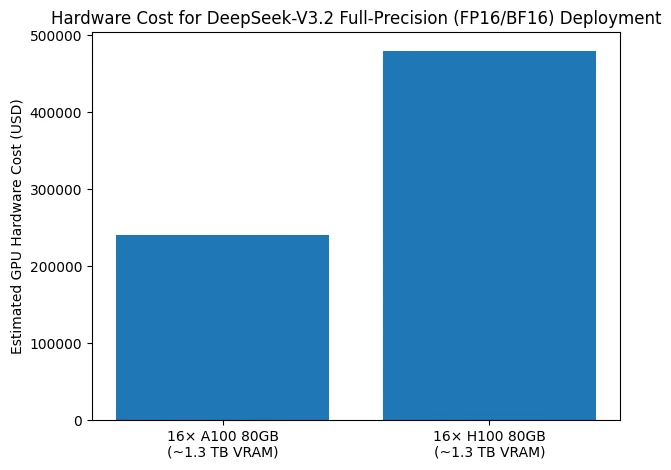
O gráfico de barras ilustra o custo de hardware necessário para implantar o DeepSeek-V3.2 em configurações de precisão total (FP16/BF16). Para atender ao requisito aproximado de 1,3 TB de memória GPU, uma configuração típica depende de 16 GPUs com 80 GB de VRAM cada. Ao usar GPUs A100 de 80 GB, o custo estimado apenas de GPUs é de cerca de USD 240.000, enquanto uma configuração equivalente baseada em GPUs H100 de 80 GB aumenta o custo para aproximadamente USD 480.000.
Essa comparação destaca que, mesmo antes de considerar servidores, interconexões de alta velocidade, energia e infraestrutura de resfriamento, a inferência de precisão total do DeepSeek-V3.2 já envolve centenas de milhares de dólares em investimento apenas em GPUs. A figura, portanto, ressalta a barreira de custo de hardware excepcionalmente alta da implantação do DeepSeek-V3.2 em FP16/BF16, o que explica por que essas implantações são amplamente confinadas a data centers em larga escala e por que estratégias de quantização e offloading são frequentemente consideradas essenciais na prática.
Comparação de custos: GPU local vs GPU na nuvem do DeepSeek V3.2
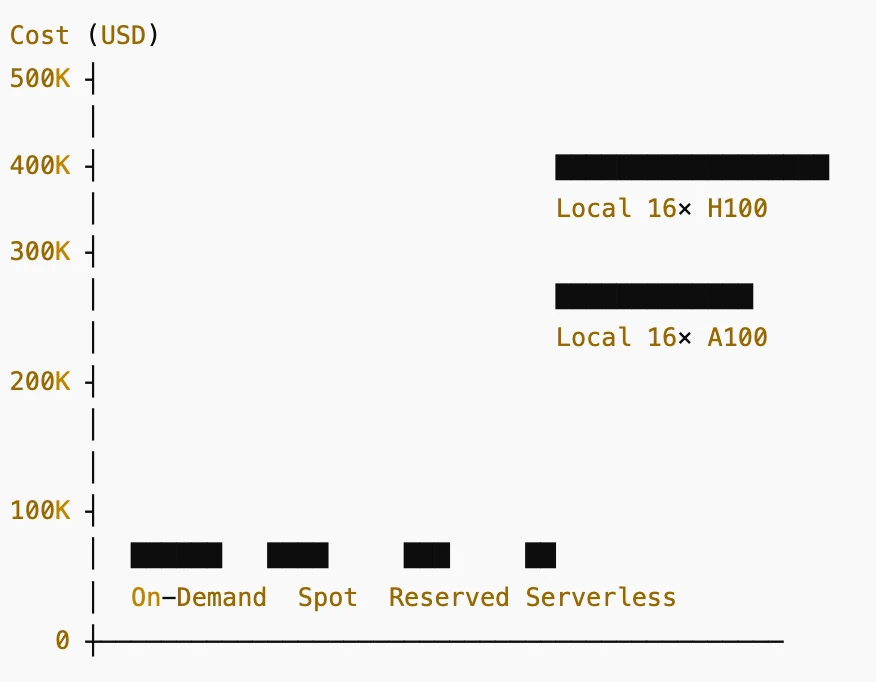
Barras (da esquerda para a direita):
- Sob demanda: ~US$ 26.000/ano
- Instâncias spot: ~US$ 13.000/ano
- Reservado / Assinatura: ~US$ 8.000/ano
- Cobrança de GPU serverless: ~US$ 5.000/ano
- Local 16× A100 80 GB: custo de hardware de ~US$ 240.000
- Local 16× H100 80 GB: custo de hardware de ~US$ 480.000
Uma forma melhor e mais barata de usar o DeepSeek V3.2 em GPU na nuvem
A Novita AI fornece quatro modelos de cobrança de GPU para acomodar diferentes padrões de carga de trabalho e requisitos de custo.
Modelo de preço Método de cobrança Disponibilidade de recursos Nível de custo Risco de interrupção Casos de uso típicos Sob demanda (pague pelo uso) Cobrado pelo tempo de execução real (por segundo ou por hora) Alta, instâncias podem ser iniciadas ou paradas a qualquer momento Médio Nenhum Desenvolvimento e teste, depuração de modelos, cargas de trabalho variáveis ou imprevisíveis Instâncias spot Cobrado pelo tempo de execução com taxas com desconto Médio, dependente da capacidade ociosa disponível Baixo (geralmente até ~50% mais barato que Sob demanda) Sim, instâncias podem ser preemptadas Tarefas em lote, inferência offline, treinamento tolerante a falhas, cargas de trabalho sensíveis a custo Assinatura / Planos reservados Cobrança fixa mensal ou anual Alta, recursos dedicados e previsíveis Médio-baixo (com desconto vs. Sob demanda) Nenhum Cargas de trabalho estáveis de longo prazo, sistemas de produção, treinamento ou inferência contínuos Cobrança de GPU serverless Cobrado pelo poder de computação real consumido por execução Escala automaticamente com a demanda Baixo-médio (pague apenas pelo que é usado) Nenhum (totalmente gerenciado pela plataforma) Inferência orientada a eventos, tráfego com picos, serving de modelos baseado em API, sobrecarga operacional mínima
1. Sob demanda (pague pelo uso)
O Sob demanda é o modelo de consumo padrão no qual o poder de computação GPU é cobrado estritamente pelo tempo de execução, geralmente por segundo ou por hora, sem compromissos ou reservas de longo prazo. Ele oferece máxima flexibilidade e é adequado para cargas de trabalho variáveis, uso intermitente e experimentação em estágio inicial, pois os custos são incorridos apenas enquanto a instância está ativa. Armazenamento e recursos auxiliares, incluindo discos e rede, são cobrados com base no uso.
Experimente GPU rápida e barata agora!
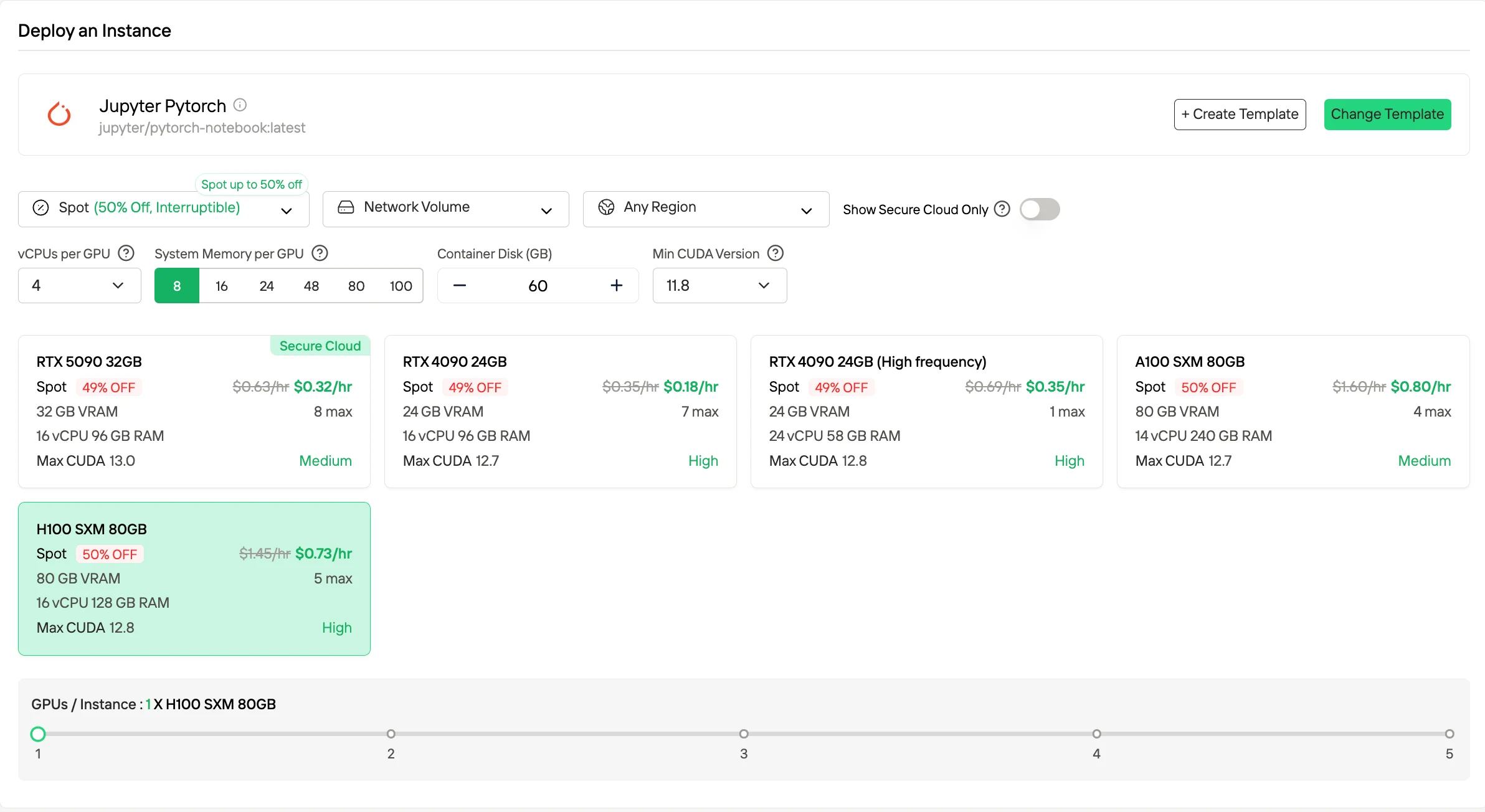
2. Instâncias spot
As Instâncias spot oferecem preços horários substancialmente reduzidos, geralmente até aproximadamente 50% menores que as taxas Sob demanda, ao utilizar a capacidade ociosa de GPU. Essas instâncias podem ser preemptadas pela plataforma. A Novita mitiga esse risco fornecendo uma janela de proteção de uma hora e notificações de término antecipado. Esse modo de preço é apropriado para cargas de trabalho tolerantes a falhas ou em lote, onde interrupções ocasionais podem ser acomodadas.
Experimente GPU rápida e barata agora!
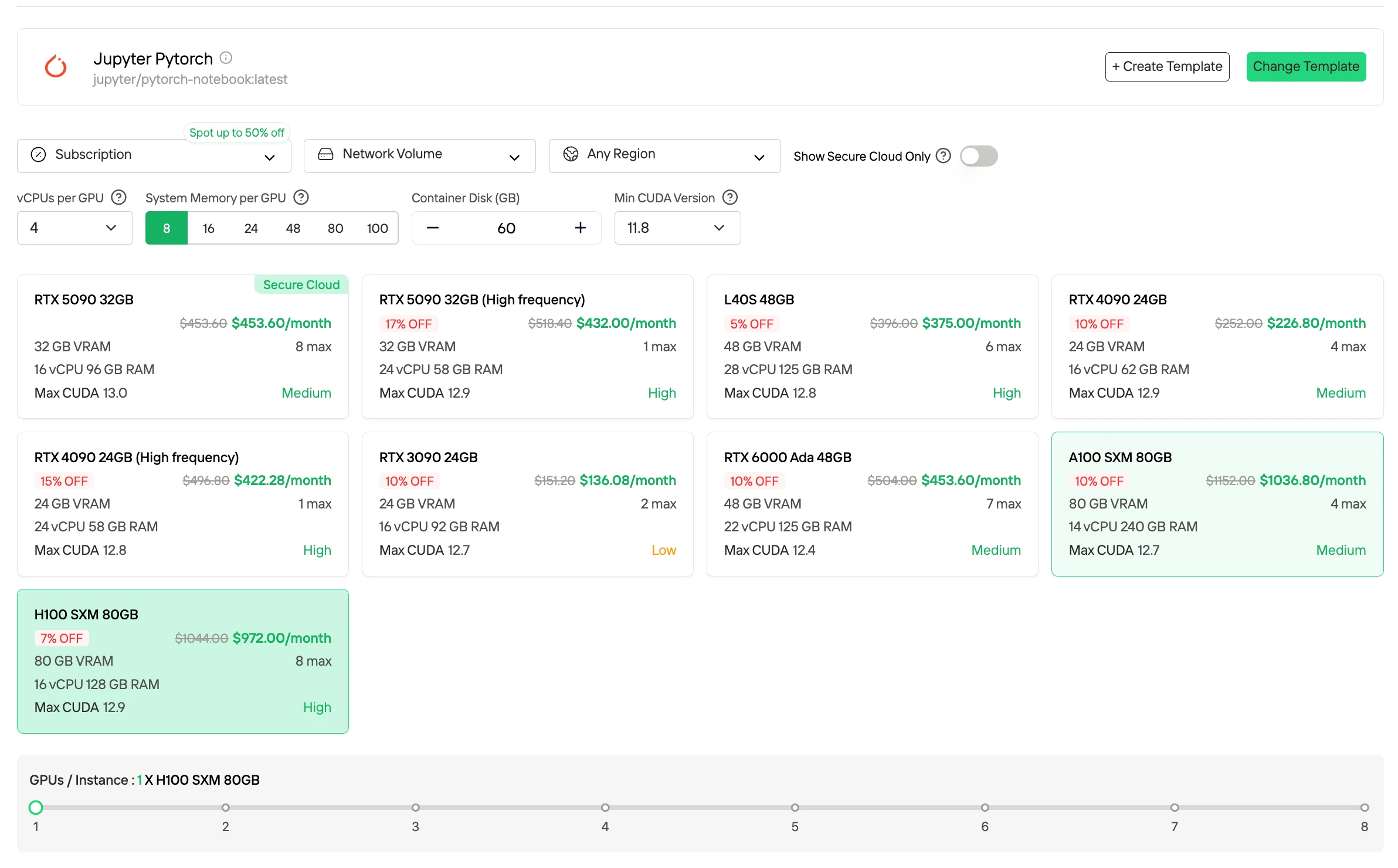
3. Assinatura / Planos reservados
Assinaturas e planos reservados estão disponíveis em termos mensais ou anuais e fornecem recursos GPU dedicados com disponibilidade previsível. Comparado com os preços Sob demanda, esses planos geralmente oferecem custos unitários efetivos menores em troca de compromisso de longo prazo. Eles são mais adequados para cargas de trabalho estáveis e contínuas e ambientes de produção que exigem capacidade de computação consistente.
Experimente GPU rápida e barata agora!
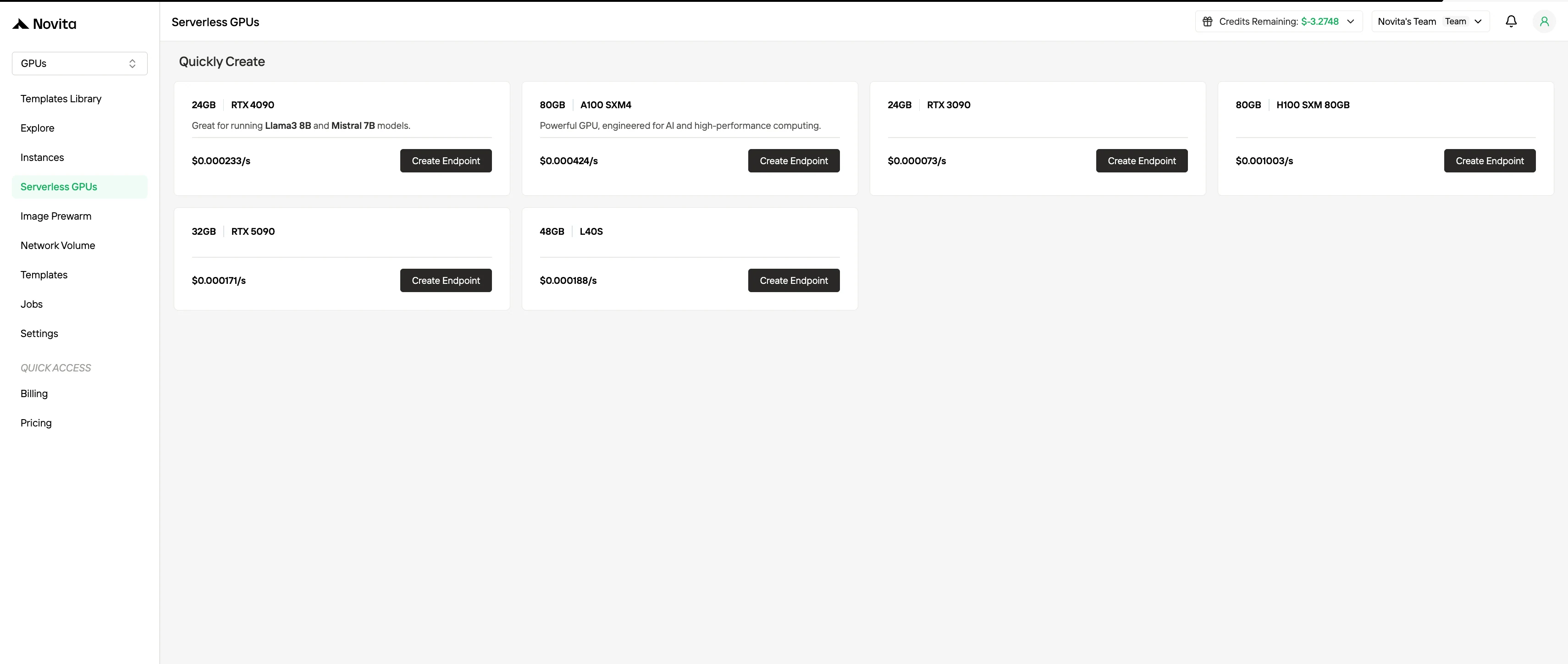
4. Cobrança de GPU serverless
A cobrança de GPU serverless abstrai o gerenciamento de instâncias, escalando automaticamente os recursos GPU em resposta à demanda da carga de trabalho. Os usuários são cobrados apenas pelos recursos de computação realmente consumidos, em vez de instâncias provisionadas. Esse modelo é vantajoso para cargas de trabalho orientadas a eventos ou altamente elásticas, pois minimiza a sobrecarga operacional enquanto melhora a eficiência de custos.
Experimente GPU rápida e barata agora!
A Novita AI também oferece templates, projetados para reduzir significativamente a sobrecarga operacional e cognitiva associada à implantação de cargas de trabalho de IA baseadas em GPU. Em vez de exigir que os desenvolvedores montem ambientes manualmente do zero, o sistema de templates fornece imagens pré-configuradas e prontas para produção que agrupam o sistema operacional, versões de CUDA e cuDNN, frameworks de aprendizado profundo, motores de inferência e, em alguns casos, até pilhas de serving de modelo totalmente conectadas.
Como implantar o DeepSeek V3.2 na Novita AI
Passo 1: Crie uma conta
Crie sua conta Novita AI por meio do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para visualizar nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Passo 2: Explore templates e servidores GPU
Escolha entre templates como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida — as opções incluem o poderoso L40S, RTX 4090 ou A100 SXM4, cada um com diferentes especificações de VRAM, RAM e armazenamento.
Passo 3: Personalize sua implantação e lance uma instância
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho de IA e necessidades de desenvolvimento específicas. Em seguida, seu ambiente GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computação.
Passo 4: Monitore o progresso da implantação
Navegue até o Gerenciamento de instâncias para acessar o console de controle. Este painel permite acompanhar o status da implantação em tempo real.
Experimente GPU rápida e barata agora!
Passo 5: Visualize o status de download da imagem
Clique na sua instância específica para monitorar o progresso do download da imagem do contêiner. Esse processo pode levar vários minutos, dependendo das condições de rede.
Passo 6: Verifique a implantação bem-sucedida
Depois que a instância for iniciada, ela começará a baixar o modelo. Clique em “Logs” -> “Logs da instância” para monitorar o progresso do download do modelo. Procure pela mensagem
"Application startup complete."nos logs da instância. Isso indica que o processo de implantação foi concluído com sucesso.Clique em “Conectar”, depois clique em -> “Conectar ao serviço HTTP [Porta 8000]”. Como este é um serviço de API, você precisará copiar o endereço.
Para fazer solicitações ao seu modelo, substitua o endereço
"[http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai](http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai&/#8221)"pelo seu endereço exposto real. Copie o código abaixo para acessar seu modelo privado!
O DeepSeek V3.2 representa uma evolução orientada à implantação de grandes modelos de linguagem MoE, combinando atenção esparsa, raciocínio consciente de agentes e aprendizado por reforço de recompensa mista para melhorar a eficiência de contexto longo e a confiabilidade de múltiplas ferramentas. No entanto, em configurações FP16/BF16, o DeepSeek V3.2 requer aproximadamente 1,3 TB de memória GPU agregada, o que se traduz em centenas de milhares de dólares em custos de hardware de GPU apenas. A quantização e o offload reduzem significativamente a pressão de memória, mas introduzem compromissos em complexidade e desempenho. Por outro lado, a implantação baseada em nuvem na Novita AI oferece um caminho mais acessível, aproveitando modelos de cobrança flexíveis, templates pré-configurados e provisionamento rápido para reduzir as barreiras financeiras e operacionais. Juntas, essas opções esclarecem como o DeepSeek V3.2 pode ser implantado de forma estratégica, e não proibitiva.
Perguntas frequentes
Por que o DeepSeek V3.2 requer tanta memória GPU em precisão total?
O DeepSeek V3.2 requer grande memória GPU porque seus ≈685B parâmetros, combinados com caches KV de contexto longo e buffers de execução em tempo de execução, levam implantações FP16/BF16 a cerca de 1,3 TB de VRAM agregada.
Como o DeepSeek V3.2 reduz os custos de contexto longo em comparação com modelos anteriores?
O DeepSeek V3.2 introduz a Atenção Esparsa do DeepSeek (DSA), que poda a atenção para os tokens top-k mais relevantes, reduzindo o uso de computação e VRAM de contexto longo em 50 a 70% em comparação com a atenção densa em comprimentos de contexto grandes.
Qual hardware é geralmente necessário para executar o DeepSeek V3.2 em FP16/BF16?
A inferência de precisão total do DeepSeek V3.2 geralmente depende de 8 a 16 GPUs A100 ou H100 com 80 GB de VRAM cada, totalizando quase 1,3 TB de memória GPU total.
A Novita AI é a plataforma de nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instância GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.
Leitura recomendada
MiniMax Speech 02: Principal solução para geração de voz rápida e natural
Requisitos de VRAM do ERNIE-4.5-VL-A3B: Execute modelos multimodais com menor custo
Qwen3 Embedding 8B: Busca poderosa, personalização flexível e multilíngue



