

Novita AI 正在推出“构建月”活动,为开发者提供所有主要产品高达20%的独家优惠!
随着大规模推理和代理模型从研究走向实际部署,开发者面临着能力与成本之间的关键矛盾。DeepSeek V3.2 体现了这一挑战:虽然它提供了强大的长上下文吞吐量、多步骤工具使用可靠性和改进的强化学习稳定性,但它也引入了巨大的硬件和VRAM需求,尤其是在全精度部署下。
本文通过审视 DeepSeek V3.2 的架构、VRAM 和硬件需求、本地部署的成本结构以及 Novita AI 灵活 GPU 产品提供的成本效益替代方案来探讨这些问题。
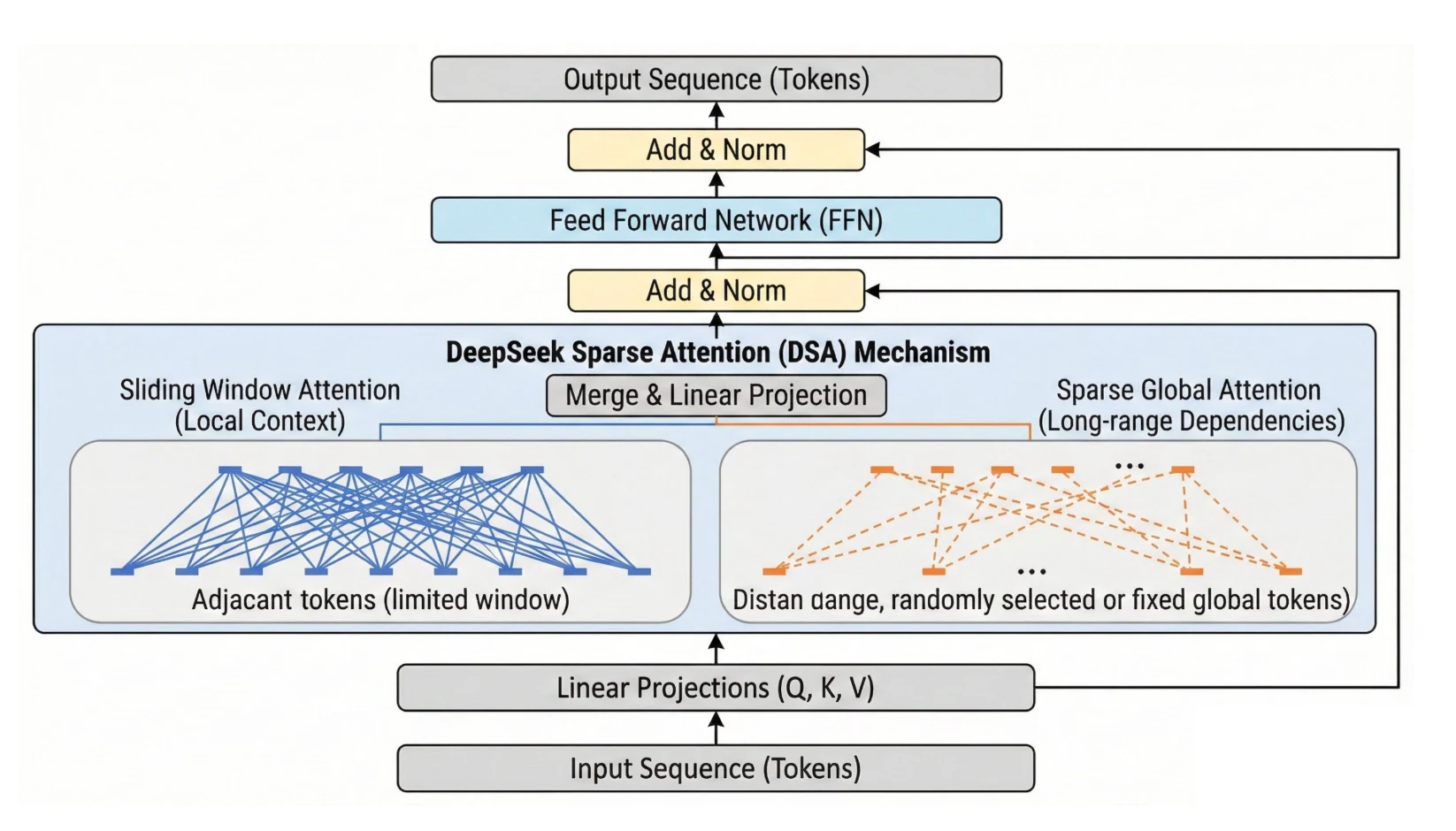
Deepseek V3.2 的架构亮点
DeepSeek V3.2 最好被视为 V3/R1 的“部署优先”升级:它专注于实际的长上下文吞吐量、具有持久推理的代理工具使用,以及更灵活的 RL 栈,将可验证奖励与基于评分标准的奖励混合用于不可验证任务,这直接关系到关心延迟、上下文压力和多步骤可靠性的 API 用户。
| 层 | V3.2 新增内容 | 对 API 用户的改变 |
|---|---|---|
| 长上下文 (DSA) | DeepSeek 稀疏注意力 (DSA) 包含一个闪电索引器+令牌选择器(top-k)。稀疏注意力减少了注意力计算。 | 长提示变得经济可行:长上下文中每个额外令牌位置的边际成本更低,长上下文场景中端到端速度提升,减少了“必须分块”的部署。 |
| 代理能力 | “在工具使用中思考”加上上下文管理,跨工具输出保留推理轨迹,以及大规模代理数据合成**(官方发布说明:1,800+ 环境,85k+ 复杂指令)。** | 多工具工作流中成功率更高。减少了每次工具调用重新推导状态的失败,但如果管理不当,上下文溢出的风险也更高。 |
| RLVR + 多奖励 | 混合 RL 使用基于规则的结果奖励 + 长度惩罚 + 语言一致性用于推理/代理任务;生成式奖励模型为一般任务提供每个提示的评分标准。GRPO 通过无偏 KL 估计、离策略序列掩码、保持路由(MoE)、保持采样掩码(top-p/top-k)来稳定。 | 对于没有符号验证器的开放任务,对齐更加稳健;大规模下 RL 稳定性更好;通过长度惩罚更可控的冗长度。 |
DeepSeek V3.2 的 DSA 对 VRAM 的影响
DeepSeek 稀疏注意力 (DSA) 通过将注意力仅修剪到最相关的令牌,削减了长上下文中注意力层的计算和内存成本,与密集注意力在大令牌数下相比,降低了总体FLOPs 和 VRAM 压力。API 价格降低 50% 以上反映了这些效率在实际中的提升。
- 与长序列场景下的密集注意力相比,DSA 将长上下文的计算和内存成本降低了约 50% 以上,且质量下降可忽略不计。
- 这种降低不会改变模型的参数总数(≈685B),但降低了长窗口的运行时内存占用,尤其是每个令牌的 KV 和注意力工作空间使用。
| 上下文长度 | 密集注意力(基准趋势) | DSA(DeepSeek 稀疏注意力)效果**(近似)** |
|---|---|---|
| 8K tokens | 基准内存和计算 | 相似或适度更低的内存 — 短长度下稀疏开销最小 |
| 32K tokens | 二次增长变大 | 与类似上下文长度的密集注意力相比内存使用降低30-40%(推理) |
| 128K tokens | 成本和内存变得非常高 | 内存使用和成本降低60-70%,推理成本降低>60%,DSA 下内存使用减少约70% |
来自 Amitray
DeepSeek V3.2 的 VRAM 和硬件需求
全精度 (FP16/BF16)
在标准全精度 (FP16/BF16) 部署下,DeepSeek-V3.2 的推理施加了极高的硬件要求,因为模型权重和运行时执行所需的组合 GPU 内存超过约 1 TB。对于 BF16/FP16 场景,常用配置包括 8–16 个 H100 或 A100 级 GPU,每个 GPU 80 GB VRAM,总计 GPU 内存容量接近 1.3 TB。
量化与卸载权衡
| 量化级别 | 近似内存占用 |
|---|---|
| FP16 / BF16 | 1.3 TB total |
| 8-bit (w8a8) | 670 GB total |
| 4-bit | 335 GB total |
DeepSeek V3.2 本地部署成本是多少?
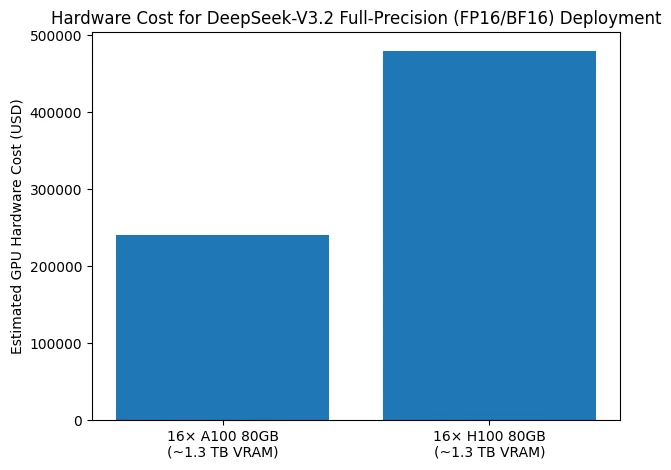
条形图展示了在全精度 (FP16/BF16) 设置下部署 DeepSeek-V3.2 所需的硬件成本。为了满足大约 1.3 TB 的 GPU 内存需求,典型配置依赖于 16 个各具 80 GB VRAM 的 GPU。当使用 A100 80 GB GPU 时,仅 GPU 的估计成本约为 240,000 美元,而基于 H100 80 GB GPU 的等效配置将成本增加到约 480,000 美元。
这一比较突显了,即使在考虑服务器、高速互连、电力和冷却基础设施之前,DeepSeek-V3.2 的全精度推理本身就需要数十万美元的 GPU 投资。因此,该图强调了在 FP16/BF16 下部署 DeepSeek-V3.2 的极高硬件成本障碍,这解释了为什么此类部署主要局限于大型数据中心,以及为什么量化与卸载策略在实践中常常被认为是必要的。
成本比较:DeepSeek V3.2 的本地 GPU 与云 GPU
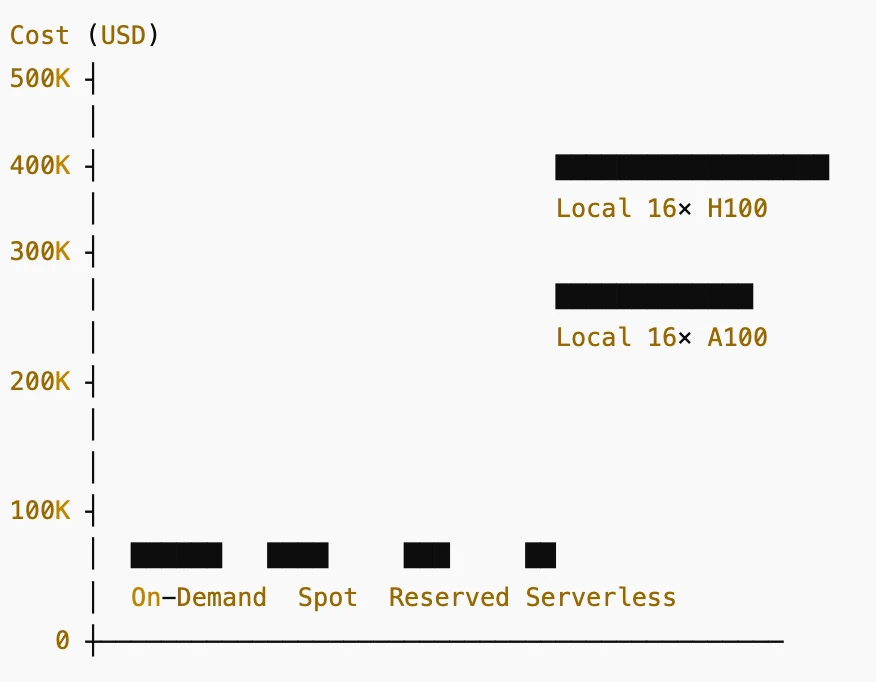
条形图(从左到右):
- 按需: 约 $26,000/年
- 竞价实例: 约 $13,000/年
- 预留/订阅: 约 $8,000/年
- 无服务器 GPU 计费: 约 $5,000/年
- 本地 16× A100 80 GB: 约 $240,000 硬件成本
- 本地 16× H100 80 GB: 约 $480,000 硬件成本
在云 GPU 上更好且廉价地使用 DeepSeek V3.2
Novita AI 提供四种 GPU 计费模式,以适应不同的工作负载模式和成本要求。
| 定价模式 | 计费方式 | 资源可用性 | 成本级别 | 中断风险 | 典型用例 |
|---|---|---|---|---|---|
| 按需(现收现付) | 按实际运行时间计费(每秒或每小时) | 高,实例可随时启动或停止 | 中等 | 无 | 开发和测试、模型调试、变化或不可预测的工作负载 |
| 竞价实例 | 按运行时间以折扣价计费 | 中等,取决于可用空闲容量 | 低(通常比按需便宜约50%) | 是,实例可能被抢占 | 批处理作业、离线推理、容错训练、成本敏感的工作负载 |
| 订阅/预留计划 | 固定月度或年度计费 | 高,专用且可预测的资源 | 中低(相比按需有折扣) | 无 | 长期稳定工作负载、生产系统、持续训练或推理 |
| 无服务器 GPU 计费 | 按每次执行实际消耗的计算计费 | 根据需求自动扩展 | 低-中等(仅按使用付费) | 无(完全由平台管理) | 事件驱动推理、突发流量、基于API的模型服务、最小化运营开销 |
1. 按需(现收现付)
按需是标准消费模式,GPU 计算严格按运行时间计费,通常按秒或按小时,无长期承诺或预留。它提供最大的灵活性,非常适合可变工作负载、间歇使用和早期实验,因为成本仅在实例活跃时产生。存储和辅助资源(包括磁盘和网络)按使用量计费。
2. 竞价实例
竞价实例通过利用闲置 GPU 容量提供大幅降低的每小时价格,通常比按需费率低约 50%。这些实例可能被平台抢占。Novita 通过提供一小时保护窗口和提前终止通知来减轻此风险。此定价模式适用于可以容忍偶尔中断的容错或批处理工作负载。
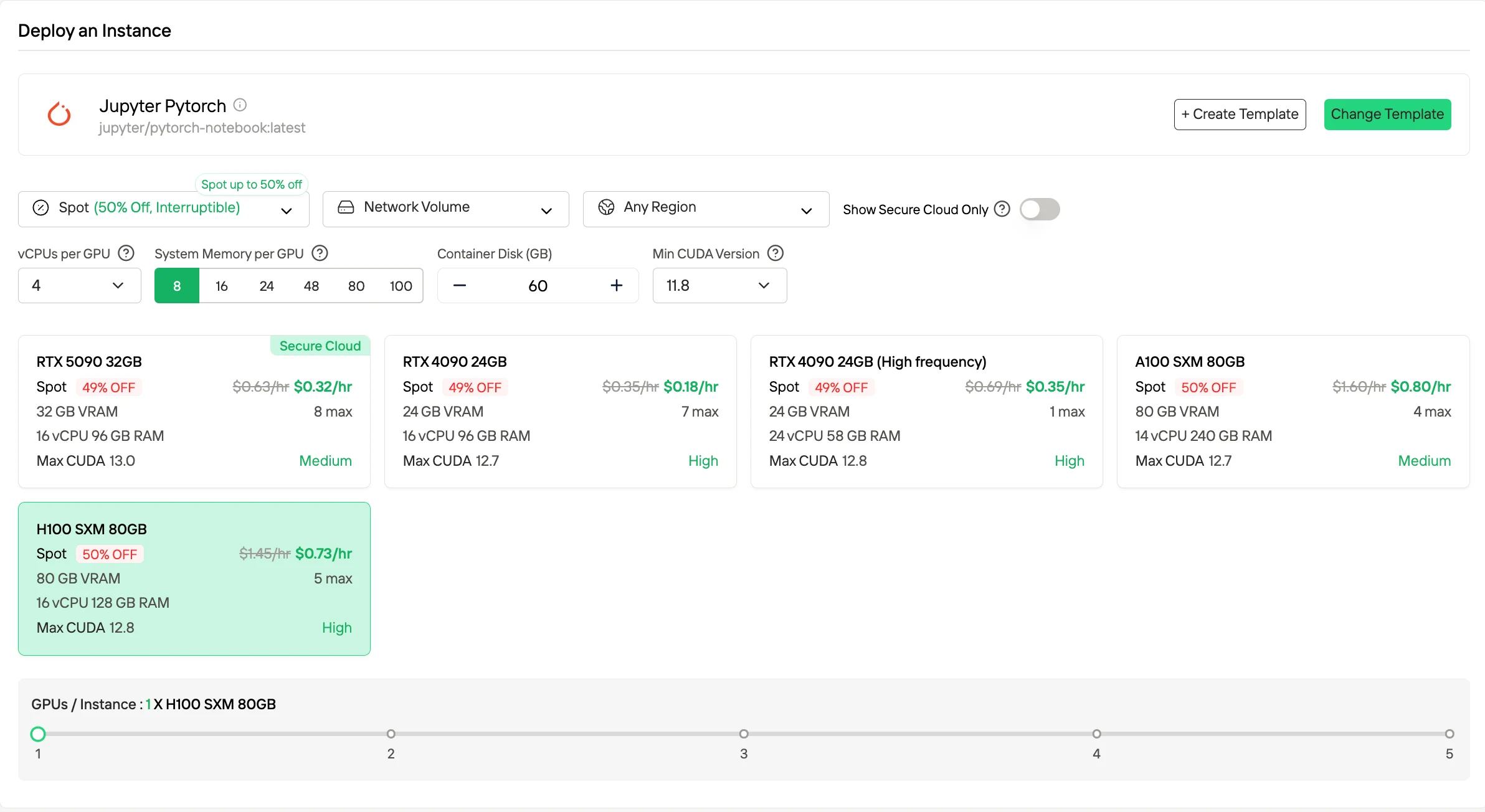
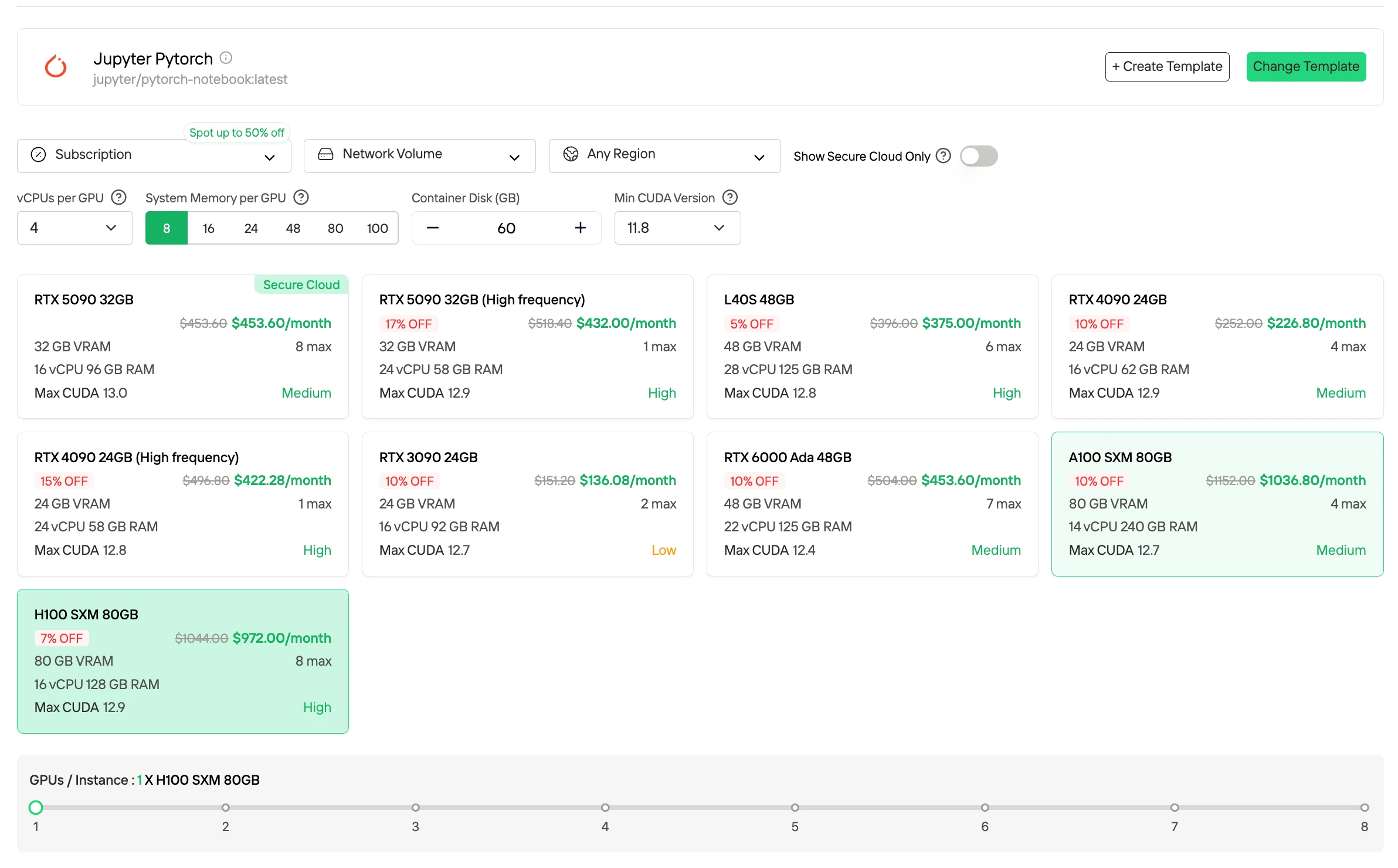
3. 订阅/预留计划
订阅和预留计划以月度或年度期限提供,提供专用 GPU 资源,具有可预测的可用性。与按需定价相比,这些计划通常以较长期承诺换取较低的有效单位成本。它们最适合需要持续计算能力的稳定、连续工作负载和生产环境。
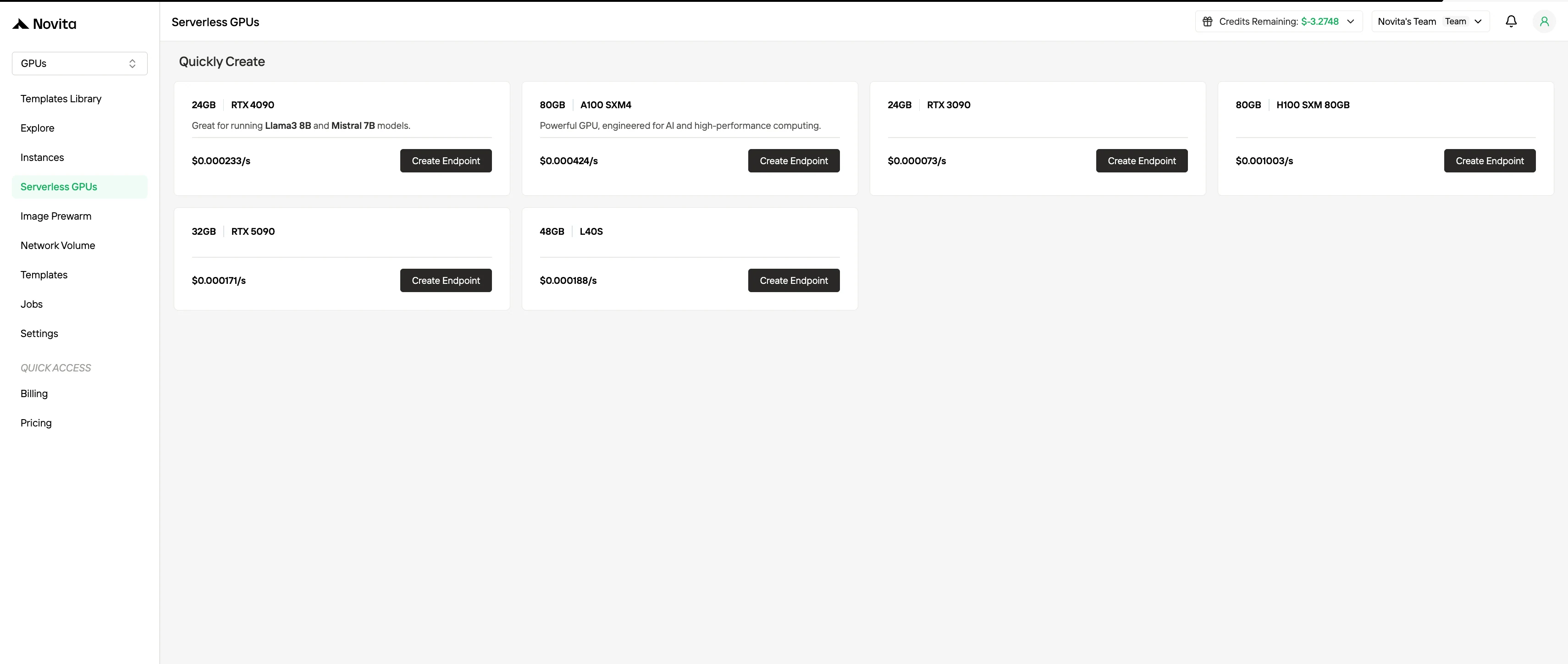
4. 无服务器 GPU 计费
无服务器 GPU 计费通过根据工作负载需求自动扩展 GPU 资源,抽象化了实例管理。用户仅按实际消耗的计算资源付费,而不是按预置实例付费。此模式对于事件驱动或高度弹性的工作负载有利,因为它最小化运营开销同时提高成本效率。
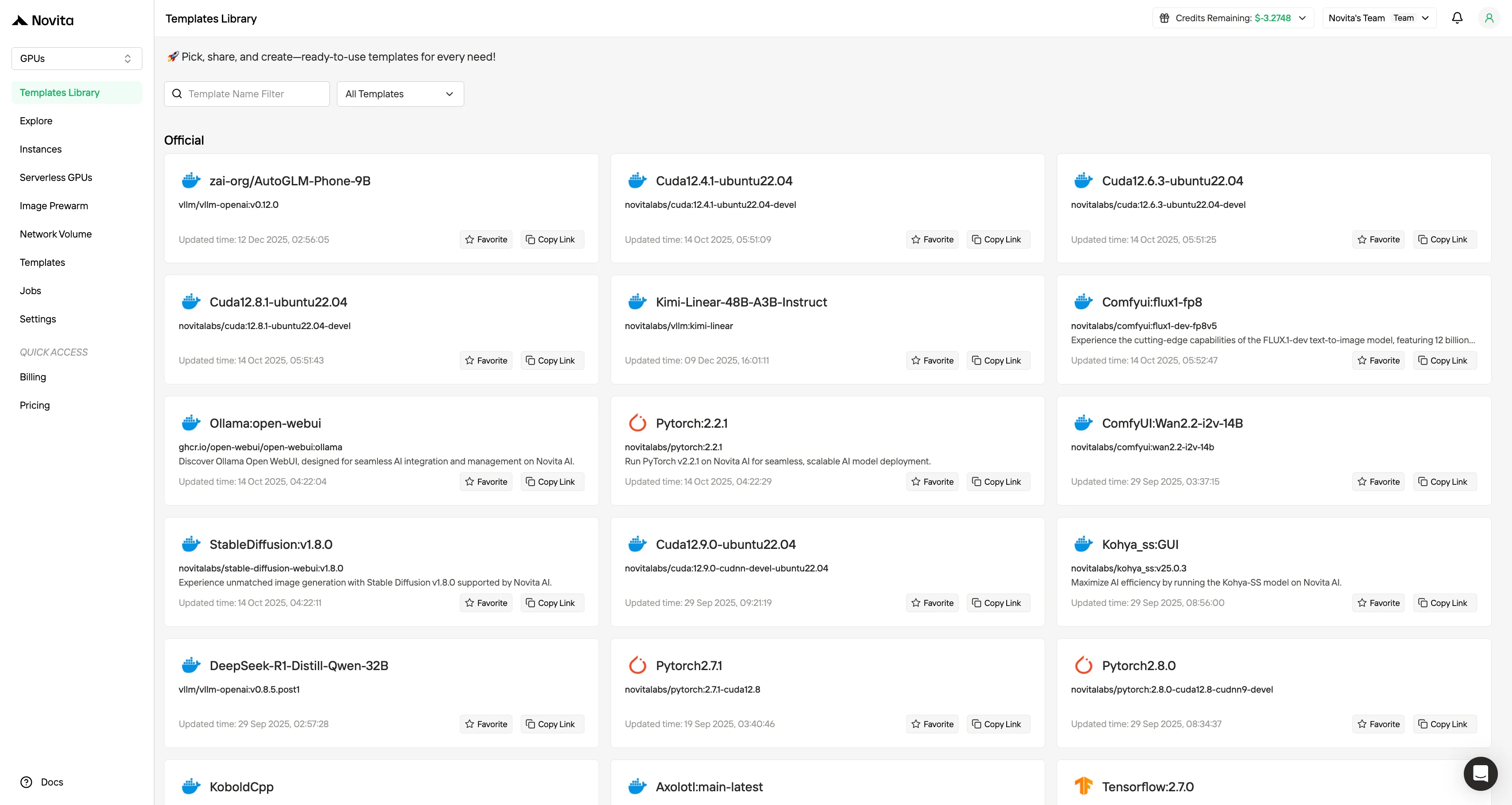
Novita AI 还提供模板,旨在显著降低与部署基于 GPU 的 AI 工作负载相关的运营和认知开销。模板系统不需要开发者从头手动组装环境,而是提供预配置的、可用于生产的镜像,这些镜像捆绑了操作系统、CUDA 和 cuDNN 版本、深度学习框架、推理引擎,在某些情况下甚至包括完全连接的模型服务栈。
如何在 Novita AI 上部署 DeepSeek V3.2
步骤1:注册账户
通过我们的网站创建您的 Novita AI 账户。注册后,导航到左侧边栏的“探索”部分查看我们的 GPU 产品,并开始您的 AI 开发之旅。

步骤2:探索模板和 GPU 服务器
从与您项目需求匹配的模板中选择,如 PyTorch、TensorFlow 或 CUDA。然后选择您偏好的 GPU 配置——选项包括强大的 L40S、RTX 4090 或 A100 SXM4,每种配置具有不同的 VRAM、RAM 和存储规格。
步骤3:定制部署并启动实例
通过选择偏好的操作系统和配置选项来自定义您的环境,以确保为您的特定 AI 工作负载和开发需求提供最佳性能。然后,您的高性能 GPU 环境将在几分钟内准备就绪,使您能够立即开始机器学习、渲染或计算项目。
步骤4:监控部署进度
导航到实例管理以访问控制台。此仪表板允许您实时跟踪部署状态。
步骤5:查看镜像拉取状态
点击您的特定实例以监控容器镜像下载进度。此过程可能需要几分钟,具体取决于网络条件。
步骤6:验证部署成功
实例启动后,将开始拉取模型。点击“日志” -> “实例日志”以监控模型下载进度。在实例日志中查找消息
"Application startup complete."。这表示部署过程已成功完成。点击“连接”,然后点击 -> “连接到 HTTP 服务 [端口 8000]”。由于这是一个 API 服务,您需要复制地址。
要向您的模型发出请求,请将***“http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai"*** 替换为您实际的暴露地址。复制以下代码以访问您的私有模型!
DeepSeek V3.2 代表了大型 MoE 语言模型的部署导向演进,结合了稀疏注意力、代理感知推理和混合奖励强化学习,以提高长上下文效率和多工具可靠性。然而,在 FP16/BF16 设置下,DeepSeek V3.2 需要大约 1.3 TB 的聚合 GPU 内存,这意味着仅 GPU 硬件成本就高达数十万美元。量化和卸载显著降低了内存压力,但在复杂性和性能方面引入了权衡。相比之下,基于 Novita AI 的云部署提供了一条更易访问的路径,利用灵活的计费模式、预配置模板和快速配置,降低了财务和运营障碍。这些选项共同阐明了 DeepSeek V3.2 如何能够战略性地部署,而不是令人望而却步。
常见问题
1. 为什么 DeepSeek V3.2 在全精度下需要如此大的 GPU 内存?
DeepSeek V3.2 需要大量 GPU 内存,因为其约 685B 参数,加上长上下文 KV 缓存和运行时执行缓冲区,将 FP16/BF16 部署推至约 1.3 TB 的聚合 VRAM。
2. 与早期模型相比,DeepSeek V3.2 如何降低长上下文成本?
DeepSeek V3.2 引入了 DeepSeek 稀疏注意力 (DSA),它将注意力修剪到 top-k 相关令牌,在长上下文长度下与密集注意力相比,将长上下文计算和 VRAM 使用量减少了 50–70%。
3. 运行 DeepSeek V3.2 FP16/BF16 通常需要什么硬件?
DeepSeek V3.2 的全精度推理通常依赖于 8–16 个 A100 或 H100 GPU,每个 80 GB VRAM,总计近 1.3 TB 的 GPU 内存。
Novita AI 是一站式云平台,助力您的 AI 雄心。集成 API、无服务器、GPU 实例——您需要的经济高效工具。消除基础设施,免费开始,将您的 AI 愿景变为现实。
推荐阅读
MiniMax Speech 02:快速自然语音生成的最佳解决方案



