

重點摘要
選擇 Llama 3.3 70B 的時機: 應用如多語言聊天機器人、智能助理和 AI 研究,但需要較高的硬體資源。
Llama 3.3 70B 不適合的情況: 需要影像或音訊處理時
選擇 Mistral Nemo 的時機: 文字生成任務,以及需要函式呼叫的情境
Mistral Nemo 不適合的情況: 追求全面的頂尖基準評分
如果您想根據自己的使用情境評估 Llama 3.3 70b 或 Mistral Nemo,註冊後 Novita AI 會提供 $0.5 的額度供您開始使用!
人工智慧領域正在快速發展,Meta 與 Mistral AI 分別推出了它們的次世代語言模型 Llama 3.3 70B 和 Mistral Nemo。這些發布在業界引起了廣泛關注。本文將全面分析這兩個模型的功能與應用場景,為讀者提供詳盡的參考。
模型系列基本介紹
在開始比較之前,我們先了解每個模型的基本特性。
Llama 3.3 模型系列特性
- 發布日期:2024 年 12 月 6 日
- 模型規模:
- 主要創新:
- 僅提供指令調整版本
- 支援函式呼叫
- 針對多語言對話優化
- 利用 GQA 技術提升處理效率
- 支援 128K tokens 的上下文視窗
- 在推理、數學和一般知識方面有顯著改進
Mistral 模型系列特性
- 發布日期:2024 年 7 月 19 日
- 模型規模:
- 主要特色:
- 開源多語言模型
- 128K tokens 的大上下文視窗
- 支援函式呼叫
- 使用 Tekken tokenizer 提升效率
- 在推理、世界知識和程式碼撰寫方面表現優異
模型比較
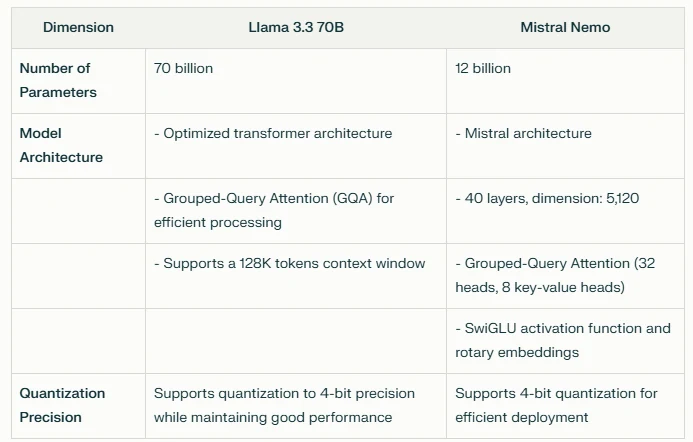
此表格凸顯了兩個模型在參數、架構設計和量化能力上的差異。Llama 3.3 70B 提供顯著更大的參數量和針對高容量任務優化的架構,而 Mistral Nemo 則提供更緊湊的設計和高效的處理功能。兩個模型都支援量化以提升部署效率。
基準測試比較
在了解每個模型的基本特性後,現在讓我們深入探討它們在各項基準測試中的表現。這個比較將有助於說明它們在不同領域的優勢。
| 基準測試 | 意義 | Llama 3.3 70b | Mistral Nemo |
|---|---|---|---|
| MMLU | MMLU(大規模多任務語言理解)評估模型在各種任務中的一般語言理解能力。 | 86 | 66 |
| HumanEval | HumanEval 測試模型根據給定的問題描述撰寫正確 Python 程式碼的能力。 | 86 | 71 |
| MATH | MATH 評估模型的數學問題解決能力。 | 76 | 44 |
| Artificial Analysis Multilingual Index | 反映模型在多種語言中的表現。計算方式為 Multilingual MMLU(一般推理)和 MGSM(數學推理)評估分數的平均值。 | 84 | <61 |
從這個表格可以看出,Llama 3.3 70b 在所有維度上都展現出特別的優勢。
如果您想了解更多關於 llama3.3 基準測試的知識,可以參考這篇文章:Llama 3.3 Benchmark:主要優勢與應用洞察。
透過 Novita AI 進行的速度比較
如果您想親自測試,可以在 Novita AI 網站上開始免費試用。
延遲
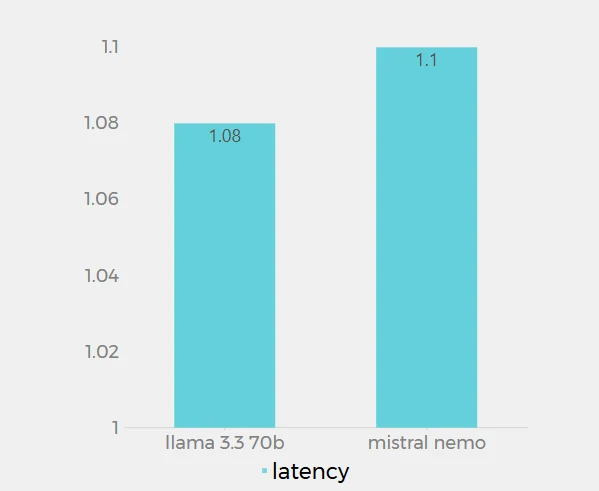
Llama 3.3 70B(1.08 秒)和 Mistral Nemo(1.1 秒)在 Novita AI 上的延遲值非常接近,僅相差 0.02 秒。這個數據代表每個模型在 Novita AI 平台上處理請求的回應時間。Llama 3.3 70B 的延遲略低,表示它的回應速度比 Mistral Nemo 稍快。不過,差異非常小,在大多數實際應用中可能不會被注意到。兩個模型都表現出低延遲,顯示它們都經過良好優化,能夠快速回應。
吞吐量(每秒 Token 數)
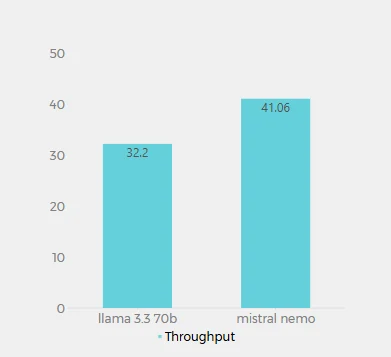
Llama 3.3 70B(32.2 tokens/秒)和 Mistral Nemo(41.06 tokens/秒)在 Novita AI 上的吞吐量值代表每個模型每秒可處理的 token 數量。這個指標對於了解模型的處理速度和效率至關重要。Mistral Nemo 展現出更高的吞吐量,每秒處理的 token 數比 Llama 3.3 70B 大約多 27.5%。這表示 Mistral Nemo 在生成文字方面效率更高,對於較長的輸出可能提供更快的回應時間。
硬體需求比較
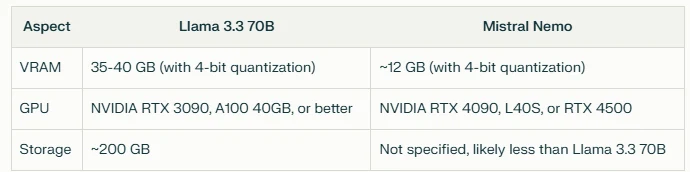
總而言之,Mistral Nemo 在硬體需求方面似乎提供了更高效的選擇,可能更適合資源有限的部署或效率優先的場合。然而,Llama 3.3 70B 較高的資源需求可能因其更大的模型規模而合理,這在某些任務中可能帶來更好的表現。
應用與使用案例
Llama 3.3 70B
- 多語言聊天機器人和智能助理
- 程式碼支援與軟體開發
- 合成數據生成
- 多語言內容創作與在地化
- AI 研究和實驗平台
- 基於知識的應用開發
- 適合小團隊的靈活部署
Mistral Nemo
- 全球多語言應用,特別適合需要函式呼叫的情境
- 文字生成與翻譯任務
透過 Novita AI 的可用性與部署
步驟 1:登入並訪問模型庫
登入您的帳戶,然後點選 模型庫 按鈕。

步驟 2:選擇您的模型
瀏覽可用的選項,然後選擇適合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。

步驟 4:獲取您的 API 金鑰
為了驗證 API,我們將提供您一個新的 API 金鑰。進入「設定」頁面,您可以如圖所示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言專屬的套件管理器安裝 API。

安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是給 Python 使用者的聊天補全 API 範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.3-70b-instruct"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
註冊後,Novita AI 會提供 $0.5 的額度供您開始使用!
如果免費額度用完,您可以付費繼續使用。
總而言之,Llama 3.3 70B 和 Mistral Nemo 各自擁有獨特的特點,為 AI 應用開發提供了新的可能性。在選擇時,應考慮具體需求,權衡每個模型的功能,以達到最佳的應用效果。隨著技術的不斷進步,我們期待看到更多創新的 AI 語言模型出現,推動人工智慧領域的持續發展。
常見問題
Llama 3 70B 需要多少 RAM?
估計 RAM:在單一 GPU 上執行 Llama 3.1 70B 通常需要約 350 GB 到 500 GB 的 GPU 記憶體,而相關的系統 RAM 也可能在 64 GB 到 128 GB 的範圍內。
Llama 3 比 GPT-4 更好嗎?
我們的研究發現,透過雲端 API 提供商使用 Llama 3 70B 時,其成本可比 GPT-4 便宜 50 倍,速度快 10 倍。根據我們小規模的評估,Llama 3 70B 在小學數學、算術推理和摘要能力方面表現出色。
Llama 3 比 Claude 更好嗎?
Llama 3 是一款頂尖模型,以其理解和回應各種輸入的卓越能力而聞名。而 Claude 3 則提供不同的版本,如 Haiku、Sonnet 和 Opus,各有其獨特優勢。Claude 3 的 Opus 版本甚至在一些重要測試中超越了著名的 GPT-4。
Novita AI 是一個整合 API、無伺服器、GPU 執行個體的一站式雲端平台,提供經濟實惠的工具,助力您的 AI 願景。消除基礎設施負擔,免費開始,讓您的 AI 願景成真。



