

重點摘要
Qwen2.5-7B 是一款中型開源 LLM,擁有 7.6B 參數、128K 上下文支援,以及強大的通用能力。
Qwen2.5-7B 可以 在本機部署(例如使用 RTX 4090 等 GPU),但 FP32 等高精度格式需要昂貴的硬體配置。
為了更高的可及性,透過 ** Novita AI ** 的 API 存取 提供了可擴展且具成本效益的替代方案,並完全相容於 OpenAI 的 SDK。
邀請朋友加入 Novita AI,你們雙方都可獲得 $10 美元的 LLM API 額度,總獎勵最高 $500 美元。為了支援開發者社群,Qwen2.5-7B 目前可在 Novita AI 上免費使用。

Qwen2.5-7B 是一款專為通用任務設計的多功能開源 LLM,兼顧效能與效率。支援超過 29 種語言與高達 128K 的上下文長度,可實現長篇推理並涵蓋廣泛的應用場景。
什麼是 Qwen 2.5 7B?
Qwen 2.5 7B 是一款強大的中型開源語言模型,擁有 76 億個參數,支援 128K 上下文,並針對通用任務進行最佳化。
模型概覽
- 模型大小:7.61B 參數
- 開源狀態:開放
- 架構:Transformers,搭配 RoPE、SwiGLU、RMSNorm 及 Attention QKV 偏置
- 上下文長度:128 tokens
語言與多模態
- 支援語言:支援超過 29 種多國語言
- 多模態能力:僅文字對文字
訓練細節
- 訓練資料量:在超過 18 兆 token 的資料集上訓練
基準測試
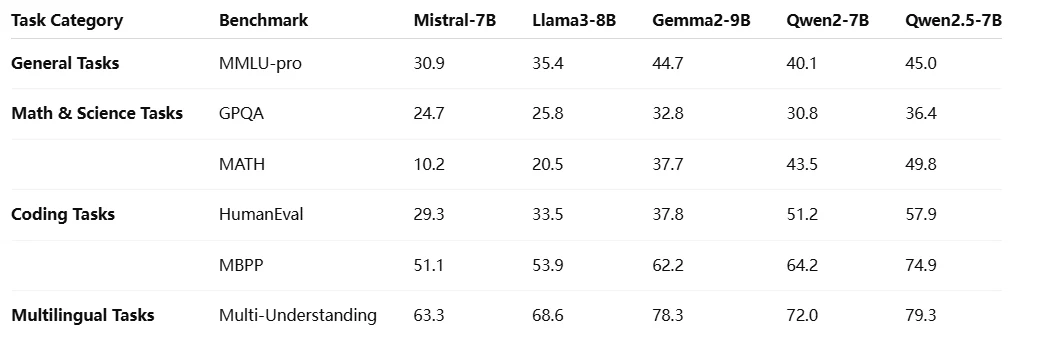
與其他 Qwen 2.5 模型比較
Qwen 2.5 系列 提供從 0.5B 到 72B 參數的可擴展模型家族,包含通用、程式碼與數學變體,可滿足從輕量部署到高效能 AI 應用的多樣需求。
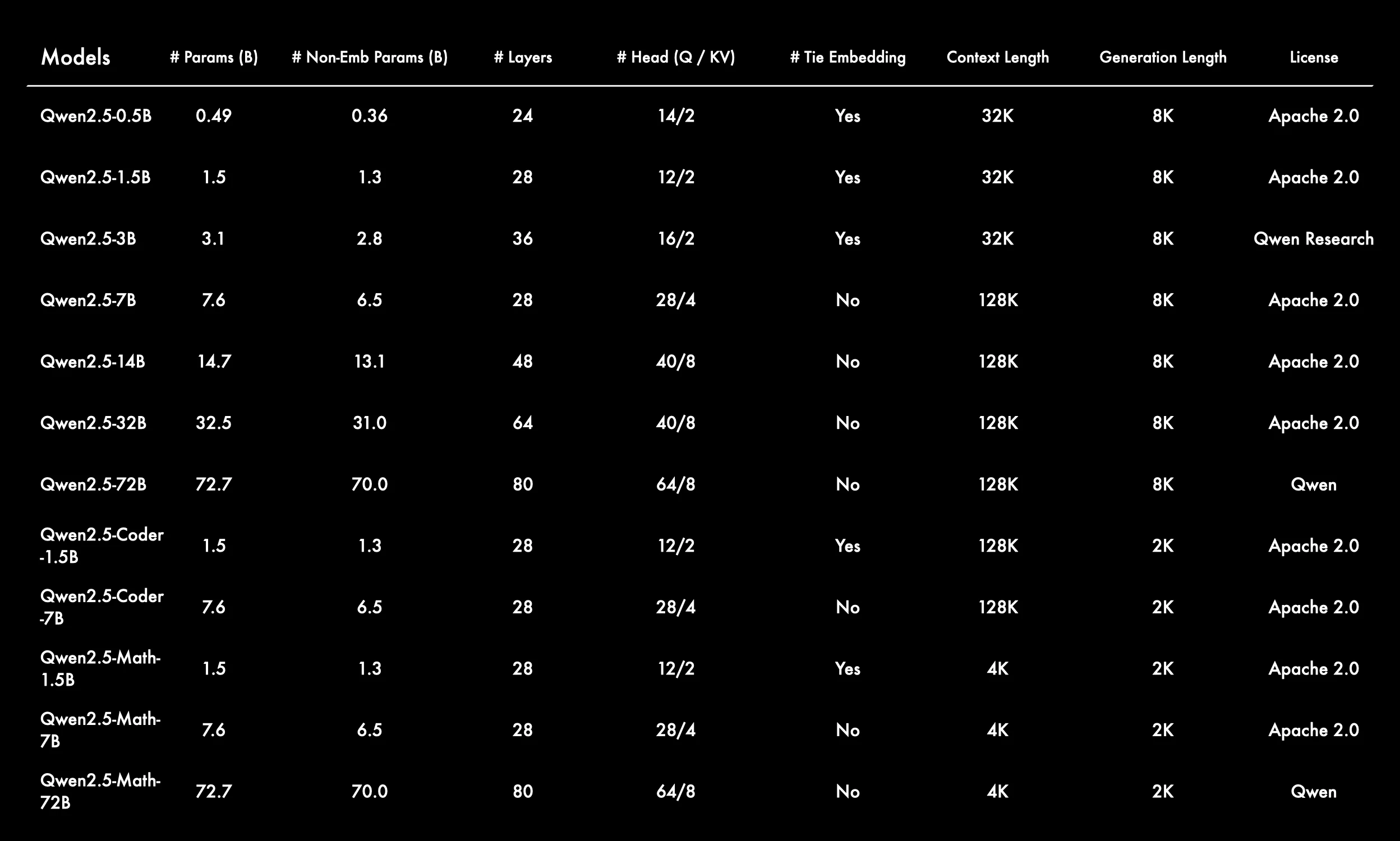
來源:Qwen
-
多種模型尺寸滿足不同應用場景
Qwen 2.5 系列涵蓋 0.5B 到 72B 參數,包含通用、Coder 與 Math 變體,為不同任務與運算預算提供靈活性。 -
大型模型支援長上下文視窗
多數模型支援 128K 或 32K 上下文長度,能進行長篇推理與多輪對話。僅 Math 模型使用較短的 4K 上下文,以最佳化密集運算。 -
選擇性地使用 Tie Embedding
較小或專用模型(如 1.5B 變體)啟用 Tie Embedding,可能用於減少參數量;而大型模型則關閉此功能以增強表示能力。 -
架構隨模型大小可預測地擴展
- 層數:從 24 到 80 層
- 注意力頭數:從 14/2 到 64/8(Q/KV 分離)
這反映了深度與寬度結構化擴展的策略。
-
專用的 Coder 與 Math 模型生成長度較短
這些模型使用 2K 生成長度,並針對程式碼生成或數學推理等領域特定任務進行最佳化,以精準度優先而非上下文範圍。
如何在本機存取 Qwen 2.5 7B
GPU 建議
| **量化方式 ** | ** 模型大小 ** | ** 建議 GPU** | **VRAM 需求 ** | ** 估計 GPU 成本(美元)** |
|---|---|---|---|---|
| FP16 | ~16.1 GB | 1× RTX 4090(24GB) | ≥24 GB | ~$1,600–$1,800 |
| FP32 | ~32.2 GB | 2× RTX 4090(各 24GB) | ≥48 GB | ~$3,200–$3,600 |
| 4-bit (Q4) | ~4.02 GB | RTX 3060(12GB) | ≥8 GB | ~$300–$350 |
快速入門
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct"
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
雖然在本機執行 Qwen2.5-7B 能提供完全控制與更快的回應時間,但購買高階 GPU(尤其是全精度 FP32 部署)的前期成本,可能遠高於使用按量計費的 API。對於預算有限的開發者或團隊來說,API 存取往往是更具成本效益且可擴展的解決方案。
如何透過 API 存取 Qwen 2.5 7B?
Novita AI 是一個 AI 雲端平台,讓開發者能透過簡單的 API 輕鬆部署 AI 模型,同時也提供實惠且可靠的 GPU 雲端服務,用於建置與擴展。
您可以開始免費試用,探索所選模型的能力。安裝後,在開發環境中匯入必要的程式庫。使用您的 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下是 Python 使用者使用聊天補全 API 的範例。
直接 API 整合
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
使用 OpenAI Agents SDK 進行多代理工作流程
透過將 Novita AI 整合至 OpenAI Agents SDK,建置進階的多代理系統:
- 隨插即用: 在任何 OpenAI Agents 工作流程中使用 Novita AI 的 LLM。
- 支援交接、路由與工具使用: 設計能夠委派、分流或執行功能的代理,全部由 Novita AI 的模型驅動。
- Python 整合: 只需將 SDK 指向 Novita 的端點(
https://api.novita.ai/v3/openai),並使用您的 API 金鑰即可。
在第三方平台上
- Hugging Face:透過 Novita AI 端點,在 Spaces、pipeline 或 Transformers 函式庫中使用 Qwen 3。
- 代理與編排框架: 透過官方連接器與逐步整合指南,輕鬆將 Novita AI 與 Continue、AnythingLLM、LangChain、Dify 及 Langflow 等合作平台連接。
- 相容 OpenAI 的 API: 無痛遷移並整合至 Cline、Cursor 等工具,專為 OpenAI API 標準設計。
無論是在本機或透過 API 執行 Qwen2.5-7B,開發者都能獲得強大的工具組。然而,**RTX 4090 等 GPU 的本機部署成本 ** 可能令人卻步,因此 Novita AI 的 API 整合對大多數團隊來說,是更聰明且更具可擴展性的選擇。
常見問題
如何在本機執行 Qwen 2.5 7B?
使用高階 GPU,例如 RTX 4090。FP16 需要約 24GB VRAM,而 FP32 則需約 48GB。您還需要安裝 Transformers 函式庫,並使用 AutoModelForCausalLM 載入模型。
API 存取與在本機執行模型相比如何?
API 存取消除了前期的 GPU 成本,並提供彈性的可擴展性。本機部署則提供控制權,但全精度配置的成本高出許多。
如何透過 API 存取 Qwen 2.5 7B?
Novita AI 提供隨插即用、相容 OpenAI 的 API。
Novita AI 是一個一站式雲端平台,助您實現 AI 抱負。整合的 API、無伺服器、GPU 實例——您所需的低成本工具。消除基礎設施負擔,從免費開始,讓您的 AI 願景成真。



