

核心要点
Qwen2.5-7B 是一款中型开源 LLM,拥有 7.6B 参数、128K 上下文支持,以及强大的通用性能。
Qwen2.5-7B 可以在 本地部署(如 RTX 4090 等 GPU),但 FP32 等高精度格式需要昂贵的硬件配置。
为了实现更广泛的访问,通过 ** Novita AI ** 提供的 API 访问 是一种可扩展、高性价比的替代方案,并且完全兼容 OpenAI 的 SDK。
邀请你的朋友使用 Novita AI,你们双方都将获得 10 美元的 LLM API 额度——最高可获得 500 美元奖励。为了支持开发者社区,Qwen2.5-7B 目前在 Novita AI 上免费提供。

Qwen2.5-7B 是一款面向通用任务的多功能开源 LLM,在性能与效率之间取得了良好平衡。它支持超过 29 种语言,并拥有高达 128K 的上下文长度,可实现长文本推理和广泛的应用覆盖。
什么是 Qwen 2.5 7B?
Qwen 2.5 7B 是一款功能强大的中型开源语言模型,拥有 7.6B 参数,支持 128K 上下文,针对通用任务进行了优化。
模型概览
- 模型大小:7.61B 参数
- 开源状态:开源
- 架构:基于 RoPE、SwiGLU、RMSNorm 和 Attention QKV bias 的 Transformers
- 上下文长度:128K tokens
语言与多模态
- 支持的语言:支持超过 29 种多语言
- 多模态能力:仅文本到文本
训练详情
- 训练数据量:基于超过 18 万亿 tokens 的数据集进行训练
基准测试
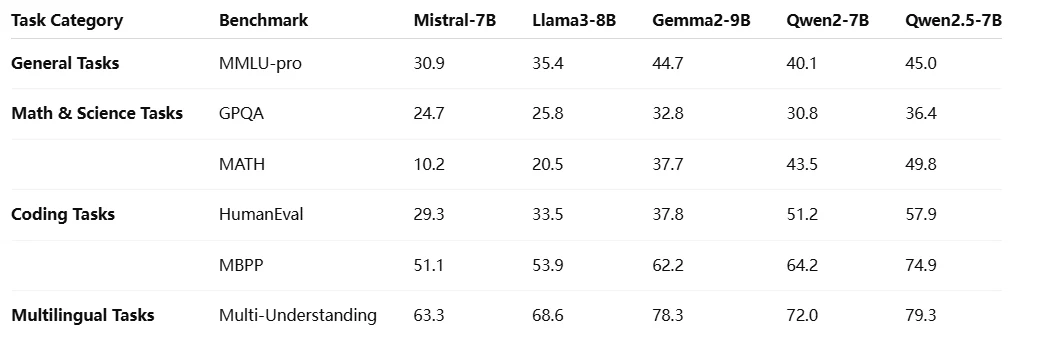
与其他 Qwen 2.5 模型对比
Qwen 2.5 系列 提供从 0.5B 到 72B 参数的可扩展模型,包括通用、编程和数学变体,旨在满足从轻量级部署到高性能 AI 应用的多样化需求。
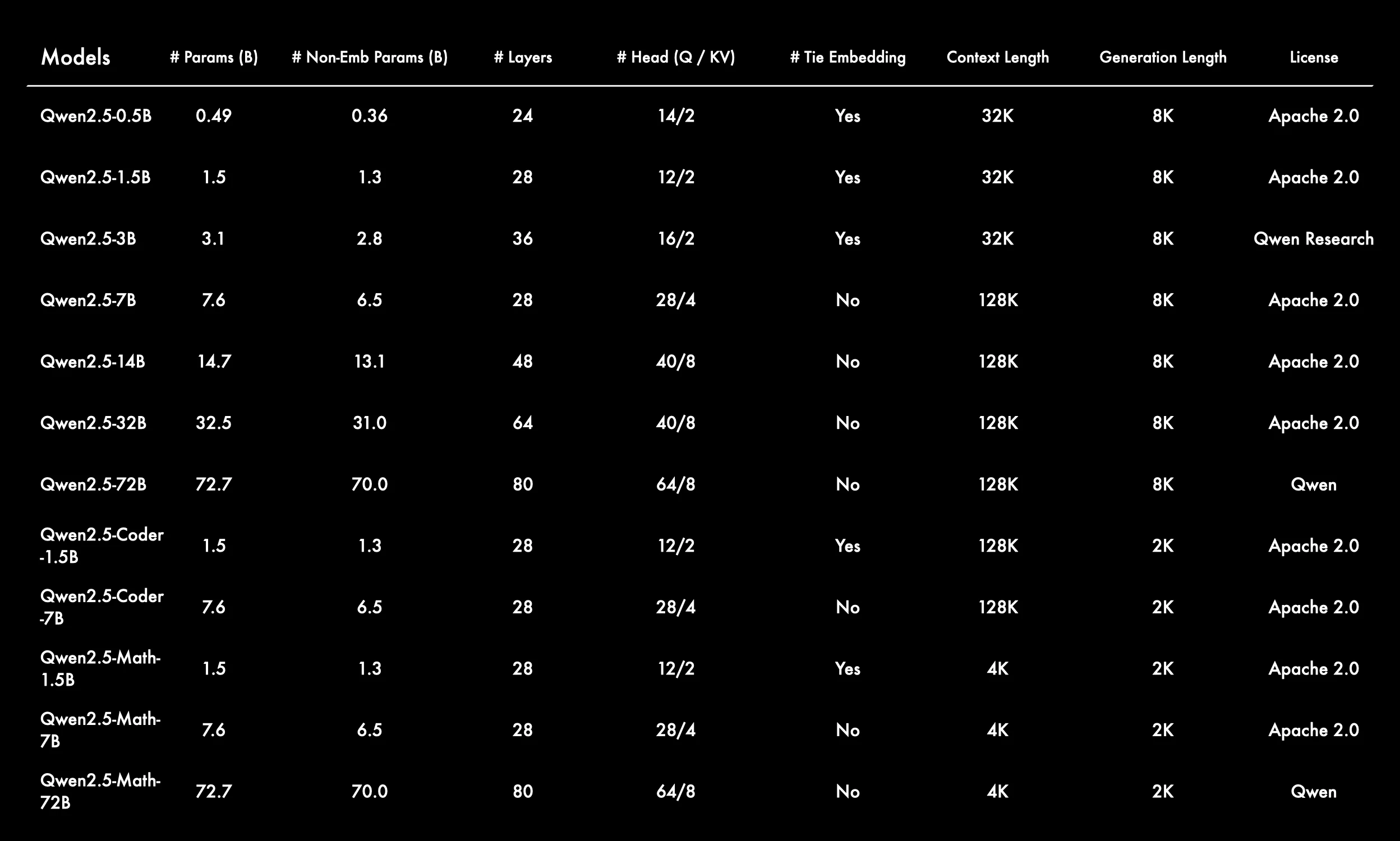
来自 Qwen
-
面向不同用例的广泛模型尺寸选择
Qwen 2.5 系列涵盖从 0.5B 到 72B 参数,包括通用、Coder 和 Math 变体——为不同任务和计算预算提供了灵活性。 -
较大模型拥有长上下文窗口
大多数模型支持 128K 或 32K 上下文长度,支持长文本推理和多轮对话。只有 Math 模型使用较短的 4K 上下文,以优化密集计算。 -
选择性地使用 Tie Embedding
较小和专用模型(如 1.5B 变体)启用了 tie embedding,这可能是为了减少参数量,而较大模型则禁用它以增强表示能力。 -
架构随模型大小可预测地扩展
- 层数:从 24 到 80
- 注意力头:从 14/2 到 64/8(Q/KV 拆分)
这体现了深度和宽度上的结构化缩放策略。
-
专用编程和数学模型具有更短的生成长度
这些模型使用 2K 生成长度,并针对代码生成或数学推理等特定领域任务进行了优化——更注重精度而非上下文跨度。
如何在本地访问 Qwen 2.5 7B
GPU 推荐
| **量化方式 ** | ** 模型大小 ** | ** 推荐 GPU** | **VRAM 需求 ** | ** 预估 GPU 成本(美元)** |
|---|---|---|---|---|
| FP16 | ~16.1 GB | 1× RTX 4090 (24GB) | ≥24 GB | ~$1,600–$1,800 |
| FP32 | ~32.2 GB | 2× RTX 4090 (24GB each) | ≥48 GB | ~$3,200–$3,600 |
| 4-bit (Q4) | ~4.02 GB | RTX 3060 (12GB) | ≥8 GB | ~$300–$350 |
快速开始
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # 加载模型的目标设备
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
虽然本地运行 Qwen2.5-7B 可以提供完全控制权和更快的响应速度,但购买高端 GPU(尤其是全精度 FP32 部署)的前期成本可能远高于按需付费的 API。对于预算有限的开发者或团队来说,API 访问通常是更具成本效益和可扩展性的解决方案。
如何通过 API 访问 Qwen 2.5 7B?
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云服务,用于构建和扩展应用。
你可以开始免费试用,探索所选模型的能力。安装后,将必要的库导入到你的开发环境中。使用你的 API 密钥初始化 API,即可开始与 Novita AI LLM 进行交互。以下是一个面向 Python 用户的聊天补全 API 示例。
直接 API 集成
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
使用 OpenAI Agents SDK 实现多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级的多智能体系统:
- 即插即用: 在任何 OpenAI Agents 工作流中使用 Novita AI 的 LLM。
- 支持交接、路由和工具使用: 设计能够委派、分类或执行函数的智能体,全部由 Novita AI 的模型提供支持。
- Python 集成: 只需将 SDK 指向 Novita 的端点(
https://api.novita.ai/v3/openai)并使用你的 API 密钥即可。
在第三方平台上
- Hugging Face:在 Spaces、pipeline 或使用 Transformers 库通过 Novita AI 端点使用 Qwen 3。
- 智能体与编排框架: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与 Continue、AnythingLLM、LangChain、Dify 和 Langflow 等合作伙伴平台连接。
- OpenAI 兼容 API: 享受与 Cline 和 Cursor 等工具的无缝迁移和集成,这些工具专为 OpenAI API 标准设计。
无论通过本地还是 API 方式运行 Qwen2.5-7B,开发者都能获得一套强大的工具。然而,**RTX 4090 等 GPU 的本地部署成本可能过高 **,这使得 Novita AI 的 API 集成成为大多数团队更明智且更具可扩展性的选择。
常见问题解答
如何在本地运行 Qwen 2.5 7B?
使用高端 GPU,如 RTX 4090。FP16 需要约 24GB VRAM,而 FP32 需要约 48GB。你还需要安装 Transformers 库,并使用 AutoModelForCausalLM 加载模型。
API 访问与本地运行相比如何?
API 访问消除了 GPU 的前期成本,并提供弹性扩展能力。本地部署可提供控制权,但全精度设置的成本要高得多。
如何通过 API 访问 Qwen 2.5 7B?
Novita AI 提供即插即用的 OpenAI 兼容 API。
Novita AI 是一个一站式云平台,助力你的 AI 抱负。集成 API、无服务器、GPU 实例——你所需的经济高效工具。无需管理基础设施,免费开始,让你的 AI 愿景成为现实。



