

주요 내용
Qwen2.5-7B 는 7.6B 파라미터, 128K 컨텍스트 지원, 강력한 범용 성능을 갖춘 중간 규모 오픈소스 LLM입니다.
Qwen2.5-7B는 GPU(예: RTX 4090)를 사용하여 로컬에 배포 할 수 있지만, FP32와 같은 고정밀 형식은 고비용 하드웨어가 필요합니다.
더 넓은 접근성을 위해 Novita AI를 통한 API 접근 은 확장 가능하고 비용 효율적인 대안을 제공하며, OpenAI SDK와 완전히 호환됩니다.
친구를 Novita AI에 추천하면 두 분 모두 LLM API 크레딧으로 $10를 받을 수 있습니다. 최대 $500까지 적립 가능합니다. 개발자 커뮤니티를 지원하기 위해 Qwen2.5-7B는 현재 Novita AI에서 무료로 제공됩니다.

Qwen2.5-7B는 범용 작업을 위해 설계된 다재다능한 오픈소스 LLM으로, 성능과 효율성의 균형을 맞췄습니다. 29개 이상의 언어와 방대한 128K 컨텍스트 길이를 지원하여 장문 추론과 폭넓은 애플리케이션 적용이 가능합니다.
Qwen 2.5 7B란?
Qwen 2.5 7B 는 7.6B 파라미터를 가진 강력한 중간 규모 오픈소스 언어 모델로, 128K 컨텍스트를 지원하며 범용 작업에 최적화되었습니다.
모델 개요
- 모델 크기: 7.61B 파라미터
- 오픈소스: 공개
- 아키텍처: RoPE, SwiGLU, RMSNorm, Attention QKV bias를 사용하는 Transformers
- 컨텍스트 길이: 128 토큰
언어 및 멀티모달
- 지원 언어: 29개 이상의 다국어 지원
- 멀티모달 기능: 텍스트-텍스트 전용
학습 세부 정보
- 학습 데이터 양: 18조 개 이상의 토큰으로 구성된 데이터셋으로 학습
벤치마크
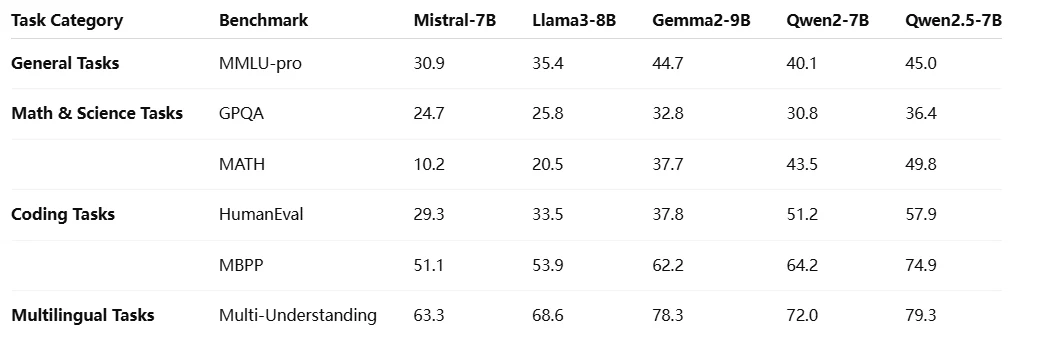
다른 Qwen 2.5 모델과의 비교
Qwen 2.5 시리즈 는 0.5B에서 72B 파라미터까지 확장 가능한 모델 제품군을 제공하며, 일반, 코딩, 수학 변형을 포함하여 경량 배포부터 고성능 AI 애플리케이션까지 다양한 요구 사항을 충족하도록 설계되었습니다.
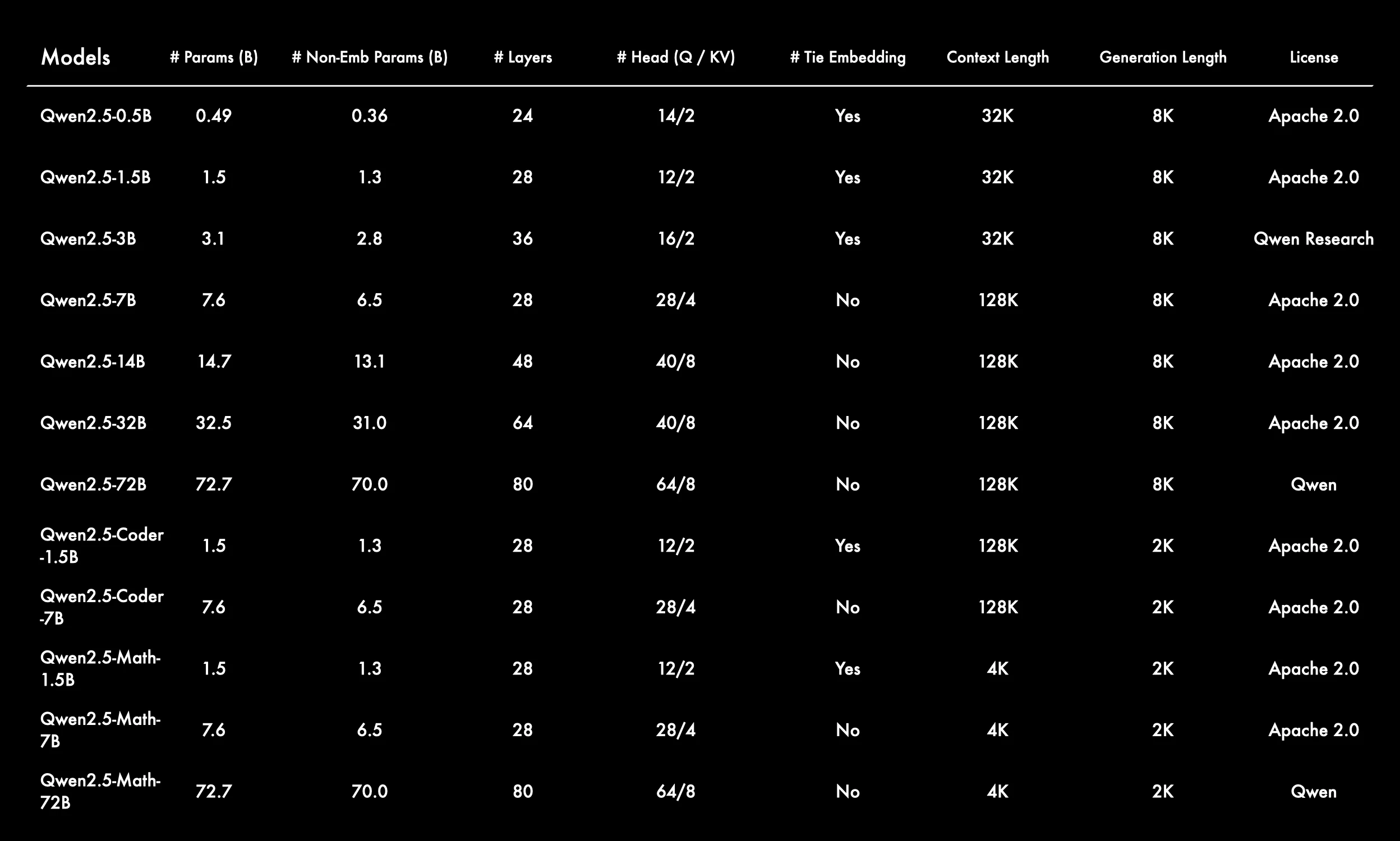
출처: Qwen
- 다양한 사용 사례를 위한 폭넓은 모델 크기
Qwen 2.5 시리즈는 0.5B에서 72B 파라미터까지 범용, Coder, Math 변형을 포함하여 다양한 작업과 컴퓨팅 예산에 맞는 유연성을 제공합니다. - 더 큰 모델은 긴 컨텍스트 윈도우 지원
대부분의 모델은 128K 또는 32K 컨텍스트 길이를 지원하여 장문 추론과 다중 턴 대화가 가능합니다. Math 모델만 밀집 계산에 최적화된 더 짧은 4K 컨텍스트를 사용합니다. - 선택적 Tie Embedding 사용
Tie embedding은 소형 및 특수 모델(예: 1.5B 변형)에서 활성화되어 파라미터 수를 줄이는 반면, 대형 모델에서는 표현력을 높이기 위해 비활성화됩니다. - 모델 크기에 따라 예측 가능하게 확장되는 아키텍처
- 레이어: 24개에서 최대 80개
- 어텐션 헤드: 14/2에서 64/8(Q/KV 분할)
이는 깊이와 너비가 증가하는 구조적 확장 전략을 반영합니다.
- 특수 Coder 및 Math 모델은 더 짧은 생성 길이 사용
이 모델들은 2K 생성 길이 를 사용하며 코드 생성이나 수학적 추론 같은 도메인별 작업에 최적화되어 컨텍스트 범위보다 정밀도를 우선시합니다.
로컬에서 Qwen 2.5 7B에 접근하는 방법
GPU 권장 사항
| **양자화 ** | ** 모델 크기 ** | ** 권장 GPU** | **VRAM 요구 사항 ** | ** 예상 GPU 비용 (USD)** |
|---|---|---|---|---|
| FP16 | ~16.1 GB | 1× RTX 4090 (24GB) | ≥24 GB | ~$1,600–$1,800 |
| FP32 | ~32.2 GB | 2× RTX 4090 (24GB each) | ≥48 GB | ~$3,200–$3,600 |
| 4-bit (Q4) | ~4.02 GB | RTX 3060 (12GB) | ≥8 GB | ~$300–$350 |
빠른 시작
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Qwen2.5-7B를 로컬에서 실행하면 완전한 제어와 빠른 응답 시간을 제공하지만, 특히 전체 정밀도(FP32) 배포를 위한 고급 GPU 구매 비용은 종량제 API 사용보다 훨씬 높을 수 있습니다. 예산이 제한된 개발자나 팀에게 API 접근은 훨씬 더 비용 효율적이고 확장 가능한 솔루션임이 드러납니다.
API를 통해 Qwen 2.5 7B에 접근하는 방법
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 또한 저렴하고 안정적인 GPU 클라우드를 제공하여 구축과 확장을 지원합니다.
선택한 모델의 기능을 탐색하기 위해 무료 체험판을 시작할 수 있습니다. 설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키를 사용하여 API를 초기화하면 Novita AI LLM과 상호 작용을 시작할 수 있습니다. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
직접 API 통합
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
OpenAI Agents SDK를 사용한 멀티 에이전트 워크플로우
Novita AI를 OpenAI Agents SDK와 통합하여 고급 멀티 에이전트 시스템을 구축하세요:
- 플러그 앤 플레이: 모든 OpenAI Agents 워크플로우에서 Novita AI의 LLM을 사용하세요.
- 핸드오프, 라우팅, 도구 사용 지원: Novita AI의 모델을 기반으로 위임, 분류 또는 함수 실행이 가능한 에이전트를 설계하세요.
- Python 통합: SDK를 Novita 엔드포인트(
https://api.novita.ai/v3/openai)에 연결하고 API 키를 사용하기만 하면 됩니다.
타사 플랫폼에서
- Hugging Face: Novita AI 엔드포인트를 통해 Spaces, 파이프라인 또는 Transformers 라이브러리에서 Qwen 3를 사용하세요.
- 에이전트 및 오케스트레이션 프레임워크: Continue, AnythingLLM, LangChain, Dify, Langflow와 같은 파트너 플랫폼을 공식 커넥터와 단계별 통합 가이드를 통해 쉽게 연결하세요.
- OpenAI 호환 API: Cline 및 Cursor와 같은 OpenAI API 표준에 맞춰 설계된 도구와 번거로움 없는 마이그레이션 및 통합을 누리세요.
Qwen2.5-7B를 로컬에서 또는 API를 통해 실행할 때, 개발자는 강력한 도구 세트에 접근할 수 있습니다. 그러나 **RTX 4090과 같은 GPU의 로컬 배포 비용 ** 은 부담스러울 수 있으므로, Novita AI의 API 통합이 대부분의 팀에게 더 현명하고 확장 가능한 선택 입니다.
자주 묻는 질문
Qwen 2.5 7B를 로컬에서 어떻게 실행하나요?
RTX 4090과 같은 고급 GPU를 사용하세요. FP16은 약 24GB VRAM이 필요하고, FP32는 약 48GB가 필요합니다. Transformers 라이브러리를 설치하고 AutoModelForCausalLM으로 모델을 로드해야 합니다.
API 접근이 로컬 실행과 어떻게 비교되나요?
API 접근은 선불 GPU 비용이 없으며 탄력적인 확장성을 제공합니다. 로컬 배포는 제어권을 제공하지만 전체 정밀도 설정에서는 훨씬 더 비쌉니다.
API를 통해 Qwen 2.5 7B에 어떻게 접근하나요?
Novita AI는 플러그 앤 플레이 방식의 OpenAI 호환 API를 제공합니다.
Novita AI는 AI 비전을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 비용 효율적인 도구. 인프라를 없애고, 무료로 시작하여 AI 비전을 현실로 만드세요.



