

Puntos Clave
Qwen2.5-7B es un LLM de código abierto de tamaño medio con 7.6B parámetros, soporte de contexto de 128K y un rendimiento robusto para uso general.
Qwen2.5-7B se puede implementar localmente con GPUs (p. ej., RTX 4090), pero los formatos de alta precisión como FP32 requieren configuraciones de hardware costosas.
Para una mayor accesibilidad, el acceso vía API a través de Novita AI ofrece una alternativa escalable y rentable, completamente compatible con el SDK de OpenAI.
Recomienda a tus amigos Novita AI y ambos ganarán $10 en créditos de API LLM, hasta $500 en recompensas totales. Para apoyar a la comunidad de desarrolladores, Qwen2.5-7B está actualmente disponible de forma gratuita en Novita AI.

Qwen2.5-7B es un LLM de código abierto versátil diseñado para tareas generales, equilibrando potencia y eficiencia. Con soporte para más de 29 idiomas y una longitud de contexto masiva de 128K, permite razonamiento de formato largo y una amplia cobertura de aplicaciones.
¿Qué es Qwen 2.5 7B?
Qwen 2.5 7B es un potente modelo de lenguaje de código abierto de tamaño medio con 7.6 mil millones de parámetros, soporta contexto de 128K y está optimizado para tareas de propósito general.
Resumen del Modelo
- Tamaño del modelo: 7.61B parámetros
- Código abierto: Sí
- Arquitectura: Transformers con RoPE, SwiGLU, RMSNorm y sesgo Attention QKV
- Longitud de contexto: 128 tokens
Idiomas y Multimodal
- Idiomas compatibles: Soporta más de 29 idiomas multilingües
- Capacidad multimodal: Solo texto a texto
Detalles de Entrenamiento
- Volumen de datos de entrenamiento: Entrenado en un conjunto de datos que comprende más de 18 billones de tokens
Benchmark
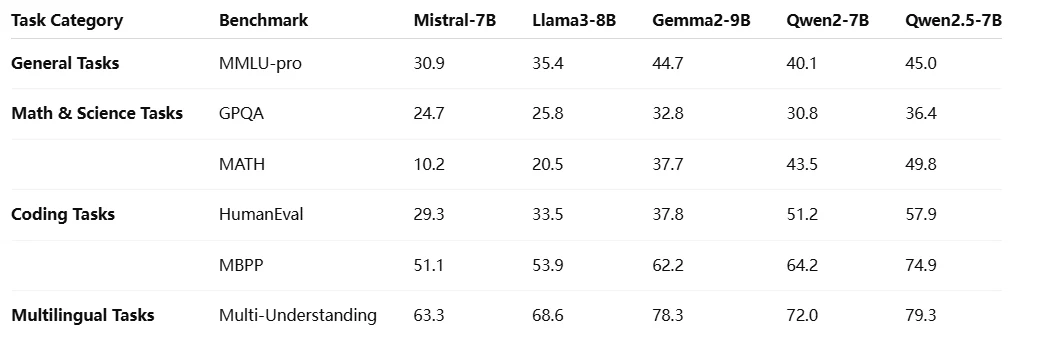
Comparación con Otros Modelos Qwen 2.5
La serie Qwen 2.5 ofrece una familia escalable de modelos que van desde 0.5B hasta 72B parámetros, incluyendo variantes generales, de codificación y matemáticas, diseñadas para satisfacer diversas necesidades, desde implementación ligera hasta aplicaciones de IA de alto rendimiento.
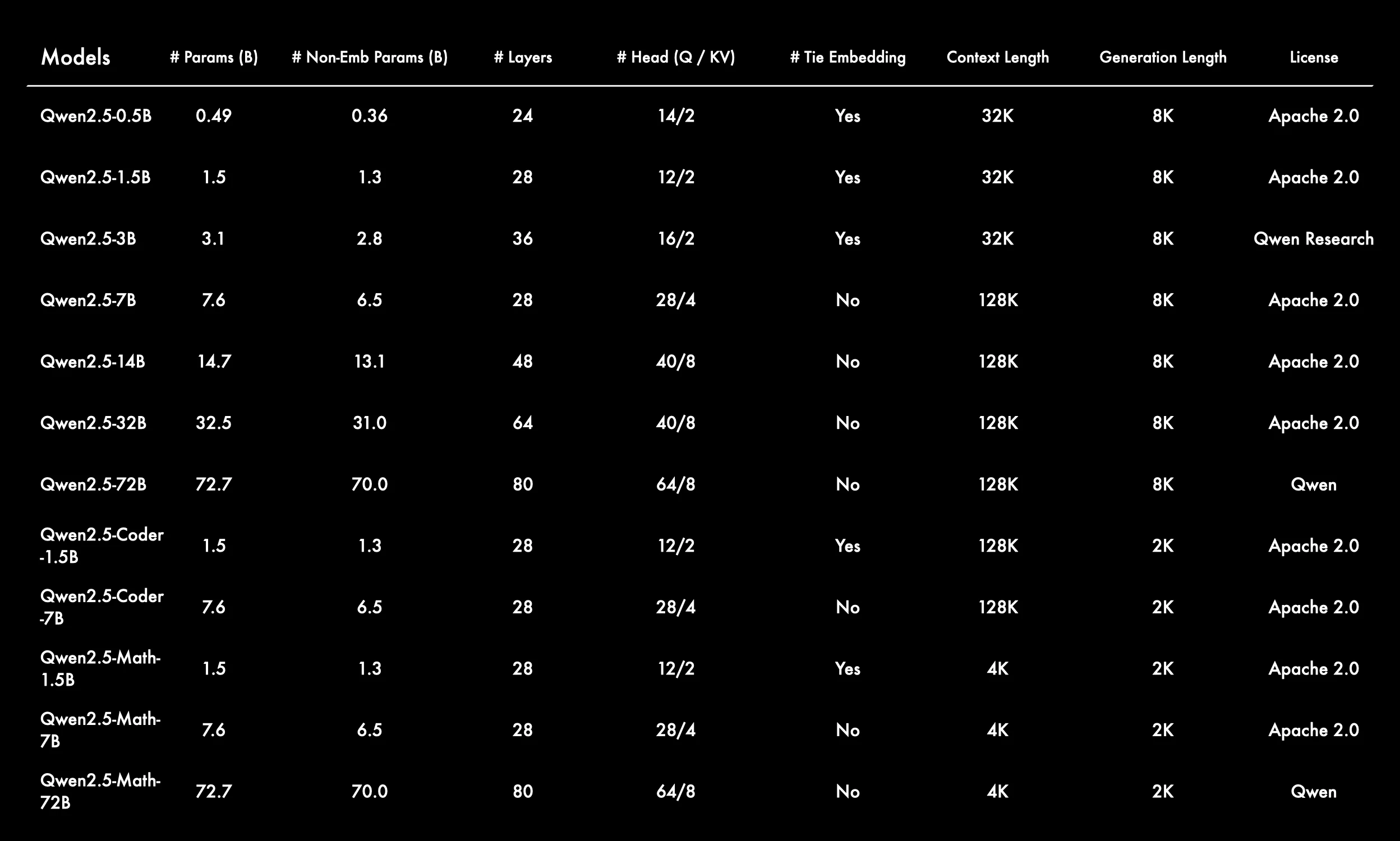
De Qwen
- Amplia gama de tamaños de modelo para diferentes casos de uso
La serie Qwen 2.5 abarca desde 0.5B hasta 72B parámetros, incluyendo variantes de propósito general, Coder y Math, brindando flexibilidad para diversas tareas y presupuestos computacionales. - Modelos más grandes con ventanas de contexto largas
La mayoría de los modelos soportan longitudes de contexto de 128K o 32K, lo que permite razonamiento de formato largo y conversaciones de múltiples turnos. Solo los modelos matemáticos utilizan contextos más cortos de 4K, optimizados para cálculos densos. - Tie Embedding usado selectivamente
Tie embedding está habilitado para modelos más pequeños y especializados (por ejemplo, variantes de 1.5B), probablemente para reducir el número de parámetros, mientras que los modelos más grandes lo deshabilitan para mejorar la potencia de representación. - La arquitectura escala predeciblemente con el tamaño del modelo
- Capas: de 24 hasta 80
- Cabezas de atención: de 14/2 a 64/8 (división Q/KV)
Esto refleja una estrategia de escalado estructurado con profundidad y anchura crecientes.
- Los modelos Coder y Math especializados tienen longitudes de generación más cortas
Estos modelos utilizan una longitud de generación de 2K y están optimizados para tareas específicas del dominio, como generación de código o razonamiento matemático, favoreciendo la precisión sobre el alcance del contexto.
Cómo Acceder a Qwen 2.5 7B Localmente
Recomendaciones de GPU
| Cuantización | Tamaño del modelo | GPU recomendada | Requisito de VRAM | Costo estimado de GPU (USD) |
|---|---|---|---|---|
| FP16 | ~16.1 GB | 1× RTX 4090 (24GB) | ≥24 GB | ~$1,600–$1,800 |
| FP32 | ~32.2 GB | 2× RTX 4090 (24GB cada una) | ≥48 GB | ~$3,200–$3,600 |
| 4-bit (Q4) | ~4.02 GB | RTX 3060 (12GB) | ≥8 GB | ~$300–$350 |
Inicio Rápido
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Si bien ejecutar Qwen2.5-7B localmente ofrece control total y tiempos de respuesta más rápidos, el costo inicial de adquirir GPUs de alta gama—especialmente para implementación de precisión completa (FP32)—puede ser significativamente mayor que usar una API de pago por uso. Para desarrolladores o equipos con presupuestos limitados, el acceso vía API suele ser una solución mucho más rentable y escalable.
¿Cómo Acceder a Qwen 2.5 7B a Través de API?
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.
Puedes comenzar tu prueba gratuita para explorar las capacidades del modelo seleccionado. Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
¡Prueba el Demo de Qwen 2.5 7B Ahora!
Integración Directa de API
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Flujos de Trabajo Multi-Agente con el SDK de OpenAI Agents
Construye sistemas multi-agente avanzados integrando Novita AI con el OpenAI Agents SDK:
- Plug-and-play: Usa los LLM de Novita AI en cualquier flujo de trabajo de OpenAI Agents.
- Soporta traspasos, enrutamiento y uso de herramientas: Diseña agentes que puedan delegar, clasificar o ejecutar funciones, todo impulsado por los modelos de Novita AI.
- Integración en Python: Simplemente apunta el SDK al endpoint de Novita (
https://api.novita.ai/v3/openai) y usa tu clave de API.
En Plataformas de Terceros
- Hugging Face: Usa Qwen 3 en Spaces, pipelines, o con la biblioteca Transformers a través de endpoints de Novita AI.
- Frameworks de Agentes y Orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
- API Compatible con OpenAI: Disfruta de una migración e integración sin problemas con herramientas como Cline y Cursor, diseñadas para el estándar de API de OpenAI.
Ya sea ejecutando Qwen2.5-7B localmente o a través de API, los desarrolladores obtienen acceso a un potente conjunto de herramientas. Sin embargo, los costos de implementación local para GPUs como RTX 4090 pueden ser prohibitivos, lo que hace que la integración de API de Novita AI sea una opción más inteligente y escalable para la mayoría de los equipos.
Preguntas Frecuentes
¿Cómo puedo ejecutar Qwen 2.5 7B localmente?
Usa una GPU de alta gama como una RTX 4090. FP16 requiere ~24GB de VRAM, mientras que FP32 necesita ~48GB. También necesitarás instalar la biblioteca Transformers y cargar el modelo con AutoModelForCausalLM.
¿Cómo se compara el acceso por API con ejecutar el modelo localmente?
El acceso por API elimina los costos iniciales de GPU y ofrece escalabilidad elástica. La implementación local ofrece control pero es mucho más costosa para configuraciones de precisión completa.
¿Cómo acceder a Qwen 2.5 7B a través de API?
Novita AI proporciona una API plug-and-play compatible con OpenAI.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancia de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



