

Key Highlights
QwQ 32B: A powerful, large-scale model (32B parameters) ideal for enterprise-grade coding, complex workflows, and backend AI services.
Qwen 2.5 7B: A lightweight, highly optimized model excelling at math reasoning, coding assistance, and local deployments.
Performance: QwQ 32B provides production-grade robustness; Qwen 2.5 7B offers compact, user-friendly outputs.
Hardware: QwQ 32B requires server-level GPUs; Qwen 2.5 7B runs smoothly on desktop GPUs.
Application Fit: QwQ 32B is best for heavy-duty backend tasks; Qwen 2.5 7B is perfect for personal tools, lightweight apps, and research.
Access: Both models are available for free trial on Novita AI, with easy API integration for developers.
When choosing between QwQ 32B and Qwen 2.5 7B, understanding their core strengths is crucial. QwQ 32B offers robust capabilities for large-scale, high-load applications, while Qwen 2.5 7B focuses on providing agile, math-optimized solutions with minimal hardware requirements. In this comparison, we explore their benchmarks, hardware demands, coding performance, and application suitability to help you select the best model for your needs.
QwQ 32B vs Qwen 2.5 7B: Basic Introduction
QwQ 32B Introduction
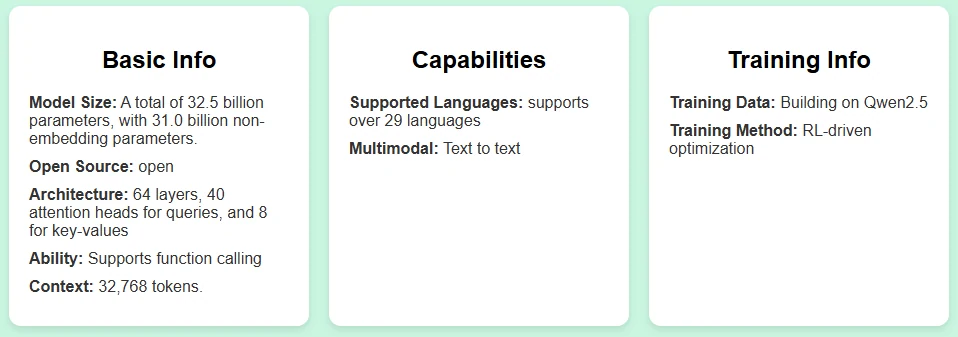
Qwen 2.5 7B Introduction

QwQ 32B vs Qwen 2.5 7B: Benchmark
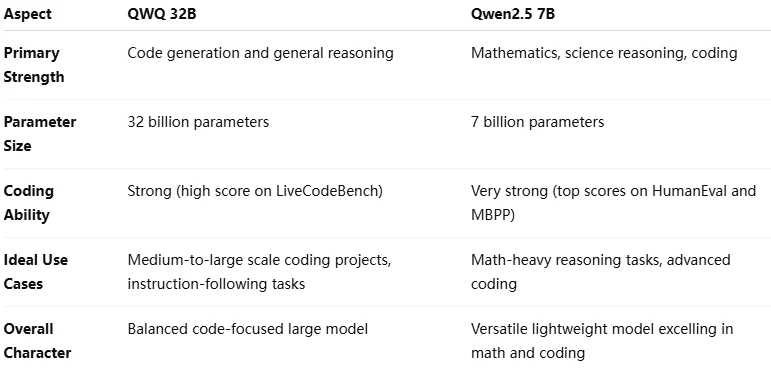
If you want to test it yourself, you can start a free trial on the Novita AI website.

Try QwQ 32B and Qwen 2.5 7B Demo Now!
QwQ 32B vs Qwen 2.5 7B: Hardware Requirements

If you’re looking for local flexibility, Qwen2.5-7B wins hands down. If you need maximum power and can afford server-grade GPUs, QWQ 32B is your pick.
QwQ 32B vs Qwen 2.5 7B: Applications
QwQ 32B
Large-Scale Coding Projects:
With its 32 billion parameters, QWQ 32B is highly capable of handling complex, multi-layered coding tasks. It is an ideal choice for building advanced software development assistants or managing extensive codebases automatically.
Complex Instruction-Following Systems:
QWQ 32B excels at interpreting detailed, multi-step instructions, making it suitable for constructing enterprise-level virtual agents, process automation tools, or customer service bots requiring intricate workflows.
High-Load Backend Services:
Thanks to its large memory requirements and powerful reasoning capabilities, QWQ 32B fits well in environments that demand continuous high-volume AI tasks — such as content generation platforms, intelligent database management, or AI-driven operations centers.
Qwen 2.5 7B
Personal Coding Assistants:
Qwen2.5 7B offers excellent coding capabilities while maintaining a compact model size. It is perfect for developers who want to run intelligent code suggestion or bug-fixing assistants locally on a single GPU.
Math-Heavy Reasoning Tools:
With outstanding performance in mathematical benchmarks, Qwen2.5 7B is ideal for educational AI tools, computational research support, or tutoring systems focused on math and science topics.
Lightweight Chatbots and Assistants:
Thanks to its low resource requirements (running smoothly even on mid-range GPUs with quantization), Qwen2.5 7B is well-suited for lightweight conversational agents, personal productivity bots, or embedded AI features in applications.
QwQ 32B vs Qwen 2.5 7B: Tasks
Prompt:
A password is considered strong if the below conditions are all met:
- It has at least 6 characters and at most 20 characters.
- It contains at least one lowercase letter, at least one uppercase letter, and at least one digit.
- It does not contain three repeating characters in a row (i.e., "Baaabb0" is weak, but "Baaba0" is strong).
Given a string password, return the minimum number of steps required to make password strong. if password is already strong, return 0.
In one step, you can:
- Insert one character to password,
- Delete one character from password, or
- Replace one character of password with another character.
Example 1:
Input: password = "a"
Output: 5
Example 2:
Input: password = "aA1"
Output: 3
Example 3:
Input: password = "1337C0d3"
Output: 0
Constraints:
1 <= password.length <= 50
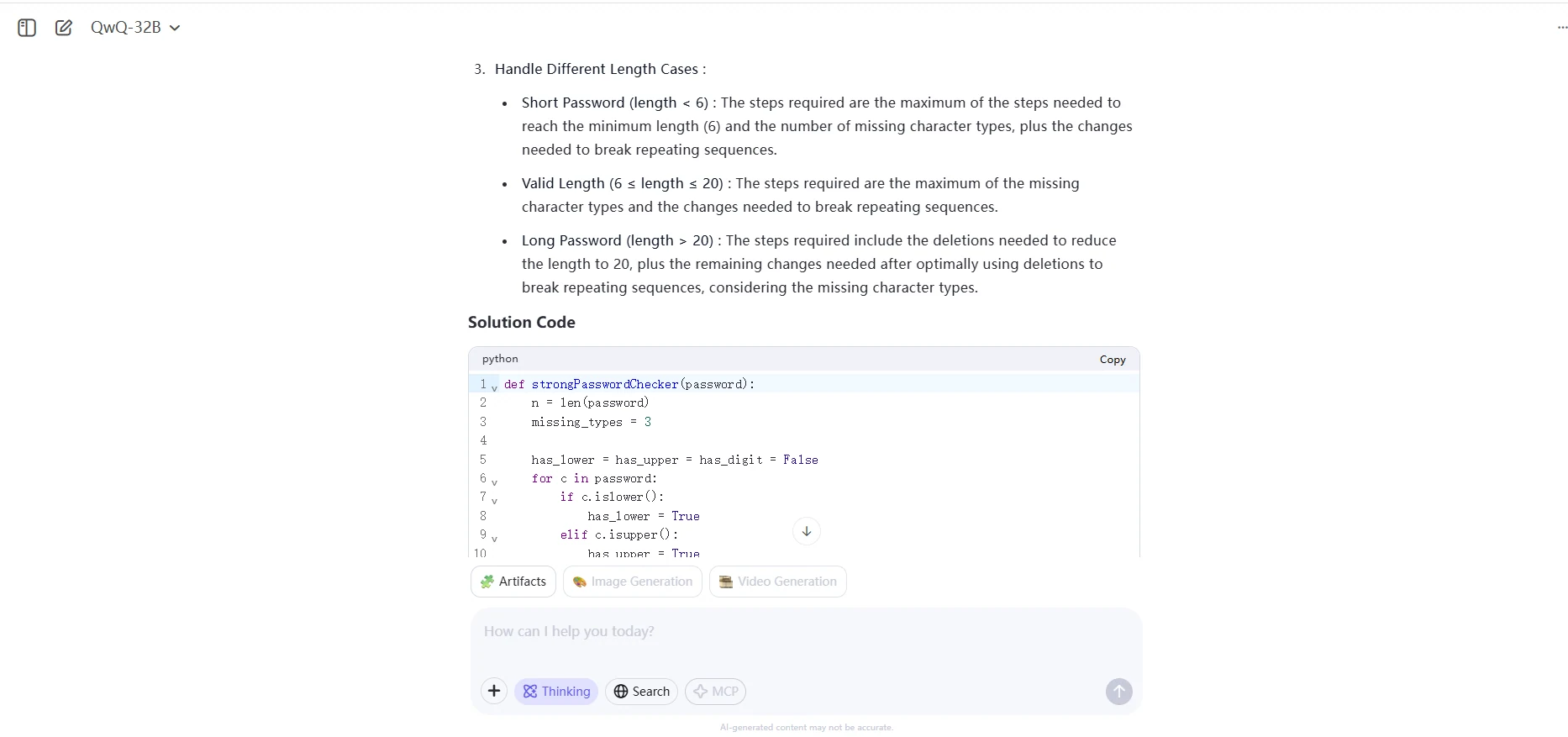
password consists of letters, digits, dot '.' or exclamation mark '!'.QwQ 32B
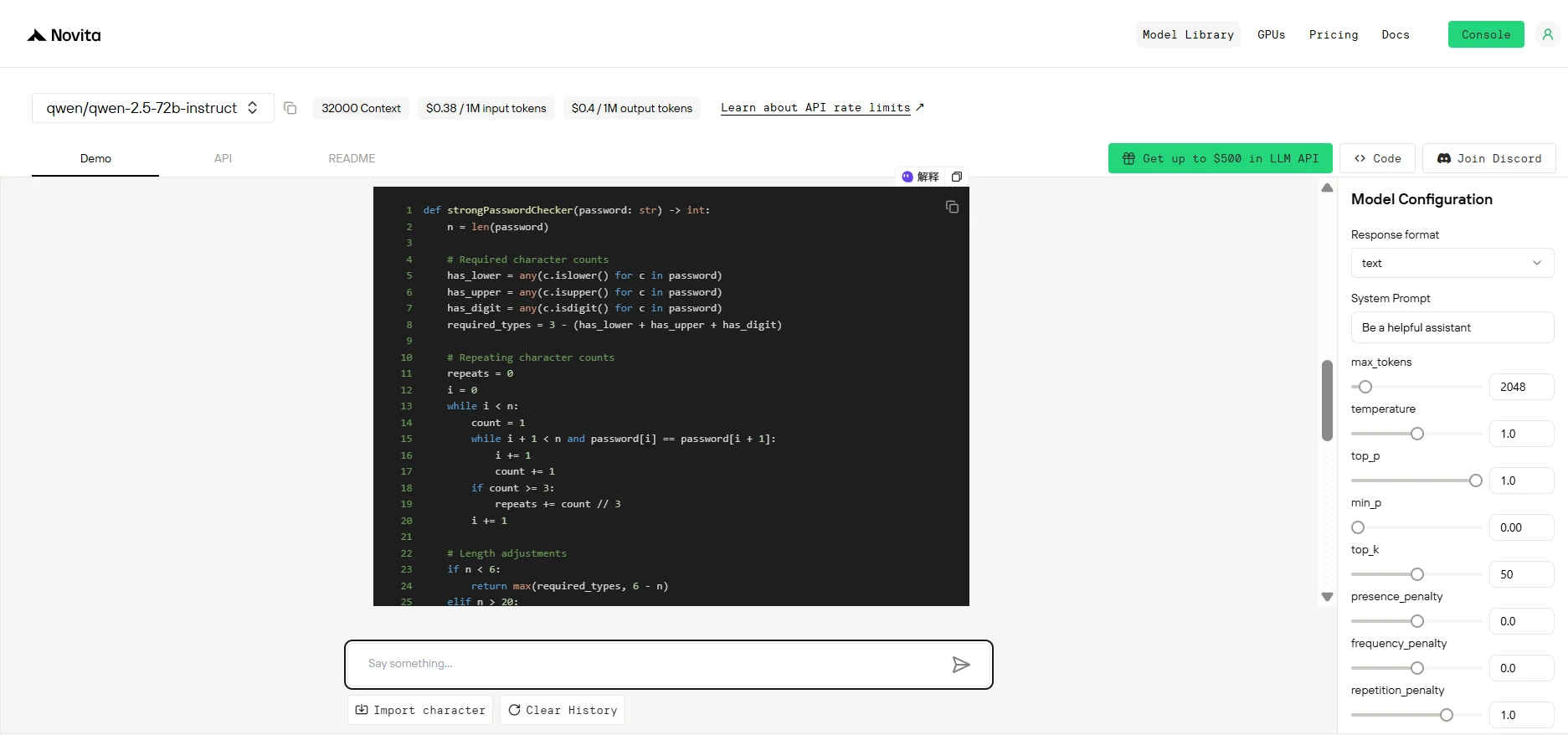
Qwen 2.5 7B
QWQ 32B generated a very thorough, production-grade solution — best suited when clarity and full edge case control are priorities.
Qwen2.5 7B produced a cleaner, user-friendly version with examples, making it highly practical for tutorials, quick demos, or lightweight applications.
How to Access QwQ 32B and Qwen 2.5 7B via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwq-32b"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
QwQ 32B and Qwen 2.5 7B each shine in their own right. If you require enterprise-level AI power and can invest in server-grade hardware, QwQ 32B is the clear choice. However, if flexibility, lightweight deployment, and cost-efficiency matter most, Qwen 2.5 7B delivers exceptional value.
Frequently Asked Questions
What is the main difference between QwQ 32B vs Qwen 2.5 7B?
QwQ 32B is a large-scale, high-performance model suited for enterprise deployments, while Qwen 2.5 7B is lightweight, efficient, and perfect for local development and research projects.
Which model is better for local deployment, QwQ 32B or Qwen 2.5 7B?
Qwen 2.5 7B is more suitable for local deployment, running easily on a single RTX 4090 or even mid-range GPUs after quantization.
Can I try QwQ 32B and Qwen 2.5 7B for free?
Yes! You can access free trials for both models via Novita AI’s platform and integrate them easily into your development workflow through the API.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



