

Ключевые моменты
Qwen2.5-7B — это средняя open-source LLM с 7,6 млрд параметров, поддержкой контекста в 128K и высокой производительностью для общих задач.
Qwen2.5-7B можно развернуть локально на GPU (например, RTX 4090), но форматы высокой точности, такие как FP32, требуют дорогостоящего оборудования.
Для более широкой доступности доступ по API через Novita AI предлагает масштабируемую и экономичную альтернативу, полностью совместимую с SDK OpenAI.
Пригласите друзей в Novita AI, и вы оба получите по $10 в виде кредитов на LLM API — до $500 суммарного вознаграждения. Для поддержки сообщества разработчиков Qwen2.5-7B сейчас доступна бесплатно на Novita AI.

Qwen2.5-7B — это универсальная open-source LLM, разработанная для общих задач, сочетающая мощность и эффективность. С поддержкой более 29 языков и огромным контекстом в 128K она позволяет выполнять длинные рассуждения и охватывать широкий круг задач.
Что такое Qwen 2.5 7B?
Qwen 2.5 7B — это мощная средняя open-source языковая модель с 7,6 млрд параметров, поддерживающая контекст в 128K и оптимизированная для задач общего назначения.
Обзор модели
- Размер модели: 7,61 млрд параметров
- Открытый исходный код: Да
- Архитектура: Transformers с RoPE, SwiGLU, RMSNorm и Attention QKV bias
- Длина контекста: 128 токенов
Языки и мультимодальность
- Поддерживаемые языки: Более 29 языков
- Мультимодальные возможности: Только текст-в-текст
Детали обучения
- Объем обучающих данных: Обучен на наборе данных объемом более 18 триллионов токенов
Бенчмарки
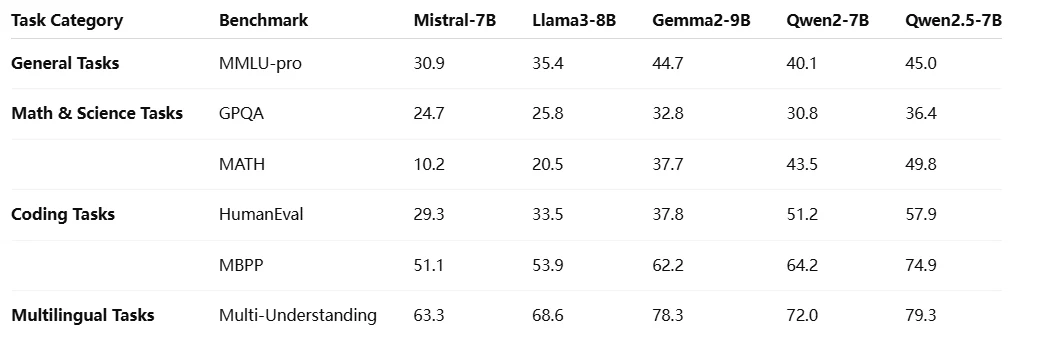
Сравнение с другими моделями Qwen 2.5
Серия Qwen 2.5 предлагает масштабируемое семейство моделей от 0,5B до 72B параметров, включая общие, для кодинга и математические варианты, предназначенные для различных задач — от легковесного развертывания до высокопроизводительных AI-приложений.
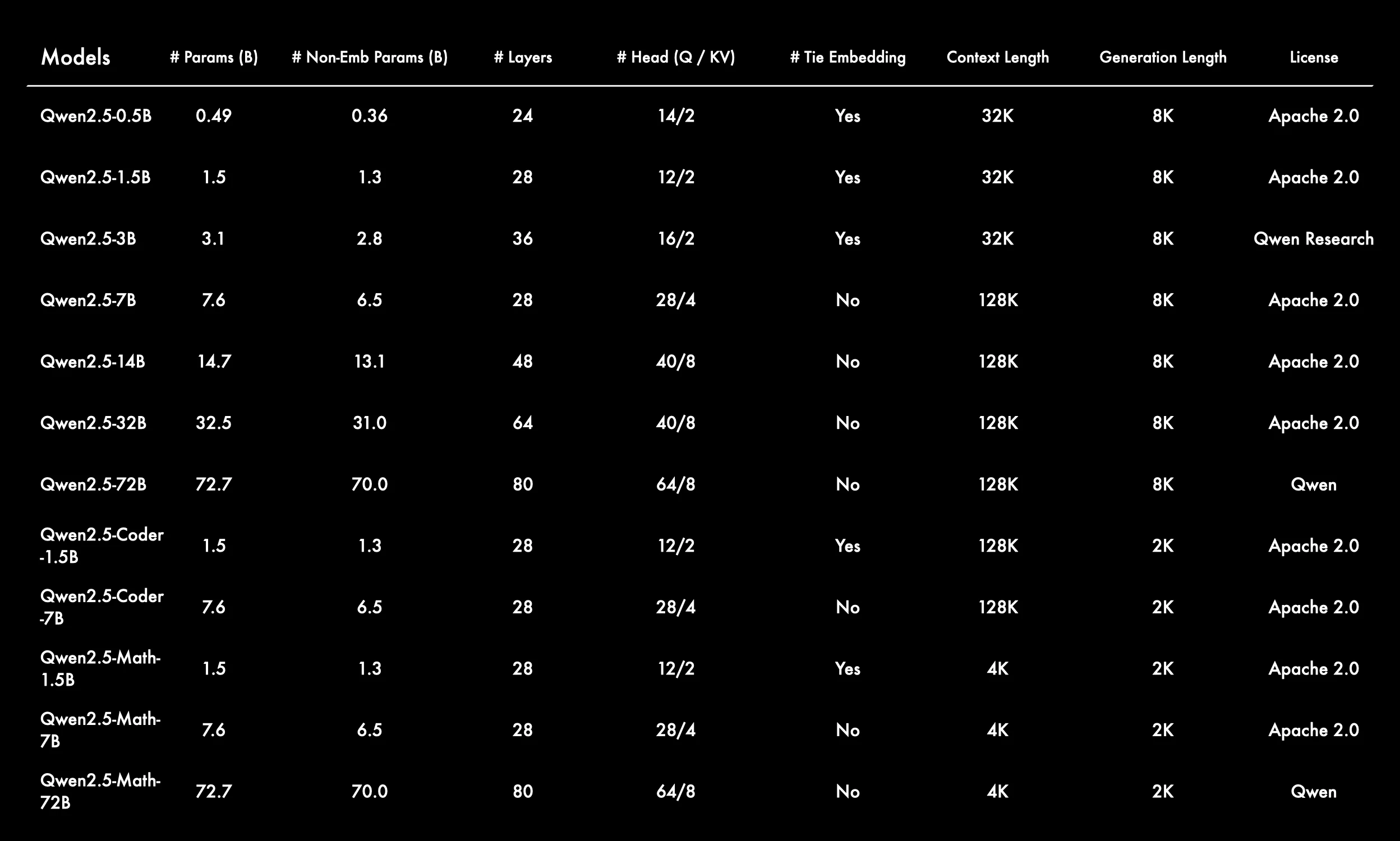
Источник: Qwen
-
Широкий диапазон размеров моделей для разных сценариев использования
Серия Qwen 2.5 охватывает размеры от 0,5B до 72B параметров, включая варианты общего назначения, Coder и Math — обеспечивая гибкость для разнообразных задач и вычислительных бюджетов. -
Крупные модели обладают длинными окнами контекста
Большинство моделей поддерживают длину контекста 128K или 32K, что позволяет выполнять длинные рассуждения и многошаговые диалоги. Только математические модели используют более короткий контекст 4K, оптимизированный для плотных вычислений. -
Tie Embedding используется выборочно
Tie embedding включен для меньших и специализированных моделей (например, варианты 1.5B), вероятно, для уменьшения количества параметров, тогда как в больших моделях он отключен для повышения выразительности. -
Архитектура предсказуемо масштабируется с размером модели
- Слои: от 24 до 80
- Головы внимания: от 14/2 до 64/8 (разделение Q/KV)
Это отражает структурированную стратегию масштабирования с увеличением глубины и ширины.
-
Специализированные модели Coder и Math имеют меньшую длину генерации
Эти модели используют длину генерации 2K и оптимизированы для специфичных доменов, таких как генерация кода или математические рассуждения — отдавая предпочтение точности перед длиной контекста.
Как получить доступ к Qwen 2.5 7B локально
Рекомендации по GPU
| Квантование | Размер модели | Рекомендуемый GPU | Требования к VRAM | Примерная стоимость GPU (USD) |
|---|---|---|---|---|
| FP16 | ~16.1 GB | 1× RTX 4090 (24GB) | ≥24 GB | ~$1,600–$1,800 |
| FP32 | ~32.2 GB | 2× RTX 4090 (24GB each) | ≥48 GB | ~$3,200–$3,600 |
| 4-bit (Q4) | ~4.02 GB | RTX 3060 (12GB) | ≥8 GB | ~$300–$350 |
Быстрый старт
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Хотя локальный запуск Qwen2.5-7B дает полный контроль и более быстрое время отклика, первоначальные затраты на покупку высокопроизводительных GPU (особенно для полноточной точности FP32) могут быть значительно выше, чем использование модели по принципу «плати по мере использования» через API. Для разработчиков или команд с ограниченным бюджетом доступ через API часто оказывается гораздо более экономичным и масштабируемым решением.
Как получить доступ к Qwen 2.5 7B через API?
Novita AI — это облачная платформа AI, которая предоставляет разработчикам простой способ развертывания AI-моделей через наш простой API, а также предлагает доступное и надежное облако GPU для создания и масштабирования.
Вы можете начать бесплатный пробный период, чтобы изучить возможности выбранной модели. После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Это пример использования chat completions API для пользователей Python.
Попробовать Qwen 2.5 7B Demo сейчас!
Прямая интеграция API
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Многоагентные рабочие процессы с SDK агентов OpenAI
Создавайте продвинутые многоагентные системы, интегрируя Novita AI с OpenAI Agents SDK:
- Готово к использованию: Используйте LLM Novita AI в любых рабочих процессах OpenAI Agents.
- Поддерживает передачу, маршрутизацию и использование инструментов: Проектируйте агентов, которые могут делегировать, сортировать или выполнять функции, используя модели Novita AI.
- Интеграция с Python: Просто направьте SDK на endpoint Novita (
https://api.novita.ai/v3/openai) и используйте свой API-ключ.
На сторонних платформах
- Hugging Face: Используйте Qwen 3 в Spaces, пайплайнах или с библиотекой Transformers через endpoints Novita AI.
- Фреймворки агентов и оркестровки: Легко подключайте Novita AI к партнерским платформам, таким как Continue, AnythingLLM, LangChain, Dify и Langflow через официальные коннекторы и пошаговые руководства по интеграции.
- API, совместимый с OpenAI: Легкая миграция и интеграция с такими инструментами, как Cline и Cursor, разработанными под стандарт API OpenAI.
Независимо от того, запускаете ли вы Qwen2.5-7B локально или через API, разработчики получают доступ к мощному набору инструментов. Однако стоимость локального развертывания на GPU, таких как RTX 4090, может быть prohibitive, что делает интеграцию API Novita AI более разумным и масштабируемым выбором для большинства команд.
Часто задаваемые вопросы
Как запустить Qwen 2.5 7B локально?
Используйте высокопроизводительный GPU, например RTX 4090. FP16 требует ~24 ГБ VRAM, а FP32 — ~48 ГБ. Также необходимо установить библиотеку Transformers и загрузить модель с помощью AutoModelForCausalLM.
Как сравнить доступ через API с локальным запуском модели?
Доступ через API исключает первоначальные затраты на GPU и обеспечивает эластичную масштабируемость. Локальное развертывание дает контроль, но гораздо дороже при использовании полной точности.
Как получить доступ к Qwen 2.5 7B через API?
Novita AI предоставляет готовый API, совместимый с OpenAI.
Novita AI — это универсальная облачная платформа, которая расширяет ваши AI-амбиции. Интегрированные API, бессерверные решения, GPU-инстансы — экономичные инструменты, которые вам нужны. Устраните инфраструктурные сложности, начните бесплатно и воплотите свое AI-видение в реальность.



