

NVIDIA 的 H200 與 B200 GPU 是當前 AI 硬體領域最先進的兩款選擇,各自擁有獨特優勢,適用於推論與訓練的不同場景。本文將深入解析這兩款 GPU,梳理其優勢與適用場景,幫助你明確它們分別適合哪些 AI 工作負載。
H200 與 B200 功能對比
| 功能項 | 1 顆 H200 SXM | 1 顆 B200 |
| 架構 | Hooper | Blackwell |
| GPU 記憶體 | 141GB HBM3e | 192GB HBM3e |
| 記憶體頻寬 | 4.8TB/s | 8TB/s |
| Tensor Core | 最高 4 PFLOPS FP8 | 最高 5 PFLOPS FP8 與 9 PFLOPS FP4 |
H200 與 B200 核心優勢
1 顆 H200 SXM
- 高容量記憶體:H200 搭載 141GB HBM3e 記憶體與 4.8TB/s 頻寬,可容納遠超前代產品的大型數據集,這種高容量設計能最大程度減少記憶體瓶頸、提升數據傳輸效率,讓長上下文語言模型推論、科學模擬等複雜工作負載運行得更穩定高效,在處理高負載 AI 與高效能運算(HPC)任務時,也能實現更流暢的擴展與更穩定的效能表現。
- FP8 Tensor Core 效能:H200 最高可提供 4 PFLOPS 的 FP8 運算效能,大幅提升了 AI 工作負載的處理效率。FP8 在運算吞吐量與精度之間取得了實用平衡,非常適合生產級生成式 AI 場景;同時它在幾乎不犧牲精度的前提下實現更快的推論速度,讓 H200 成為開發者與企業大規模部署 AI 時的高效選擇。
- 推論優化架構:H200 的硬體設計側重低延遲與高能效推論,能支援從生成式 AI 模型到推薦引擎等即時應用場景的響應式 AI 系統;同時在保持強勁運算輸出的前提下降低功耗,為持續高負載推論任務提供了效能與效率的可靠平衡。
1 顆 B200
- 更大記憶體容量:B200 搭載 192GB HBM3e 記憶體,原始記憶體容量遠超 H200,這額外容量支援直接部署超大規模 AI 模型,無需進行模型分區或複雜的記憶體管理。對於需要處理超大數據集或超長序列上下文的工作負載,B200 能最大程度減少限制、簡化工作流程設計,讓開發者在擴展系統時擁有更大的靈活性。
- FP4 精度支援:FP4 Tensor Core 運算是 Blackwell 架構的標誌性創新之一,B200 首次支援該功能。FP4 大幅提升了吞吐量與能源效率,讓大規模訓練與推論能以更低的成本更快完成;同時在保留功能精度的前提下降低了運算開銷,這項突破能直接幫助追求模型規模與效能極限的組織。
- 前瞻性設計:B200 結合了大容量記憶體、更高頻寬與先進精度格式,其架構設計能適應 AI 模型持續複雜化的趨勢,避免快速過時。這套前瞻性設計能確保如今投資 B200 的研究團隊與企業,在未來數年內仍有足夠的運算餘量支援新興工作負載,它不僅是當前前沿模型的解決方案,更是下一代 AI 開發的穩定基礎。
儘管 B200 在記憶體、精度與可擴展性方面優勢明顯,H200 依然是強勁且實用的選擇。它以更易負擔的成本提供穩健的效能,是追求性價比、無需投入下一代系統高額成本的企業的均衡選擇。
H200 與 B200 應用場景
H200 SXM
- 生成式 AI 與大型語言模型(LLM):非常適合長上下文推論場景,可支援高級聊天機器人與內容生成應用。
- 高效能運算(HPC):頻寬驅動的效能可加速數據密集型的科學模擬與建模任務。
- 企業級推論:是大規模部署搜尋、推薦、對話式 AI 系統的可靠選擇。
B200
- 前沿 AI 開發:專為突破現有極限的尖端大型語言模型與多模態系統的訓練與推論設計。
- 企業級大規模部署:能為持續高吞吐量的 AI 平台提供所需的容量與運算餘量。
- 研究基礎設施:適合構建可擴展基礎設施、支援下一代 AI 模型開發的組織使用。
H200 與 B200 價格對比
| 顯卡 | 零售價區間 | 伺服器/企業套裝價格 | 雲端租賃價格 |
|---|---|---|---|
| NVIDIA H200 | $30,000 - $40,000 | 完整系統可超過 $500,000 | 每小時 $3.25(例如透過 Novita AI) |
| NVIDIA B200 | $45,000–$50,000 | 完整系統可超過 $500,000 | 每小時 $3.84 |
H200 與 B200 樹立了 GPU 效能的標杆,但對於追求成本與靈活性平衡的用戶而言,投資完整系統未必是最優選擇。GPU 實例剛好滿足這類需求——Novita AI 提供靈活的平台,幫助開發者與企業輕鬆擴展,讓這兩款旗艦顯卡比以往更易取得。
透過 Novita AI GPU 實例取得 H200 與 B200 的五大理由
1. 競爭力定價與靈活計費
定價:Novita AI vs RunPod
| 供應商 | H200 SXM | B200 SXM |
| Novita AI | $3.25/小時 | $3.84/小時 |
| RunPod | $3.59/小時 | $5.98/小時 |
計費選項
| 顯卡 | 現貨價(Spot) | 隨需付費(On-Demand) | 訂閱方案 |
| 1 顆 H200 SXM | $1.63/小時 | $3.25/小時 | $2160 /小時 |
| 1 顆 B200 SXM | $1.92/小時 | $3.84/小時 | - |
現貨價提供折扣費率,但可用性不固定;隨需付費採用即用即付模式,可即時取得資源;訂閱方案則能為長期、可預測的使用場景節省成本。
2. 多元旗艦 GPU 選擇
| 級別 | GPU |
| 消費級 | RTX 3090 24GB, RTX 4090 24GB, RTX 4090 24GB (高頻版本), RTX 5090 32GB |
| 工作站級 | RTX 6000 Ada 48GB |
| 資料中心級 | L40S 48GB, A100 SXM 80GB, H100 SXM 80GB, H200 SXM 141GB, B200 192GB |
3. 提供開箱即用模板
預配置模板省去了手動設定的繁瑣步驟,不僅為熱門模型提供優化環境,還包含經過驗證的部署參數、環境變量與容器配置,讓你可以直接啟動 DeepSeek、Llama 等主流 AI 框架的模型。此外,自定義模板支援為高級用戶提供完全的環境靈活性,你可以透過個性化的部署腳本、自定義軟體棧與細化優化設定構建專用環境,充分滿足獨特需求。
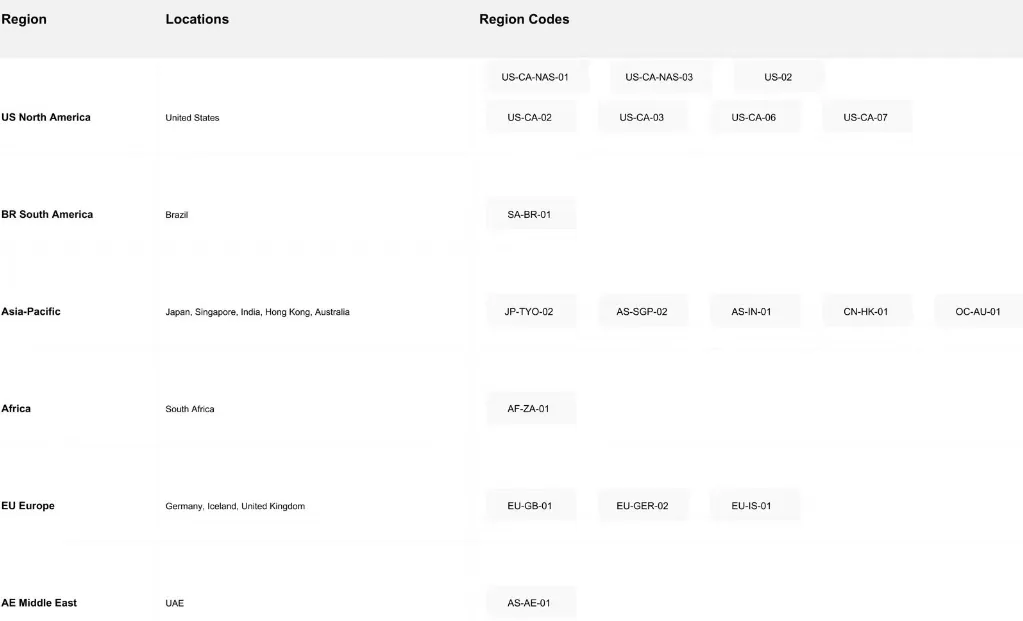
4. 全球部署網絡
Novita AI 構建了全球基礎設施,在多個大洲設有 18 個可用區,確保全球範圍內廣泛且可靠的覆蓋:
5. 優化使用者體驗
Novita AI 透過即時監控、靈活資源擴展、簡單的映像升級與自動故障轉移簡化操作流程,提供穩定可靠的 GPU 實例。
開始使用 Novita AI 的 GPU 實例
步驟 1:登入或註冊帳號,進入「GPUs -> GPU Instance」頁面
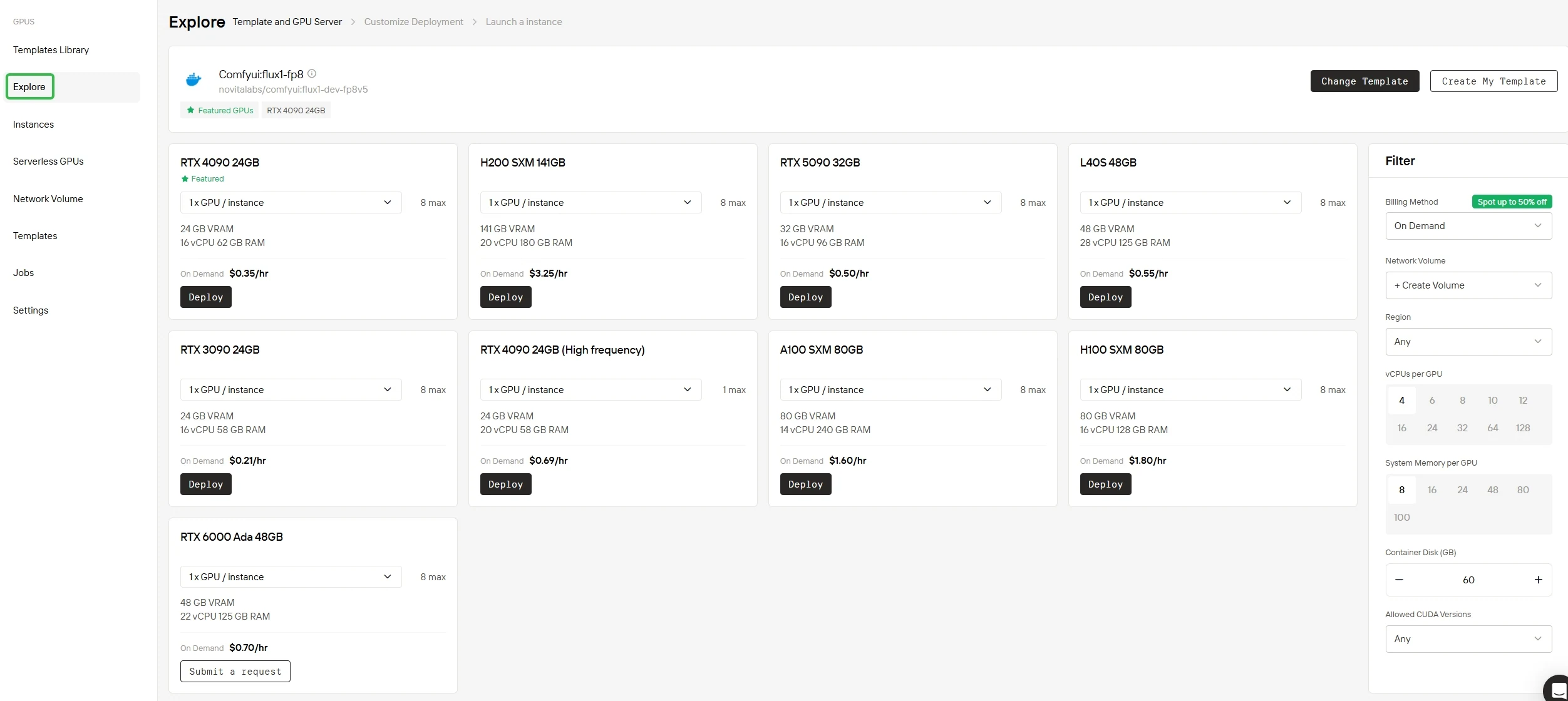
步驟 2:選擇你的 GPU
無論你使用我們的開箱即用模板庫,還是設計完全自定義的環境,平台都能提供你所需的所有核心組件。搭載 NVIDIA B200 SXM 或 H200 SXM 等搭載大容量記憶體的尖端硬體,即使是最苛刻的 AI 工作負載也能提供卓越效能。
Novita AI 現已提供 B200 SXM 裸金屬 GPU
對於追求更高控制權與專屬效能的使用者,Novita AI 也提供B200 SXM 裸金屬租賃選項。
每台 B200 SXM 裸金屬節點包含 8 張 GPU(每張 180GB 顯存)、144 個 vCPU 與 30.8TB 儲存空間。裸金屬服務提供完整的實體伺服器與獨占資源,與管理式、靈活的 GPU 實例不同,它給予使用者完全的控制權,但需要自行運維。
常見問題
Novita AI 是 AI 雲端平台,為開發者提供簡單的 API 介面,方便快速部署 AI 模型,同時也提供高性價比、可靠的 GPU 雲端服務,用於 AI 應用的構建與擴展。



