

重點摘要
DeepSeek R1 的 VRAM 需求極高,尤其是完整 671B 參數版本,需要超過 1800GB 的 VRAM。
蒸餾版本(8B、14B 等)較為可行,在經過最佳化後可在高階消費級 GPU 上運行。
本地部署存在重大技術挑戰,包括 VRAM 限制、電源與散熱需求,以及複雜的多 GPU 設定。
像 Novita AI 這樣的平台 提供高效能 GPU 實例及 DeepSeek R1 API 存取,讓部署更經濟且可擴展。
大型語言模型(LLM)如 DeepSeek R1 推進了自然語言理解與生成,但本地運行它們卻面臨嚴峻的硬體挑戰——尤其 VRAM 方面。本文將探討 DeepSeek R1 的 VRAM 需求、家庭伺服器部署的困難、實用的最佳化策略,以及使用雲端 API 的成本效益。
什麼是 VRAM?
VRAM 架構
視訊記憶體(VRAM)是 GPU 內的專用記憶體,最初設計用於將影像與圖形渲染從 CPU 卸載。VRAM 的頻寬高於系統 RAM,能夠快速傳輸資料,對處理大型圖形與模型工作負載至關重要。與共享系統 RAM 不同,VRAM 專屬於 GPU,確保穩定且可預測的效能。
雖然 VRAM 是關鍵,但運行像 DeepSeek R1 這樣的大型語言模型也需要平衡的硬體配置:
- CPU:多核心處理器支援系統任務與資料預處理。
- RAM:充足的系統記憶體用於資料處理與中間計算。
- 儲存:模型與資料集需要大量磁碟空間。
- 散熱:高效能組件會產生熱量,需要有效的散熱解決方案。
為什麼 VRAM 對 LLM 很重要?
- 高記憶體需求:LLM 需要大量 VRAM 來載入訓練與推理期間的數十億模型參數。
- Transformer 架構:多層結構與注意力機制依賴快速、並行存取儲存在 VRAM 中的權重。
- 批次處理:推理常使用批次輸入以提高吞吐量——較大的批次需要更多 VRAM。
- 精度格式:較低精度格式(如 FP16)可減少 VRAM 使用,較高精度則增加需求。
- 推理效率:快速存取參數與中間計算至關重要,而 VRAM 確保了流暢運作。
DeepSeek R1 VRAM 需求與建議 GPU
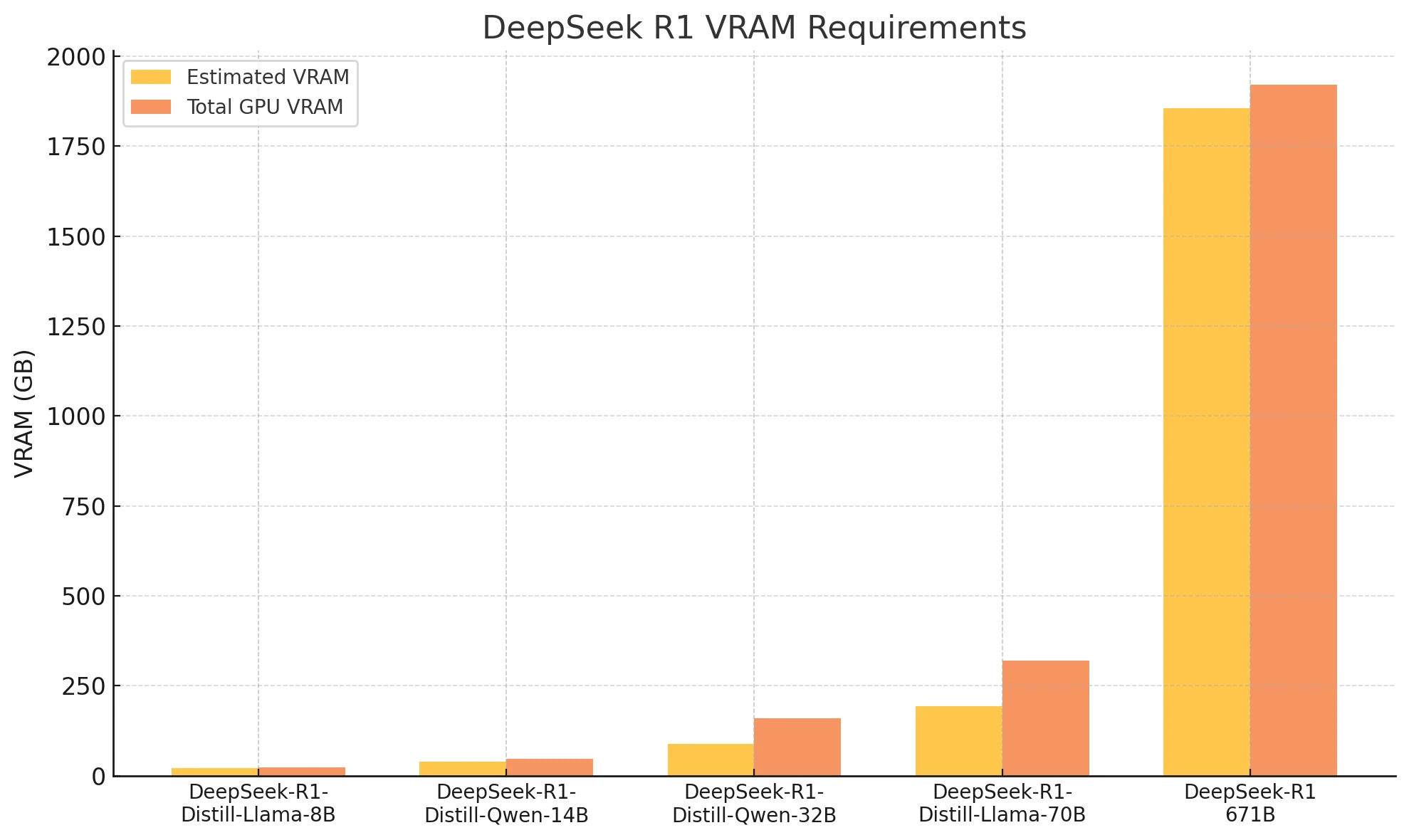
| 預估 VRAM | 建議 GPU | 總 VRAM | |
| DeepSeek-R1-Distill-Llama-8B | 約 22.2GB | RTX 4090 | 24GB |
| DeepSeek-R1-Distill-Qwen-14B | 約 39GB | 2xRTX 4090 | 48GB |
| DeepSeek-R1-Distill-Qwen-32B | 約 88.99GB | 2xH100 | 160GB |
| DeepSeek-R1-Distill-Llama-70B | 約 194.14GB | 4xH100 | 320GB |
| DeepSeek-R1:671b | 約 1854.43GB | 24xH100(80*24GB) | 1920GB |
家庭伺服器的技術挑戰
在典型家庭伺服器上運行 DeepSeek R1(甚至其蒸餾版本)會遇到幾個硬體與基礎設施挑戰,與其他大型 LLM(如 LLaMA 3.3 70B)類似:
- VRAM 與儲存不足
大多數消費級 GPU 缺乏運行即使較小 DeepSeek R1 模型所需的 VRAM。此外,模型權重可能佔用數百 GB 的儲存空間。 - 電源與散熱
高階 GPU 耗電量大且產生大量熱量,需要先進(且通常吵雜)的散熱方案——這往往超出家庭環境的能力範圍。 - 網路頻寬與延遲
高效的 LLM 效能(尤其在多使用者或遠端存取情境下)需要快速、低延遲的網路。有限的頻寬會成為推理速度的瓶頸。 - 可擴展性與多 GPU 設置
較大的模型需要多 GPU 設置以獲得最佳效能。配置這類環境可能很複雜,且可能超出一般使用者的技術能力。
為 DeepSeek R1 最佳化家庭伺服器
在較低配置的環境中運行 DeepSeek R1 具有挑戰性,但幾種借鑒自其他大型 LLM 部署的策略可以有所幫助:
4.1 配置建議
- 保持軟體更新:使用最新的作業系統、GPU 驅動程式與 AI 框架,以確保最佳效能與穩定性。
- GPU 降壓:稍微降低 GPU 電壓可以在不大幅影響效能的情況下減少功耗與熱量。
- 使用 Docker:容器化可隔離環境、簡化依賴管理並避免衝突。
4.2 記憶體最佳化
- 梯度檢查點:透過在推理期間重新計算激活值來減少記憶體使用——以計算換取記憶體。
- 剪枝與量化:修剪不重要的權重,並使用較低精度格式(如 FP16)來節省 VRAM,同時將準確度損失降至最低。探索量化版本的 DeepSeek R1 對於本地部署特別有用。
⚠️ 注意:雖然這些方法有幫助,但在典型家庭硬體上運行較大的 DeepSeek R1 模型時,它們可能仍然不足。
API 存取:小型開發人員的經濟實惠選擇
考慮到高昂的硬體需求——尤其是 671B 模型——基於雲端的 API 為小型開發人員提供了更實用的途徑:
- 無需前期硬體成本
透過 API 存取 DeepSeek R1 消除了昂貴 GPU 與基礎設施的需求。 - 按用量付費定價
使用者只需為實際使用付費,使成本可預測且易於管理。 - 自動擴展
資源根據工作負載動態調整,避免過度配置。 - 無維護負擔
雲端提供商負責更新、擴展與基礎設施,讓開發人員專注於建構。
Novita AI 推出了 DeepSeek R1 Turbo,提供 **3 倍吞吐量 ** 與 ** 限時 60% 折扣 。此外,此版本完全支援 ** 函式呼叫。
更令人興奮的是:Novita AI 是 OpenRouter 上排名靠前的 DeepSeek R1 API 之一。

步驟 1:登入並存取模型庫
登入您的帳戶,然後點選 Model Library 按鈕。

步驟 2:選擇您的模型
瀏覽可用的選項,然後選擇適合您需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的功能。
步驟 4:取得 API 金鑰
為了驗證 API,我們將為您提供一個新的 API 金鑰。進入「Settings」頁面,您可以按照圖片指示複製 API 金鑰。

步驟 5:安裝 API
使用您程式語言對應的套件管理器安裝 API。

安裝完成後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API,開始與 Novita AI LLM 互動。以下是適用於 Python 使用者的聊天補全 API 範例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
本地運行 DeepSeek R1 要求極高,因此對小型開發人員來說,雲端 API 是更實用且經濟的選擇。
運行 DeepSeek R1 需要多少 VRAM?
最小的蒸餾模型需要約 22GB 的 VRAM。完整的 671B 模型需要超過 1800GB——遠超出一般家庭硬體的能力範圍。您可以在 Novita AI 上選擇更方便且具成本效益的 API!
我可以用單張 RTX 4090 運行 DeepSeek R1 嗎?
可以,但僅限 8B 蒸餾版本。運行 14B 或更大的模型通常需要多張 GPU。
在家裡設置多 GPU 可行嗎?
不太容易。需要硬體相容性、驅動程式設定、模型分片以及通訊調校——對非專業人士來說相當困難。
Novita AI 是一個 AI 雲端平台,為開發人員提供透過簡單 API 部署 AI 模型的便捷方式,同時也提供經濟實惠且可靠的 GPU 雲端,用於建構與擴展。



