

Puntos clave
DeepSeek R1 tiene requisitos de VRAM extremadamente altos, especialmente la versión completa de 671B parámetros, que demanda más de 1800GB de VRAM.
Las versiones destiladas (8B, 14B, etc.) son más manejables y pueden ejecutarse en GPUs de consumo de gama alta con optimizaciones.
Ejecutarlo localmente presenta grandes desafíos técnicos, incluyendo VRAM limitada, demandas de energía y refrigeración, y configuraciones complejas con múltiples GPUs.
Plataformas como Novita AI ofrecen instancias GPU de alto rendimiento y acceso API para DeepSeek R1, haciendo la implementación más asequible y escalable.
Los modelos de lenguaje grandes (LLMs) como DeepSeek R1 han avanzado en la comprensión y generación de lenguaje natural, pero ejecutarlos localmente plantea grandes desafíos de hardware, especialmente en términos de VRAM. Este artículo explora los requisitos de VRAM de DeepSeek R1, las dificultades de implementación en servidores domésticos, estrategias prácticas de optimización y los beneficios de coste de usar APIs basadas en la nube.
¿Qué es la VRAM?
Arquitectura de la VRAM
La VRAM (memoria de vídeo de acceso aleatorio) es una memoria dedicada dentro de la GPU, diseñada originalmente para descargar la renderización de imágenes y gráficos de la CPU. Con un ancho de banda mayor que la RAM del sistema, la VRAM permite una transferencia rápida de datos, esencial para manejar cargas de trabajo gráficas y de modelos grandes. A diferencia de la RAM del sistema compartida, la VRAM es exclusiva de la GPU, lo que garantiza un rendimiento constante y predecible.
Si bien la VRAM es clave, ejecutar modelos de lenguaje grandes como DeepSeek R1 también requiere una configuración de hardware bien equilibrada:
- CPU: Los procesadores multinúcleo soportan tareas del sistema y preprocesamiento de datos.
- RAM: Se necesita memoria del sistema adecuada para el manejo de datos y cálculos intermedios.
- Almacenamiento: Los modelos y conjuntos de datos demandan un espacio de disco significativo.
- Refrigeración: Los componentes de alto rendimiento generan calor, requiriendo soluciones de refrigeración eficientes.
¿Por qué es importante la VRAM para los LLMs?
- Alta demanda de memoria: Los LLMs requieren una gran cantidad de VRAM para cargar miles de millones de parámetros del modelo durante el entrenamiento y la inferencia.
- Arquitectura Transformer: La estructura multicapa y el mecanismo de atención dependen de un acceso rápido y paralelo a los pesos almacenados en la VRAM.
- Procesamiento por lotes: La inferencia a menudo utiliza entrada por lotes para mejorar el rendimiento: lotes más grandes necesitan más VRAM.
- Formato de precisión: Los formatos de menor precisión (por ejemplo, FP16) reducen el uso de VRAM, mientras que una mayor precisión aumenta la demanda.
- Eficiencia de inferencia: El acceso rápido a los parámetros y cálculos intermedios es crítico, y la VRAM asegura un funcionamiento fluido.
Requisitos de VRAM de DeepSeek R1 y GPUs recomendadas
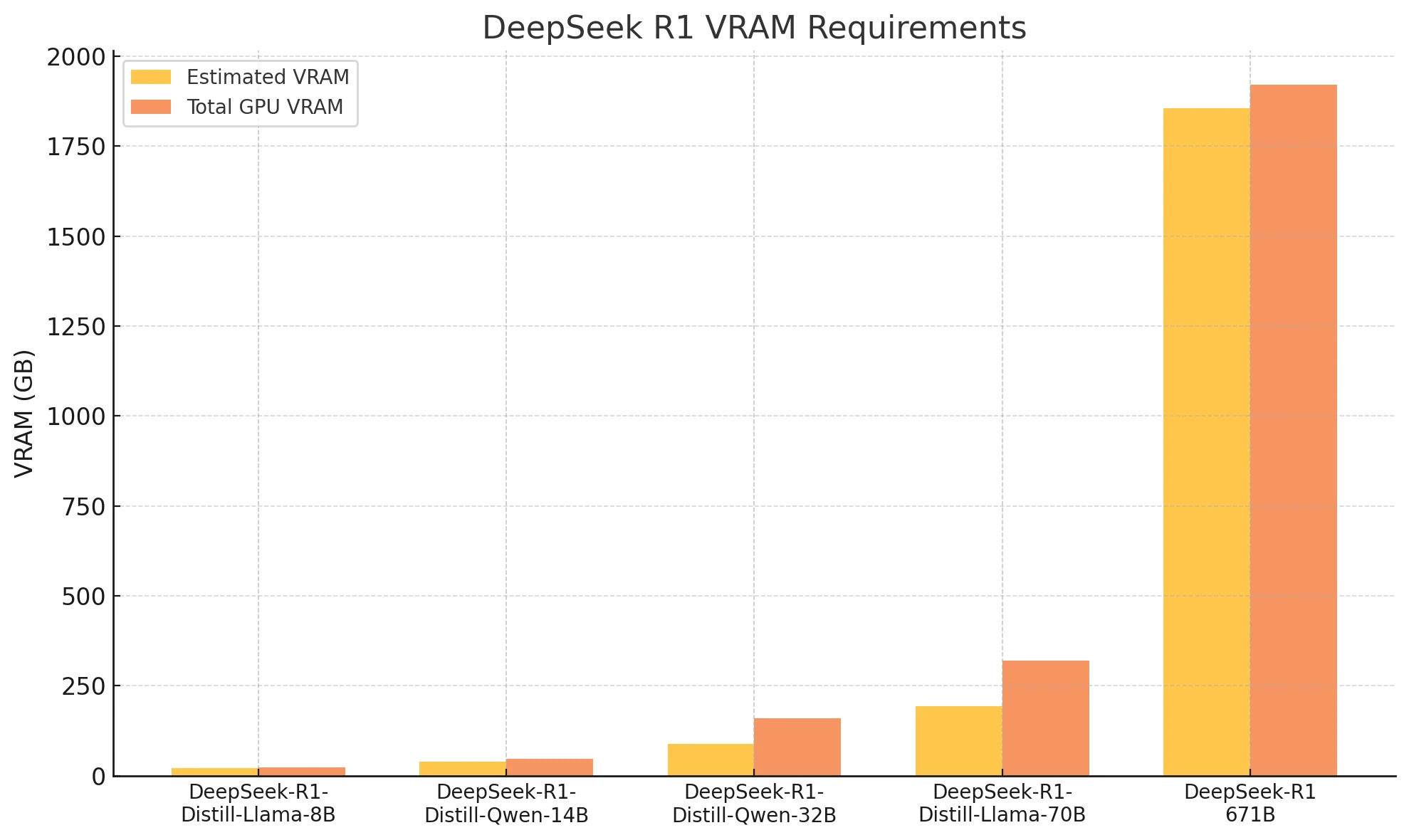
| VRAM estimada | GPUs recomendadas | VRAM total | |
| DeepSeek-R1-Distill-Llama-8B | Aprox. 22.2GB | RTX 4090 | 24GB |
| DeepSeek-R1-Distill-Qwen-14B | Aprox. 39GB | 2xRTX 4090 | 48GB |
| DeepSeek-R1-Distill-Qwen-32B | Aprox. 88.99GB | 2xH100 | 160GB |
| DeepSeek-R1-Distill-Llama-70B | Aprox. 194.14GB | 4xH100 | 320GB |
| DeepSeek-R1:671b | Aprox. 1854.43GB | 24xH100(80*24GB) | 1920GB |
Desafíos técnicos para servidores domésticos
Ejecutar DeepSeek R1 —o incluso sus versiones destiladas— en un servidor doméstico típico plantea varios desafíos de hardware e infraestructura, similares a los que se enfrentan con otros LLMs grandes como LLaMA 3.3 70B:
- VRAM y almacenamiento insuficientes
La mayoría de las GPUs de consumo carecen de la VRAM necesaria incluso para los modelos más pequeños de DeepSeek R1. Además, los pesos del modelo pueden ocupar cientos de gigabytes de almacenamiento. - Energía y refrigeración
Las GPUs de gama alta consumen una cantidad considerable de energía y generan un calor significativo, lo que requiere soluciones de refrigeración avanzadas (y a menudo ruidosas) que suelen estar fuera del alcance de las configuraciones domésticas. - Ancho de banda y latencia de red
Un rendimiento eficiente de los LLM, especialmente en escenarios multiusuario o de acceso remoto, demanda una internet rápida y de baja latencia. El ancho de banda limitado puede convertirse en un cuello de botella para la velocidad de inferencia. - Escalabilidad y configuración multi-GPU
Los modelos más grandes necesitan configuraciones multi-GPU para un rendimiento óptimo. Configurar estos entornos puede ser complejo y puede exceder las capacidades técnicas de los usuarios domésticos típicos.
Optimización de servidores domésticos para DeepSeek R1
Ejecutar DeepSeek R1 en configuraciones modestas es un desafío, pero varias estrategias —tomadas de otras implementaciones de LLMs grandes— pueden ayudar:
4.1 Consejos de configuración
- Mantén el software actualizado: Usa el último SO, controladores de GPU y frameworks de IA para garantizar un rendimiento y estabilidad óptimos.
- Subvoltaje de la GPU: Reducir ligeramente el voltaje de la GPU puede disminuir la energía y el calor sin una pérdida importante de rendimiento.
- Usa Docker: La contenerización aísla entornos, simplifica la gestión de dependencias y evita conflictos.
4.2 Optimización de memoria
- Gradient checkpointing: Reduce el uso de memoria al recalcular las activaciones durante la inferencia —intercambiando memoria por cómputo.
- Poda y cuantización: Elimina pesos menos importantes y usa formatos de menor precisión (por ejemplo, FP16) para ahorrar VRAM con una pérdida mínima de precisión. Explorar versiones cuantizadas de DeepSeek R1 es especialmente útil para la implementación local.
⚠️ Nota: Aunque estos métodos ayudan, pueden no ser suficientes para ejecutar modelos más grandes de DeepSeek R1 en hardware doméstico típico.
Acceso API: Una opción rentable para pequeños desarrolladores
Dadas las altas demandas de hardware —especialmente para el modelo de 671B—, las APIs basadas en la nube ofrecen un camino más práctico para los pequeños desarrolladores:
- Sin costes iniciales de hardware
Acceder a DeepSeek R1 a través de API elimina la necesidad de GPUs e infraestructura costosas. - Precios de pago por uso
Los usuarios pagan solo por lo que usan, lo que hace que los costes sean predecibles y manejables. - Autoescalado
Los recursos se ajustan dinámicamente según la carga de trabajo, evitando el sobredimensionamiento. - Sin carga de mantenimiento
El proveedor de la nube se encarga de las actualizaciones, el escalado y la infraestructura, permitiendo a los desarrolladores centrarse en construir.
Novita AI ha presentado DeepSeek R1 Turbo, que ofrece 3x de rendimiento y 60% de descuento por tiempo limitado. Además, esta versión es totalmente compatible con function calling.
Aún más emocionante: Novita AI es una de las APIs de DeepSeek R1 mejor clasificadas en OpenRouter.

Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.

¡Prueba la Demo de DeepSeek R1 Turbo ahora!
Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Entra en la página de “Ajustes” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo del uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Ejecutar DeepSeek R1 localmente es muy exigente, por lo que las APIs basadas en la nube son una opción más práctica y rentable para los desarrolladores pequeños.
¿Cuánta VRAM se necesita para ejecutar DeepSeek R1?
El modelo destilado más pequeño requiere alrededor de 22GB de VRAM. El modelo completo de 671B necesita más de 1800GB, muy por encima de las capacidades del hardware doméstico típico. ¡Puedes elegir una API más conveniente y rentable en Novita AI!
¿Puedo ejecutar DeepSeek R1 con una sola RTX 4090?
Sí, pero solo la versión destilada de 8B. Ejecutar modelos de 14B o más grandes normalmente requiere múltiples GPUs.
¿Es factible una configuración multi-GPU en casa?
No es fácil. Requiere compatibilidad de hardware, configuración de controladores, fragmentación de modelos y ajuste de comunicación, lo cual es difícil para los no expertos.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y confiable para construir y escalar.



