

Wichtige Erkenntnisse
DeepSeek R1 hat extrem hohe VRAM-Anforderungen, insbesondere die vollständige 671B-Parameterversion, die über 1800 GB VRAM benötigt.
Destillierte Versionen (8B, 14B usw.) sind handlicher und können mit Optimierungen auf High-End-Consumer-GPUs ausgeführt werden.
Der lokale Betrieb stellt große technische Herausforderungen dar, darunter begrenzter VRAM, Anforderungen an Stromversorgung und Kühlung sowie komplexe Multi-GPU-Setups.
Plattformen wie Novita AI bieten leistungsstarke GPU-Instanzen und API-Zugang für DeepSeek R1, wodurch der Einsatz erschwinglicher und skalierbarer wird.
Large Language Models (LLMs) wie DeepSeek R1 haben das Verständnis und die Generierung natürlicher Sprache grundlegend verbessert, aber der lokale Betrieb stellt große hardwaretechnische Herausforderungen dar – insbesondere im Hinblick auf den VRAM. Dieser Artikel untersucht die VRAM-Anforderungen von DeepSeek R1, die Schwierigkeiten bei der Bereitstellung auf Heimsystemen, praktische Optimierungsstrategien und die Kostenvorteile der Nutzung cloudbasierter APIs.
Was ist VRAM?
VRAM-Architektur
Video-RAM (VRAM) ist dedizierter Speicher in einer GPU, der ursprünglich entwickelt wurde, um Bild- und Grafikrendering von der CPU zu entlasten. Mit einer höheren Bandbreite als System-RAM ermöglicht VRAM schnelle Datenübertragungen, die für die Verarbeitung großer grafischer und modellbezogener Arbeitslasten unerlässlich sind. Im Gegensatz zu gemeinsam genutztem System-RAM ist VRAM exklusiv der GPU zugeordnet, was eine konsistente und vorhersagbare Leistung gewährleistet.
Während VRAM entscheidend ist, erfordert der Betrieb großer Sprachmodelle wie DeepSeek R1 auch eine gut ausbalancierte Hardwarekonfiguration:
- CPU: Mehrkernprozessoren unterstützen Systemaufgaben und Datenvorverarbeitung.
- RAM: Ausreichender Systemspeicher ist für Datenverwaltung und Zwischenberechnungen erforderlich.
- Speicher: Modelle und Datensätze benötigen erheblichen Festplattenspeicher.
- Kühlung: Hochleistungskomponenten erzeugen Wärme und benötigen effiziente Kühllösungen.
Warum ist VRAM für LLMs wichtig?
- Hoher Speicherbedarf: LLMs benötigen große VRAM-Mengen, um Milliarden von Modellparametern während Training und Inferenz zu laden.
- Transformer-Architektur: Die mehrschichtige Struktur und der Aufmerksamkeitsmechanismus basieren auf schnellem, parallelem Zugriff auf im VRAM gespeicherte Gewichte.
- Batch-Verarbeitung: Bei der Inferenz wird oft Batch-Input verwendet, um den Durchsatz zu verbessern – größere Batches benötigen mehr VRAM.
- Präzisionsformat: Formate mit niedrigerer Präzision (z. B. FP16) reduzieren die VRAM-Nutzung, während höhere Präzision den Bedarf erhöht.
- Inferenzeffizienz: Schneller Zugriff auf Parameter und Zwischenberechnungen ist entscheidend, und VRAM gewährleistet einen reibungslosen Betrieb.
DeepSeek R1 VRAM-Anforderungen und empfohlene GPUs
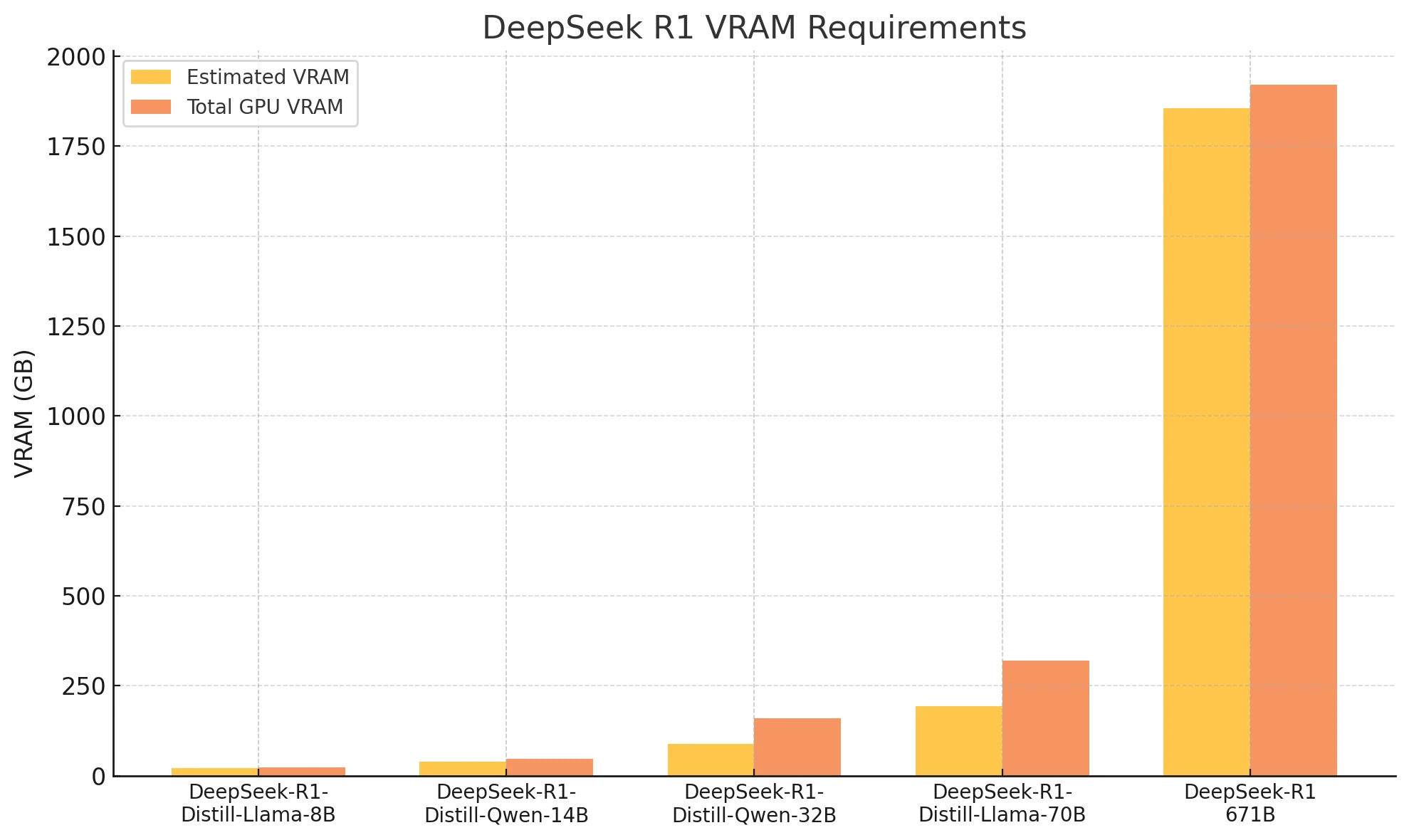
| Geschätzter VRAM | Empfohlene GPUs | Gesamt-VRAM | |
| DeepSeek-R1-Distill-Llama-8B | Ca. 22,2 GB | RTX 4090 | 24 GB |
| DeepSeek-R1-Distill-Qwen-14B | Ca. 39 GB | 2x RTX 4090 | 48 GB |
| DeepSeek-R1-Distill-Qwen-32B | Ca. 88,99 GB | 2x H100 | 160 GB |
| DeepSeek-R1-Distill-Llama-70B | Ca. 194,14 GB | 4x H100 | 320 GB |
| DeepSeek-R1:671b | Ca. 1854,43 GB | 24x H100 (80*24 GB) | 1920 GB |
Technische Herausforderungen für Heimsysteme
Der Betrieb von DeepSeek R1 – oder selbst seiner destillierten Versionen – auf einem typischen Heimserver bringt mehrere hardware- und infrastrukturelle Herausforderungen mit sich, ähnlich denen bei anderen großen LLMs wie LLaMA 3.3 70B:
- Unzureichender VRAM und Speicher
Die meisten Consumer-GPUs besitzen nicht den erforderlichen VRAM, um selbst kleinere DeepSeek R1-Modelle auszuführen. Zudem können die Modellgewichte hunderte Gigabyte Speicherplatz beanspruchen. - Stromversorgung und Kühlung
High-End-GPUs verbrauchen viel Strom und erzeugen erhebliche Wärme, was fortschrittliche (und oft laute) Kühllösungen erfordert – oft jenseits der Möglichkeiten von Heimumgebungen. - Netzwerkbandbreite und Latenz
Effiziente LLM-Leistung, insbesondere in Szenarien mit mehreren Benutzern oder Remote-Zugriff, erfordert schnelles Internet mit niedriger Latenz. Begrenzte Bandbreite kann die Inferenzgeschwindigkeit zum Engpass machen. - Skalierbarkeit und Multi-GPU-Setup
Größere Modelle benötigen Multi-GPU-Setups für optimale Leistung. Die Konfiguration solcher Umgebungen kann komplex sein und die technischen Fähigkeiten typischer Heimanwender übersteigen.
Optimierung von Heimservern für DeepSeek R1
Der Betrieb von DeepSeek R1 auf bescheidenen Systemen ist herausfordernd, aber verschiedene Strategien – übernommen von anderen großen LLM-Bereitstellungen – können helfen:
4.1 Konfigurationstipps
- Software aktuell halten: Verwenden Sie das neueste Betriebssystem, die neuesten GPU-Treiber und KI-Frameworks, um optimale Leistung und Stabilität zu gewährleisten.
- GPU-Undervolting: Eine leichte Senkung der GPU-Spannung kann Stromverbrauch und Wärme reduzieren, ohne große Leistungseinbußen.
- Docker verwenden: Containerisierung isoliert Umgebungen, vereinfacht die Abhängigkeitsverwaltung und vermeidet Konflikte.
4.2 Speicheroptimierung
- Gradient Checkpointing: Reduziert den Speicherverbrauch, indem Aktivierungen während der Inferenz neu berechnet werden – Speicher wird gegen Rechenleistung getauscht.
- Pruning und Quantisierung: Entfernen Sie weniger wichtige Gewichte und verwenden Sie Formate mit niedrigerer Präzision (z. B. FP16), um VRAM bei minimalem Genauigkeitsverlust zu sparen. Die Erkundung quantisierter DeepSeek R1-Versionen ist besonders für die lokale Bereitstellung nützlich.
⚠️ Hinweis: Obwohl diese Methoden helfen, können sie für den Betrieb größerer DeepSeek R1-Modelle auf typischer Heimhardware dennoch unzureichend sein.
API-Zugang: Eine kosteneffiziente Wahl für kleine Entwickler
Angesichts der hohen Hardwareanforderungen – insbesondere für das 671B-Modell – bieten cloudbasierte APIs einen praktischeren Weg für kleine Entwickler:
- Keine anfänglichen Hardwarekosten
Der Zugriff auf DeepSeek R1 über API macht teure GPUs und Infrastruktur überflüssig. - Pay-as-you-go-Preise
Benutzer zahlen nur für die tatsächliche Nutzung, was die Kosten vorhersagbar und verwaltbar macht. - Automatische Skalierung
Ressourcen passen sich dynamisch an die Arbeitslast an und vermeiden Überdimensionierung. - Kein Wartungsaufwand
Der Cloud-Anbieter kümmert sich um Updates, Skalierung und Infrastruktur, sodass sich Entwickler auf das Wesentliche konzentrieren können.
Novita AI hat DeepSeek R1 Turbo eingeführt, das 3-fachen Durchsatz und zeitlich begrenzt 60% Rabatt bietet. Darüber hinaus unterstützt diese Version vollständig Function Calling.
Noch aufregender: Novita AI ist eine der am höchsten bewerteten DeepSeek R1 APIs auf OpenRouter.

Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Jetzt DeepSeek R1 Turbo Demo ausprobieren!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # oder False
max_tokens = 2048
system_content = """Sei ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Der lokale Betrieb von DeepSeek R1 ist äußerst anspruchsvoll, was cloudbasierte APIs zu einer praktikableren und kosteneffizienteren Wahl für kleine Entwickler macht.
Wie viel VRAM wird benötigt, um DeepSeek R1 auszuführen?
Das kleinste destillierte Modell benötigt etwa 22 GB VRAM. Die vollständige 671B-Version benötigt über 1800 GB – weit jenseits der Möglichkeiten typischer Heimhardware. Sie können eine bequemere und kosteneffizientere API auf Novita AI wählen!
Kann ich DeepSeek R1 mit einer einzigen RTX 4090 ausführen?
Ja, aber nur die 8B-destillierte Version. Der Betrieb der 14B- oder größeren Versionen erfordert in der Regel mehrere GPUs.
Ist ein Multi-GPU-Setup zu Hause machbar?
Nicht einfach. Es erfordert Hardwarekompatibilität, Treibereinrichtung, Modell-Sharding und Kommunikationsoptimierung – schwierig für Nicht-Experten.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle mit einer simplen API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



