

Points clés
DeepSeek R1 a des besoins VRAM extrêmement élevés, en particulier la version complète à 671 milliards de paramètres, qui nécessite plus de 1800 Go de VRAM.
Les versions distillées (8B, 14B, etc.) sont plus gérables et peuvent fonctionner sur des GPU grand public haut de gamme avec des optimisations.
L’exécution locale présente des défis techniques majeurs, notamment une VRAM limitée, des besoins en énergie et en refroidissement, et des configurations multi-GPU complexes.
Des plateformes comme Novita AI proposent des instances GPU hautes performances et un accès API pour DeepSeek R1, rendant le déploiement plus abordable et évolutif.
Les grands modèles de langage (LLM) comme DeepSeek R1 ont fait progresser la compréhension et la génération du langage naturel, mais leur exécution locale pose des défis matériels majeurs – surtout en termes de VRAM. Cet article explore les besoins VRAM de DeepSeek R1, les difficultés du déploiement sur serveur domestique, les stratégies pratiques d’optimisation et les avantages économiques de l’utilisation d’API cloud.
Qu’est-ce que la VRAM ?
Architecture de la VRAM
La VRAM (Video RAM) est une mémoire dédiée au sein d’un GPU, conçue à l’origine pour décharger le rendu d’images et de graphismes du CPU. Avec une bande passante supérieure à celle de la RAM système, la VRAM permet un transfert rapide des données, essentiel pour gérer de lourdes charges de travail graphiques et de modèles. Contrairement à la RAM système partagée, la VRAM est exclusive au GPU, garantissant des performances constantes et prévisibles.
Bien que la VRAM soit essentielle, l’exécution de grands modèles de langage comme DeepSeek R1 nécessite également une configuration matérielle bien équilibrée :
- CPU : Des processeurs multi-cœurs prennent en charge les tâches système et le prétraitement des données.
- RAM : Une mémoire système adéquate est nécessaire pour la gestion des données et les calculs intermédiaires.
- Stockage : Les modèles et les jeux de données occupent un espace disque important.
- Refroidissement : Les composants hautes performances génèrent de la chaleur, nécessitant des solutions de refroidissement efficaces.
Pourquoi la VRAM est-elle importante pour les LLM ?
- Demande mémoire élevée : Les LLM nécessitent une grande VRAM pour charger des milliards de paramètres lors de l’entraînement et de l’inférence.
- Architecture Transformer : La structure multicouche et le mécanisme d’attention reposent sur un accès rapide et parallèle aux poids stockés dans la VRAM.
- Traitement par lots : L’inférence utilise souvent des entrées par lots pour améliorer le débit – des lots plus grands nécessitent plus de VRAM.
- Format de précision : Les formats de précision inférieure (ex. FP16) réduisent l’utilisation de la VRAM, tandis qu’une précision plus élevée augmente la demande.
- Efficacité de l’inférence : L’accès rapide aux paramètres et aux calculs intermédiaires est critique, et la VRAM garantit un fonctionnement fluide.
Exigences VRAM de DeepSeek R1 et GPU recommandés
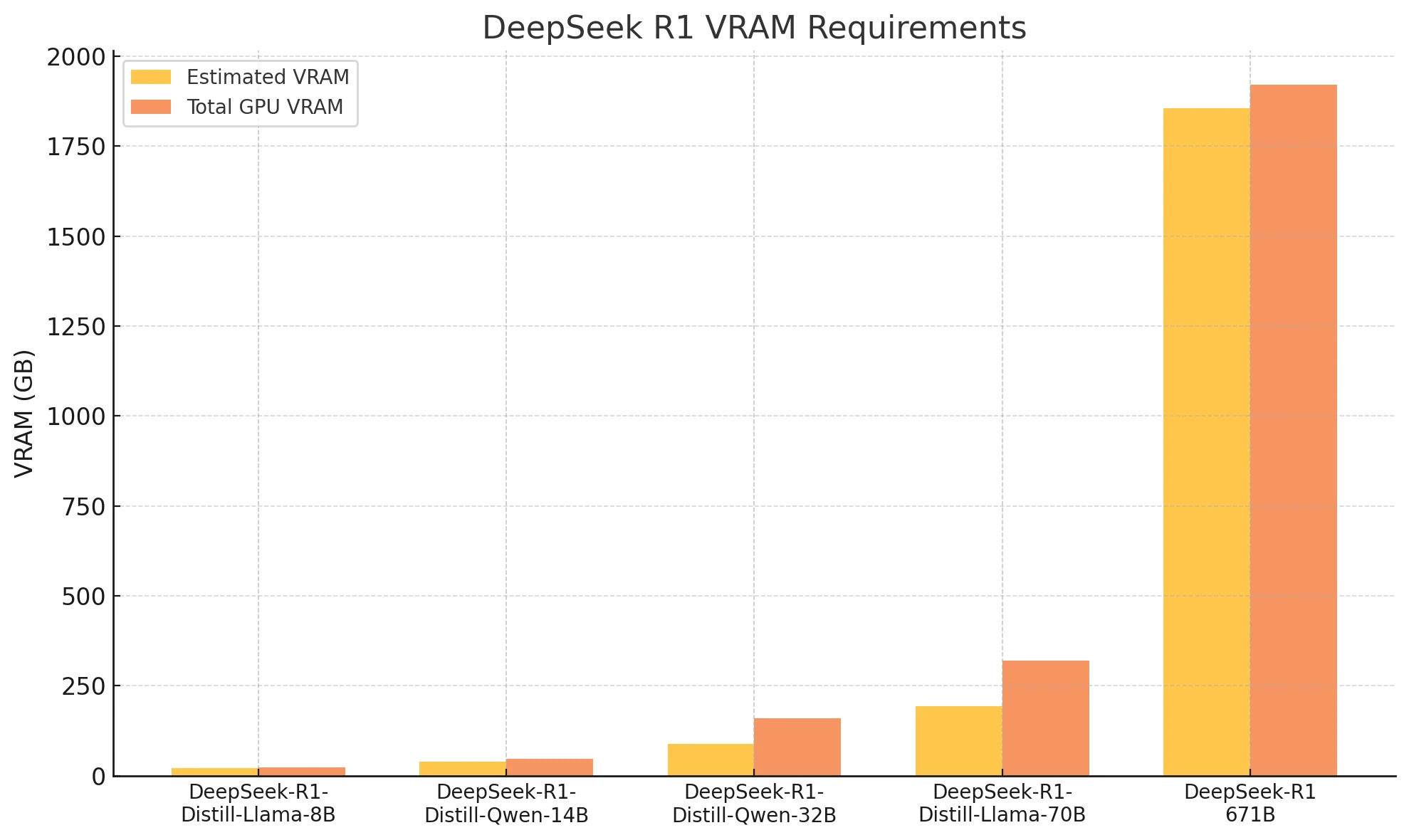
| VRAM estimée | GPU recommandés | VRAM totale | |
| DeepSeek-R1-Distill-Llama-8B | Environ 22,2 Go | RTX 4090 | 24 Go |
| DeepSeek-R1-Distill-Qwen-14B | Environ 39 Go | 2xRTX 4090 | 48 Go |
| DeepSeek-R1-Distill-Qwen-32B | Environ 88,99 Go | 2xH100 | 160 Go |
| DeepSeek-R1-Distill-Llama-70B | Environ 194,14 Go | 4xH100 | 320 Go |
| DeepSeek-R1:671b | Environ 1854,43 Go | 24xH100(80*24Go) | 1920 Go |
Défis techniques pour les serveurs domestiques
Faire fonctionner DeepSeek R1 – ou même ses versions distillées – sur un serveur domestique typique pose plusieurs défis matériels et d’infrastructure, similaires à ceux rencontrés avec d’autres grands LLM comme LLaMA 3.3 70B :
- VRAM et stockage insuffisants
La plupart des GPU grand public manquent de la VRAM requise, même pour les petits modèles DeepSeek R1. De plus, les poids du modèle peuvent occuper des centaines de gigaoctets de stockage. - Alimentation et refroidissement
Les GPU haut de gamme consomment beaucoup d’énergie et dégagent une chaleur importante, nécessitant des solutions de refroidissement avancées (et souvent bruyantes) – souvent au-delà de ce que les configurations domestiques peuvent gérer. - Bande passante réseau et latence
Les performances efficaces des LLM, surtout dans les scénarios multi-utilisateurs ou d’accès à distance, exigent une connexion Internet rapide et à faible latence. Une bande passante limitée peut ralentir l’inférence. - Évolutivité et configuration multi-GPU
Les grands modèles nécessitent des configurations multi-GPU pour des performances optimales. Configurer de tels environnements peut être complexe et dépasser les capacités techniques des utilisateurs domestiques typiques.
Optimiser les serveurs domestiques pour DeepSeek R1
Faire fonctionner DeepSeek R1 sur des configurations modestes est difficile, mais plusieurs stratégies – empruntées à d’autres déploiements de grands LLM – peuvent aider :
4.1 Conseils de configuration
- Garder les logiciels à jour : Utilisez la dernière version du système d’exploitation, des pilotes GPU et des frameworks IA pour garantir des performances et une stabilité optimales.
- Underclocking GPU : Baisser légèrement la tension du GPU peut réduire la consommation et la chaleur sans perte de performance majeure.
- Utiliser Docker : La conteneurisation isole les environnements, simplifie la gestion des dépendances et évite les conflits.
4.2 Optimisation de la mémoire
- Gradient checkpointing : Réduit l’utilisation mémoire en recalculant les activations pendant l’inférence – échange mémoire contre calcul.
- Élagage et quantification : Élaguer les poids moins importants et utiliser des formats de précision inférieure (ex. FP16) pour économiser la VRAM avec une perte de précision minimale. Explorer les versions quantifiées de DeepSeek R1 est particulièrement utile pour un déploiement local.
⚠️ Remarque : Bien que ces méthodes aident, elles peuvent encore s’avérer insuffisantes pour exécuter les grands modèles DeepSeek R1 sur du matériel domestique typique.
Accès API : un choix économique pour les petits développeurs
Compte tenu des besoins matériels élevés – surtout pour le modèle 671B – les API cloud offrent une voie plus pratique pour les petits développeurs :
- Aucun coût matériel initial
Accéder à DeepSeek R1 via une API élimine le besoin de GPU et d’infrastructure coûteux. - Paiement à l’utilisation
Les utilisateurs ne paient que pour ce qu’ils consomment, rendant les coûts prévisibles et gérables. - Mise à l’échelle automatique
Les ressources s’ajustent dynamiquement en fonction de la charge de travail, évitant le surdimensionnement. - Aucune charge de maintenance
Le fournisseur cloud gère les mises à jour, la mise à l’échelle et l’infrastructure, permettant aux développeurs de se concentrer sur la création.
Novita AI a introduit DeepSeek R1 Turbo, offrant 3x le débit et 60% de réduction à durée limitée. De plus, cette version prend entièrement en charge l’appel de fonctions.
Encore plus excitant : Novita AI est l’une des API DeepSeek R1 les mieux classées sur OpenRouter.

Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez la démo de DeepSeek R1 Turbo maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle choisi.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. Entrez dans la page Paramètres, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<VOTRE_CLÉ_API_Novita_AI>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # ou False
max_tokens = 2048
system_content = """Soyez un assistant utile"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Faire fonctionner DeepSeek R1 localement est très exigeant, ce qui fait des API cloud un choix plus pratique et économique pour les petits développeurs.
Quelle quantité de VRAM est nécessaire pour exécuter DeepSeek R1 ?
Le plus petit modèle distillé nécessite environ 22 Go de VRAM. Le modèle complet à 671B nécessite plus de 1800 Go – bien au-delà des capacités du matériel domestique typique. Vous pouvez choisir une API plus pratique et économique sur Novita AI !
Puis-je exécuter DeepSeek R1 avec une seule RTX 4090 ?
Oui, mais seulement la version distillée 8B. L’exécution de modèles 14B ou plus nécessite généralement plusieurs GPU.
Une configuration multi-GPU à la maison est-elle réalisable ?
Pas facilement. Cela nécessite une compatibilité matérielle, une configuration des pilotes, un partitionnement du modèle et un réglage de la communication – difficile pour les non-experts.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



