

Principais Destaques
Os requisitos de VRAM do DeepSeek R1 são extremamente altos, especialmente na versão completa de 671B parâmetros, que exige mais de 1800GB de VRAM.
As versões destiladas (8B, 14B, etc.) são mais gerenciáveis e podem ser executadas em GPUs de consumo topo de linha com otimizações.
Executar localmente apresenta grandes desafios técnicos, incluindo VRAM limitada, demandas de energia e refrigeração, e configurações complexas com múltiplas GPUs.
Plataformas como a Novita AI fornecem instâncias de GPU de alto desempenho e acesso via API para o DeepSeek R1, tornando a implantação mais acessível e escalável.
Grandes Modelos de Linguagem (LLMs) como o DeepSeek R1 avançaram o entendimento e a geração de linguagem natural, mas executá-los localmente apresenta grandes desafios de hardware — especialmente em termos de VRAM. Este artigo explora os requisitos de VRAM do DeepSeek R1, as dificuldades da implantação em servidores domésticos, estratégias práticas de otimização e os benefícios de custo do uso de APIs baseadas na nuvem.
O que é VRAM?
Arquitetura da VRAM
A VRAM (Video RAM) é uma memória dedicada dentro da GPU, originalmente projetada para aliviar a CPU da renderização de imagens e gráficos. Com maior largura de banda que a RAM do sistema, a VRAM permite transferência rápida de dados, essencial para lidar com cargas de trabalho gráficas e de modelos grandes. Diferente da RAM do sistema compartilhada, a VRAM é exclusiva da GPU, garantindo desempenho consistente e previsível.
Embora a VRAM seja fundamental, executar grandes modelos de linguagem como o DeepSeek R1 também requer uma configuração de hardware bem equilibrada:
- CPU: Processadores multinúcleo suportam tarefas do sistema e pré-processamento de dados.
- RAM: Memória do sistema adequada é necessária para manipulação de dados e cálculos intermediários.
- Armazenamento: Modelos e conjuntos de dados exigem espaço significativo em disco.
- Refrigeração: Componentes de alto desempenho geram calor, exigindo soluções de refrigeração eficientes.
Por que a VRAM é importante para LLMs?
- Alta Demanda de Memória: LLMs exigem grande quantidade de VRAM para carregar bilhões de parâmetros do modelo durante treinamento e inferência.
- Arquitetura Transformer: A estrutura multicamadas e o mecanismo de atenção dependem de acesso rápido e paralelo aos pesos armazenados na VRAM.
- Processamento em Lote: A inferência frequentemente usa entrada em lote para melhorar a taxa de transferência — lotes maiores precisam de mais VRAM.
- Formato de Precisão: Formatos de menor precisão (ex.: FP16) reduzem o uso de VRAM, enquanto maior precisão aumenta a demanda.
- Eficiência da Inferência: O acesso rápido aos parâmetros e cálculos intermediários é crítico, e a VRAM garante operação suave.
Requisitos de VRAM do DeepSeek R1 e GPUs Recomendadas
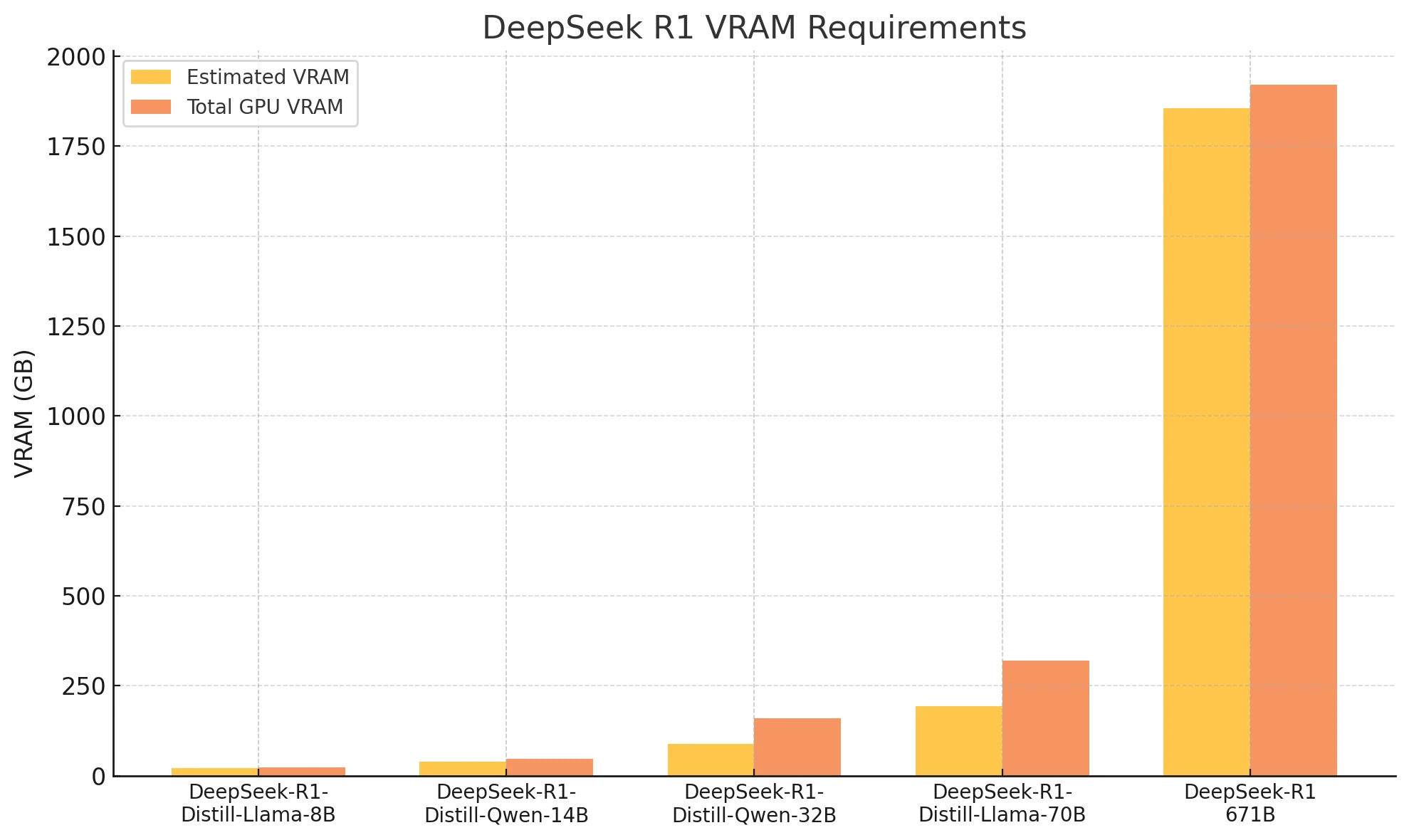
| VRAM Estimada | GPUs Recomendadas | VRAM Total | |
| DeepSeek-R1-Distill-Llama-8B | Cerca de 22,2GB | RTX 4090 | 24GB |
| DeepSeek-R1-Distill-Qwen-14B | Cerca de 39GB | 2xRTX 4090 | 48GB |
| DeepSeek-R1-Distill-Qwen-32B | Cerca de 88,99GB | 2xH100 | 160GB |
| DeepSeek-R1-Distill-Llama-70B | Cerca de 194,14GB | 4xH100 | 320GB |
| DeepSeek-R1:671b | Cerca de 1854,43GB | 24xH100(80*24GB) | 1920GB |
Desafios Técnicos para Servidores Domésticos
Executar o DeepSeek R1 — ou mesmo suas versões destiladas — em um servidor doméstico típico apresenta vários desafios de hardware e infraestrutura, semelhantes aos enfrentados com outros LLMs grandes como o LLaMA 3.3 70B:
- VRAM e Armazenamento Insuficientes
A maioria das GPUs de consumo não possui a VRAM necessária nem mesmo para os modelos menores do DeepSeek R1. Além disso, os pesos do modelo podem ocupar centenas de gigabytes em armazenamento. - Energia e Refrigeração
GPUs de alto desempenho consomem muita energia e produzem calor significativo, exigindo soluções de refrigeração avançadas (e muitas vezes barulhentas) — geralmente além do que configurações domésticas podem suportar. - Largura de Banda e Latência de Rede
O desempenho eficiente de LLMs, especialmente em cenários multiusuário ou acesso remoto, exige internet rápida e de baixa latência. A largura de banda limitada pode se tornar um gargalo para a velocidade de inferência. - Escalabilidade e Configuração MultigPU
Modelos maiores precisam de configurações com múltiplas GPUs para desempenho ideal. Configurar esses ambientes pode ser complexo e pode exceder a capacidade técnica de usuários domésticos típicos.
Otimizando Servidores Domésticos para DeepSeek R1
Executar o DeepSeek R1 em configurações modestas é desafiador, mas várias estratégias — emprestadas de outras implantações de LLMs grandes — podem ajudar:
4.1 Dicas de Configuração
- Mantenha o software atualizado: Use o sistema operacional, drivers de GPU e frameworks de IA mais recentes para garantir desempenho e estabilidade ideais.
- Undervolting da GPU: Reduzir ligeiramente a voltagem da GPU pode diminuir o consumo de energia e calor sem perda significativa de desempenho.
- Use Docker: A conteinerização isola ambientes, simplifica o gerenciamento de dependências e evita conflitos.
4.2 Otimização de Memória
- Gradient checkpointing: Reduz o uso de memória ao recalcular ativações durante a inferência — trocando memória por computação.
- Podagem e quantização: Remova pesos menos importantes e use formatos de menor precisão (ex.: FP16) para economizar VRAM com perda mínima de precisão. Explorar versões quantizadas do DeepSeek R1 é especialmente útil para implantação local.
⚠️ Nota: Embora esses métodos ajudem, eles podem ainda ser insuficientes para executar modelos maiores do DeepSeek R1 em hardware doméstico típico.
Acesso via API: Uma Escolha Custo-Eficiente para Pequenos Desenvolvedores
Dadas as altas exigências de hardware — especialmente para o modelo de 671B — as APIs baseadas na nuvem oferecem um caminho mais prático para pequenos desenvolvedores:
- Sem custos iniciais de hardware
Acessar o DeepSeek R1 via API elimina a necessidade de GPUs e infraestrutura caras. - Preço conforme o uso
Os usuários pagam apenas pelo que usam, tornando os custos previsíveis e gerenciáveis. - Escalabilidade automática
Os recursos se ajustam dinamicamente conforme a carga de trabalho, evitando provisionamento excessivo. - Sem sobrecarga de manutenção
O provedor de nuvem cuida de atualizações, escalonamento e infraestrutura, permitindo que os desenvolvedores foquem na construção.
A Novita AI lançou o DeepSeek R1 Turbo, oferecendo 3x mais taxa de transferência e desconto de 60% por tempo limitado. Além disso, esta versão suporta completamente function calling.
Ainda mais empolgante: A Novita AI é uma das APIs do DeepSeek R1 mais bem classificadas no OpenRouter.

Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente o DeepSeek R1 Turbo Demo Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar na API, forneceremos uma nova chave de API. Acesse a página “Settings” e copie a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<SUA CHAVE DE API Novita AI>",
)
model = "deepseek/deepseek-r1-turbo"
stream = True # ou False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Executar o DeepSeek R1 localmente é altamente exigente, tornando as APIs baseadas na nuvem uma escolha mais prática e econômica para pequenos desenvolvedores.
Quanta VRAM é necessária para executar o DeepSeek R1?
O menor modelo destilado requer cerca de 22GB de VRAM. O modelo completo de 671B precisa de mais de 1800GB — muito além das capacidades de hardware doméstico típico. Você pode escolher uma API mais conveniente e econômica na Novita AI!
Posso executar o DeepSeek R1 com uma única RTX 4090?
Sim, mas apenas a versão destilada de 8B. Executar modelos de 14B ou maiores geralmente requer múltiplas GPUs.
É viável uma configuração multigPU em casa?
Não facilmente. Requer compatibilidade de hardware, configuração de drivers, fragmentação do modelo e ajuste de comunicação — difícil para não especialistas.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



