

推荐朋友使用 Novita AI,你和朋友各将获得 $10 的 LLM API 额度——总奖励最高可达 $500。
为了支持开发者社区,Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B 现已在 Novita AI 上免费提供。

每个人都在谈论 Llama 3.2 1B 是完美的“设备端”语言模型。小巧、多语言、高效——听起来像是移动应用和边缘设备的理想工具。
但真相是:真正本地运行它?并不容易。它可能会卡顿、崩溃或需要比预期更多的设置。这就是 API 接入改变游戏规则 的地方。零安装、弹性扩展、近乎即时的响应,API 提供了解锁 Llama 3.2 1B 能力的最顺畅途径。
在本文中,我们将介绍 三个顶级 API 提供商——Novita AI、Deepinfra 和 Nebius——并精确展示如何免费或以近乎零成本开始使用。
Llama 3.2 1B 是什么?
Llama 3.2 1B 模型是 Meta 开发的一个轻量级多语言大型语言模型,旨在于边缘和移动设备上高效运行,同时为各种自然语言处理任务提供强劲性能。
-
模型大小: 1B
-
开源: 是
-
架构: 密集 Transformer
-
上下文长度: 128,000 tokens
-
支持的多语言:
- 官方支持:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语、泰语
- 更广泛集合:训练数据包含超过上述 8 种语言的更多语言。
-
多模态能力:
- 输入:文本
- 输出:文本与代码
-
训练方法: Llama 3.2 1B 通过对 Llama 3.1 8B 模型进行结构化剪枝来训练,系统性地移除网络部分并调整权重,从而创建更小、更高效的模型。它还采用了知识蒸馏,在预训练期间将 Llama 3.1 8B 和 70B 模型的 logits 作为 token 级别的目标。这种方法使 Llama 3.2 1B 能够利用更大模型的见解,在剪枝后提升性能。
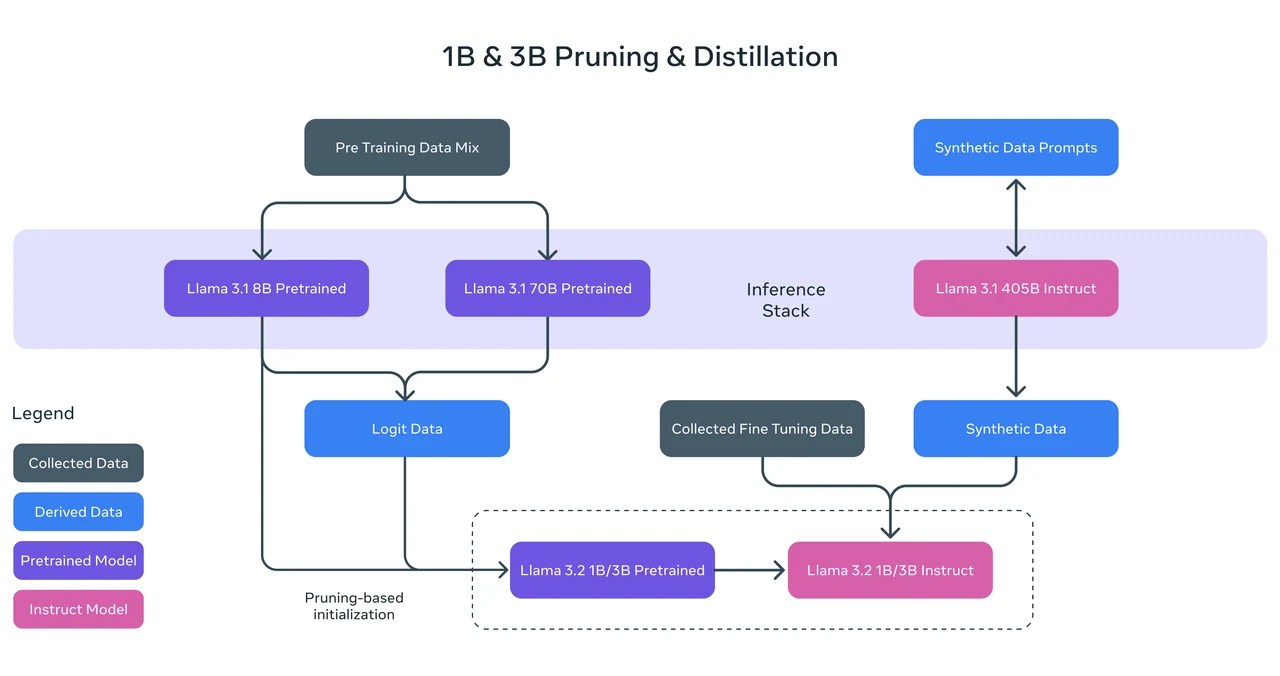
Llama 3.2 1B 基准测试
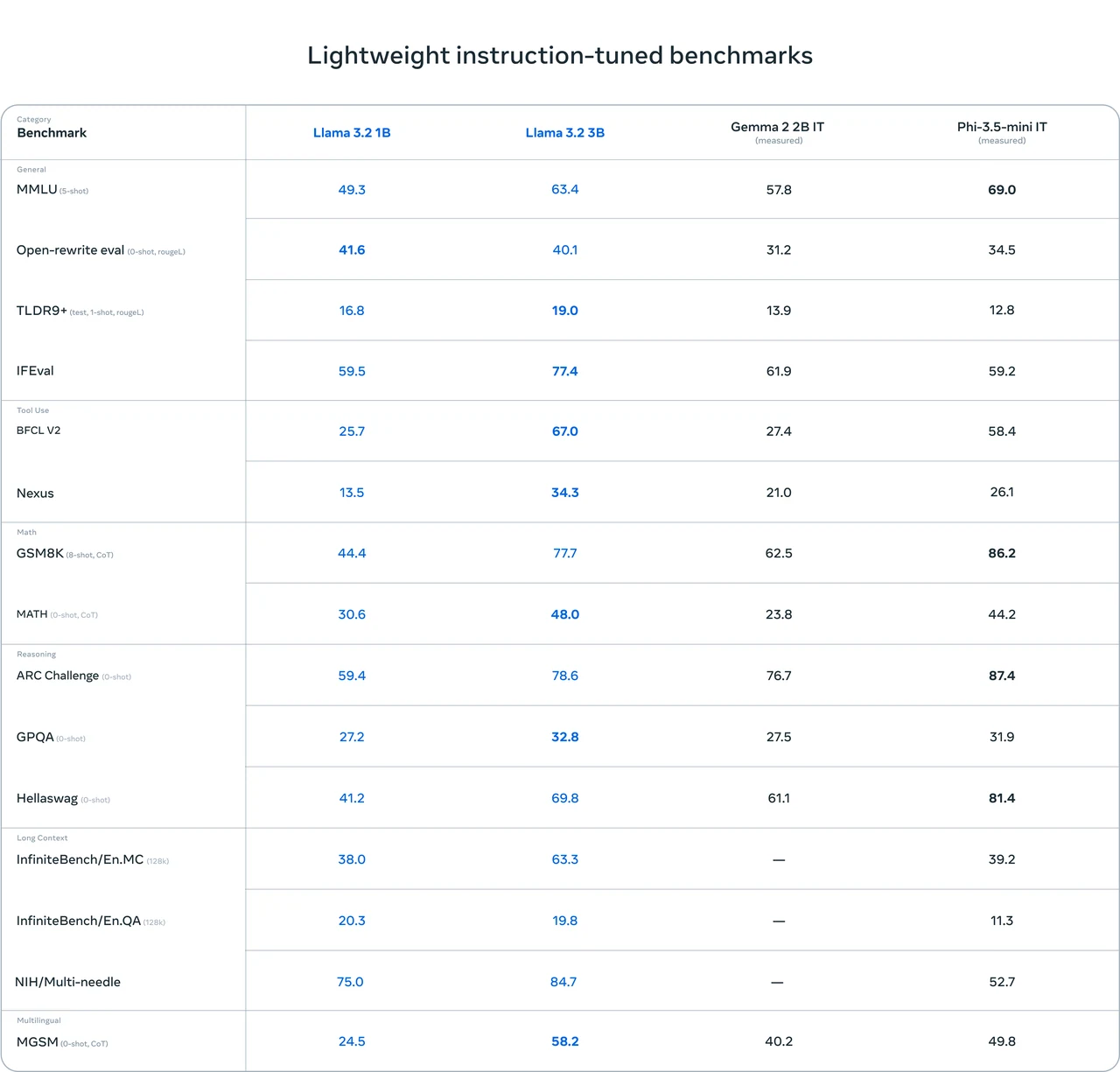
Llama 3.2 1B 硬件需求
推理细节
-
模型: Llama 3.2 1B
-
量化: FP16
-
推理所需显存: 3.14 GB
-
兼容 GPU:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
微调细节
- 模型: Llama 3.2 1B
- 量化: FP16
- 微调所需显存: 14.11 GB
- 兼容 GPU: RTX 4090 (24 GB)
尽管 LLaMA 3.2 1B 的显存需求相对较低,但这并不意味着部署轻而易举。
API——一种简单、一键式使用方式
API 的优势
- 即时启动,无需本地设置: 无需高端服务器或复杂配置。降低部署与维护成本。
- 高可用性与弹性伸缩: 自动处理高流量;通过动态伸缩保证正常运行时间。
- 始终使用最新模型与功能: 持续更新使系统保持最新算法与特性。
- 标准化、易集成: RESTful、gRPC、GraphQL API 确保与多个平台和语言的兼容性。
- 丰富的额外功能: 包括监控、日志记录、速率限制、微调和私有部署。
- 多平台支持: API 可服务于 Web、移动应用、IoT 设备等。
如何选择 API 提供商?
为了支持开发者社区,Llama 3.2 1B、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B 现已在 Novita AI 上免费提供。
最大输出:
- 衡量模型单次响应能生成的最大 tokens 数量。
- 越高越好
- 示例:Llama 4 Scout 支持 131,000 tokens。
输入成本:
- 每百万输入 tokens 的费用(如提示词、上下文)。
- 越低越好
- 示例:Llama 4 Scout 每 1M 输入 tokens 成本 $0.1。
输出成本:
- 每百万输出 tokens 的费用(如模型响应)。
- 越低越好
- 示例:Llama 4 Scout 每 1M 输出 tokens 成本 $0.5。
延迟:
- 请求与响应之间的时间延迟。
- 越低越好
- 对聊天机器人、实时翻译和交互系统至关重要。
吞吐量:
- 每秒处理的请求数量。
- 越高越好
- 确保能够流畅处理并发请求或批量处理。
三大 Llama 3.2 1B API 提供商
1. Novita AI
Novita AI 是一个先进的 AI 云平台,让开发者能够通过简单的 API 轻松部署 AI 模型。同时,它还提供经济实惠且可靠的 GPU 云,用于构建和扩展 AI 解决方案。

为什么选择 Novita AI?
1. 开发效率
- 内置多模态模型: 如 DeepSeek V3、DeepSeek R1 和 LLaMA 3.3 70B 等先进模型已集成并立即可用——无需额外设置。
- 简化部署: 开发者可以快速轻松地启动 AI 模型,无需专门的 AI 团队或复杂流程。
2. 成本优势
- 自有优化: 独特的优化技术将推理成本比主流提供商降低 30%-50%,使 AI 更加经济实惠。可查看此页面的价格。
3. 扩展性
- Novita AI 支持模型的函数调用和结构化输出。您可以点击 “My Model” 查看特定模型是否支持这些功能。
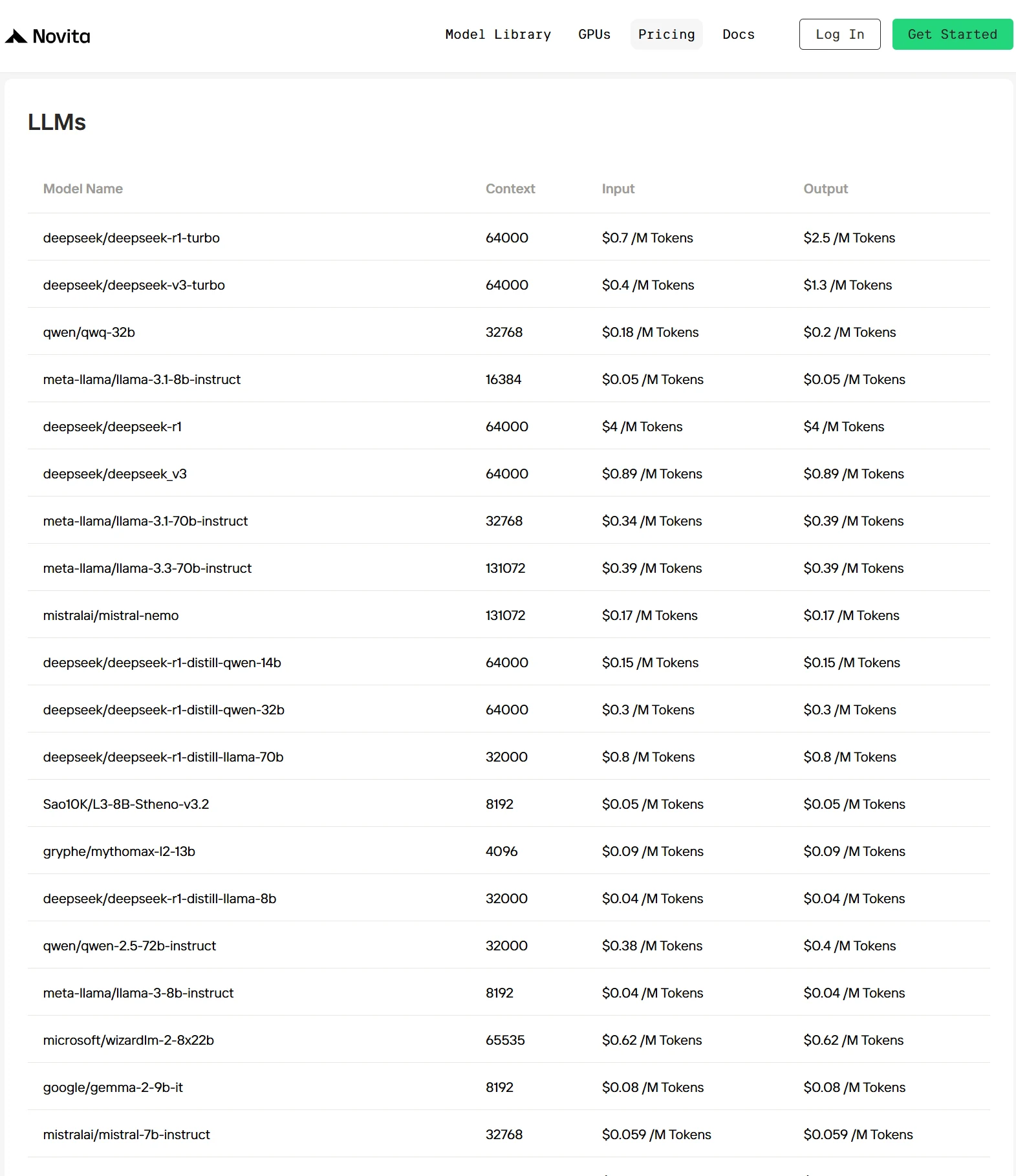
如何通过 Novita API 接入 Llama 3.2 1B?
第 1 步:登录并访问模型库
登录您的账户,点击 Model Library 按钮。

第 2 步:开始免费试用
开始免费试用,探索所选模型的能力。
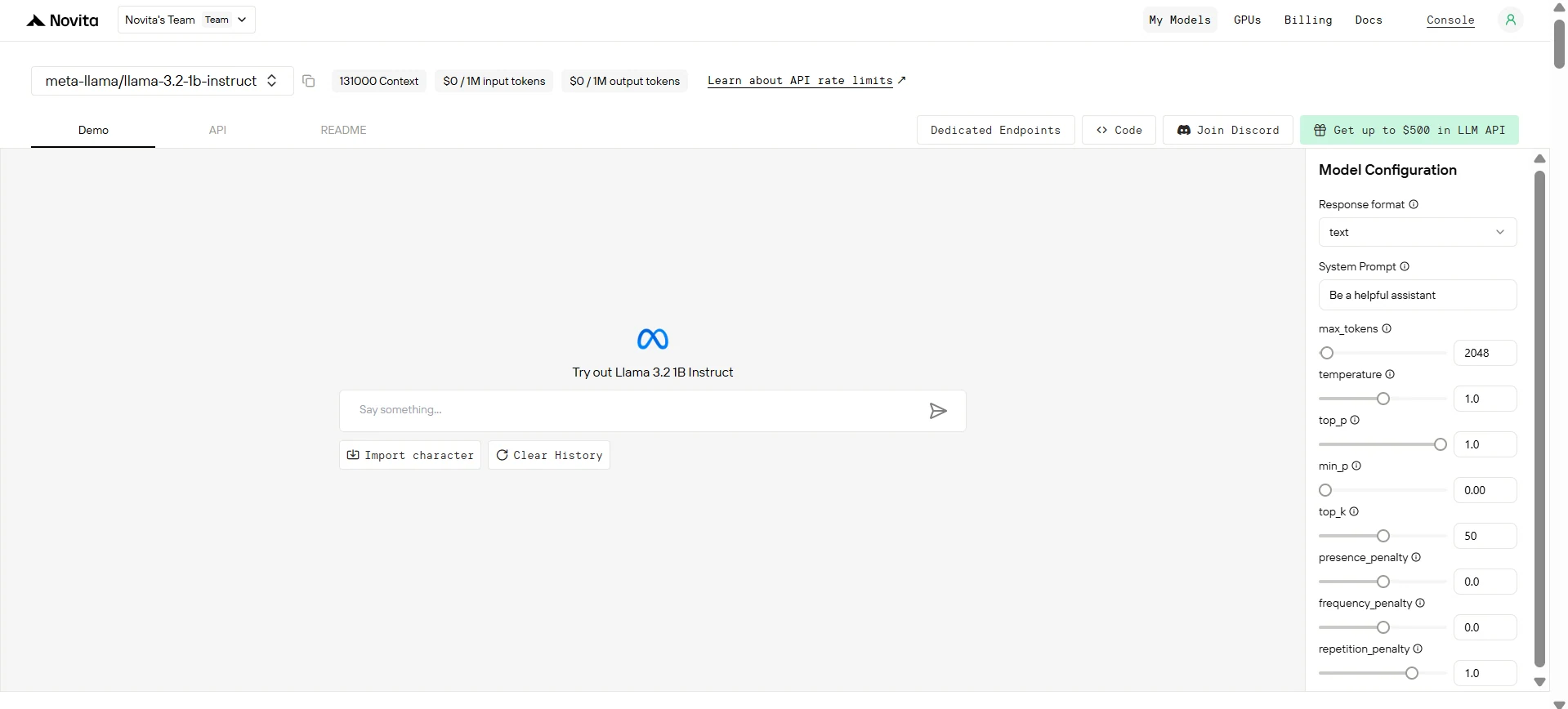
第 3 步:获取 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“Settings”页面,您可以复制 API 密钥,如下图所示。

第 4 步:安装 API
使用特定于编程语言的包管理器安装 API。

安装后,将必要的库导入开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。这是一个适用于 Python 用户的 chat completions API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. Deepinfra
Deepinfra 让通过简单 API 访问领先 AI 模型变得轻松。享受经济实惠的按需付费计划、可扩展的性能以及为实际部署打造的可靠基础设施。
为什么选择 Deepinfra?

如何通过 Deepinfra 接入 Llama 3.2 1B?
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
3. Nebius AI
Nebius 是一个一体化 AI 开发平台,简化了在高性能 NVIDIA GPU 上的模型创建、微调和部署,为企业级应用提供卓越的效率和速度。

为什么选择它?
高性能骨干:Nebius 的 AI 优化云平台利用先进 NVIDIA H100/H200 GPU 和 InfiniBand 连接,通过灵活、高吞吐量的 API 实现强大的模型微调、无缝扩展和低延迟数据处理。

如何通过 Nebius 接入 Llama 3.2 1B?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
Llama 3.2 1B 实现了罕见的平衡:高性能、低资源需求以及通过现代 API 轻松接入。无论您是在笔记本电脑 GPU 上部署还是扩展云应用,该模型都是一个经济高效的强大工具。而且借助 Novita AI 等平台提供的免费访问和扩展功能,开发人员现在没有理由不开始使用。
常见问题
Llama 3.2 1B 是开源的吗?
是的,它完全开源,由 Meta 开发。
运行 Llama 3.2 1B 需要什么硬件?
推理:3.14 GB 显存(例如 RTX 4060)
微调:14.11 GB 显存(例如 RTX 4090)
如何在没有 GPU 的情况下使用 Llama 3.2 1B?
使用 Novita AI 的免费 API。只需登录,获取密钥,然后开始调用模型。
Novita AI 是一个 AI 云平台,让开发者能够通过简单的 API 轻松部署 AI 模型,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。



