

友達を Novita AI に紹介すると、あなたと友達の両方が LLM API クレジットとして $10 を獲得できます。最大 $500 まで獲得可能です。
開発者コミュニティを支援するため、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B が現在 Novita AI で無料で利用できます。

誰もが Llama 3.2 1B を完璧な「オンデバイス」言語モデルとして話題にしています。小型で多言語対応、高効率——モバイルアプリやエッジデバイス向けの夢のツールのように 聞こえます。
しかし、実際にローカルで実行するのはそう簡単ではありません。ラグが発生したり、クラッシュしたり、予想以上にセットアップが必要になることがあります。そこで API アクセスが状況を一変させます。インストール不要、弾力的なスケーラビリティ、ほぼ即時の応答により、API は Llama 3.2 1B のパワーを引き出す最もスムーズな方法を提供します。
この記事では、3つのトップティア API プロバイダー——Novita AI、Deepinfra、Nebius——を紹介し、無料またはほぼ無料で始める方法を正確に説明します。
Llama 3.2 1B とは?
Llama 3.2 1B モデルは、Meta が開発した軽量で多言語対応の大規模言語モデルです。エッジやモバイルデバイスで効率的に動作するように設計されており、さまざまな自然言語処理タスクで強力なパフォーマンスを発揮します。
-
モデルサイズ: 1B
-
オープンソース: はい
-
アーキテクチャ: Dense Transformer
-
コンテキスト長: 128,000 トークン
-
対応多言語:
- 公式対応: 英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語
- より広範なコレクション: 上記8言語以外の言語でもトレーニング済み。
-
マルチモーダル機能:
- 入力: テキスト
- 出力: テキストとコード
-
トレーニング手法: Llama 3.2 1B は、Llama 3.1 8B モデルからの構造化プルーニングを使用してトレーニングされました。ネットワークの一部を体系的に削除し、重みを調整することで、小型で効率的なモデルを作成しました。また、Llama 3.1 8B および 70B モデルからのロジットを、事前トレーニング中のトークンレベルのターゲットとして使用する知識蒸留も採用しました。このアプローチにより、Llama 3.2 1B はより大きなモデルからの洞察を活用し、プルーニング後のパフォーマンスを向上させることができました。
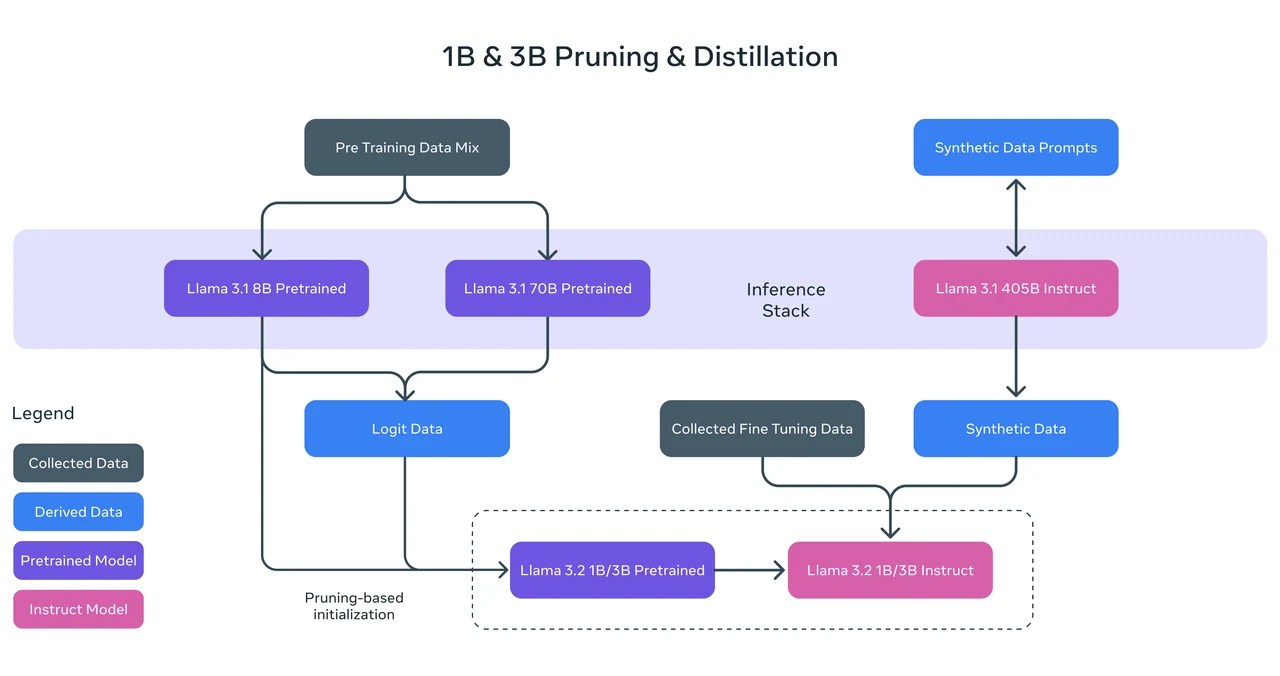
Llama 3.2 1B ベンチマーク
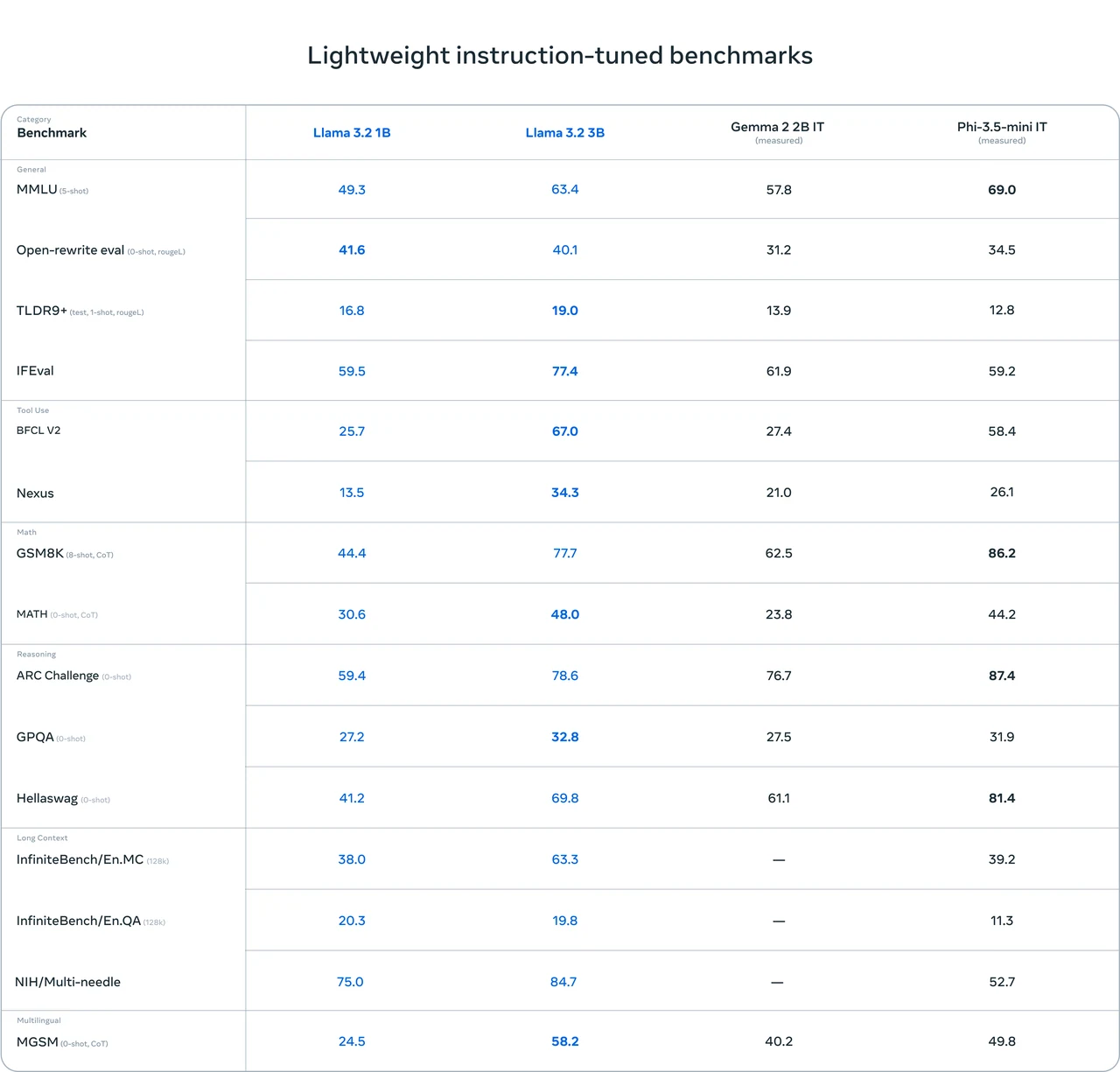
Llama 3.2 1B ハードウェア要件
推論の詳細
-
モデル: Llama 3.2 1B
-
量子化: FP16
-
必要 VRAM (推論): 3.14 GB
-
互換性のある GPU:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
ファインチューニングの詳細
- モデル: Llama 3.2 1B
- 量子化: FP16
- 必要 VRAM (ファインチューニング): 14.11 GB
- 互換性のある GPU: RTX 4090 (24 GB)
LLaMA 3.2 1B は比較的低い VRAM 要件ですが、それでもデプロイが簡単というわけではありません。
API – シンプルでワンクリックの利用方法
API の利点
- 即時開始、ローカル設定不要: ハイエンドサーバーや複雑な設定は不要。デプロイとメンテナンスのコストを削減します。
- 高可用性と弾力的なスケーリング: 大量のトラフィックを自動的に処理。動的スケーリングで稼働時間を確保します。
- 常に最新のモデルと機能: 継続的なアップグレードにより、システムは最新のアルゴリズムと機能に対応します。
- 標準化された簡単な統合: RESTful、gRPC、GraphQL API により、複数のプラットフォームや言語との互換性を確保します。
- 豊富な追加機能: モニタリング、ログ、レート制限、ファインチューニング、プライベートデプロイなどを含みます。
- マルチプラットフォーム対応: API は Web、モバイルアプリ、IoT デバイスなど、さまざまな環境で利用可能です。
API プロバイダーの選び方
開発者コミュニティを支援するため、Llama 3.2 1B、Qwen2.5-7B、Qwen 3 0.6B、Qwen 3 1.7B、Qwen 3 4B が現在 Novita AI で無料で利用できます。
最大出力:
- モデルが1回の応答で生成できる最大トークン数を測定します。
- 高いほど良い
- 例: Llama 4 Scout は 131,000 トークン をサポート。
入力コスト:
- 100万入力トークンあたりのコスト(例: プロンプト、コンテキスト)。
- 低いほど良い
- 例: Llama 4 Scout は 100万入力トークンあたり $0.1。
出力コスト:
- 100万出力トークンあたりのコスト(例: モデルの応答)。
- 低いほど良い
- 例: Llama 4 Scout は 100万出力トークンあたり $0.5。
レイテンシ:
- リクエストから応答までの時間遅延。
- 低いほど良い
- チャットボット、ライブ翻訳、インタラクティブシステムにとって重要。
スループット:
- 1秒あたりに処理されるリクエスト数。
- 高いほど良い
- 同時リクエストやバッチ処理をスムーズに処理できる。
Llama 3.2 1B のトップ3 API プロバイダー
1. Novita AI
Novita AI は、開発者がシンプルな API を介して AI モデルを簡単にデプロイできる高度な AI クラウドプラットフォームです。また、AI ソリューションの構築とスケーリングのための手頃で信頼性の高い GPU クラウドも提供します。

Novita AI を選ぶべき理由
1. 開発効率
- 組み込みのマルチモーダルモデル: DeepSeek V3、DeepSeek R1、LLaMA 3.3 70B などの高度なモデルがすでに統合されており、追加設定なしですぐに利用可能。
- 合理化されたデプロイ: 開発者は専門の AI チームや複雑な手順を必要とせず、AI モデルを迅速かつ簡単に起動できます。
2. コスト優位性
- 独自の最適化: 独自の最適化技術により、大手プロバイダーと比較して推論コストを30%~50%削減し、AI をより手頃な価格にします。価格はこのページで確認できます。
3. 拡張性
- Novita AI はモデルの関数呼び出しと構造化出力をサポートしています。「My Model」をクリックして、特定のモデルがこれらの機能をサポートしているか確認できます。
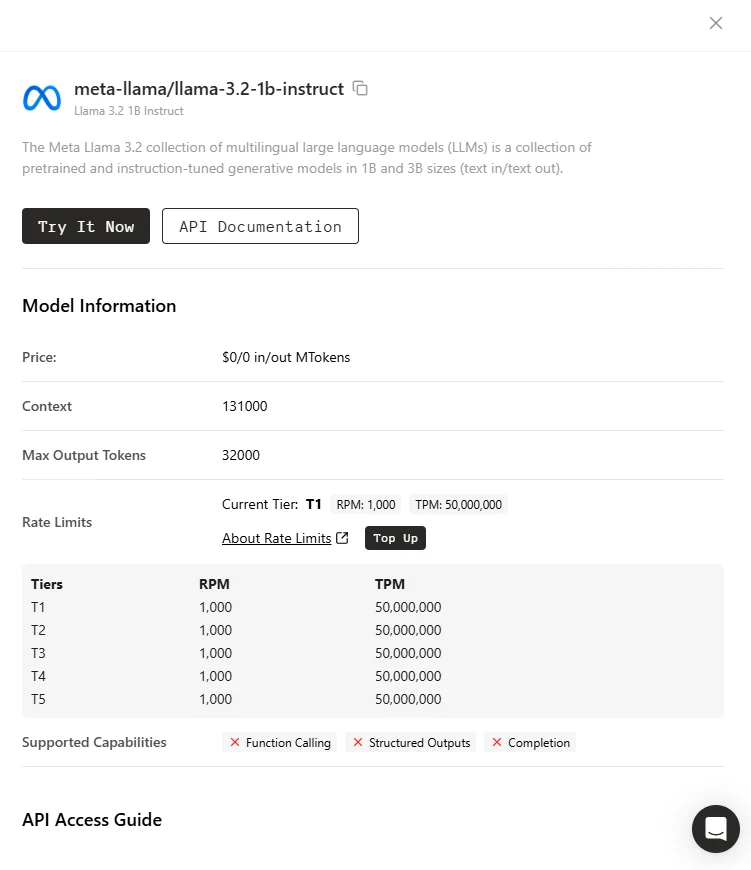
Novita API 経由で Llama 3.2 1B にアクセスする方法
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ 2: 無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試します。
ステップ 3: API キーを取得
API で認証するために、新しい API キーを提供します。「Settings」ページに移動し、画像のように API キーをコピーします。

ステップ 4: API をインストール
使用するプログラミング言語に応じたパッケージマネージャーを使用して API をインストールします。

インストール後、必要なライブラリを開発環境にインポートします。API キーを使用してクライアントを初期化し、Novita AI LLM との対話を開始します。これは Python ユーザー向けのチャット補完 API の使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. Deepinfra
Deepinfra は、シンプルな API を通じて主要な AI モデルへのアクセスを容易にします。コスト効率の良い従量課金制、スケーラブルなパフォーマンス、実運用に信頼性の高いインフラストラクチャをお楽しみいただけます。
Deepinfra を選ぶべき理由

Deepinfra 経由で Llama 3.2 1B にアクセスする方法
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
3. Nebius AI
Nebius は、高性能 NVIDIA GPU 上でのモデル作成、ファインチューニング、デプロイを効率化するオールインワン AI 開発プラットフォームです。エンタープライズグレードのアプリケーションに卓越した効率性とスピードを提供します。

Nebius AI を選ぶべき理由
高性能バックボーン: Nebius の AI 最適化クラウドプラットフォームは、InfiniBand 接続を備えた高度な NVIDIA H100/H200 GPU を活用します。柔軟で高スループットな API により、強力なモデルファインチューニング、シームレスなスケーリング、低レイテンシのデータ処理を可能にします。

Nebius AI 経由で Llama 3.2 1B にアクセスする方法
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
Llama 3.2 1B は、高いパフォーマンス、低リソース需要、そして最新 API による簡単なアクセスという、稀有なバランスを実現しています。ラップトップの GPU にデプロイする場合でも、クラウドアプリをスケーリングする場合でも、このモデルはコスト効率の高い強力な選択肢です。Novita AI のようなプラットフォームが無料アクセスと拡張機能を提供している今、開発者が始められない言い訳はありません。
よくある質問
Llama 3.2 1B はオープンソースですか?
はい、完全にオープンソースで、Meta によって開発されています。
Llama 3.2 1B を実行するにはどのようなハードウェアが必要ですか?
推論: 3.14 GB VRAM(例: RTX 4060)
ファインチューニング: 14.11 GB VRAM(例: RTX 4090)
GPU なしで Llama 3.2 1B を使用するにはどうすればよいですか?
Novita AI の無料 API を使用してください。ログインしてキーを取得し、モデルを呼び出し始めるだけです。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、AI ソリューションの構築とスケーリングのための手頃で信頼性の高い GPU クラウドも提供します。



