

Key Highlights
Extreme VRAM Demands: Llama 4 Maverick requires up to 145,016GB VRAM for FP16/128K configurations, far exceeding consumer GPUs (e.g., H100’s 80GB).
Massive Hardware Costs: Deploying FP16 models demands thousands of H100 GPUs, costing $120K–$480K, excluding operational expenses.
API Simplifies Access: Novita AI’s API eliminates hardware burdens, enabling low-cost, scalable usage without GPU clusters or distributed training.
Llama 4 Maverick is a high-performance LLM optimized for long-context tasks (up to 128K tokens) but demands extraordinary computational resources. Its FP16/128K configuration requires 145,016GB VRAM and 5,016 H100 GPUs, making local deployment impractical for most users. While INT4 quantization reduces hardware needs, precision trade-offs persist. For developers, Novita AI’s API offers an affordable alternative, bypassing hardware costs and technical complexities while maintaining full model capabilities.
Llama 4 Maverick VRAM Requirements
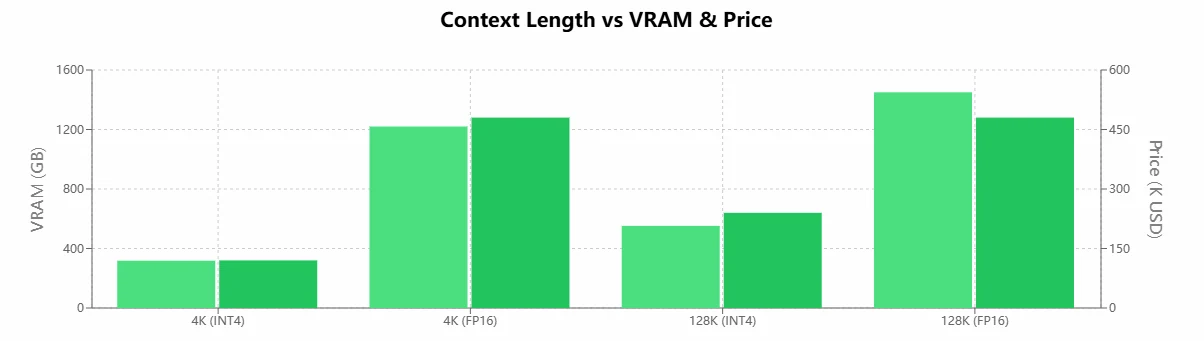
| Context Length | Precision | VRAM (GB) | H100 Count | Price (K USD) |
|---|---|---|---|---|
| Llama 4 Maverick 4K Tokens | INT4 | 318 | 4 | $120K |
| Llama 4 Maverick 4K Tokens | FP16 | 1220 | 16 | $480K |
| Llama 4 Maverick 128K Tokens | INT4 | 552 | 8 | $240K |
| Llama 4 Maverick 128K Tokens | FP16 | 1450 | 16 | $480K |
Major Challenges of Running Llama 4 Maverick Locally
High VRAM (Video Memory) Requirements
- Problem: VRAM requirements vary significantly depending on the configuration. For example:
- Under FP16 precision, 4K context requires 122,016 GB VRAM, and 128K context requires 145,016 GB VRAM—far beyond the capacity of current consumer-grade GPUs.
- Impact: This necessitates a large number of GPUs:
- For instance, the FP16 4K version would require 2016 H100 GPUs, making hardware costs and technical complexity extremely high.
Extremely High Hardware Costs
- Cost: The hardware alone costs between $120K and $480K, excluding electricity, cooling, and maintenance expenses.
- H100 Quantity: High-precision or long-context models require hundreds to thousands of H100 GPUs:
- For example, the FP16 128K version would require 5016 H100 GPUs, making actual deployment nearly impossible.
Trade-offs Between Context Length and Precision
- INT4 Precision: Reduces VRAM requirements, but quantization may degrade model performance.
- FP16 Precision: Retains higher precision but results in exponentially higher VRAM and computational demands.
Software and Training Complexity
- Requires distributed training frameworks to support multi-GPU parallelism. However, debugging and optimization are extremely challenging.
Potential Solutions for Running Llama 4 Maverick Locally
Quantization and Model Compression
- Prioritize INT4 quantization to reduce VRAM and GPU requirements at the expense of a slight precision trade-off.
- Combine with dynamic quantization or sparsity techniques to further reduce resource consumption.
Distributed Computing Optimization
- Implement model parallelism + pipeline parallelism to shard the model across multiple GPUs, reducing the VRAM burden on individual GPUs.
- Use ZeRO-Offload technology to offload parts of the computation to CPUs or disk storage.
Mixed-Precision Training
- Use FP16 precision in critical layers and INT4 precision in other layers to balance precision and efficiency.
API Access: An Affordable Solution for Independent Developerspers
API Access Benefits
Eliminates High Hardware Costs
- Benefit: Developers can access powerful models via APIs hosted on cloud infrastructure without purchasing expensive GPUs like H100.
- How It Helps:
- No upfront hardware investment.
- Pay-as-you-go pricing models allow developers to scale usage based on their needs, drastically reducing costs for small-scale projects.
Bypasses High VRAM Requirements
- Benefit: The heavy computational and memory requirements (e.g., 145,016 GB VRAM for 128K context) are handled by the API provider, so developers don’t need to worry about hardware limitations.
- How It Helps:
- Even consumer-grade devices or low-resource environments can access advanced models.
- Long-context processing becomes feasible without managing distributed GPU setups.
Simplifies Software and Training Complexity
- Benefit: APIs abstract away the need for distributed training frameworks (e.g., DeepSpeed or Megatron) and multi-GPU parallelism.
- How It Helps:
- Developers don’t need to spend time debugging or optimizing distributed systems.
- Models are pre-trained and optimized by the API provider, allowing users to focus solely on application development.
Scalable and On-Demand Access
- Benefit: APIs allow developers to scale usage up or down based on demand, making them ideal for projects with fluctuating requirements.
- How It Helps:
- No need to maintain idle GPUs during low usage periods.
- Handle traffic spikes or increased workloads seamlessly without additional infrastructure.
Reduces Maintenance and Operational Costs
- Benefit: APIs include built-in maintenance, updates, and model improvements managed by the provider.
- How It Helps:
- Developers no longer worry about upgrading hardware, cooling, or electricity costs.
- Always have access to the latest model versions and optimizations without manual intervention.
Novita AI: A Reliable and Cost-Effective API Solution
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
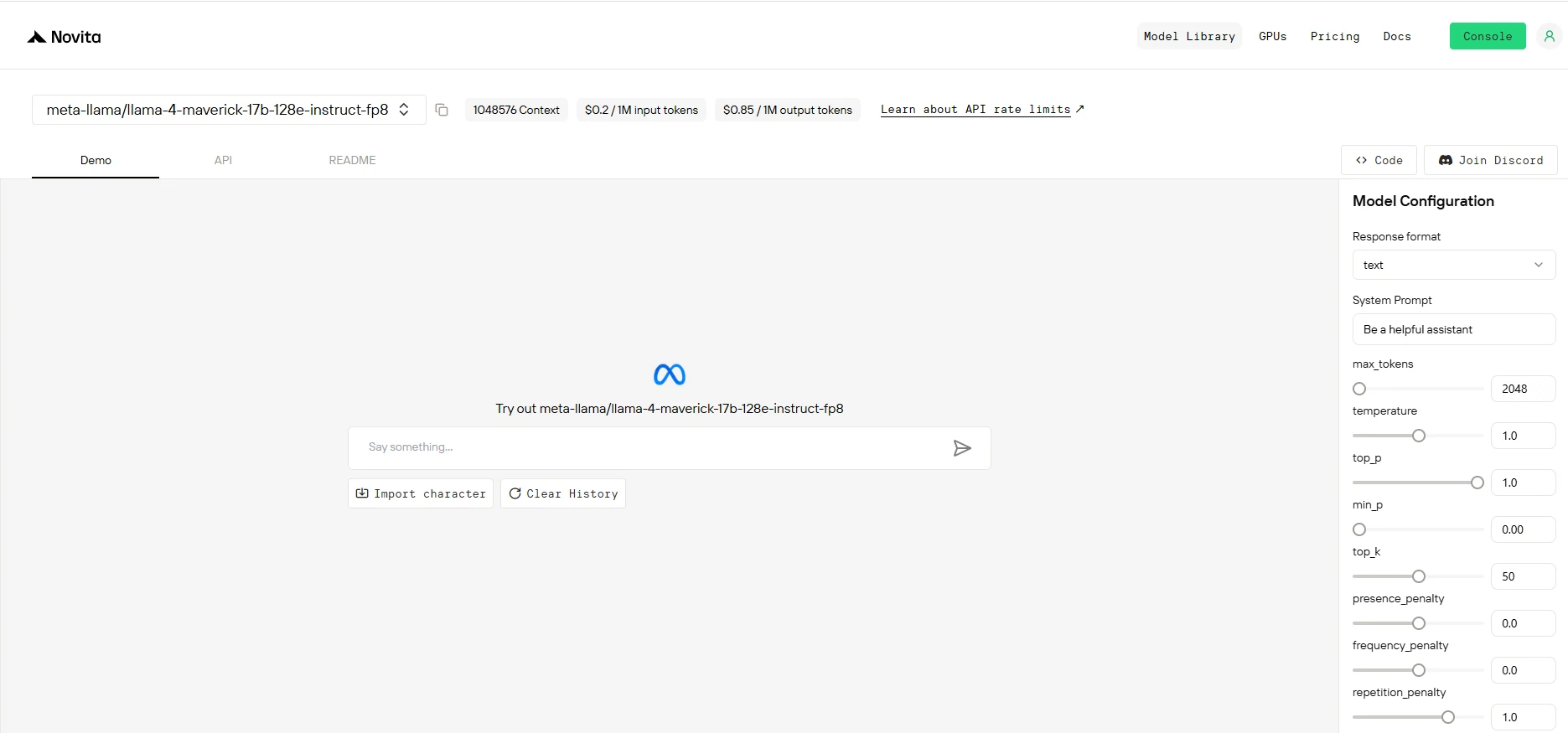
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Llama 4 Maverick’s power comes with prohibitive hardware requirements, limiting local deployment to large enterprises. Quantization and distributed computing offer partial relief but add complexity. Novita AI’s API democratizes access, allowing developers to leverage its advanced features cost-effectively. By prioritizing scalability and simplicity, API solutions bridge the gap between cutting-edge AI and practical, real-world applications.
Frequently Asked Questions
Why is running Llama 4 Maverick locally challenging?
Even high-end GPUs lack sufficient VRAM; FP16/128K demands 5,016 H100s, costing $480K. You can choose cost effective API like Novita AI!
What is Llama 4 Maverick’s key differentiator?
It supports ultra-long contexts but requires extreme VRAM, necessitating specialized infrastructure.
Does Llama 4 Maverick INT4 quantization degrade performance?
Slightly, but it reduces VRAM needs by 96%.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing an affordable and reliable GPU cloud for building and scaling.



