

Wichtige Highlights
Extreme VRAM-Anforderungen: Llama 4 Maverick benötigt bis zu 145.016 GB VRAM für FP16/128K-Konfigurationen – weit über den Kapazitäten von Consumer-GPUs (z. B. H100 mit 80 GB).
Massive Hardware-Kosten: Der Einsatz von FP16-Modellen erfordert Tausende von H100-GPUs und kostet 120.000–480.000 USD, ohne Berücksichtigung der Betriebskosten.
API vereinfacht den Zugriff: Die API von Novita AI eliminiert Hardware-Hürden und ermöglicht kostengünstige, skalierbare Nutzung ohne GPU-Cluster oder verteiltes Training.
Llama 4 Maverick ist ein leistungsstarkes Large Language Model (LLM), das für lang kontextbezogene Aufgaben (bis zu 128K Tokens) optimiert ist, aber außergewöhnliche Rechenressourcen erfordert. Die FP16/128K-Konfiguration benötigt 145.016 GB VRAM und 5.016 H100-GPUs, was eine lokale Bereitstellung für die meisten Benutzer unpraktikabel macht. Während INT4-Quantisierung die Hardware-Anforderungen reduziert, bleiben Präzisionsabwägungen bestehen. Für Entwickler bietet die API von Novita AI eine erschwingliche Alternative, die Hardware-Kosten und technische Komplexität umgeht und dabei die vollständigen Modellfähigkeiten bewahrt.
VRAM-Anforderungen von Llama 4 Maverick
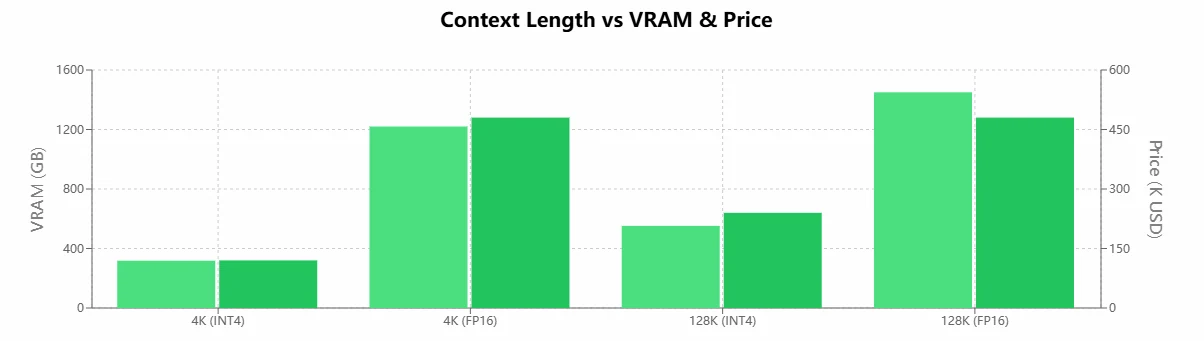
| Kontextlänge | Präzision | VRAM (GB) | H100-Anzahl | Preis (in Tsd. USD) |
|---|---|---|---|---|
| Llama 4 Maverick 4K Tokens | INT4 | 318 | 4 | 120.000 USD |
| Llama 4 Maverick 4K Tokens | FP16 | 1220 | 16 | 480.000 USD |
| Llama 4 Maverick 128K Tokens | INT4 | 552 | 8 | 240.000 USD |
| Llama 4 Maverick 128K Tokens | FP16 | 1450 | 16 | 480.000 USD |
Hauptprobleme beim lokalen Ausführen von Llama 4 Maverick
Hohe VRAM-Anforderungen (Arbeitsspeicher)
- Problem: Die VRAM-Anforderungen variieren stark je nach Konfiguration. Beispiel:
- Bei FP16-Präzision benötigt der 4K-Kontext 122.016 GB VRAM und der 128K-Kontext 145.016 GB VRAM – weit über der Kapazität aktueller Consumer-GPUs.
- Auswirkung: Dies erfordert eine große Anzahl von GPUs:
- Beispielsweise würde die FP16-4K-Version 2016 H100-GPUs benötigen, was die Hardware-Kosten und die technische Komplexität extrem erhöht.
Extrem hohe Hardware-Kosten
- Kosten: Die Hardware allein kostet zwischen 120.000 und 480.000 USD, ohne Strom, Kühlung und Wartung.
- H100-Anzahl: Hochpräzise oder langkontextbezogene Modelle benötigen Hunderte bis Tausende von H100-GPUs:
- Beispielsweise würde die FP16-128K-Version 5016 H100-GPUs erfordern, was eine tatsächliche Bereitstellung nahezu unmöglich macht.
Kompromisse zwischen Kontextlänge und Präzision
- INT4-Präzision: Reduziert den VRAM-Bedarf, aber die Quantisierung kann die Modellleistung beeinträchtigen.
- FP16-Präzision: Bewahrt eine höhere Genauigkeit, führt jedoch zu exponentiell höheren VRAM- und Rechenanforderungen.
Software- und Trainingskomplexität
- Erfordert verteilte Trainings-Frameworks zur Unterstützung von Multi-GPU-Parallelität. Debugging und Optimierung sind jedoch extrem anspruchsvoll.
Mögliche Lösungen für den lokalen Betrieb von Llama 4 Maverick
Quantisierung und Modellkompression
- Bevorzugen Sie INT4-Quantisierung, um VRAM- und GPU-Anforderungen zu reduzieren, allerdings mit einem leichten Präzisionsverlust.
- Kombinieren Sie mit dynamischer Quantisierung oder Sparsity-Techniken, um den Ressourcenverbrauch weiter zu senken.
Optimierung des verteilten Rechnens
- Implementieren Sie Modellparallelität + Pipeline-Parallelität, um das Modell auf mehrere GPUs aufzuteilen und so die VRAM-Last einzelner GPUs zu verringern.
- Nutzen Sie die ZeRO-Offload-Technologie, um Teile der Berechnung auf CPU oder Festplattenspeicher auszulagern.
Gemischte Präzision beim Training
- Verwenden Sie FP16-Präzision in kritischen Schichten und INT4-Präzision in anderen Schichten, um Präzision und Effizienz auszugleichen.
API-Zugriff: Eine erschwingliche Lösung für unabhängige Entwickler
Vorteile des API-Zugriffs
Eliminierung hoher Hardware-Kosten
- Vorteil: Entwickler können über die in der Cloud gehosteten APIs auf leistungsstarke Modelle zugreifen, ohne teure GPUs wie die H100 kaufen zu müssen.
- Wie es hilft:
- Keine anfängliche Hardware-Investition.
- Bezahlmodell „Pay-as-you-go“ ermöglicht es Entwicklern, die Nutzung je nach Bedarf zu skalieren und die Kosten für kleine Projekte drastisch zu senken.
Umgehung hoher VRAM-Anforderungen
- Vorteil: Die schwerwiegenden Rechen- und Speicheranforderungen (z. B. 145.016 GB VRAM für 128K-Kontext) werden vom API-Anbieter übernommen, sodass Entwickler sich keine Gedanken über Hardware-Limits machen müssen.
- Wie es hilft:
- Selbst Geräte der Consumer-Klasse oder ressourcenarme Umgebungen können auf fortschrittliche Modelle zugreifen.
- Die Verarbeitung langer Kontexte wird möglich, ohne verteilte GPU-Setups verwalten zu müssen.
Vereinfachung von Software- und Trainingskomplexität
- Vorteil: APIs abstrahieren die Notwendigkeit von verteilten Trainings-Frameworks (z. B. DeepSpeed oder Megatron) und Multi-GPU-Parallelität.
- Wie es hilft:
- Entwickler müssen keine Zeit für Debugging oder Optimierung verteilter Systeme aufwenden.
- Modelle werden vom API-Anbieter vortrainiert und optimiert, sodass sich die Nutzer ausschließlich auf die Anwendungsentwicklung konzentrieren können.
Skalierbarer und bedarfsgerechter Zugriff
- Vorteil: APIs ermöglichen es Entwicklern, die Nutzung je nach Bedarf zu erhöhen oder zu reduzieren – ideal für Projekte mit schwankenden Anforderungen.
- Wie es hilft:
- Keine Notwendigkeit, GPUs in Schwachlastzeiten ungenutzt zu lassen.
- Problemlose Bewältigung von Verkehrsspitzen oder erhöhten Arbeitslasten ohne zusätzliche Infrastruktur.
Reduzierung von Wartungs- und Betriebskosten
- Vorteil: APIs beinhalten integrierte Wartung, Updates und Modellverbesserungen, die vom Anbieter verwaltet werden.
- Wie es hilft:
- Entwickler müssen sich nicht um Hardware-Upgrades, Kühlung oder Stromkosten kümmern.
- Stets Zugriff auf die neuesten Modellversionen und Optimierungen ohne manuelles Eingreifen.
Novita AI: Eine zuverlässige und kosteneffiziente API-Lösung
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Jetzt Llama 4 Maverick ausprobieren!
Schritt 2: Wählen Sie Ihr Modell aus
Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API erhalten Sie einen neuen API-Schlüssel. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.

Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "meta-llama/llama-4-maverick-17b-128e-instruct-fp8"
stream = True # oder False
max_tokens = 2048
system_content = """Seien Sie ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Die Leistungsfähigkeit von Llama 4 Maverick geht mit unerschwinglichen Hardware-Anforderungen einher, was die lokale Bereitstellung auf große Unternehmen beschränkt. Quantisierung und verteiltes Rechnen bieten eine teilweise Entlastung, erhöhen aber die Komplexität. Die API von Novita AI demokratisiert den Zugang und ermöglicht es Entwicklern, die erweiterten Funktionen kosteneffizient zu nutzen. Durch die Priorisierung von Skalierbarkeit und Einfachheit schließen API-Lösungen die Lücke zwischen hochmoderner KI und praktischen, realen Anwendungen.
Häufig gestellte Fragen
Warum ist die lokale Ausführung von Llama 4 Maverick eine Herausforderung?
Selbst High-End-GPUs haben nicht genug VRAM; FP16/128K erfordert 5.016 H100 und kostet 480.000 USD. Sie können eine kosteneffiziente API wie Novita AI wählen!
Was ist das wichtigste Unterscheidungsmerkmal von Llama 4 Maverick?
Es unterstützt extrem lange Kontexte, benötigt aber ebenso extremes VRAM, was spezialisierte Infrastruktur erforderlich macht.
Verschlechtert die INT4-Quantisierung von Llama 4 Maverick die Leistung?
Leicht, aber sie reduziert den VRAM-Bedarf um 96 %.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Erstellung und Skalierung bereitstellt.



