

Parrainez vos amis sur Novita AI et vous gagnerez tous les deux 10 $ de crédits API LLM – jusqu’à 500 $ de récompenses totales.
Pour soutenir la communauté des développeurs, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B sont actuellement disponibles gratuitement sur Novita AI.

Tout le monde parle de Llama 3.2 1B comme le modèle de langage « sur appareil » parfait. Petit, multilingue et efficace – il semble être l’outil rêvé pour les applications mobiles et les appareils en périphérie.
Mais voici la vérité : l’exécuter localement n’est pas si simple. Il peut ralentir, planter ou nécessiter plus de configuration que prévu. C’est là que l’accès par API change la donne. Sans installation, avec une évolutivité élastique et des réponses quasi instantanées, les API offrent le chemin le plus fluide pour exploiter la puissance de Llama 3.2 1B.
Dans cet article, nous allons présenter trois fournisseurs d’API de premier plan – Novita AI, Deepinfra et Nebius – et vous montrer exactement comment démarrer, gratuitement ou presque sans frais.
Qu’est-ce que Llama 3.2 1B ?
Le modèle Llama 3.2 1B est un modèle de langage multilingue léger développé par Meta, conçu pour fonctionner efficacement sur les appareils mobiles et en périphérie tout en offrant de solides performances pour diverses tâches de traitement du langage naturel.
-
Taille du modèle : 1B
-
Open Source : Oui
-
Architecture : Transformeur dense
-
Longueur de contexte : 128 000 tokens
-
Langues multilingues prises en charge :
- Prise en charge officielle : anglais, allemand, français, italien, portugais, hindi, espagnol, thaï
- Ensemble plus large : entraîné sur des langues supplémentaires au-delà des 8 listées.
-
Capacité multimodale :
- Entrée : Texte
- Sortie : Texte et code
-
Méthode d’entraînement : Llama 3.2 1B a été entraîné à l’aide d’un élagage structuré à partir du modèle Llama 3.1 8B, supprimant systématiquement des parties du réseau tout en ajustant les poids pour créer un modèle plus petit et efficace. Il a également utilisé la distillation des connaissances, où les logits des modèles Llama 3.1 8B et 70B ont été utilisés comme cibles au niveau des tokens pendant le pré-entraînement. Cette approche a permis à Llama 3.2 1B de tirer parti des informations des plus grands modèles, améliorant ainsi ses performances après le processus d’élagage.
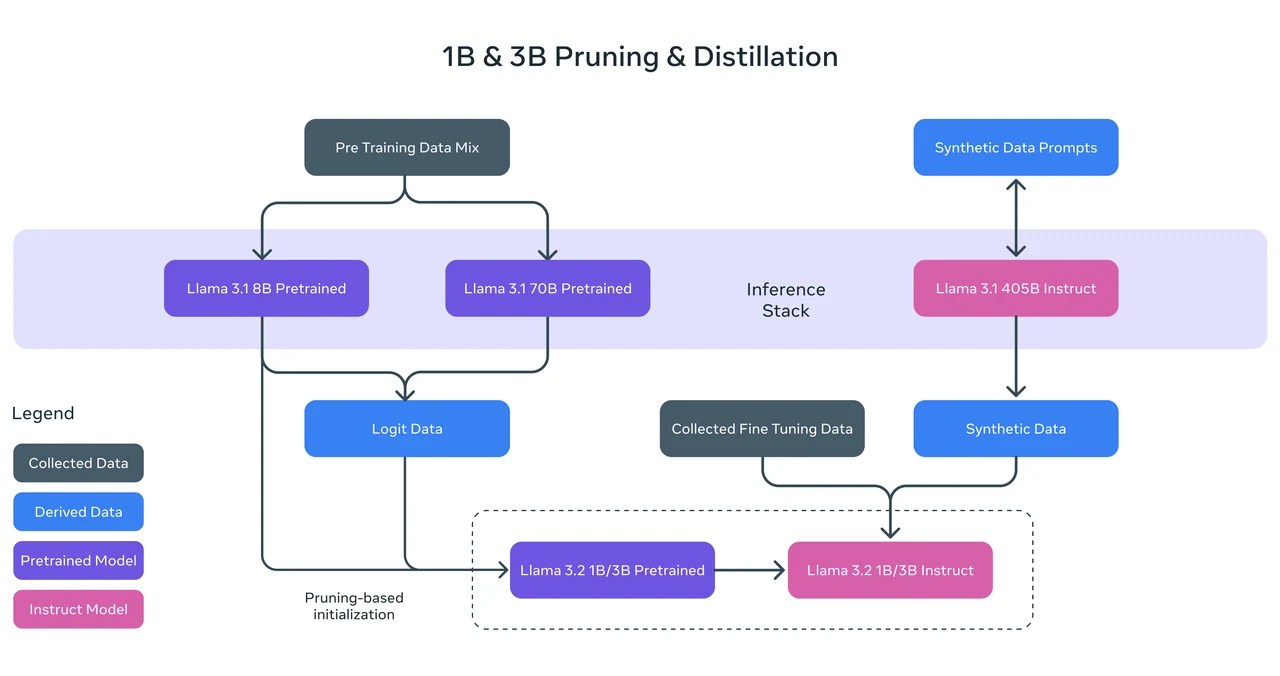
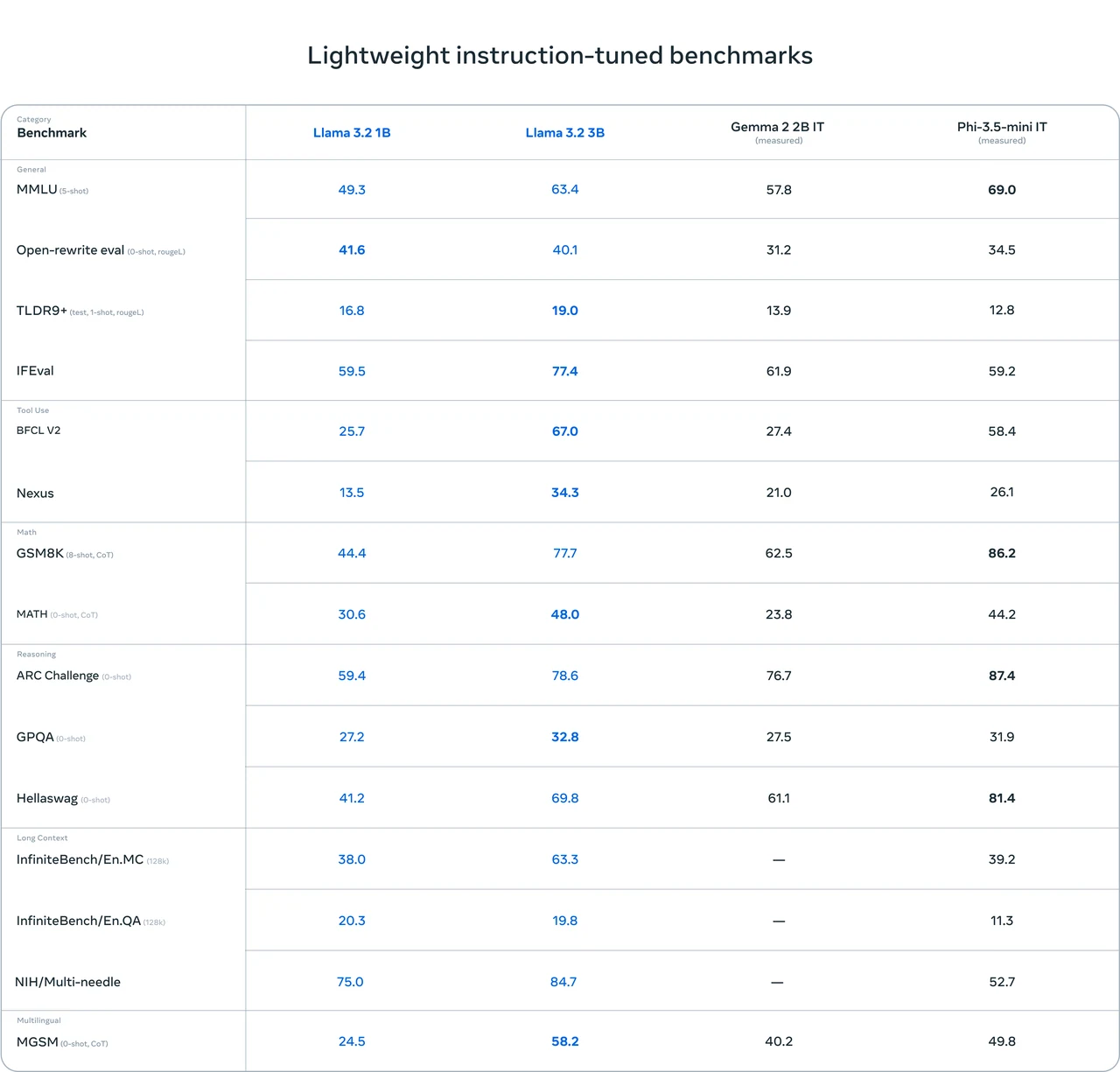
Benchmark de Llama 3.2 1B
Configuration matérielle requise pour Llama 3.2 1B
Détails d’inférence
-
Modèle : Llama 3.2 1B
-
Quantification : FP16
-
VRAM requise (inférence) : 3,14 Go
-
GPU compatibles :
- RTX 3090 (12 Go)
- RTX 4060 (8 Go)
Détails de fine-tuning
- Modèle : Llama 3.2 1B
- Quantification : FP16
- VRAM requise (fine-tuning) : 14,11 Go
- GPU compatible : RTX 4090 (24 Go)
Même si LLaMA 3.2 1B a des besoins en VRAM relativement faibles, cela ne signifie pas que le déploiement est sans effort.
API – Une manière simple et en un clic d’utiliser le modèle
Avantages de l’API
- Démarrage instantané, aucune configuration locale : Pas besoin de serveurs haut de gamme ni de configurations complexes. Réduit les coûts de déploiement et de maintenance.
- Haute disponibilité et mise à l’échelle élastique : Gère automatiquement le trafic important ; garantit la disponibilité avec une mise à l’échelle dynamique.
- Modèles et fonctionnalités toujours à jour : Les mises à niveau continues maintiennent le système à jour avec les derniers algorithmes et fonctionnalités.
- Standardisée et intégration facile : Les API RESTful, gRPC, GraphQL assurent la compatibilité avec plusieurs plateformes et langages.
- Fonctionnalités supplémentaires riches : Inclut la surveillance, la journalisation, la limitation de débit, le fine-tuning et les déploiements privés.
- Support multiplateforme : Les API sont polyvalentes, servant les applications web, mobiles, les appareils IoT, etc.
Comment choisir un fournisseur d’API ?
Pour soutenir la communauté des développeurs, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B sont actuellement disponibles gratuitement sur Novita AI.
Essayez Llama 3.2 1B maintenant !
Sortie maximale :
- Mesure le nombre maximal de tokens que le modèle peut générer en une seule réponse.
- Plus élevé = Mieux
- Exemple : Llama 4 Scout prend en charge 131 000 tokens.
Coût d’entrée :
- Coût par million de tokens d’entrée (par exemple, prompts, contexte).
- Plus bas = Mieux
- Exemple : Llama 4 Scout coûte 0,1 $ par 1M de tokens d’entrée.
Coût de sortie :
- Coût par million de tokens de sortie (par exemple, réponses du modèle).
- Plus bas = Mieux
- Exemple : Llama 4 Scout coûte 0,5 $ par 1M de tokens de sortie.
Latence :
- Délai entre la requête et la réponse.
- Plus bas = Mieux
- Critique pour les chatbots, les traductions en direct et les systèmes interactifs.
Débit :
- Nombre de requêtes traitées par seconde.
- Plus élevé = Mieux
- Assure une gestion fluide des requêtes simultanées ou du traitement par lots.
Top 3 des fournisseurs d’API pour Llama 3.2 1B
1. Novita AI
Novita AI est une plateforme cloud d’IA avancée qui permet aux développeurs de déployer facilement des modèles d’IA via une API simple. Elle fournit également un cloud GPU abordable et fiable pour construire et faire évoluer des solutions d’IA.

Pourquoi choisir Novita AI ?
1. Efficacité de développement
- Modèles multimodaux intégrés : Des modèles avancés comme DeepSeek V3, DeepSeek R1 et LLaMA 3.3 70B sont déjà intégrés et prêts à l’emploi – aucune configuration supplémentaire requise.
- Déploiement simplifié : Les développeurs peuvent lancer des modèles d’IA rapidement et facilement, sans besoin d’une équipe d’IA spécialisée ni de procédures complexes.
2. Avantage de coût
- Optimisation propriétaire : Des technologies d’optimisation uniques réduisent les coûts d’inférence de 30 % à 50 % par rapport aux principaux fournisseurs, rendant l’IA plus abordable. Vous pouvez consulter les prix sur cette page.
3.Extension
- Novita AI prend en charge l’appel de fonctions et la sortie structurée pour les modèles. Vous pouvez cliquer sur “My Model” pour vérifier si un modèle spécifique prend en charge ces fonctionnalités.
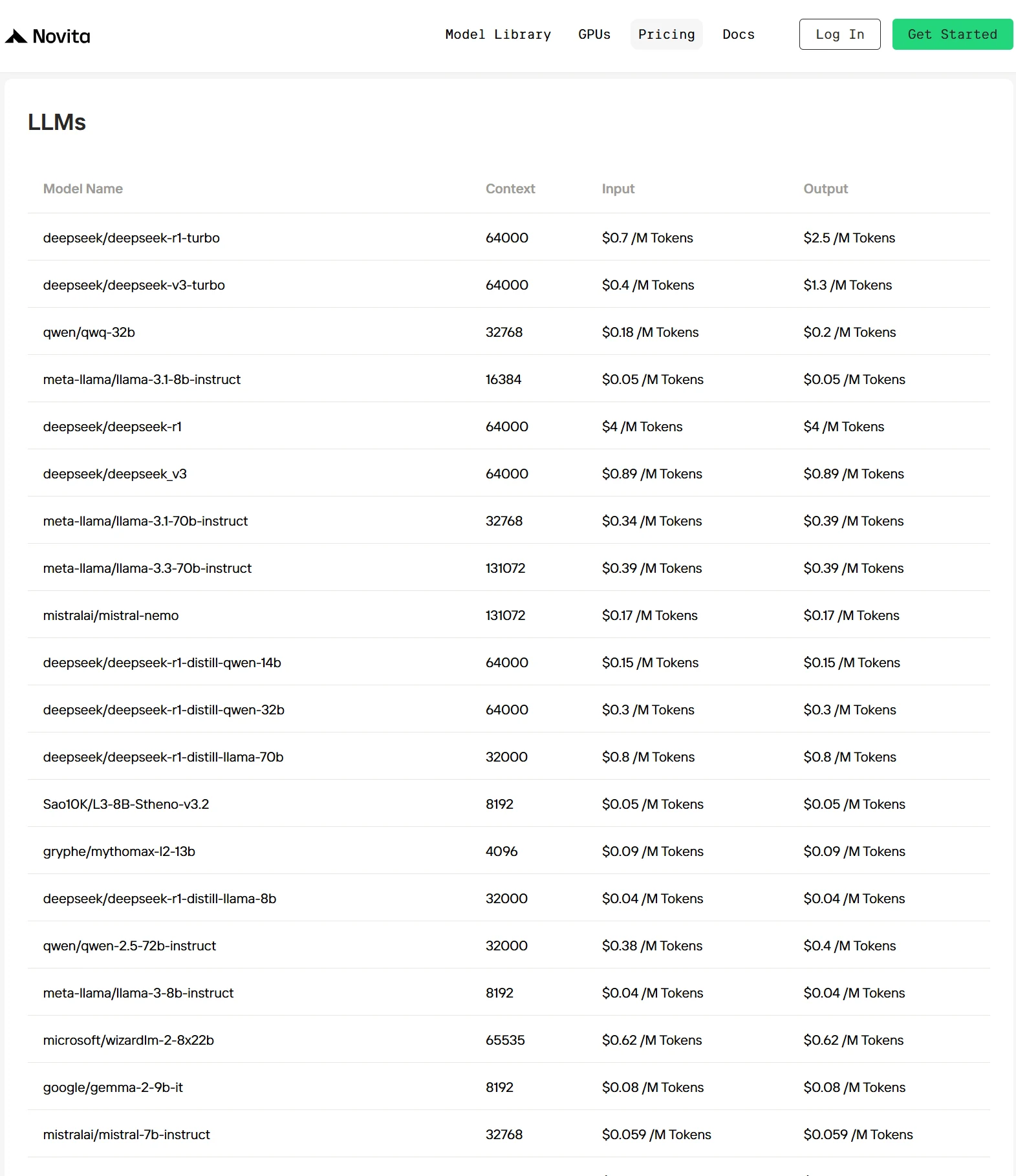
Comment accéder à Llama 3.2 1B via l’API Novita ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.

Essayez Llama 3.2 1B maintenant !
Étape 2 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
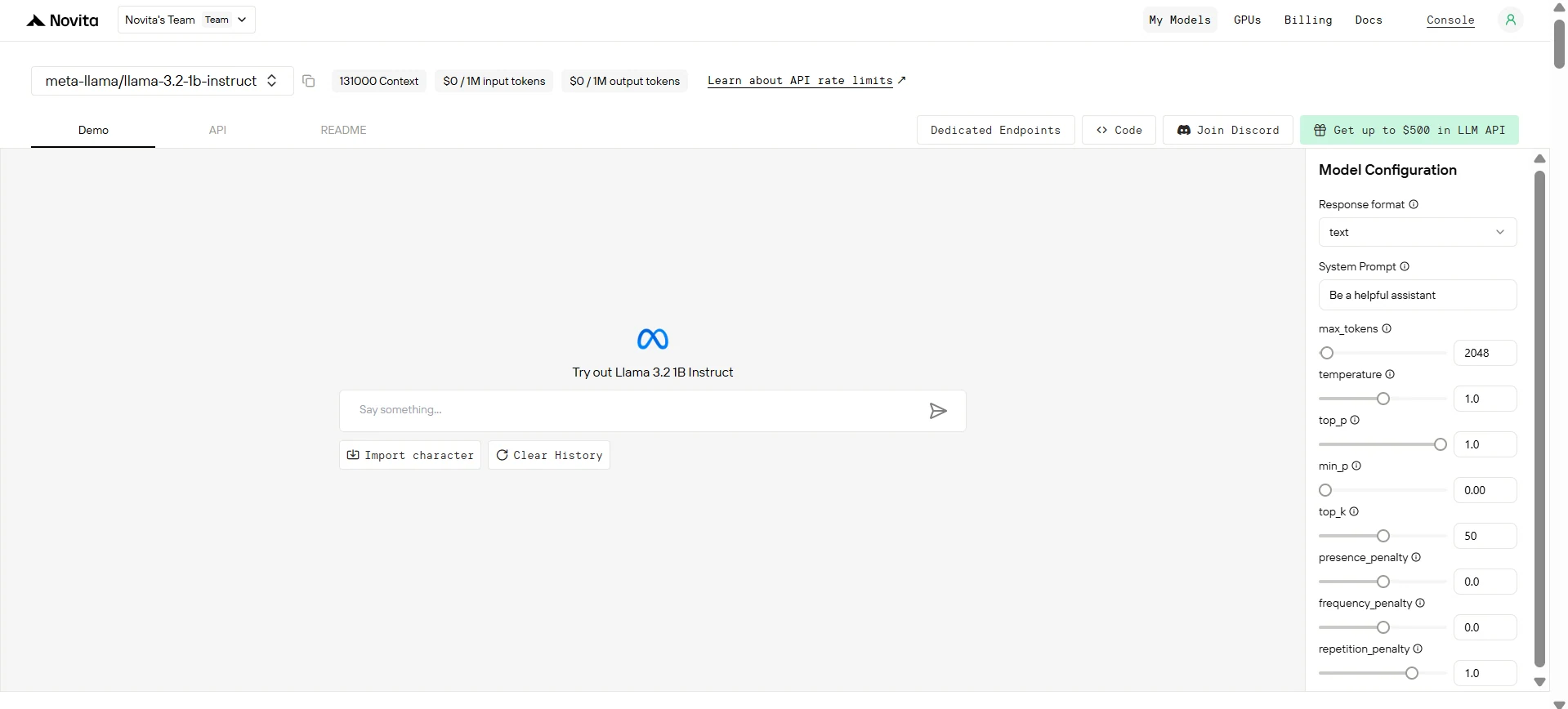
Étape 3 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Settings », vous pouvez copier la clé API comme indiqué dans l’image.

Étape 4 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.

Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2.Deepinfra
Deepinfra facilite l’accès aux principaux modèles d’IA via une API simple. Profitez de plans à l’utilisation économiques, de performances évolutives et d’une infrastructure fiable conçue pour un déploiement réel.
Pourquoi choisir Deepinfra ?

Comment y accéder à Llama 3.2 1B ?
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
3. Nebius AI
Nebius est une plateforme de développement d’IA tout-en-un qui simplifie la création, le fine-tuning et le déploiement de modèles sur des GPU NVIDIA hautes performances, offrant une efficacité et une rapidité exceptionnelles pour les applications d’entreprise.

Pourquoi le choisir ?
Infrastructure hautes performances : La plateforme cloud optimisée pour l’IA de Nebius exploite les GPU NVIDIA H100/H200 avancés avec connectivité InfiniBand, permettant un fine-tuning puissant des modèles, une mise à l’échelle fluide et un traitement des données à faible latence grâce à des API flexibles à haut débit.

Comment accéder à Llama 3.2 1B via Nebius ?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
Llama 3.2 1B offre un rare équilibre : hautes performances, faible demande de ressources et accès facile via des API modernes. Que vous déployiez sur un GPU de PC portable ou que vous mettiez à l’échelle une application cloud, ce modèle est un concentré de puissance rentable. Et avec des plateformes comme Novita AI qui offrent un accès gratuit et des fonctionnalités étendues, les développeurs n’ont plus d’excuse pour ne pas commencer.
Foire aux questions
Llama 3.2 1B est-il open source ?
Oui, il est entièrement open source et développé par Meta.
De quel matériel ai-je besoin pour exécuter Llama 3.2 1B ?
Inférence : 3,14 Go de VRAM (par exemple RTX 4060)
Fine-tuning : 14,11 Go de VRAM (par exemple RTX 4090)
Comment utiliser Llama 3.2 1B sans GPU ?
Utilisez l’API gratuite de Novita AI. Connectez-vous, obtenez votre clé et commencez à appeler le modèle.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API, tout en fournissant le cloud GPU abordable et fiable pour construire et faire évoluer.



