

Indique um amigo para a Novita AI e ambos receberão $10 em créditos de API LLM — até $500 em recompensas totais.
Para apoiar a comunidade de desenvolvedores, o Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B está atualmente disponível gratuitamente na Novita AI.

Todo mundo está falando do Llama 3.2 1B como o modelo de linguagem “no dispositivo” perfeito. Pequeno, multilíngue e eficiente — parece a ferramenta dos sonhos para aplicativos móveis e dispositivos de borda.
Mas a verdade é esta: executá-lo localmente? Nem tão fácil. Pode gerar lentidão, travar ou exigir mais configuração do que o esperado. É aí que o acesso via API muda o jogo. Com zero instalação, escalabilidade elástica e respostas quase instantâneas, as APIs oferecem o caminho mais suave para desbloquear o poder do Llama 3.2 1B.
Neste post, apresentaremos três provedores de API de primeira linha — Novita AI, Deepinfra e Nebius — e mostraremos exatamente como começar, de graça ou quase sem custo.
O que é Llama 3.2 1B?
O modelo Llama 3.2 1B é um modelo de linguagem grande leve e multilíngue desenvolvido pela Meta, projetado para rodar eficientemente em dispositivos de borda e móveis, ao mesmo tempo que oferece desempenho robusto para várias tarefas de processamento de linguagem natural.
-
Tamanho do modelo: 1B
-
Código aberto: Sim
-
Arquitetura: Transform denso
-
Comprimento do contexto: 128.000 tokens
-
Idiomas multilíngues suportados:
- Suporte oficial: Inglês, Alemão, Francês, Italiano, Português, Hindi, Espanhol, Tailandês
- Coleção mais ampla: Treinado em idiomas adicionais além dos 8 listados.
-
Capacidade multimodal:
- Entrada: Texto
- Saída: Texto e código
-
Método de treinamento: O Llama 3.2 1B foi treinado usando poda estruturada a partir do modelo Llama 3.1 8B, removendo sistematicamente partes da rede enquanto ajustava os pesos para criar um modelo menor e eficiente. Também empregou destilação de conhecimento, onde os logits dos modelos Llama 3.1 8B e 70B foram usados como alvos no nível de token durante o pré-treinamento. Essa abordagem permitiu que o Llama 3.2 1B aproveitasse insights de modelos maiores, melhorando seu desempenho após o processo de poda.
Benchmark do Llama 3.2 1B
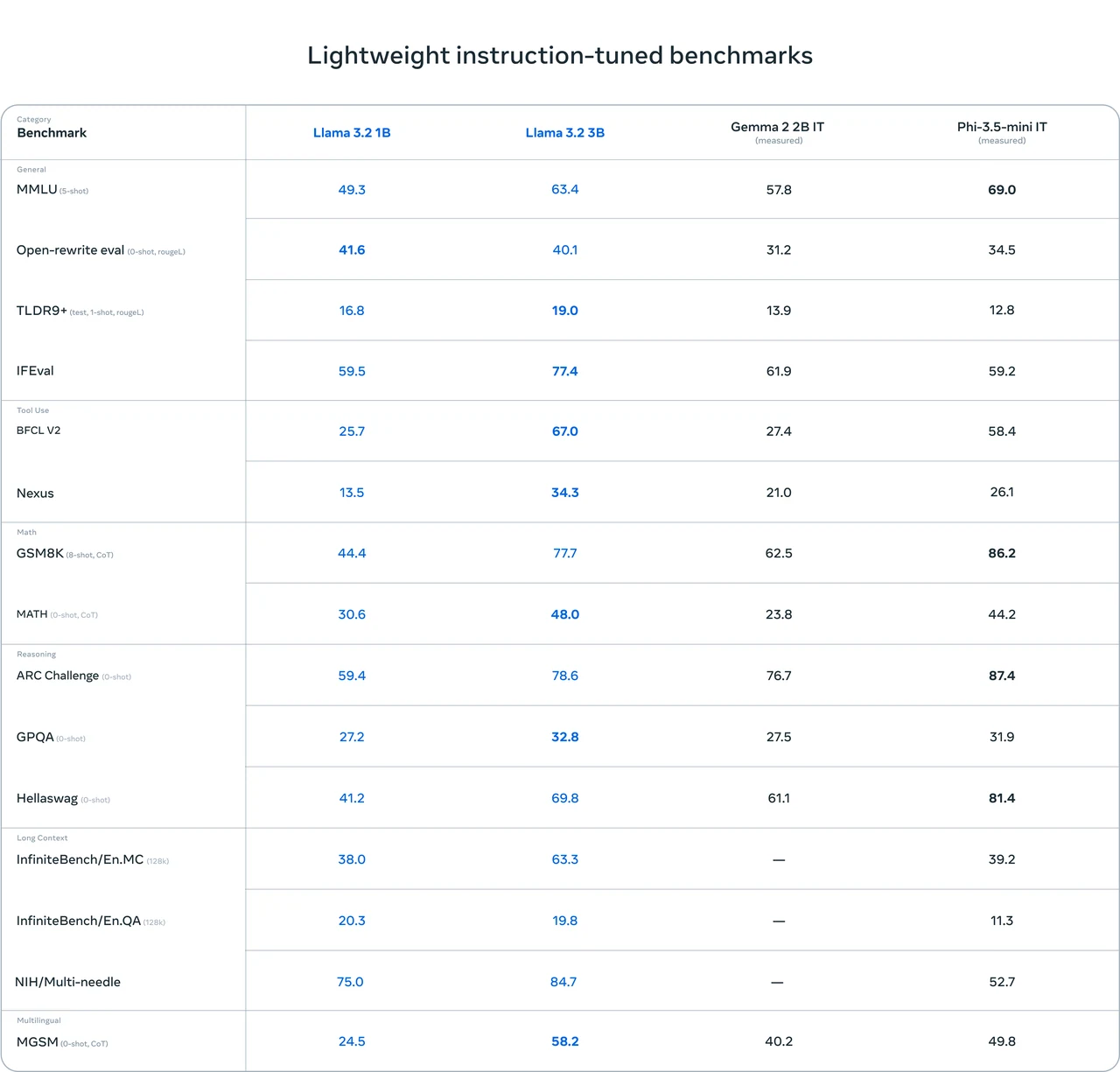
Requisitos de Hardware do Llama 3.2 1B
Detalhes de Inferência
-
Modelo: Llama 3.2 1B
-
Quantização: FP16
-
VRAM necessária (inferência): 3,14 GB
-
GPUs compatíveis:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
Detalhes de Fine-Tuning
- Modelo: Llama 3.2 1B
- Quantização: FP16
- VRAM necessária (fine-tuning): 14,11 GB
- GPU compatível: RTX 4090 (24 GB)
Mesmo que o LLaMA 3.2 1B tenha requisitos de VRAM relativamente baixos, isso não significa que a implantação seja simples.
API – Uma maneira simples e com um clique de usar
Benefícios da API
- Início imediato, sem configuração local: Sem necessidade de servidores de alto desempenho ou configurações complexas. Reduz custos de implantação e manutenção.
- Alta disponibilidade e escalabilidade elástica: Lida com tráfego pesado automaticamente; garante tempo de atividade com escalonamento dinâmico.
- Modelos e recursos sempre atualizados: Atualizações contínuas mantêm o sistema alinhado com os algoritmos e recursos mais recentes.
- Integração padronizada e fácil: APIs RESTful, gRPC, GraphQL garantem compatibilidade com várias plataformas e linguagens.
- Recursos extras ricos: Inclui monitoramento, registro, limitação de taxa, fine-tuning e implantações privadas.
- Suporte multiplataforma: APIs são versáteis, atendendo web, aplicativos móveis, dispositivos IoT e muito mais.
Como escolher um provedor de API?
Para apoiar a comunidade de desenvolvedores, o Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B está atualmente disponível gratuitamente na Novita AI.
Experimente o Llama 3.2 1B agora!
Saída máxima:
- Mede o número máximo de tokens que o modelo pode gerar em uma resposta.
- Maior = Melhor
- Exemplo: Llama 4 Scout suporta 131.000 tokens.
Custo de entrada:
- O custo por milhão de tokens de entrada (por exemplo, prompts, contexto).
- Menor = Melhor
- Exemplo: Llama 4 Scout custa $0,1 por 1M de tokens de entrada.
Custo de saída:
- O custo por milhão de tokens de saída (por exemplo, respostas do modelo).
- Menor = Melhor
- Exemplo: Llama 4 Scout custa $0,5 por 1M de tokens de saída.
Latência:
- Atraso entre a solicitação e a resposta.
- Menor = Melhor
- Crítico para chatbots, traduções ao vivo e sistemas interativos.
Taxa de transferência:
- O número de solicitações processadas por segundo.
- Maior = Melhor
- Garante o manuseio suave de solicitações simultâneas ou processamento em lote.
Os 3 Principais Provedores de API para Llama 3.2 1B
1. Novita AI
Novita AI é uma plataforma avançada de nuvem de IA que permite aos desenvolvedores implantar modelos de IA sem esforço por meio de uma API simples. Ela também fornece uma nuvem GPU acessível e confiável para criar e escalar soluções de IA.

Por que você deve escolher a Novita AI?
1. Eficiência de Desenvolvimento
- Modelos multimodais integrados: Modelos avançados como DeepSeek V3, DeepSeek R1 e LLaMA 3.3 70B já estão integrados e disponíveis para uso imediato — sem configuração extra necessária.
- Implantação simplificada: Desenvolvedores podem lançar modelos de IA de forma rápida e fácil, sem a necessidade de uma equipe especializada em IA ou procedimentos complexos.
2. Vantagem de Custo
- Otimização proprietária: Tecnologias de otimização exclusivas reduzem os custos de inferência em 30%-50% em comparação com grandes provedores, tornando a IA mais acessível. Você pode verificar o preço nesta página.
3.Extensão
- A Novita AI suporta chamada de funções e saída estruturada para modelos. Você pode clicar em “Meu Modelo” para verificar se um modelo específico suporta esses recursos.
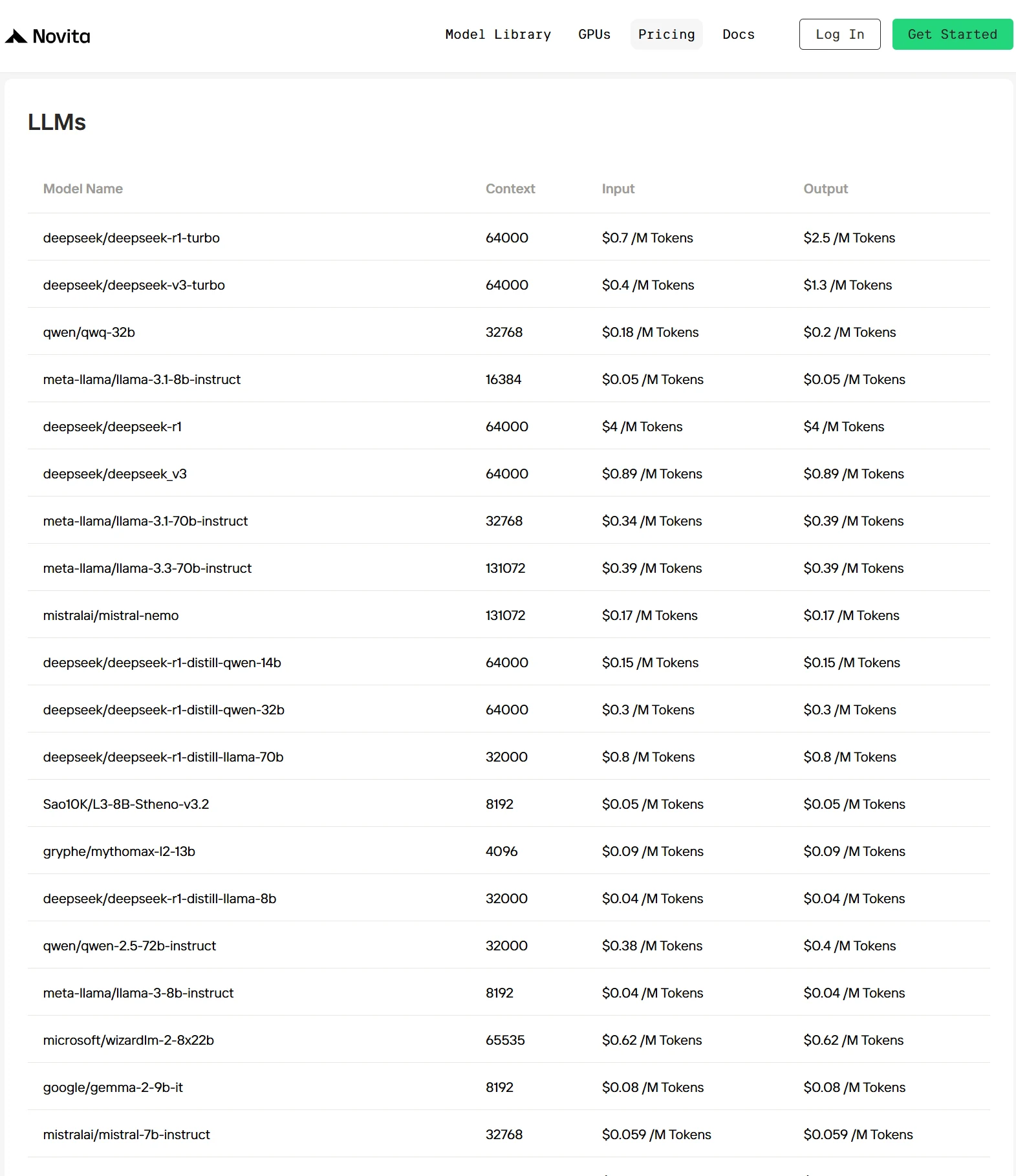
Como acessar o Llama 3.2 1B via API Novita?
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos .

Experimente o Llama 3.2 1B agora!
Passo 2: Inicie seu teste gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
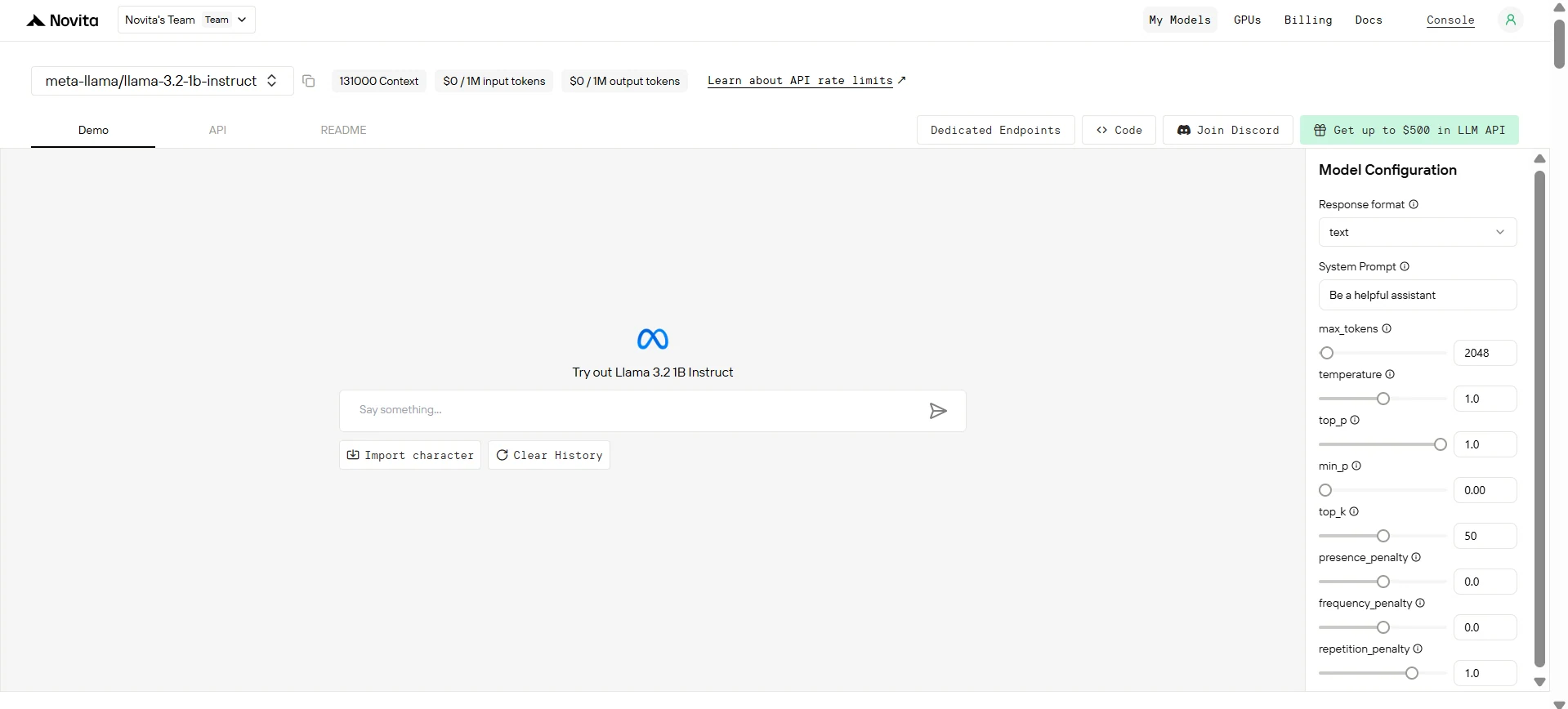
Passo 3: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Entrando na página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 4: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de conclusão de chat para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<SUA CHAVE DE API NOVITA AI>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # ou False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2.Deepinfra
Deepinfra facilita o acesso a modelos de IA líderes por meio de uma API simples. Aproveite planos pré-pagos econômicos, desempenho escalável e infraestrutura confiável, construída para implantação no mundo real.
Por que escolher Deepinfra?

Como acessar o Llama 3.2 1B através dela?
# Assumindo openai>=1.0.0
from openai import OpenAI
# Crie um cliente OpenAI com seu token e endpoint do deepinfra
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Olá"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
3. Nebius AI
Nebius é uma plataforma de desenvolvimento de IA completa que simplifica a criação, o fine-tuning e a implantação de modelos em GPUs NVIDIA de alto desempenho, entregando eficiência e velocidade excepcionais para aplicações de nível empresarial.

Por que escolhê-la?
Base de Alto Desempenho: A plataforma de nuvem otimizada para IA da Nebius aproveita GPUs NVIDIA H100/H200 avançadas com conectividade InfiniBand, permitindo fine-tuning poderoso de modelos, escalabilidade contínua e processamento de dados de baixa latência por meio de APIs flexíveis e de alta taxa de transferência.

Como acessar o Llama 3.2 1B através dela?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
O Llama 3.2 1B atinge um equilíbrio raro: alto desempenho, baixa demanda de recursos e fácil acesso por meio de APIs modernas. Seja implantando em uma GPU de laptop ou escalando um aplicativo na nuvem, este modelo é uma potência de baixo custo. E com plataformas como a Novita AI oferecendo acesso gratuito e recursos estendidos, os desenvolvedores agora não têm desculpa para não começar.
Perguntas Frequentes
O Llama 3.2 1B é código aberto?
Sim, é totalmente open source e desenvolvido pela Meta.
Qual hardware preciso para executar o Llama 3.2 1B?
Inferência: 3,14 GB de VRAM (ex.: RTX 4060)
Fine-tuning: 14,11 GB de VRAM (ex.: RTX 4090)
Como usar o Llama 3.2 1B sem uma GPU?
Use a API gratuita da Novita AI. Basta fazer login, obter sua chave e começar a chamar o modelo.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.



