

Refer your friends to Novita AI and both of you will earn $10 in LLM API credits—up to $500 in total rewards.
To support the developer community, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B is currently available for free on Novita AI.

Everyone’s talking about Llama 3.2 1B as the perfect “on-device” language model. Small, multilingual, and efficient—it sounds like the dream tool for mobile apps and edge devices.
But here’s the truth: actually running it locally? Not so easy. It can lag, crash, or demand more setup than expected. That’s where API access changes the game. With zero installation, elastic scalability, and near-instant responses, APIs offer the smoothest path to unlocking Llama 3.2 1B’s power.
In this post, we’ll introduce three top-tier API providers—Novita AI, Deepinfra, and Nebius—and show you exactly how to get started, for free or almost no cost.
What is Llama 3.2 1B ?
The Llama 3.2 1B model is a lightweight, multilingual large language model developed by Meta, designed to run efficiently on edge and mobile devices while providing strong performance for various natural language processing tasks.
-
Model Size: 1B
-
Open Source: Yes
-
Architecture: Dense Transform
-
Context Length: 128,000 tokens
-
Supported Multilingual Languages:
- Officially Supported: English, German, French, Italian, Portuguese, Hindi, Spanish, Thai
- Broader Collection: Trained on additional languages beyond the 8 listed.
-
Multimodal Capability:
- Input: Text
- Output: Text and Code
-
Trained Method: Llama 3.2 1B was trained using structured pruning from the Llama 3.1 8B model, systematically removing parts of the network while adjusting weights to create a smaller, efficient model. It also employed knowledge distillation, where logits from the Llama 3.1 8B and 70B models were used as token-level targets during pre-training. This approach enabled Llama 3.2 1B to leverage insights from larger models, enhancing its performance after the pruning process.
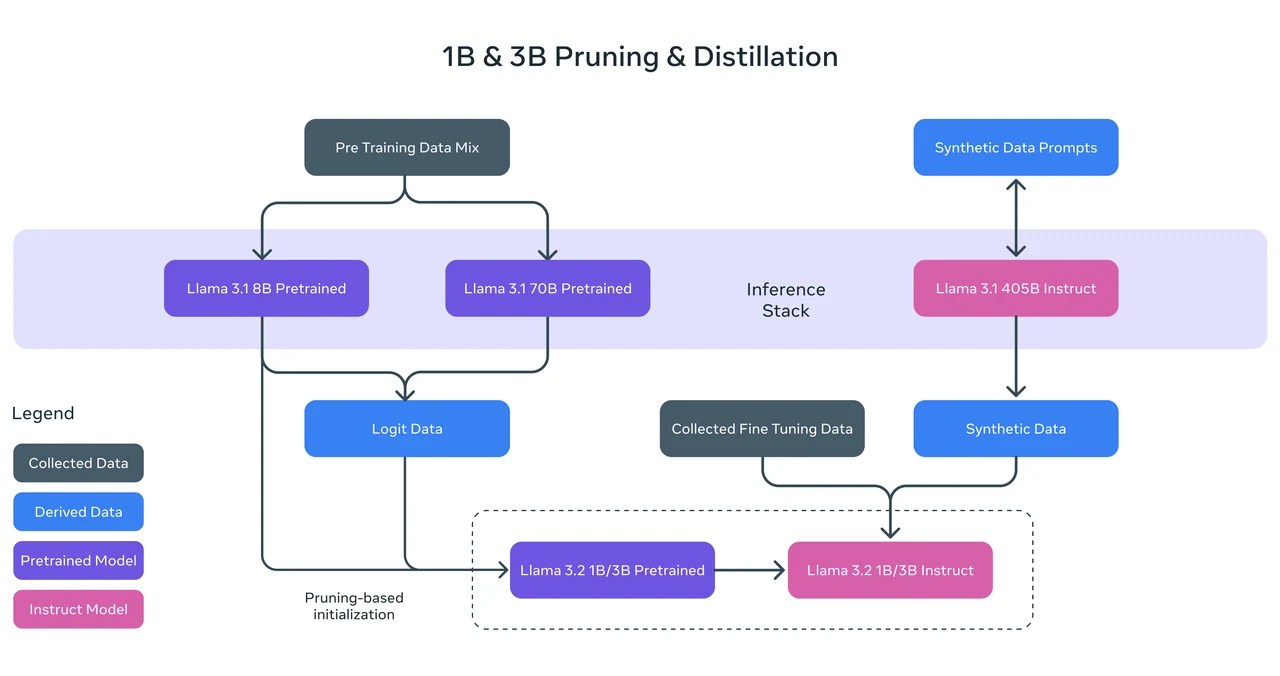
Llama 3.2 1B Benchmark
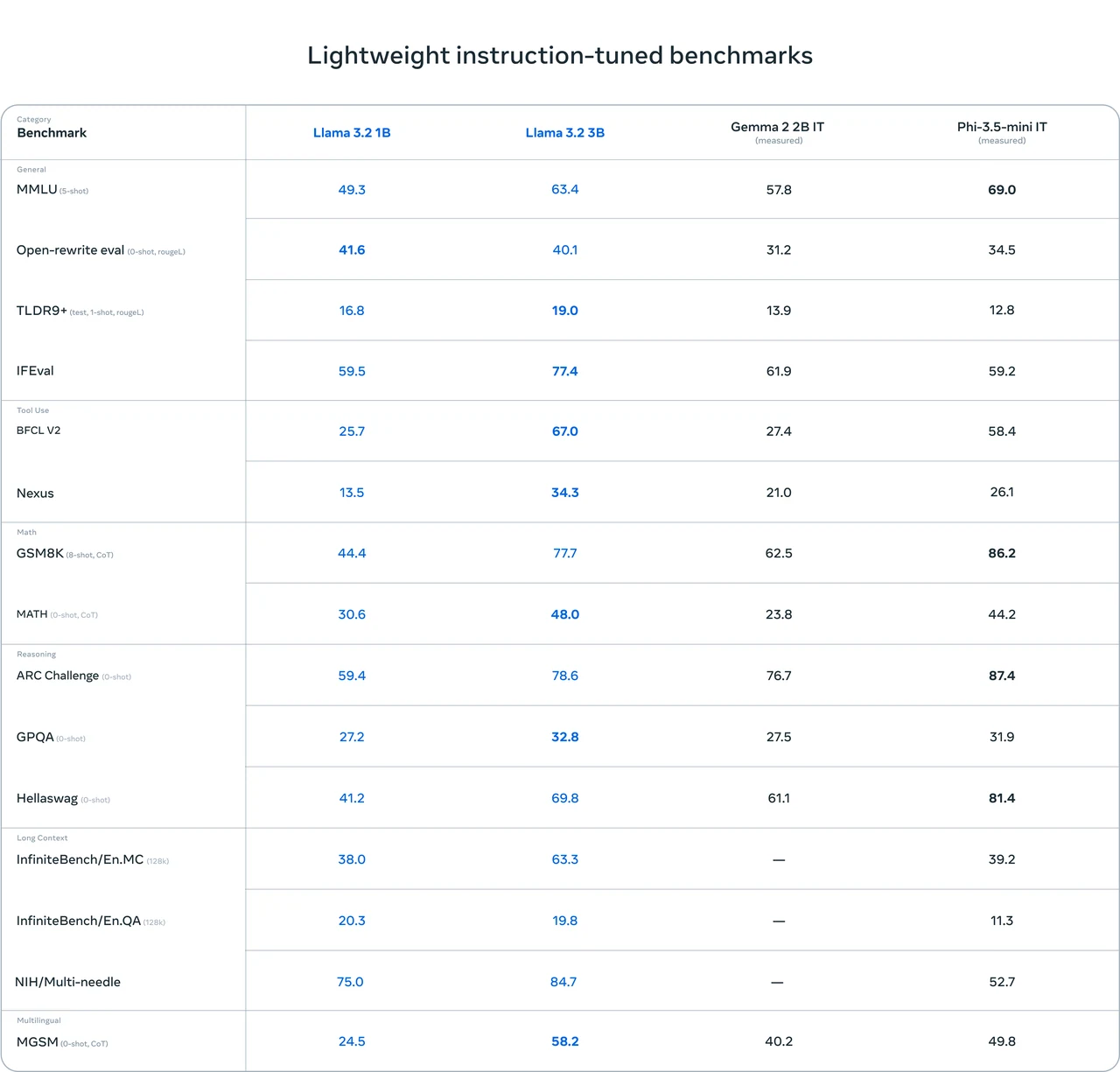
Llama 3.2 1B Hardware Requirements
Inference Details
-
Model: Llama 3.2 1B
-
Quantization: FP16
-
VRAM Required (Inference): 3.14 GB
-
Compatible GPUs:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
Fine-Tuning Details
- Model: Llama 3.2 1B
- Quantization: FP16
- VRAM Required (Fine-Tuning): 14.11 GB
- Compatible GPU: RTX 4090 (24 GB)
Even though LLaMA 3.2 1B has relatively low VRAM requirements, that doesn’t mean deployment is effortless.
API – A simple, One-click Way to Use
Benefits of API
- Instant Start, No Local Setup: No need for high-end servers or complex configurations. Reduces deployment and maintenance costs.
- High Availability & Elastic Scaling: Handles heavy traffic automatically; ensures uptime with dynamic scaling.
- Always Latest Models & Features: Continuous upgrades keep the system up-to-date with the latest algorithms and features.
- Standardized & Easy Integration: RESTful, gRPC, GraphQL APIs ensure compatibility with multiple platforms and languages.
- Rich Extra Features: Includes monitoring, logging, rate limiting, fine-tuning, and private deployments.
- Multi-Platform Support: APIs are versatile, serving web, mobile apps, IoT devices, and more.
How to Choose an API Provider?
To support the developer community, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B is currently available for free on Novita AI.
Max Output:
- Measures the maximum tokens the model can generate in one response.
- Higher = Better
- Example: Llama 4 Scout supports 131,000 tokens.
Input Cost:
- The cost per million input tokens (e.g., prompts, context).
- Lower = Better
- Example: Llama 4 Scout costs $0.1 per 1M input tokens.
Output Cost:
- The cost per million output tokens (e.g., model responses).
- Lower = Better
- Example: Llama 4 Scout costs $0.5 per 1M output tokens.
Latency:
- Time delay between request and response.
- Lower = Better
- Critical for chatbots, live translations, and interactive systems.
Throughput:
- The number of requests processed per second.
- Higher = Better
- Ensures smooth handling of concurrent requests or bulk processing.
Top 3 API Providers of Llama 3.2 1B
1. Novita AI
Novita AI is an advanced AI cloud platform that enables developers to effortlessly deploy AI models via a simple API. It also provides an affordable and reliable GPU cloud for building and scaling AI solutions.

Why Should You Choose Novita AI?
1. Development Efficiency
- Built-in Multimodal Models: Advanced models like DeepSeek V3, DeepSeek R1, and LLaMA 3.3 70B are already integrated and available for immediate use—no extra setup required.
- Streamlined Deployment: Developers can launch AI models quickly and easily, without the need for a specialized AI team or complex procedures.
2. Cost Advantage
- Proprietary Optimization: Unique optimization technologies lower inference costs by 30%-50% compared to major providers, making AI more affordable. You can check the price on this page.
3.Extension
- Novita AI supports function calling and structured output for models. You can click on “My Model” to check whether a specific model supports these features.
How to Access Llama 3.2 1B via Novita API?
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
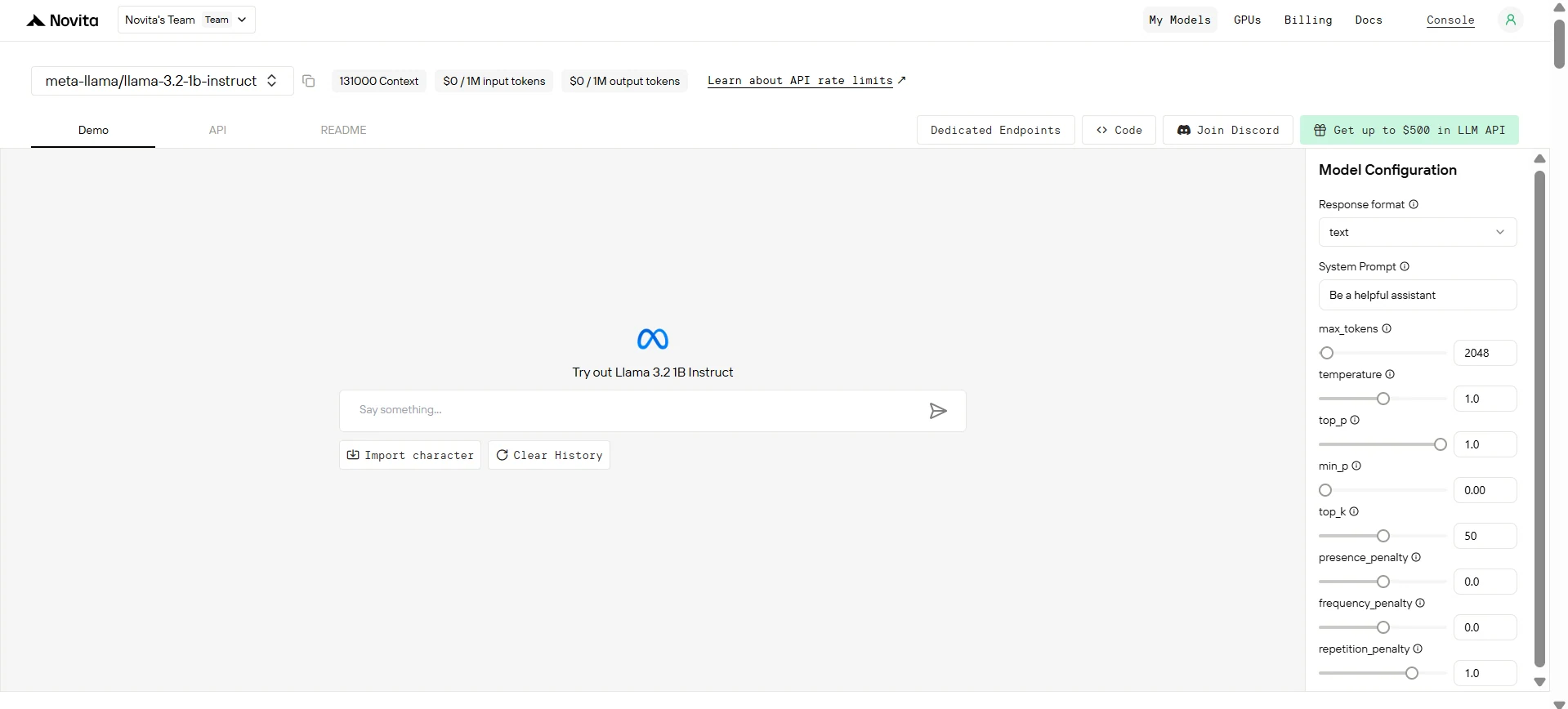
Step 3: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 4: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)2.Deepinfra
Deepinfra makes it easy to access leading AI models through a simple API. Enjoy cost-effective, pay-as-you-go plans, scalable performance, and dependable infrastructure built for real-world deployment.
Why Should you Choose Deepinfra?

How to Access Llama 3.2 1B through it?
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)3. Nebius AI
Nebius is an all-in-one AI development platform that streamlines model creation, fine-tuning, and deployment on high-performance NVIDIA GPUs, delivering exceptional efficiency and speed for enterprise-grade applications.

Why Choose it?
High-Performance Backbone: Nebius’s AI-optimized cloud platform leverages advanced NVIDIA H100/H200 GPUs with InfiniBand connectivity, enabling powerful model fine-tuning, seamless scaling, and low-latency data processing through flexible, high-throughput APIs.

How to Access Llama 3.2 1B through it?
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())Llama 3.2 1B strikes a rare balance: high performance, low resource demand, and easy access via modern APIs. Whether you’re deploying on a laptop GPU or scaling a cloud app, this model is a cost-effective powerhouse. And with platforms like Novita AI offering free access and extended features, developers now have no excuse not to get started.
Frequently Asked Questions
Is Llama 3.2 1B open source?
Yes, it’s fully open source and developed by Meta.
What hardware do I need to run Llama 3.2 1B?
Inference: 3.14 GB VRAM (e.g. RTX 4060)
Fine-tuning: 14.11 GB VRAM (e.g. RTX 4090)
How do I use Llama 3.2 1B without a GPU?
Use Novita AI’s free API. Just log in, get your key, and start calling the model.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



