

Recomienda a tus amigos Novita AI y ambos recibirán $10 en créditos de API de LLM, ¡hasta $500 en recompensas totales!
Para apoyar a la comunidad de desarrolladores, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B están actualmente disponibles de forma gratuita en Novita AI.

Todo el mundo habla de Llama 3.2 1B como el modelo de lenguaje “en dispositivo” perfecto. Pequeño, multilingüe y eficiente: suena como la herramienta soñada para aplicaciones móviles y dispositivos periféricos.
Pero aquí está la verdad: ¿ejecutarlo realmente de forma local? No es tan fácil. Puede retrasarse, fallar o requerir más configuración de la esperada. Ahí es donde el acceso por API cambia el juego. Sin instalación, escalabilidad elástica y respuestas casi instantáneas, las API ofrecen el camino más fluido para desbloquear el poder de Llama 3.2 1B.
En este artículo, presentaremos tres proveedores de API de primer nivel: Novita AI, Deepinfra y Nebius, y te mostraremos exactamente cómo empezar, de forma gratuita o casi sin costo.
¿Qué es Llama 3.2 1B?
El modelo Llama 3.2 1B es un modelo de lenguaje grande ligero y multilingüe desarrollado por Meta, diseñado para ejecutarse de manera eficiente en dispositivos periféricos y móviles, al mismo tiempo que ofrece un rendimiento sólido para diversas tareas de procesamiento de lenguaje natural.
-
Tamaño del modelo: 1B
-
Código abierto: Sí
-
Arquitectura: Dense Transform
-
Longitud de contexto: 128,000 tokens
-
Idiomas multilingües compatibles:
- Compatibles oficialmente: inglés, alemán, francés, italiano, portugués, hindi, español, tailandés
- Colección más amplia: Entrenado en idiomas adicionales más allá de los 8 listados.
-
Capacidad multimodal:
- Entrada: Texto
- Salida: Texto y código
-
Método de entrenamiento: Llama 3.2 1B se entrenó mediante poda estructurada a partir del modelo Llama 3.1 8B, eliminando sistemáticamente partes de la red mientras se ajustaban los pesos para crear un modelo más pequeño y eficiente. También empleó destilación de conocimiento, donde los logits de los modelos Llama 3.1 8B y 70B se usaron como objetivos a nivel de token durante el preentrenamiento. Este enfoque permitió a Llama 3.2 1B aprovechar las ideas de modelos más grandes, mejorando su rendimiento después del proceso de poda.
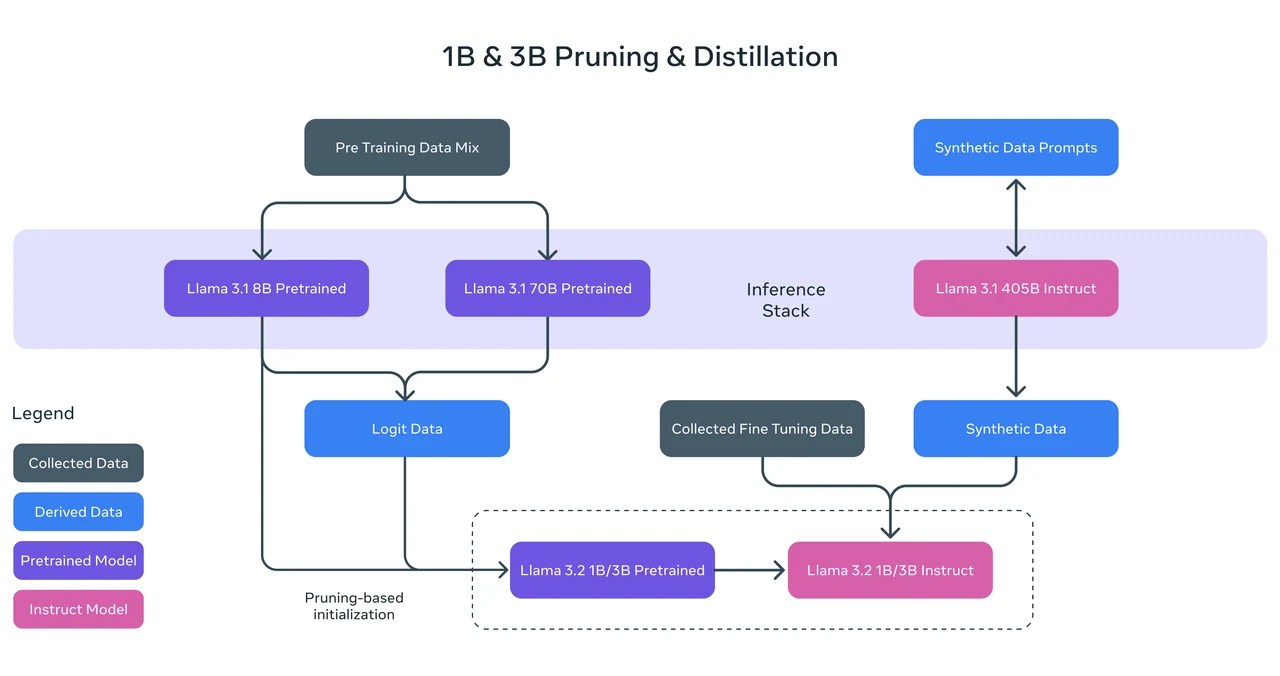
Benchmark de Llama 3.2 1B
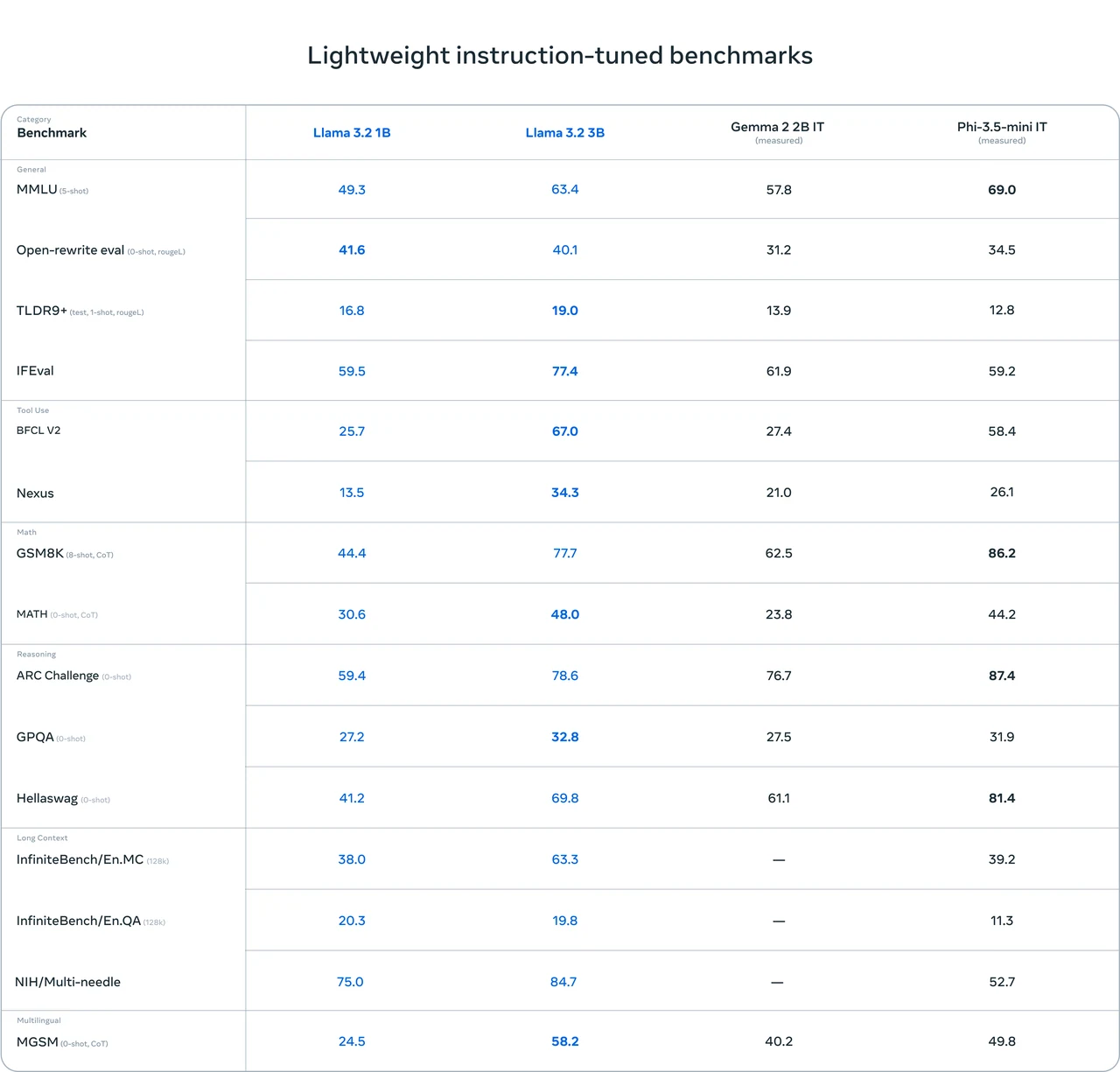
Requisitos de hardware de Llama 3.2 1B
Detalles de inferencia
-
Modelo: Llama 3.2 1B
-
Cuantización: FP16
-
VRAM requerida (inferencia): 3.14 GB
-
GPUs compatibles:
- RTX 3090 (12 GB)
- RTX 4060 (8 GB)
Detalles de ajuste fino
- Modelo: Llama 3.2 1B
- Cuantización: FP16
- VRAM requerida (ajuste fino): 14.11 GB
- GPU compatible: RTX 4090 (24 GB)
Aunque LLaMA 3.2 1B tiene requisitos de VRAM relativamente bajos, eso no significa que la implementación sea sencilla.
API: una forma simple, con un solo clic para usar
Beneficios de la API
- Inicio instantáneo, sin configuración local: No se necesitan servidores de alta gama ni configuraciones complejas. Reduce los costos de implementación y mantenimiento.
- Alta disponibilidad y escalado elástico: Maneja tráfico pesado automáticamente; garantiza tiempo de actividad con escalado dinámico.
- Siempre los modelos y funciones más recientes: Las actualizaciones continuas mantienen el sistema al día con los últimos algoritmos y funciones.
- Integración estandarizada y fácil: Las API RESTful, gRPC y GraphQL garantizan compatibilidad con múltiples plataformas y lenguajes.
- Funciones adicionales enriquecidas: Incluye monitoreo, registro, limitación de velocidad, ajuste fino e implementaciones privadas.
- Soporte multiplataforma: Las API son versátiles y sirven para web, aplicaciones móviles, dispositivos IoT y más.
¿Cómo elegir un proveedor de API?
Para apoyar a la comunidad de desarrolladores, Llama 3.2 1B, Qwen2.5-7B, Qwen 3 0.6B, Qwen 3 1.7B, Qwen 3 4B están actualmente disponibles de forma gratuita en Novita AI.
Salida máxima:
- Mide la cantidad máxima de tokens que el modelo puede generar en una respuesta.
- Más alto = Mejor
- Ejemplo: Llama 4 Scout admite 131,000 tokens.
Costo de entrada:
- El costo por millón de tokens de entrada (por ejemplo, indicaciones, contexto).
- Más bajo = Mejor
- Ejemplo: Llama 4 Scout cuesta $0.1 por 1M de tokens de entrada.
Costo de salida:
- El costo por millón de tokens de salida (por ejemplo, respuestas del modelo).
- Más bajo = Mejor
- Ejemplo: Llama 4 Scout cuesta $0.5 por 1M de tokens de salida.
Latencia:
- Retraso de tiempo entre la solicitud y la respuesta.
- Más bajo = Mejor
- Crítico para chatbots, traducciones en vivo y sistemas interactivos.
Rendimiento:
- El número de solicitudes procesadas por segundo.
- Más alto = Mejor
- Garantiza un manejo fluido de solicitudes concurrentes o procesamiento por lotes.
Los 3 principales proveedores de API de Llama 3.2 1B
1. Novita AI
Novita AI es una plataforma avanzada de nube de IA que permite a los desarrolladores implementar modelos de IA sin esfuerzo a través de una API simple. También proporciona una GPU en la nube asequible y confiable para construir y escalar soluciones de IA.

¿Por qué deberías elegir Novita AI?
1. Eficiencia de desarrollo
- Modelos multimodales integrados: Modelos avanzados como DeepSeek V3, DeepSeek R1 y LLaMA 3.3 70B ya están integrados y disponibles para uso inmediato, sin necesidad de configuración adicional.
- Implementación simplificada: Los desarrolladores pueden lanzar modelos de IA rápida y fácilmente, sin necesidad de un equipo de IA especializado ni procedimientos complejos.
2. Ventaja de costo
- Optimización propia: Las tecnologías de optimización únicas reducen los costos de inferencia entre un 30% y un 50% en comparación con los principales proveedores, haciendo la IA más asequible. Puedes consultar el precio en esta página.
3. Extensión
- Novita AI admite llamadas a funciones y salida estructurada para los modelos. Puedes hacer clic en “Mi modelo” para verificar si un modelo específico admite estas funciones.
Cómo acceder a Llama 3.2 1B a través de la API de Novita
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
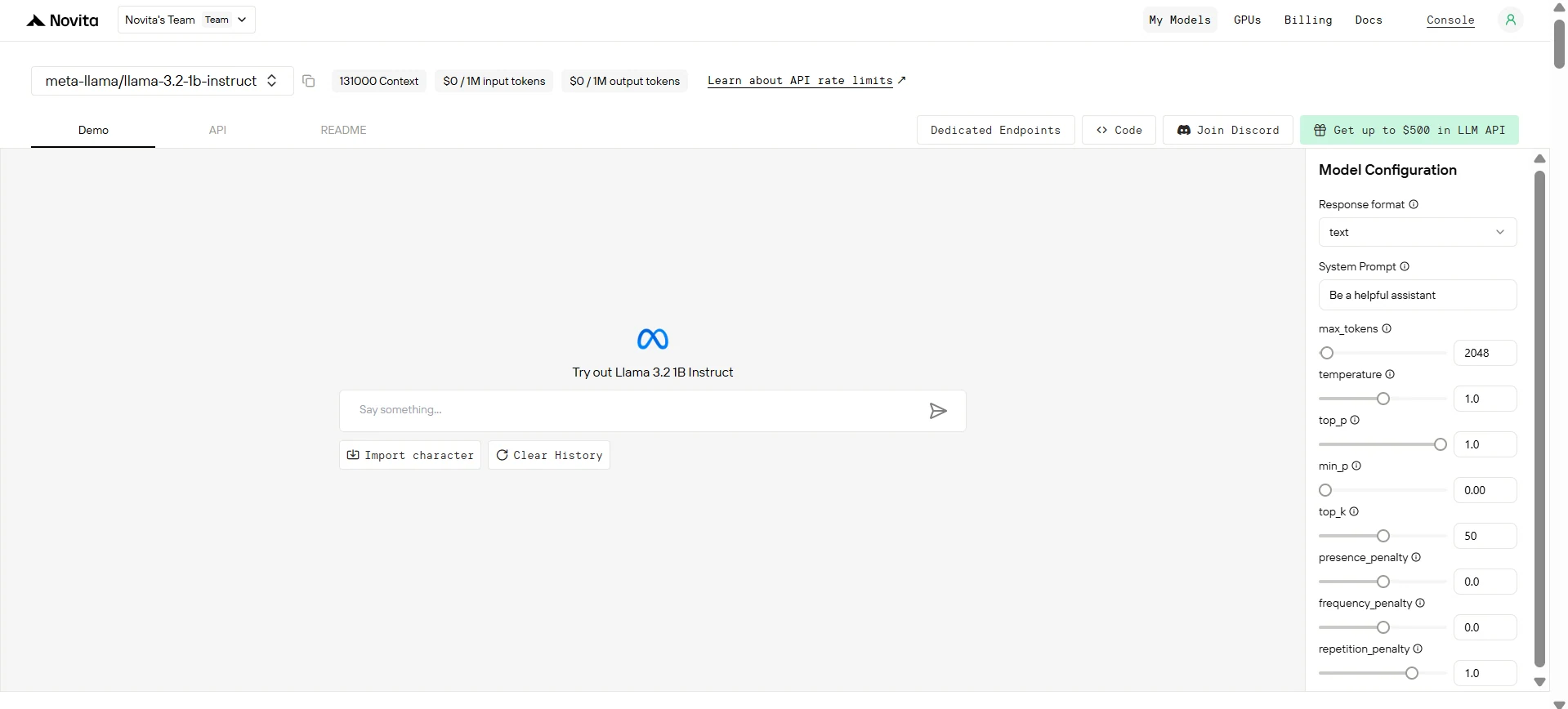
Paso 3: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Ingresa a la página de “Configuración” y copia la clave de API como se indica en la imagen.

Paso 4: Instala la API
Instala la API usando el administrador de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalización de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<TU Clave de API de Novita AI>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # o False
max_tokens = 2048
system_content = """Sé un asistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. Deepinfra
Deepinfra facilita el acceso a los principales modelos de IA a través de una API simple. Disfruta de planes de pago por uso rentables, rendimiento escalable e infraestructura confiable diseñada para implementación en el mundo real.
¿Por qué elegir Deepinfra?

Cómo acceder a Llama 3.2 1B a través de Deepinfra
# Asume openai>=1.0.0
from openai import OpenAI
# Crea un cliente de OpenAI con tu token y punto de conexión de Deepinfra
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Hola"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
3. Nebius AI
Nebius es una plataforma de desarrollo de IA integral que agiliza la creación, el ajuste fino y la implementación de modelos en GPU NVIDIA de alto rendimiento, ofreciendo una eficiencia y velocidad excepcionales para aplicaciones de nivel empresarial.

¿Por qué elegirlo?
Columna vertebral de alto rendimiento: La plataforma en la nube optimizada para IA de Nebius aprovecha las GPU NVIDIA H100/H200 avanzadas con conectividad InfiniBand, lo que permite un potente ajuste fino de modelos, escalado sin problemas y procesamiento de datos de baja latencia a través de API flexibles y de alto rendimiento.

Cómo acceder a Llama 3.2 1B a través de Nebius
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
Llama 3.2 1B logra un equilibrio poco común: alto rendimiento, baja demanda de recursos y fácil acceso a través de API modernas. Ya sea que estés implementando en una GPU de laptop o escalando una aplicación en la nube, este modelo es una potencia rentable. Y con plataformas como Novita AI que ofrecen acceso gratuito y funciones extendidas, los desarrolladores ya no tienen excusa para no empezar.
Preguntas frecuentes
¿Llama 3.2 1B es de código abierto?
Sí, es completamente de código abierto y desarrollado por Meta.
¿Qué hardware necesito para ejecutar Llama 3.2 1B?
Inferencia: 3.14 GB de VRAM (por ejemplo, RTX 4060)
Ajuste fino: 14.11 GB de VRAM (por ejemplo, RTX 4090)
¿Cómo uso Llama 3.2 1B sin una GPU?
Usa la API gratuita de Novita AI. Solo inicia sesión, obtén tu clave y comienza a llamar al modelo.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.



