

قم بإحالة أصدقائك إلى Novita AI وستحصلان معًا على 10 دولارات من رصيد API LLM—حتى 500 دولار من المكافآت الإجمالية.
لدعم مجتمع المطورين، تتوفر نماذج Qwen2.5-7B و Qwen 3 0.6B و Qwen 3 1.7B و Qwen 3 4B مجانًا حاليًا على Novita AI.

الجميع يتحدث عن Llama 3.2 1B باعتباره نموذج اللغة المثالي “على الجهاز”. صغير، متعدد اللغات، وفعّال—يبدو وكأنه الأداة المثالية لتطبيقات الهواتف المحمولة والأجهزة الطرفية.
لكن الحقيقة هي: تشغيله محليًا ليس بهذه السهولة. قد يتأخر، أو يتعطل، أو يتطلب إعدادات أكثر مما هو متوقع. وهنا يأتي دور الوصول عبر API ليغير قواعد اللعبة. مع عدم الحاجة إلى التثبيت، وقابلية التوسع المرنة، والاستجابات شبه الفورية، تقدم APIs المسار الأكثر سلاسة لفتح قوة Llama 3.2 1B.
في هذا المنشور، سنقدم ثلاثة مزودي API من الدرجة الأولى—Novita AI و Deepinfra و Nebius—ونوضح لك بالضبط كيف تبدأ، مجانًا أو بتكلفة قريبة من الصفر.
ما هو Llama 3.2 1B؟
نموذج Llama 3.2 1B هو نموذج لغوي كبير خفيف الوزن ومتعدد اللغات طورته Meta، مصمم للتشغيل بكفاءة على الأجهزة الطرفية والمحمولة مع تقديم أداء قوي لمختلف مهام معالجة اللغة الطبيعية.
-
حجم النموذج: 1 مليار معلمة
-
مفتوح المصدر: نعم
-
الهندسة المعمارية: Dense Transformer
-
طول السياق: 128,000 رمز
-
اللغات المدعومة متعددة اللغات:
- المدعومة رسميًا: الإنجليزية، الألمانية، الفرنسية، الإيطالية، البرتغالية، الهندية، الإسبانية، التايلاندية
- مجموعة أوسع: تم التدريب على لغات إضافية تتجاوز الثماني المذكورة.
-
القدرة متعددة الوسائط:
- الإدخال: نص
- الإخراج: نص ورمز
-
طريقة التدريب: تم تدريب Llama 3.2 1B باستخدام التقليم المنظم من نموذج Llama 3.1 8B، مع إزالة أجزاء من الشبكة بشكل منهجي مع ضبط الأوزان لإنشاء نموذج أصغر وأكثر كفاءة. كما تم استخدام تقطير المعرفة، حيث تم استخدام مخرجات (logits) من نموذجي Llama 3.1 8B و 70B كأهداف على مستوى الرموز أثناء التدريب المسبق. مكّن هذا النهج Llama 3.2 1B من الاستفادة من رؤى النماذج الأكبر، مما عزز أداءه بعد عملية التقليم.
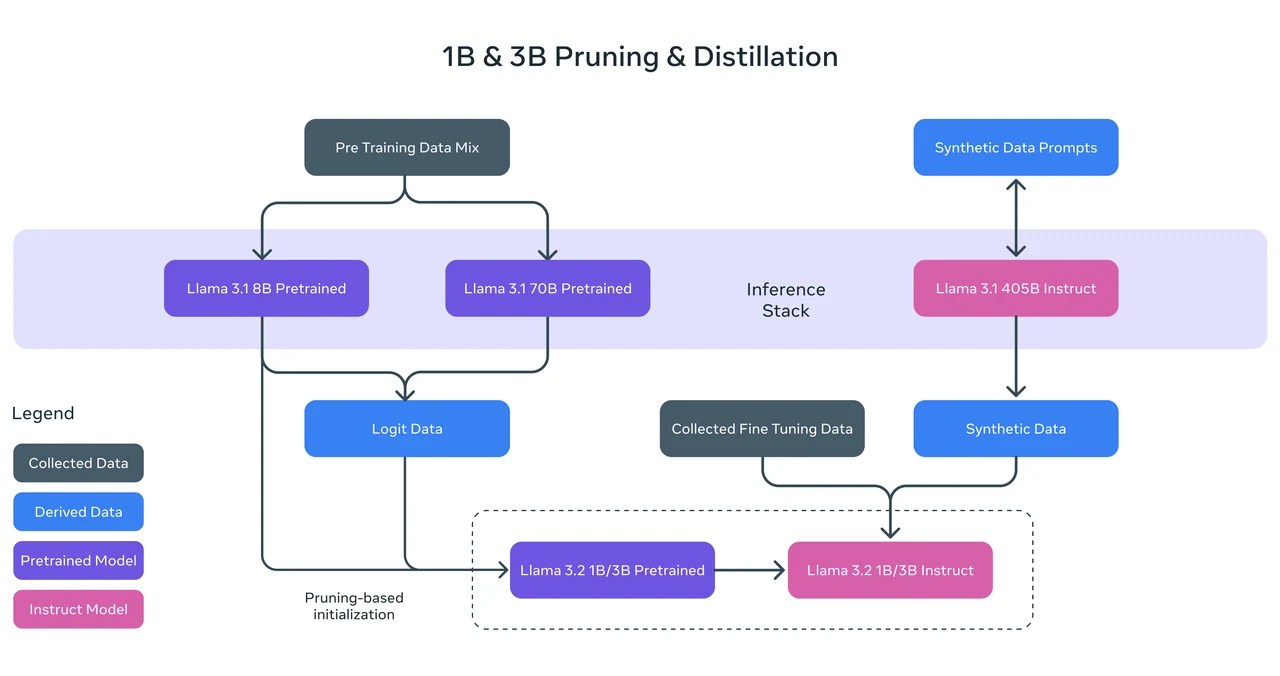
معايير أداء Llama 3.2 1B
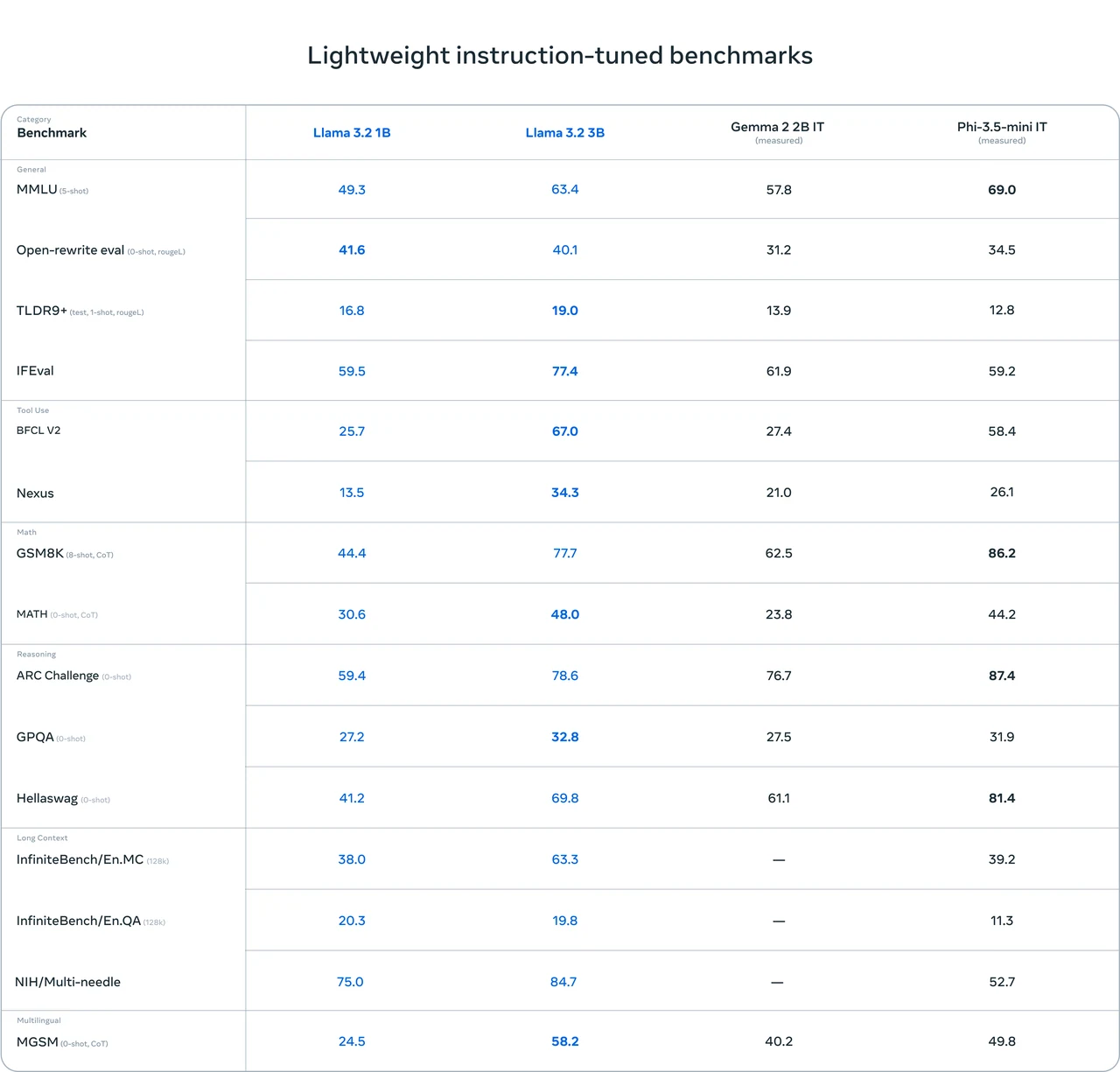
متطلبات الأجهزة لـ Llama 3.2 1B
تفاصيل الاستدلال
-
النموذج: Llama 3.2 1B
-
الكمية: FP16
-
ذاكرة VRAM المطلوبة (الاستدلال): 3.14 جيجابايت
-
بطاقات GPU المتوافقة:
- RTX 3090 (12 جيجابايت)
- RTX 4060 (8 جيجابايت)
تفاصيل الضبط الدقيق
- النموذج: Llama 3.2 1B
- الكمية: FP16
- ذاكرة VRAM المطلوبة (الضبط الدقيق): 14.11 جيجابايت
- بطاقة GPU المتوافقة: RTX 4090 (24 جيجابايت)
على الرغم من أن متطلبات VRAM لـ LLaMA 3.2 1B منخفضة نسبيًا، إلا أن هذا لا يعني أن النشر سهل.
API – طريقة بسيطة بنقرة واحدة للاستخدام
فوائد API
- بداية فورية، بدون إعداد محلي: لا حاجة لخوادم عالية المواصفات أو تكوينات معقدة. يقلل من تكاليف النشر والصيانة.
- توفر عالٍ وتوسع مرن: يتعامل مع حركة المرور الثقيلة تلقائيًا؛ يضمن استمرارية التشغيل مع التوسع الديناميكي.
- أحدث النماذج والميزات دائمًا: ترقيات مستمرة تحافظ على تحديث النظام بأحدث الخوارزميات والميزات.
- توحيد قياسي وتكامل سهل: APIs من نوع RESTful و gRPC و GraphQL تضمن التوافق مع منصات ولغات متعددة.
- ميزات إضافية غنية: تشمل المراقبة، التسجيل، تحديد المعدل، الضبط الدقيق، والنشر الخاص.
- دعم متعدد المنصات: APIs متعددة الاستخدامات، تخدم الويب، تطبيقات الهواتف المحمولة، أجهزة IoT، والمزيد.
كيف تختار مزود API؟
لدعم مجتمع المطورين، تتوفر نماذج Llama 3.2 1B و Qwen2.5-7B و Qwen 3 0.6B و Qwen 3 1.7B و Qwen 3 4B مجانًا حاليًا على Novita AI.
الحد الأقصى للإخراج:
- يقيس الحد الأقصى من الرموز التي يمكن للنموذج توليدها في استجابة واحدة.
- الأعلى = الأفضل
- مثال: يدعم Llama 4 Scout 131,000 رمزًا.
تكلفة الإدخال:
- التكلفة لكل مليون رمز إدخال (مثل المطالبات، السياق).
- الأقل = الأفضل
- مثال: تكلفة Llama 4 Scout 0.1 دولار لكل مليون رمز إدخال.
تكلفة الإخراج:
- التكلفة لكل مليون رمز إخراج (مثل استجابات النموذج).
- الأقل = الأفضل
- مثال: تكلفة Llama 4 Scout 0.5 دولار لكل مليون رمز إخراج.
زمن الاستجابة (Latency):
- التأخير الزمني بين الطلب والاستجابة.
- الأقل = الأفضل
- أمر حاسم لروبوتات الدردشة، والترجمة الفورية، والأنظمة التفاعلية.
الإنتاجية (Throughput):
- عدد الطلبات المعالجة في الثانية.
- الأعلى = الأفضل
- يضمن معالجة سلسة للطلبات المتزامنة أو المعالجة المجمعة.
أفضل 3 مزودي API لـ Llama 3.2 1B
1. Novita AI
Novita AI هي منصة سحابية متقدمة للذكاء الاصطناعي تمكن المطورين من نشر نماذج الذكاء الاصطناعي بسهولة عبر API بسيط. كما توفر سحابة GPU ميسورة التكلفة وموثوقة لبناء وتوسيع نطاق حلول الذكاء الاصطناعي.

لماذا تختار Novita AI؟
1. كفاءة التطوير
- نماذج متعددة الوسائط مدمجة: نماذج متقدمة مثل DeepSeek V3 و DeepSeek R1 و LLaMA 3.3 70B مدمجة بالفعل ومتاحة للاستخدام الفوري—لا حاجة لإعدادات إضافية.
- نشر مبسط: يمكن للمطورين إطلاق نماذج الذكاء الاصطناعي بسرعة وسهولة، دون الحاجة لفريق متخصص في الذكاء الاصطناعي أو إجراءات معقدة.
2. ميزة التكلفة
- تحسين خاص: تقنيات تحسين فريدة تخفض تكاليف الاستدلال بنسبة 30%-50% مقارنة بالمزودين الرئيسيين، مما يجعل الذكاء الاصطناعي أكثر تكلفة. يمكنك التحقق من السعر على هذه الصفحة.
3. التوسع
- تدعم Novita AI استدعاء الوظائف (function calling) والمخرجات المنظمة للنماذج. يمكنك النقر على “My Model” للتحقق مما إذا كان نموذج معين يدعم هذه الميزات.
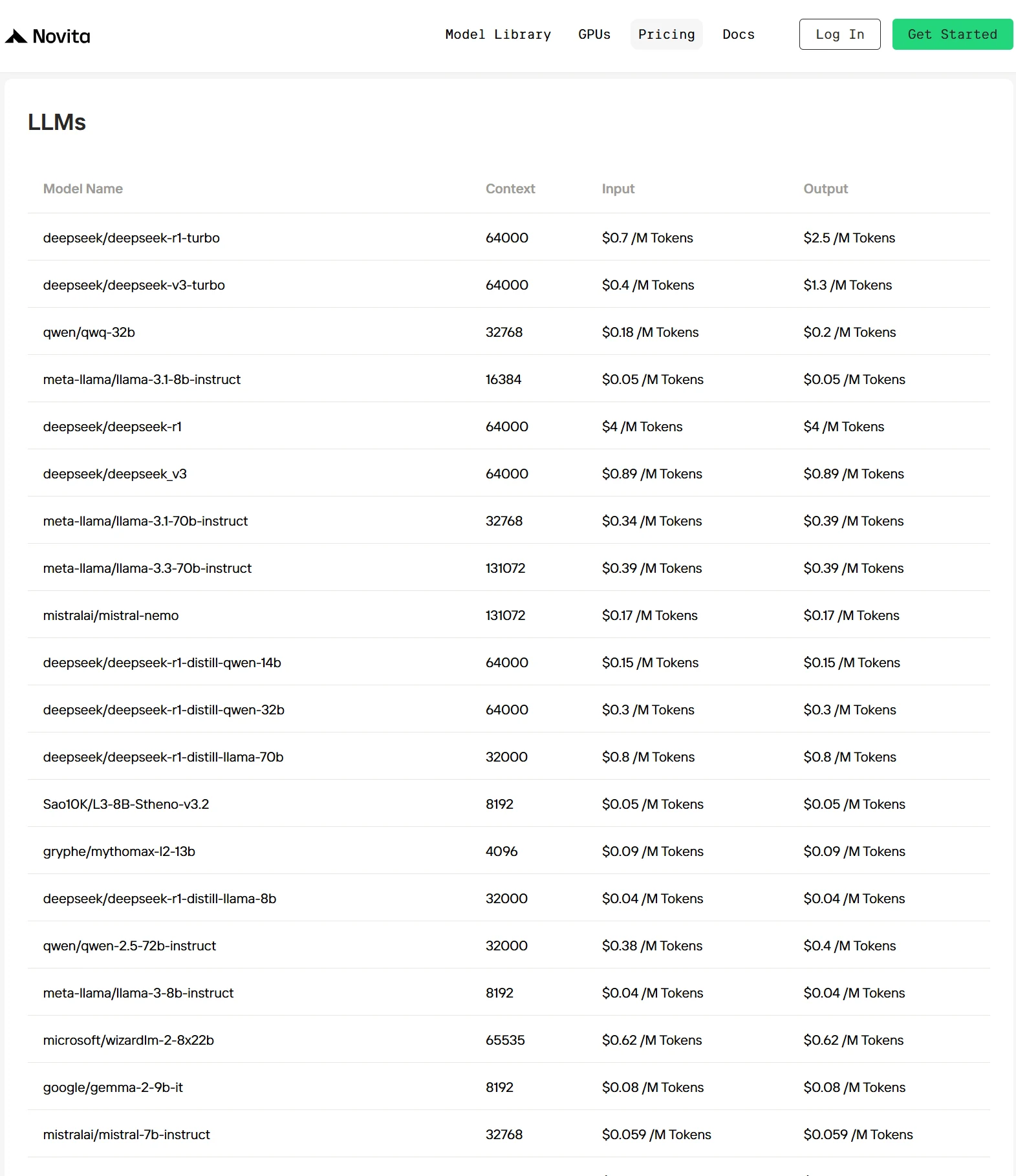
كيفية الوصول إلى Llama 3.2 1B عبر Novita API؟
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر Model Library.

الخطوة 2: ابدأ نسختك التجريبية المجانية
ابدأ نسختك التجريبية المجانية لاستكشاف قدرات النموذج المحدد.
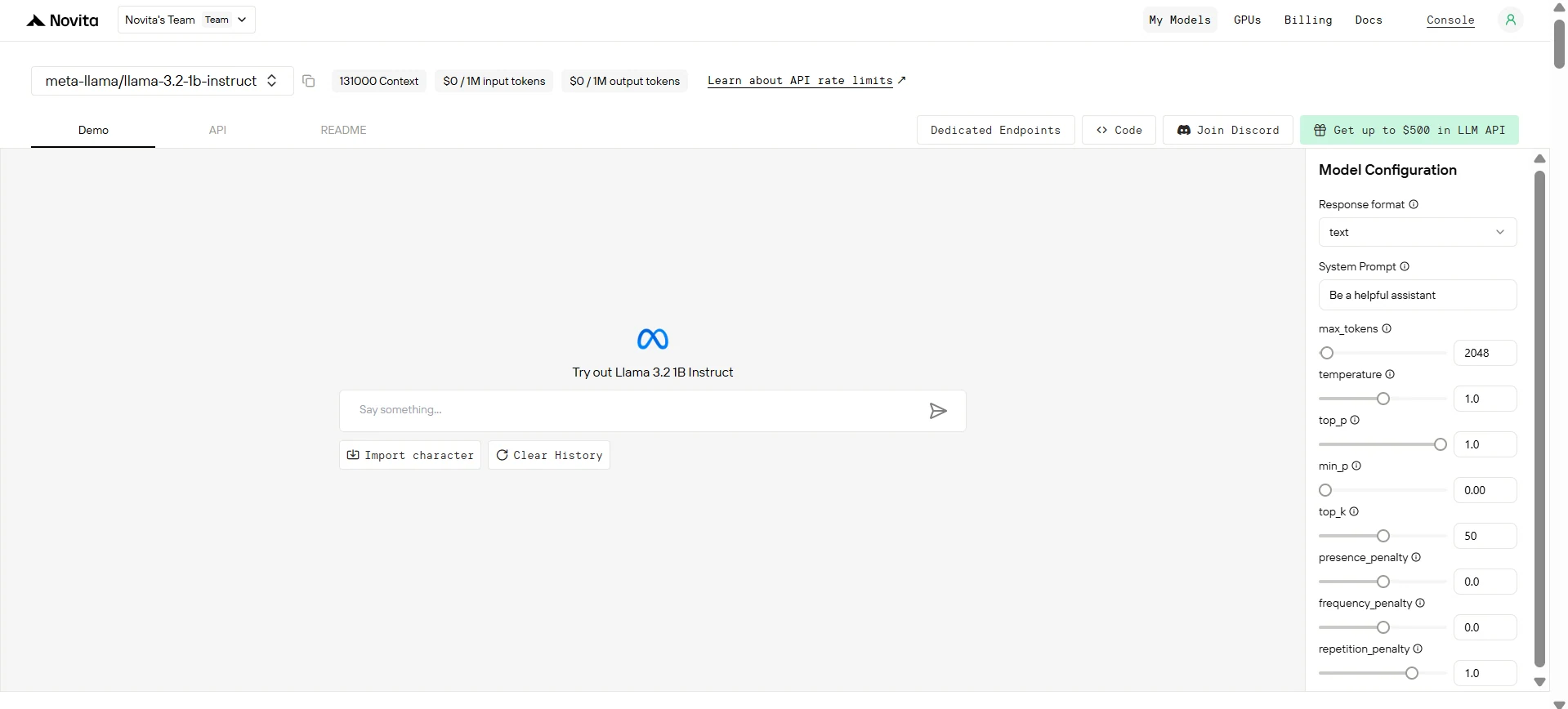
الخطوة 3: احصل على مفتاح API الخاص بك
للتحقق من الهوية مع API، سنقدم لك مفتاح API جديد. ادخل إلى صفحة “Settings”، ويمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 4: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.

بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال لاستخدام chat completions API لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "meta-llama/llama-3.2-1b-instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
2. Deepinfra
تسهل Deepinfra الوصول إلى نماذج الذكاء الاصطناعي الرائدة عبر API بسيط. استمتع بخطط دفع حسب الاستخدام فعالة من حيث التكلفة، وأداء قابل للتوسع، وبنية تحتية موثوقة مبنية للنشر في العالم الحقيقي.
لماذا تختار Deepinfra؟

كيفية الوصول إلى Llama 3.2 1B من خلالها؟
# Assume openai>=1.0.0
from openai import OpenAI
# Create an OpenAI client with your deepinfra token and endpoint
openai = OpenAI(
api_key="$DEEPINFRA_TOKEN",
base_url="https://api.deepinfra.com/v1/openai",
)
chat_completion = openai.chat.completions.create(
model="llama/llama-3.2-1b",
messages=[{"role": "user", "content": "Hello"}],
)
print(chat_completion.choices[0].message.content)
print(chat_completion.usage.prompt_tokens, chat_completion.usage.completion_tokens)
3. Nebius AI
Nebius هي منصة تطوير ذكاء اصطناعي شاملة تعمل على تبسيط إنشاء النماذج وضبطها الدقيق ونشرها على وحدات معالجة رسومية NVIDIA عالية الأداء، مما يوفر كفاءة وسرعة استثنائية للتطبيقات على مستوى المؤسسات.

لماذا تختارها؟
نواة عالية الأداء: تستخدم منصة Nebius السحابية المحسنة للذكاء الاصطناعي وحدات معالجة رسومية NVIDIA H100/H200 متقدمة مع اتصال InfiniBand، مما يتيح ضبطًا دقيقًا قويًا للنماذج، وتوسعًا سلسًا، ومعالجة بيانات بزمن استجابة منخفض من خلال APIs مرنة وعالية الإنتاجية.

كيفية الوصول إلى Llama 3.2 1B من خلالها؟
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key=os.environ.get("NEBIUS_API_KEY")
)
response = client.chat.completions.create(
model="llama/llama-3.2-1b",
max_tokens=8192,
temperature=0.6,
top_p=0.95,
messages=[]
)
print(response.to_json())
يحقق Llama 3.2 1B توازنًا نادرًا: أداء عالٍ، متطلبات موارد منخفضة، ووصول سهل عبر APIs الحديثة. سواء كنت تنشر على GPU في جهاز محمول أو توسع نطاق تطبيق سحابي، فإن هذا النموذج هو قوة فعالة من حيث التكلفة. ومع منصات مثل Novita AI التي تقدم وصولًا مجانيًا وميزات إضافية، لم يعد لدى المطورين أي عذر لعدم البدء.
الأسئلة المتكررة
هل Llama 3.2 1B مفتوح المصدر؟
نعم، إنه مفتوح المصدر بالكامل وتم تطويره بواسطة Meta.
ما هي الأجهزة التي أحتاجها لتشغيل Llama 3.2 1B؟
الاستدلال: 3.14 جيجابايت VRAM (مثل RTX 4060) الضبط الدقيق: 14.11 جيجابايت VRAM (مثل RTX 4090)
كيف يمكنني استخدام Llama 3.2 1B بدون GPU؟
استخدم API المجاني لـ Novita AI. فقط سجل الدخول، واحصل على مفتاحك، وابدأ في استدعاء النموذج.
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



