

如果你正在为生产环境选择一个专注于编码的大语言模型(LLM),通常需要在三个现实之间权衡:
- 真实工程任务上的代码质量
- 交互式开发者体验所需的速度与延迟
- 规模化运营的成本(尤其是在上下文较长时)
在本文中,我们将从 基准测试 + 速度/延迟数据(下方包含占位符)以及 Novita AI 的官方定价 的角度,对 GLM-4.7-Flash 和 Qwen3-Coder-30B 进行比较。
基本介绍
| 项目 | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| 发布方 | Z.ai(GLM 系列) | 阿里巴巴(Qwen 系列) |
| 发布时间 | 2026年1月 | 2025年7月 |
| 架构 | MoE:约 30B 总参数量 / 每个 token 约 3B 激活 | MoE:约 30B 总参数量 / 每个 token 约 3B 激活(A3B) |
| 输入 / 输出 | 文本 → 文本 | 文本 → 文本 |
| 上下文长度 | 200K(128K 输出) | 原生 262K(使用 YaRN 可扩展到 1M) |
| 推理模式 | 支持思考模式 | 仅限非思考模式 |
| Novita 模型 ID | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
总体要点: GLM-4.7-Flash 针对生产环境和交互式工作流中的 快速、可控执行 进行了优化,而 Qwen3-Coder-30B 则在多项“困难”评估中倾向于 更强的深层推理能力——代价是交互场景下的更高延迟。
基准测试对比
基准测试的故事本质上是在 面向执行的编码 与 面向深度的推理 之间的权衡。
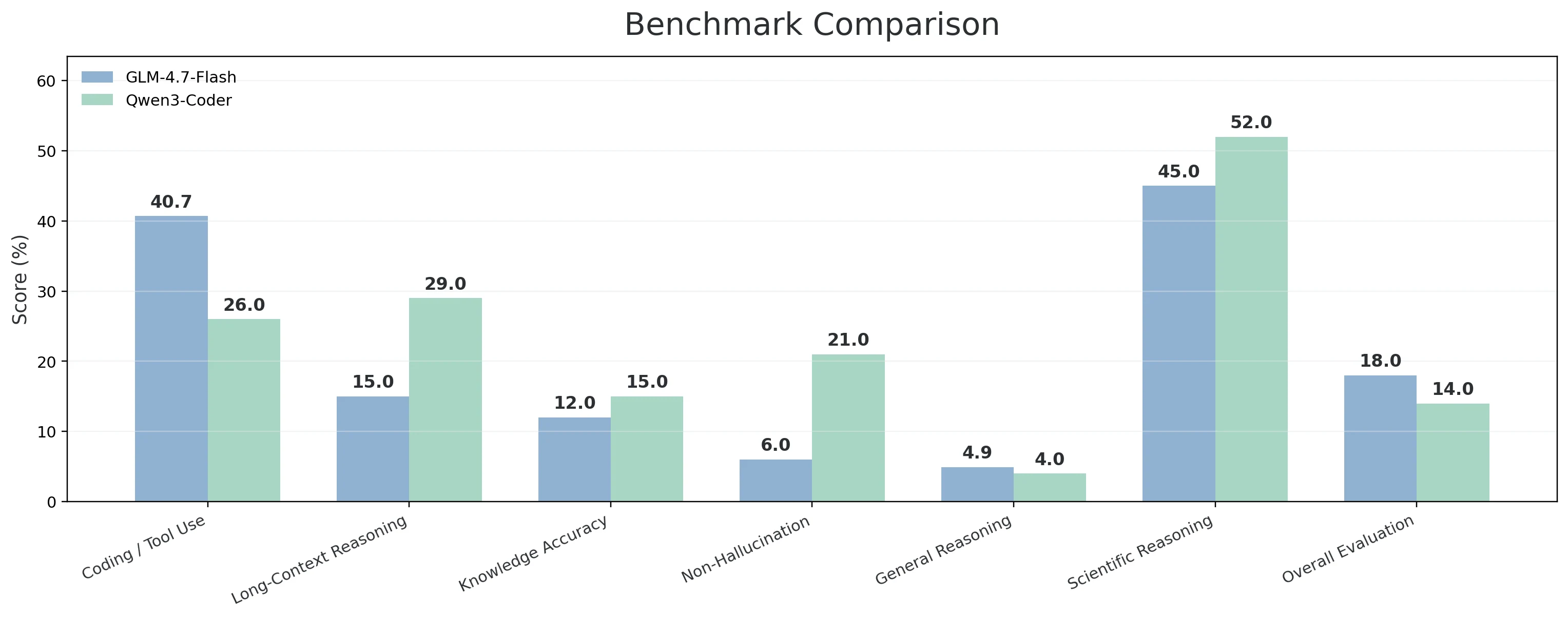
| 能力维度 | 包含的基准测试 | GLM-4.7-Flash | Qwen3-Coder |
| 编码/终端/工具使用 | Terminal-Bench Hard;τ²-Bench Telecom;SciCode | 40.70% | 26.00% |
| 长上下文推理 | AA-LCR | 15.00% | 29.00% |
| 知识准确性 | AA-Omniscience 准确率 | 12.00% | 15.00% |
| 非幻觉(可靠性) | AA-Omniscience 非幻觉率 | 6.00% | 21.00% |
| 通用推理与知识 | Humanity’s Last Exam | 4.90% | 4.00% |
| 科学推理 | GPQA Diamond | 45.00% | 52.00% |
| 整体判断/评估 | GDPval-AA | 18.00% | 14.00% |
- GLM-4.7-Flash 在最“工程化”的类别——编码/终端/工具使用——中表现更好,得分为 40.7% 对比 26.0%。这一组合(Terminal-Bench Hard + τ²-Bench Telecom + SciCode)很好地映射到实际工作流,其中模型需要 编写代码、与工具交互、解释输出并持续推进。它在 整体判断 方面也表现出更强信号,通过 GDPval-AA(18.0% 对比 14.0%),并在 通用推理与知识(Humanity’s Last Exam:4.9% 对比 4.0%)上略有优势。
- Qwen3-Coder-30B 在任务 长且对可靠性敏感 时表现出色。它在 长上下文推理(29.0% 对比 15.0%)上领先,这在提供大型仓库上下文或长规格说明并需要模型保持连贯性时非常重要。它在 非幻觉/可靠性(21.0% 对比 6.0%)方面也有显著优势,并在 知识准确性(15.0% 对比 12.0%)上小幅领先,使其在错误代价高昂的情况下更适合。它在 科学推理(GPQA Diamond:52.0% 对比 45.0%)上也更强,这对更偏研究或数学复杂的编码任务可能很重要。
你可以为工具密集型编码执行和实际决策选择 GLM-4.7-Flash;为长上下文深度和更高可靠性选择 Qwen3-Coder-30B。
速度与延迟对比
对于编码助手来说,“足够快”不仅仅关乎原始吞吐量——它还关乎 模型开始响应的速度(TTFT) 以及 典型交互从开始到结束所需的时间。
| 指标 | GLM-4.7-Flash | Qwen3-Coder-30B | 更优方向 |
| 延迟(TTFT:首个回答 token 的时间) | 0.9 秒 | 1.5 秒 | 越低越好 → GLM-4.7-Flash |
| 端到端响应时间(500 个输出 token) | 5.6 秒 | 6.3 秒 | 越低越好 → GLM-4.7-Flash |
| 输出速度(token/秒) | 106 tok/s | 104 tok/s | 越高越好 → GLM-4.7-Flash |
解读
- 在聊天/IDE 中“首次响应”更快:GLM-4.7-Flash 在 0.9 秒 vs 1.5 秒 内返回首个回答 token,使其在交互式编码聊天、IDE 辅助工具和快速调试循环中明显更灵敏。
- 常见编码提示的交互完成更快:对于 500 个 token 的响应,GLM-4.7-Flash 在 5.6 秒 vs 6.3 秒 内完成——当用户在多个交互中快速迭代时,这是一个持续的优势。
- 解码吞吐量相似:输出速度接近(106 vs 104 tok/s),因此主要用户体验优势主要在于 延迟 + 端到端时间,而非原始 token/秒。
成本对比
| 成本项目(Novita 无服务器) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| 输入价格(每 1M token) | $0.07 / Mt | $0.07 / Mt |
| 输出价格(每 1M token) | $0.40 / Mt | $0.27 / Mt |
| 缓存读取(每 1M token) | $0.01 / Mt | - |
在 Novita 无服务器上,Qwen3-Coder (30B-A3B) 在输出密集型编码中更便宜(输出 $/Mt 更低),而 GLM-4.7-Flash 在 缓存读取 适用于重复上下文时更具成本效益。
快速上手:在 Playground 上立即试用两个模型
Novita AI 提供了一个 交互式 Playground,你可以立即测试这两个模型——无需部署。
如何部署:API、SDK、集成和本地部署
API
获取 API 密钥
- 步骤 1:创建或登录你的账户
访问 [**https://novita.ai**](https://novita.ai) 并 注册 或登录到你的现有账户
- 步骤 2:导航到密钥管理
登录后,找到“API Keys”

- 步骤 3:创建新密钥
点击“Add New Key”按钮。

- 步骤 4:立即保存你的密钥
密钥生成后立即复制并存储;它通常只显示一次,之后无法找回。将密钥保存在安全位置,例如密码管理器或加密笔记中。
兼容 OpenAI 的 API(Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # 或 "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "你是一名精确的工程助手。当被要求时,输出有效的 JSON。"},
{"role": "user", "content": "总结在 20 个服务中推出功能标志的关键风险。"},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
如果你正在构建 智能体工作流(路由、交接、工具/函数调用),Novita 可与 兼容 OpenAI 的 SDK 配合使用,只需极少的改动:
- 即插即用:保留你现有的客户端逻辑;只需更改 base_url + model
- 可编排:易于实现路由(Flash 默认 → GLM-4.7 升级)
- 设置:指向
https://api.novita.ai/openai,设置NOVITA_API_KEY,选择zai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instruct
第三方平台
你也可以通过流行的生态系统运行 Novita 托管的 GLM 模型:
- 智能体框架和应用构建器:按照 Novita 的分步集成指南,与流行工具连接,例如 Continue、AnythingLLM、LangChain 和 Langflow。
- Hugging Face Hub:Novita 被列为 Hugging Face 上的 推理提供商,因此你可以通过 Hugging Face 的提供商工作流和生态系统运行支持的模型。
- 兼容 OpenAI 的 API:Novita 的 LLM 端点 兼容 OpenAI API 标准,使得迁移现有的 OpenAI 风格的应用程序并连接许多兼容 OpenAI 的工具( Cline、Cursor、Trae 和 Qwen Code)变得容易。
- 兼容 Anthropic 的 API:Novita 还提供 兼容 Anthropic SDK 的访问,以便你可以将 Novita 支持的模型集成到 Claude Code 风格的智能体编码工作流中。
- OpenCode:Novita AI 现在已直接集成到 OpenCode 中作为 受支持的提供商,因此用户可以在 OpenCode 中选择 Novita,无需手动配置。
本地和私有部署
由于 GLM-4.7-Flash 和 Qwen3-Coder 30B (A3B) 相对于前沿规模的模型来说相对轻量,它们对于倾向于 本地化部署 的团队来说是实用的选择——无论是出于隐私、合规性还是对运行时的更严格控制。
如果你想享受本地部署的好处,但 无需 维护自己的 GPU 硬件、驱动程序和 CUDA 堆栈的麻烦,你可以在 Novita GPU 实例 上运行它们。Novita 还提供不断增长的 模板库 以帮助你更快启动,包括一个即用型的 GLM-4.7-Flash 模板。
结论
如果你需要以下特性,请选择 GLM-4.7-Flash:
- 快速、低延迟的交互
- 强大的智能体编码和工具使用能力
- 显著更低的生产成本
如果你需要以下特性,请选择 Qwen3-Coder:
- 深度的长上下文推理
- 科学或分析性可靠性
- 大规模仓库理解能力
在 Novita AI 上,这两个模型都已可用于生产——但对于大多数 交互式且对成本敏感的编码工作负载,GLM-4.7-Flash 提供了最佳的整体平衡。
Novita AI 是一个 AI 云平台,为开发者提供使用简单 API 部署 AI 模型的便捷方式,同时也提供价格实惠、可靠的 GPU 云用于构建和扩展。
常见问题
什么是 GLM-4.7-Flash?
GLM-4.7-Flash 是智谱 AI 开发的一款 30B 级别的混合专家(MoE)大语言模型,旨在以高效率和低延迟提供强大的推理、编码和智能体性能。
什么是 Qwen3-30B-A3B?
Qwen3-30B-A3B 是 Qwen3-Coder 系列中一款 30B 参数的 MoE 编码模型。每个 token 激活约 3B 参数,在效率与深度之间取得平衡,擅长长上下文代码理解、大型仓库分析以及高精度推理。
GLM-4.7-Flash 的价格是多少?
在 Novita AI(无服务器)上,GLM-4.7-Flash 的定价为 输入 $0.07/百万 token、缓存读取 $0.01/百万 token 和 输出 $0.40/百万 token,对于大上下文和高吞吐量工作负载来说具有成本效益。
Qwen3-30B-A3B 是多模态的吗?
不。Qwen3-30B-A3B 是纯文本(专注于代码)模型。它不支持图像或音频等多模态输入,专门为编码、长上下文推理和仓库级分析而设计。



