

Si estás eligiendo un LLM enfocado en codificación para producción, normalmente equilibras tres realidades:
- Calidad del código en tareas reales de ingeniería
- Velocidad y latencia para una experiencia de desarrollador interactiva
- Costo a escala (especialmente cuando el contexto se vuelve largo)
En este post, comparamos GLM-4.7-Flash y Qwen3-Coder-30B desde esa perspectiva, utilizando benchmarks + archivos de velocidad/latencia (marcadores de posición incluidos abajo) y los precios oficiales de Novita AI para el costo.
Introducción básica
| Elemento | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| Editor | Z.ai (Serie GLM) | Alibaba (Serie Qwen) |
| Lanzamiento | Enero 2026 | Julio 2025 |
| Arquitectura | MoE: ~30B parámetros totales / ~3B activos por token | MoE: ~30B parámetros totales / ~3B activos por token (A3B) |
| Entrada / Salida | Texto → Texto | Texto → Texto |
| Longitud de contexto | 200K (salida de 128K) | 262K nativo (hasta 1M con YaRN) |
| Modo de razonamiento | Admite modos de pensamiento | Solo sin pensamiento |
| ID del modelo en Novita | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
Conclusión a alto nivel: GLM-4.7-Flash está optimizado para una ejecución rápida y controlable en flujos de trabajo interactivos y de producción, mientras que Qwen3-Coder-30B se inclina por señales de razonamiento profundo más fuertes en varias evaluaciones “difíciles”, a costa de una mayor latencia en entornos interactivos.
Comparación de benchmarks
La historia de los benchmarks es esencialmente un intercambio entre codificación orientada a la ejecución y razonamiento orientado a la profundidad.
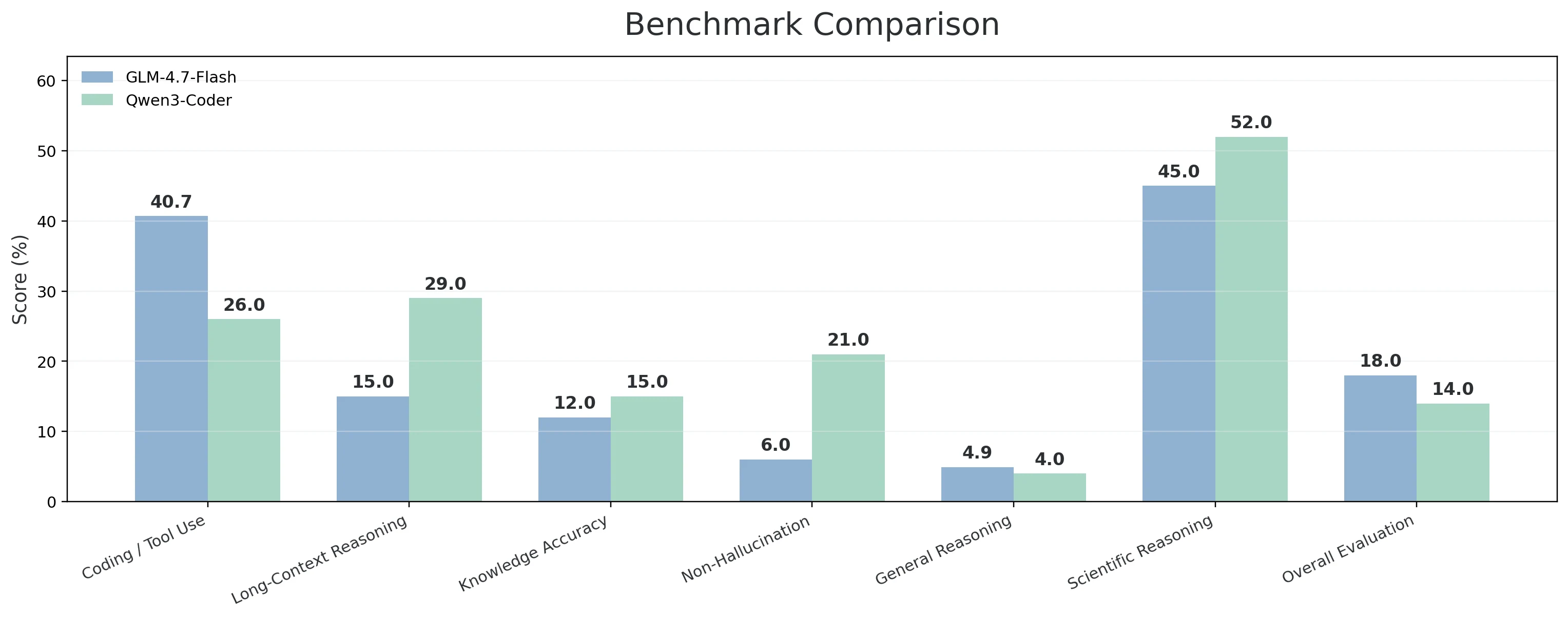
| Dimensión de capacidad | Benchmarks incluidos | GLM-4.7-Flash | Qwen3-Coder |
| Codificación / Terminal / Uso de herramientas | Terminal-Bench Hard; τ²-Bench Telecom; SciCode | 40.70% | 26.00% |
| Razonamiento con contexto largo | AA-LCR | 15.00% | 29.00% |
| Precisión del conocimiento | AA-Omniscience Accuracy | 12.00% | 15.00% |
| No alucinación (fiabilidad) | AA-Omniscience Non-Hallucination Rate | 6.00% | 21.00% |
| Razonamiento general y conocimiento | Humanity’s Last Exam | 4.90% | 4.00% |
| Razonamiento científico | GPQA Diamond | 45.00% | 52.00% |
| Juicio / Evaluación general | GDPval-AA | 18.00% | 14.00% |
- GLM-4.7-Flash se desempeña mejor en el grupo más “similar a la ingeniería”: Codificación / Terminal / Uso de herramientas, con un puntaje de 40.7% frente al 26.0%. Esa combinación (Terminal-Bench Hard + τ²-Bench Telecom + SciCode) se ajusta bien a flujos de trabajo reales donde el modelo debe escribir código, interactuar con herramientas, interpretar resultados y seguir avanzando. También muestra una señal más fuerte en juicio general a través de GDPval-AA (18.0% frente a 14.0%), además de una pequeña ventaja en razonamiento general y conocimiento (Humanity’s Last Exam: 4.9% frente a 4.0%).
- Qwen3-Coder-30B destaca cuando las tareas son largas y sensibles a la fiabilidad. Lidera en razonamiento con contexto largo (29.0% frente a 15.0%), lo que importa cuando alimentas contexto de repositorio grande o especificaciones largas y necesitas que el modelo se mantenga coherente. También tiene una ventaja importante en no alucinación / fiabilidad (21.0% frente a 6.0%) y una modesta ventaja en precisión del conocimiento (15.0% frente a 12.0%), lo que lo convierte en una mejor opción cuando los errores confiados son costosos. También es más fuerte en razonamiento científico (GPQA Diamond: 52.0% frente a 45.0%), lo que puede ser relevante para tareas de codificación con mayor carga de investigación o complejidad matemática.
Puedes elegir GLM-4.7-Flash para ejecución de codificación con uso intensivo de herramientas y toma de decisiones prácticas; elige Qwen3-Coder-30B para profundidad en contexto largo y mayor fiabilidad.
Comparación de velocidad y latencia
Para los asistentes de codificación, “suficientemente rápido” no se trata solo del rendimiento bruto, sino de qué tan rápido comienza a responder el modelo (TTFT) y cuánto tiempo toma un turno típico de principio a fin.
| Métrica | GLM-4.7-Flash | Qwen3-Coder-30B | Mejor (dirección) |
| Latencia (TTFT: Tiempo hasta el primer token de respuesta) | 0.9 s | 1.5 s | Menor es mejor → GLM-4.7-Flash |
| Tiempo de respuesta de extremo a extremo (500 tokens de salida) | 5.6 s | 6.3 s | Menor es mejor → GLM-4.7-Flash |
| Velocidad de salida (tokens/s) | 106 tok/s | 104 tok/s | Mayor es mejor → GLM-4.7-Flash |
Interpretación
- “Primera respuesta” más rápida en chat/IDE: GLM-4.7-Flash alcanza el primer token de respuesta en 0.9s frente a 1.5s, lo que lo hace notablemente más receptivo para chats de codificación interactivos, copilotos de IDE y bucles rápidos de depuración.
- Finalización más rápida de turnos para indicaciones de codificación comunes: Para una respuesta de 500 tokens, GLM-4.7-Flash termina en 5.6s frente a 6.3s, una ventaja constante cuando los usuarios iteran rápidamente en muchos turnos.
- Rendimiento de decodificación similar: La velocidad de salida es cercana (106 frente a 104 tok/s), por lo que la principal ventaja en la experiencia de usuario es principalmente la latencia + tiempo de extremo a extremo, no los tokens/s brutos.
Comparación de costos
| Elemento de costo (Novita Serverless) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| Precio de entrada (por 1M de tokens) | $0.07 / Mt | $0.07 / Mt |
| Precio de salida (por 1M de tokens) | $0.40 / Mt | $0.27 / Mt |
| Lectura de caché (por 1M de tokens) | $0.01 / Mt | - |
En Novita Serverless, Qwen3-Coder (30B-A3B) es más barato para codificación con mucha salida (menor $/Mt de salida), mientras que GLM-4.7-Flash se vuelve más rentable cuando la lectura de caché se aplica a contexto repetido.
Inicio rápido: Prueba ambos modelos al instante en Playground
Novita AI proporciona un Playground interactivo donde puedes probar ambos modelos al instante, sin necesidad de implementación.
Cómo implementar: API, SDK, integraciones e implementación local
API
Obtén una clave API
- Paso 1: Crea o inicia sesión en tu cuenta
Visita [**https://novita.ai**](https://novita.ai) y regístrate o inicia sesión en tu cuenta existente
- Paso 2: Navega a la gestión de claves
Después de iniciar sesión, encuentra “API Keys”

- Paso 3: Crea una nueva clave
Haz clic en el botón “Add New Key”.

- Paso 4: Guarda tu clave inmediatamente
Copia y almacena la clave tan pronto como se genere; generalmente se muestra solo una vez y no se puede recuperar después. Mantén la clave en un lugar seguro, como un gestor de contraseñas o notas cifradas.
API compatible con OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<TU_CLAVE_API_DE_NOVITA>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "Eres un asistente de ingeniería preciso. Genera JSON válido cuando se te pida."},
{"role": "user", "content": "Resume los riesgos clave de implementar banderas de características en 20 servicios."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Si estás creando flujos de trabajo agentivos (enrutamiento, traspasos, llamadas a herramientas/funciones), Novita funciona con SDKs compatibles con OpenAI con cambios mínimos:
- Compatible de forma directa: mantén tu lógica de cliente existente; solo cambia base_url + model
- Listo para orquestación: fácil de implementar enrutamiento (Flash por defecto → escalado a GLM-4.7)
- Configuración: apunta a
https://api.novita.ai/openai, estableceNOVITA_API_KEY, seleccionazai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instruct
Plataformas de terceros
También puedes ejecutar modelos GLM alojados en Novita a través de ecosistemas populares:
- Frameworks de agentes y creadores de aplicaciones: Sigue las guías de integración paso a paso de Novita para conectar con herramientas populares como Continue, AnythingLLM, LangChain y Langflow.
- Hugging Face Hub: Novita aparece como un proveedor de inferencia en Hugging Face, por lo que puedes ejecutar modelos compatibles a través del flujo de trabajo y ecosistema de proveedores de Hugging Face.
- API compatible con OpenAI: Los endpoints de LLM de Novita son compatibles con el estándar de la API de OpenAI, lo que facilita migrar aplicaciones existentes al estilo OpenAI y conectar muchas herramientas compatibles con OpenAI ( Cline, Cursor , Trae y Qwen Code) .
- API compatible con Anthropic: Novita también proporciona acceso compatible con el SDK de Anthropic para que puedas integrar modelos respaldados por Novita en flujos de trabajo agentivos de codificación al estilo Claude Code.
- OpenCode: Novita AI ahora está integrado directamente en OpenCode como un proveedor compatible, por lo que los usuarios pueden seleccionar Novita en OpenCode sin configuración manual.
Implementación local y privada
Debido a que GLM-4.7-Flash y Qwen3-Coder 30B (A3B) son relativamente ligeros en comparación con los modelos de frontera, son opciones prácticas para equipos que prefieren una implementación de tipo local, ya sea por privacidad, cumplimiento normativo o un control más estricto sobre el tiempo de ejecución.
Si deseas los beneficios de la implementación local sin la molestia de mantener tu propio hardware de GPU, controladores y pila CUDA, puedes ejecutarlos en instancias de GPU de Novita. Novita también ofrece una Biblioteca de plantillas en crecimiento para ayudarte a iniciar más rápido, incluida una plantilla lista para usar de GLM-4.7-Flash.
Explora la Biblioteca de plantillas
Conclusión
Elige GLM-4.7-Flash si necesitas:
- interacción rápida y de baja latencia
- codificación agentiva sólida y uso de herramientas
- costo de producción significativamente menor
Elige Qwen3-Coder si necesitas:
- razonamiento profundo con contexto largo
- fiabilidad científica o analítica
- comprensión de repositorios a gran escala
En Novita AI, ambos modelos están listos para producción, pero para la mayoría de las cargas de trabajo de codificación interactivas y sensibles al costo, GLM-4.7-Flash ofrece el mejor equilibrio general.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma fácil de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Preguntas frecuentes
¿Qué es GLM-4.7-Flash?
GLM-4.7-Flash es un modelo de lenguaje grande de 30B clase Mixture-of-Experts (MoE) desarrollado por Zhipu AI, diseñado para ofrecer un rendimiento sólido en razonamiento, codificación y agentes con alta eficiencia y baja latencia.
¿Qué es Qwen3-30B-A3B?
Qwen3-30B-A3B es un modelo de codificación MoE de 30B parámetros de Qwen3-Coder. Con ~3B parámetros activos por token, equilibra eficiencia y profundidad, sobresaliendo en comprensión de código con contexto largo, análisis de repositorios grandes y razonamiento de alta precisión.
¿Cuánto cuesta GLM-4.7-Flash?
En Novita AI (serverless), GLM-4.7-Flash tiene un precio de $0.07/M tokens de entrada, $0.01/M tokens de lectura de caché y $0.40/M tokens de salida, lo que lo hace rentable para cargas de trabajo de gran contexto y alto rendimiento.
¿Qwen3-30B-A3B es multimodal?
No. Qwen3-30B-A3B es un modelo solo de texto (centrado en código). No admite entradas multimodales como imágenes o audio, y está diseñado específicamente para codificación, razonamiento con contexto largo y análisis a nivel de repositorio.



