

Если вы выбираете LLM, ориентированную на кодирование, для продакшена, обычно приходится балансировать между тремя ключевыми факторами:
- Качество кода на реальных инженерных задачах
- Скорость и задержка для интерактивного опыта разработчика
- Стоимость при масштабировании (особенно когда контекст становится длинным)
В этой статье мы сравниваем GLM-4.7-Flash и Qwen3-Coder-30B именно с этих позиций — используя бенчмарки + файлы с показателями скорости/задержки (примеры приведены ниже) и официальные цены Novita AI для оценки стоимости.
Краткое введение
| Параметр | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| Издатель | Z.ai (серия GLM) | Alibaba (серия Qwen) |
| Дата выпуска | Январь 2026 | Июль 2025 |
| Архитектура | MoE: ~30 млрд общих параметров / ~3 млрд активных на токен | MoE: ~30 млрд общих параметров / ~3 млрд активных на токен (A3B) |
| Ввод / Вывод | Текст → Текст | Текст → Текст |
| Длина контекста | 200K (128K на вывод) | 262K нативно (до 1M с YaRN) |
| Режим рассуждений | Поддерживает режимы мышления | Только без режима мышления |
| ID модели Novita | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
Ключевой вывод: GLM-4.7-Flash оптимизирована для быстрого, управляемого выполнения в продакшене и интерактивных рабочих процессах, в то время как Qwen3-Coder-30B делает акцент на более сильных сигналах глубокого рассуждения в нескольких «сложных» оценках — ценой более высокой задержки в интерактивных сценариях.
Сравнение по бенчмаркам
История с бенчмарками по сути является компромиссом между кодированием, ориентированным на выполнение и рассуждениями, ориентированными на глубину.
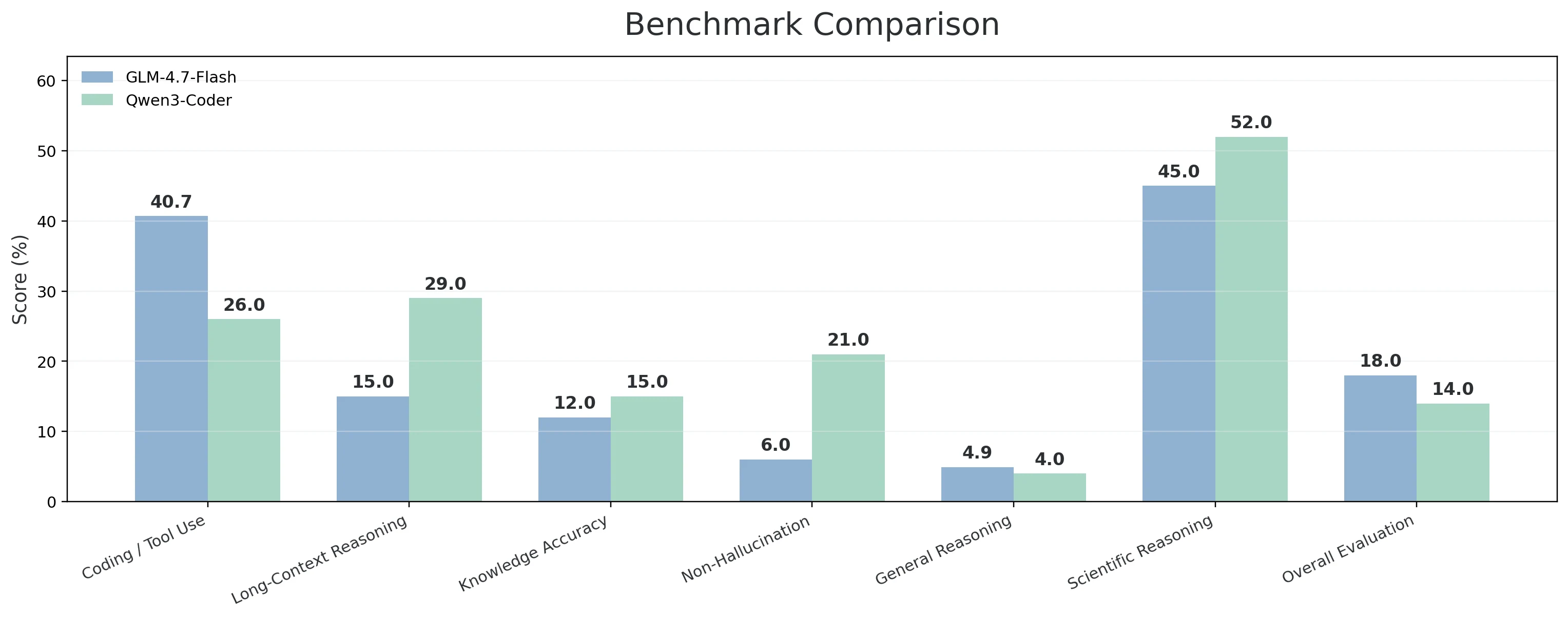
| Категория возможностей | Включенные бенчмарки | GLM-4.7-Flash | Qwen3-Coder |
| Кодирование / Терминал / Использование инструментов | Terminal-Bench Hard; τ²-Bench Telecom; SciCode | 40,70% | 26,00% |
| Рассуждения с длинным контекстом | AA-LCR | 15,00% | 29,00% |
| Точность знаний | AA-Omniscience Accuracy | 12,00% | 15,00% |
| Отсутствие галлюцинаций (Надежность) | AA-Omniscience Non-Hallucination Rate | 6,00% | 21,00% |
| Общие рассуждения и знания | Humanity’s Last Exam | 4,90% | 4,00% |
| Научные рассуждения | GPQA Diamond | 45,00% | 52,00% |
| Общее суждение / Оценка | GDPval-AA | 18,00% | 14,00% |
- GLM-4.7-Flash показывает лучшие результаты в наиболее «инженерно-ориентированной» категории — Кодирование / Терминал / Использование инструментов — с результатом 40,7% против 26,0%. Эта комбинация (Terminal-Bench Hard + τ²-Bench Telecom + SciCode) хорошо соответствует реальным рабочим процессам, где модель должна писать код, взаимодействовать с инструментами, интерпретировать выводы и продолжать работу. Она также демонстрирует более сильный сигнал по общему суждению через GDPval-AA (18,0% против 14,0%), а также небольшое преимущество в общих рассуждениях и знаниях (Humanity’s Last Exam: 4,9% против 4,0%).
- Qwen3-Coder-30B проявляет себя лучше, когда задачи длинные и критичны к надежности. Она лидирует в рассуждениях с длинным контекстом (29,0% против 15,0%), что важно, когда вы передаете контекст большого репозитория или длинные спецификации и нуждаетесь в том, чтобы модель сохраняла связность. У нее также есть большое преимущество по отсутствию галлюцинаций / надежности (21,0% против 6,0%) и небольшое преимущество в точности знаний (15,0% против 12,0%), что делает ее лучшим выбором, когда ошибки с высокой уверенностью стоят дорого. Она также сильнее в научных рассуждениях (GPQA Diamond: 52,0% против 45,0%), что может быть важно для более исследовательских или математически сложных задач по кодированию.
Вы можете выбрать GLM-4.7-Flash для выполнения задач по кодированию с интенсивным использованием инструментов и практического принятия решений; выбрать Qwen3-Coder-30B для глубины работы с длинным контекстом и более высокой надежности.
Сравнение скорости и задержки
Для ассистентов по кодированию «достаточно быстро» — это не только про сырую пропускную способность, но и про то, как быстро модель начинает отвечать (TTFT — время до первого токена ответа), и сколько времени занимает полный цикл типичного запроса от начала до конца.
| Метрика | GLM-4.7-Flash | Qwen3-Coder-30B | Лучший результат (направление) |
| Задержка (TTFT: время до первого токена ответа) | 0,9 с | 1,5 с | Меньше лучше → GLM-4.7-Flash |
| Полное время ответа (500 токенов вывода) | 5,6 с | 6,3 с | Меньше лучше → GLM-4.7-Flash |
| Скорость вывода (токенов/с) | 106 ток/с | 104 ток/с | Больше лучше → GLM-4.7-Flash |
Интерпретация
- Более быстрый «первый ответ» в чате/IDE: GLM-4.7-Flash выдает первый токен ответа за 0,9 с против 1,5 с, что делает ее заметно более отзывчивой для интерактивных чатов по кодированию, ассистентов IDE и быстрых циклов отладки.
- Быстрее завершение цикла для типичных запросов по кодированию: Для ответа длиной 500 токенов GLM-4.7-Flash завершает работу за 5,6 с против 6,3 с — стабильное преимущество, когда пользователи быстро итерируют множество запросов подряд.
- Схожая пропускная способность декодирования: Скорость вывода близка (106 против 104 ток/с), поэтому ключевое преимущество для пользовательского опыта в основном заключается в задержке + полном времени ответа, а не в сырой скорости токенов в секунду.
Сравнение стоимости
| Статья расходов (Novita Serverless) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| Цена на ввод (за 1 млн токенов) | $0.07 / Mt | $0.07 / Mt |
| Цена на вывод (за 1 млн токенов) | $0.40 / Mt | $0.27 / Mt |
| Чтение из кэша (за 1 млн токенов) | $0.01 / Mt | - |
На Novita Serverless Qwen3-Coder (30B-A3B) дешевле для задач по кодированию с большим объемом вывода (более низкая стоимость вывода $/Mt), в то время как GLM-4.7-Flash становится более экономически эффективной, когда применяется чтение из кэша для повторяющегося контекста.
Быстрый старт: попробуйте обе модели мгновенно в Playground
Novita AI предоставляет интерактивный Playground, где вы можете мгновенно протестировать обе модели — развертывание не требуется.
Как развернуть: API, SDK, интеграции и локальное развертывание
API
Получите API-ключ
- Шаг 1: Создайте учетную запись или войдите в нее
Перейдите на [**https://novita.ai**](https://novita.ai) и зарегистрируйтесь или войдите в существующую учетную запись
- Шаг 2: Перейдите в раздел управления ключами
После входа в систему найдите раздел «API-ключи»

- Шаг 3: Создайте новый ключ
Нажмите кнопку «Добавить новый ключ».

- Шаг 4: Немедленно сохраните ваш ключ
Скопируйте и сохраните ключ сразу после его генерации; обычно он отображается только один раз и не может быть восстановлен позже. Храните ключ в безопасном месте, например в менеджере паролей или зашифрованных заметках
OpenAI-Compatible API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Если вы создаете агентные рабочие процессы (маршрутизация, передача управления, вызовы инструментов/функций), Novita работает с SDK, совместимыми с OpenAI, с минимальными изменениями:
- Полная совмести мость: сохраните существующую логику клиента; просто измените base_url + model
- Готово к оркестрации: легко реализовать маршрутизацию (по умолчанию Flash → эскалация до GLM-4.7)
- Настройка: укажите адрес
https://api.novita.ai/openai, установите переменнуюNOVITA_API_KEY, выберитеzai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instruct
Сторонние платформы
Вы также можете запускать размещенные на Novita модели GLM через популярные экосистемы:
- Агентные фреймворки и конструкторы приложений: Следуйте пошаговым руководствам по интеграции от Novita, чтобы подключиться к популярным инструментам, таким как Continue, AnythingLLM, LangChain и Langflow.
- Hugging Face Hub: Novita указана как Поставщик вывода на Hugging Face, поэтому вы можете запускать поддерживаемые модели через рабочий процесс и экосистему поставщика Hugging Face.
- API, совместимый с OpenAI: Эндпоинты LLM Novita совместимы со стандартом API OpenAI, что упрощает миграцию существующих приложений в стиле OpenAI и подключение множества совместимых с OpenAI инструментов ( Cline, Cursor, Trae и Qwen Code).
- API, совместимый с Anthropic: Novita также предоставляет доступ, совместимый с SDK Anthropic, поэтому вы можете интегрировать модели на базе Novita в агентные рабочие процессы по кодированию в стиле Claude Code.
- OpenCode: Novita AI теперь напрямую интегрирована в OpenCode как поддерживаемый поставщик, поэтому пользователи могут выбрать Novita в OpenCode без ручной настройки.
Локальное и частное развертывание
Поскольку GLM-4.7-Flash и Qwen3-Coder 30B (A3B) относительно легковесны по сравнению с моделями передового масштаба, они являются практичным вариантом для команд, которые предпочитают локальное развертывание — будь то для конфиденциальности, соответствия требованиям или более строгого контроля над средой выполнения.
Если вы хотите получить преимущества локального развертывания без хлопот по поддержке собственного GPU-оборудования, драйверов и стека CUDA, вы можете запускать их на Novita GPU Instances. Novita также предлагает растущую Библиотеку шаблонов, которая поможет вам запускаться быстрее, включая готовый к использованию шаблон GLM-4.7-Flash.
Заключение
Выбирайте GLM-4.7-Flash, если вам нужно:
- быстрый интерактивный обмен с низкой задержкой
- мощное агентное кодирование и использование инструментов
- значительно более низкая стоимость в продакшене
Выбирайте Qwen3-Coder, если вам нужно:
- глубокие рассуждения с длинным контекстом
- научная или аналитическая надежность
- понимание репозиториев большого масштаба
На платформе Novita AI обе модели готовы к продакшену — но для большинства интерактивных и чувствительных к стоимости рабочих нагрузок по кодированию GLM-4.7-Flash обеспечивает лучший общий баланс.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывать AI-модели с помощью нашего простого API, а также предоставляет доступное и надежное GPU-облако для построения и масштабирования решений.
Часто задаваемые вопросы
Что такое GLM-4.7-Flash?
GLM-4.7-Flash — это крупная языковая модель класса 30 млрд параметров с архитектурой Mixture-of-Experts (MoE), разработанная Zhipu AI, предназначенная для обеспечения высокой производительности в рассуждениях, кодировании и агентных задачах с высокой эффективностью и низкой задержкой.
Что такое Qwen3-30B-A3B?
Qwen3-30B-A3B — это кодирующая модель MoE с 30 млрд параметров из линейки Qwen3-Coder. При ~3 млрд активных параметров на токен она балансирует между эффективностью и глубиной, показывая выдающиеся результаты в понимании кода с длинным контекстом, анализе больших репозиториев и высокоточных рассуждениях.
Сколько стоит GLM-4.7-Flash?
На Novita AI (serverless) GLM-4.7-Flash стоит $0,07 за 1 млн входных токенов, $0,01 за 1 млн токенов чтения из кэша и $0,40 за 1 млн выходных токенов, что делает ее экономически эффективной для рабочих нагрузок с большим контекстом и высокой пропускной способностью.
Является ли Qwen3-30B-A3B мультимодальной?
Нет. Qwen3-30B-A3B — это текстовая модель (ориентированная на код). Она не поддерживает мультимодальные входные данные, такие как изображения или аудио, и предназначена специально для кодирования, рассуждений с длинным контекстом и анализа на уровне репозитория.



