

若你要選擇一款適用於生產環境的編碼導向大型語言模型,通常需要權衡三個核心要素:
- 實際工程任務中的程式碼品質
- 為開發者提供互動體驗所需的速度與延遲
- 大規模部署成本(尤其是上下文長度較高時)
本文將從上述三個維度對比 GLM-4.7-Flash 與 Qwen3-Coder-30B,我們會使用基準測試 + 速度/延遲檔案(下方包含預留位置),並以 Novita AI 的官方定價作為成本參考。
基本介紹
| 項目 | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| 發布方 | Z.ai(GLM 系列) | 阿里巴巴(Qwen 系列) |
| 發布時間 | 2026 年 1 月 | 2025 年 7 月 |
| 架構 | MoE(混合專家模型):總參數約 300 億,每 token 活躍參數約 30 億 | MoE(混合專家模型):總參數約 300 億,每 token 活躍參數約 30 億(A3B) |
| 輸入/輸出 | 文本 → 文本 | 文本 → 文本 |
| 上下文長度 | 200K(輸出上限 128K) | 原生 262K(搭配 YaRN 可擴展至 100 萬) |
| 推理模式 | 支援思考模式 | 僅支援非思考模式 |
| Novita 模型 ID | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
核心結論: GLM-4.7-Flash 針對生產環境與互動工作流程中的快速、可控執行進行了優化;而 Qwen3-Coder-30B 則在多項「高難度」評估中側重更強的深度推理能力,但代價是互動場景下的延遲較高。
基準測試對比
基準測試的結果本質上是執行導向編碼能力與深度導向推理能力之間的權衡。
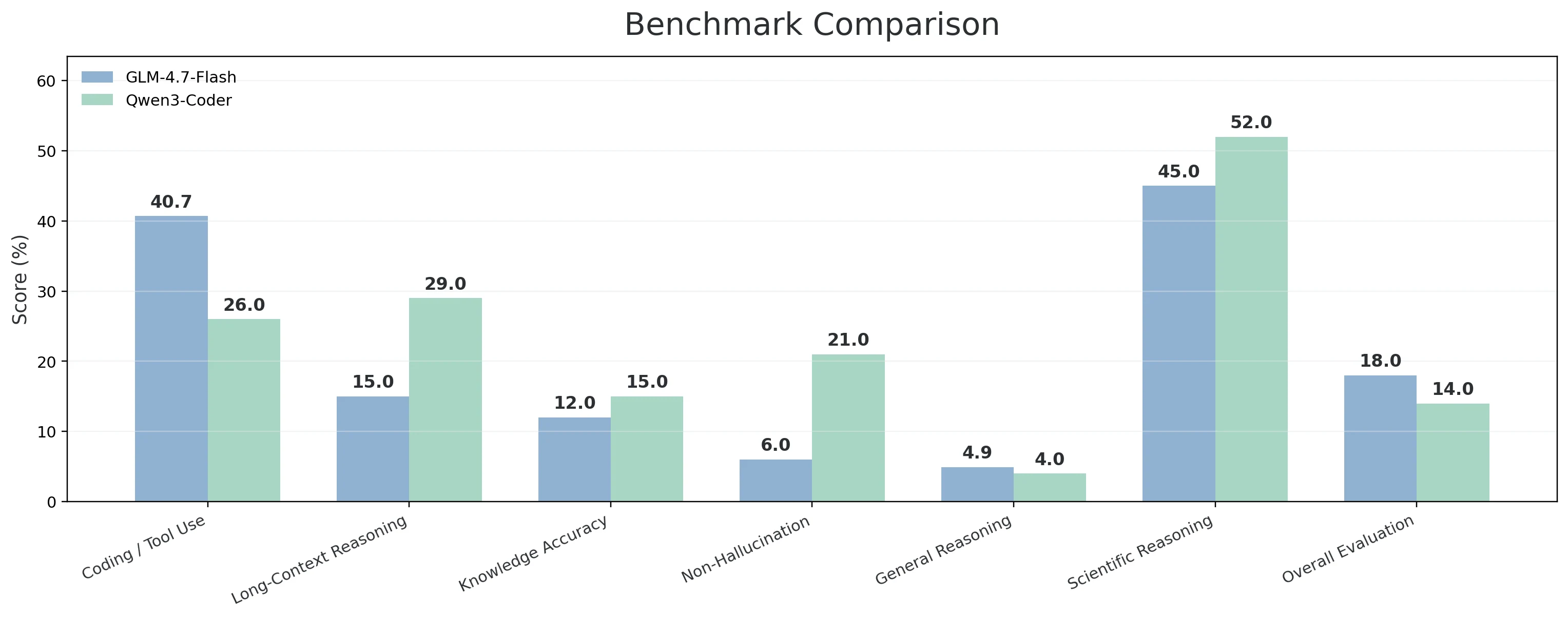
| 能力維度 | 包含的基準測試 | GLM-4.7-Flash | Qwen3-Coder |
| 編碼 / 終端 / 工具使用 | Terminal-Bench Hard;τ²-Bench Telecom;SciCode | 40.70% | 26.00% |
| 長上下文推理 | AA-LCR | 15.00% | 29.00% |
| 知識準確率 | AA-Omniscience Accuracy | 12.00% | 15.00% |
| 非幻覺(可靠性) | AA-Omniscience 非幻覺率 | 6.00% | 21.00% |
| 通用推理與知識 | Humanity’s Last Exam | 4.90% | 4.00% |
| 科學推理 | GPQA Diamond | 45.00% | 52.00% |
| 綜合判斷 / 評估 | GDPval-AA | 18.00% | 14.00% |
- GLM-4.7-Flash 在最貼近「工程實務」的編碼 / 終端 / 工具使用維度表現更優,得分為 40.7% 對 26.0%。這組測試(Terminal-Bench Hard + τ²-Bench Telecom + SciCode)非常貼近真實工作流程:模型需要編寫程式碼、與工具互動、解讀輸出並持續推進任務。此外,它在綜合判斷維度(透過 GDPval-AA 測得 18.0% 對 14.0%)也有更強的表現,同時在通用推理與知識(Humanity’s Last Exam:4.9% 對 4.0%)也有小幅領先。
- Qwen3-Coder-30B 在任務較長、對可靠性要求高的場景下表現突出。它在長上下文推理維度領先(29.0% 對 15.0%),當你輸入大型倉庫上下文或長規格文件、需要模型保持連貫性時,這項能力至關重要。它在非幻覺 / 可靠性(21.0% 對 6.0%)也有明顯優勢,且在知識準確率(15.0% 對 12.0%)小幅領先,適合對錯誤容忍度極低的場景。此外它在科學推理(GPQA Diamond:52.0% 對 45.0%)也更強,這對研究導向或數學複雜度較高的編碼任務很有幫助。
若你需要工具密集型編碼執行與實務決策能力,可選擇 GLM-4.7-Flash;若需要長上下文深度與更高的可靠性,可選擇 Qwen3-Coder-30B。
速度與延遲對比
對編碼助手而言,「足夠快」不僅指原始吞吐量,更關鍵的是模型開始回應的速度(TTFT,首個回答 token 耗時)以及單輪互動的端到端耗時。
| 指標 | GLM-4.7-Flash | Qwen3-Coder-30B | 更優方向 |
| 延遲(TTFT:首個回答 token 耗時) | 0.9 秒 | 1.5 秒 | 越低越好 → GLM-4.7-Flash |
| 端到端回應耗時(500 個輸出 token) | 5.6 秒 | 6.3 秒 | 越低越好 → GLM-4.7-Flash |
| 輸出速度(token/秒) | 106 tok/s | 104 tok/s | 越高越好 → GLM-4.7-Flash |
解讀
- 聊天/IDE 中更靈活的「首個回應」:GLM-4.7-Flash 耗時 0.9 秒即可輸出首個回答 token,相比 Qwen3-Coder-30B 的 1.5 秒,在互動式編碼對話、IDE 協同編程、快速除錯循環中回應靈敏度明顯更高。
- 常見編碼提示詞的單輪完成速度更快:生成 500 個 token 的回應時,GLM-4.7-Flash 耗時 5.6 秒,遠低於 Qwen3-Coder-30B 的 6.3 秒,在使用者快速進行多輪迭代的場景下持續領先。
- 解碼吞吐量相近:兩者的輸出速度非常接近(106 對 104 token/秒),因此使用者體驗的關鍵優勢主要來自延遲 + 端到端耗時,而非原始 token 每秒輸出量。
成本對比
| 成本項目(Novita 無伺服器模式) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| 輸入價格(每百萬 token) | $0.07 / 百萬 token | $0.07 / 百萬 token |
| 輸出價格(每百萬 token) | $0.40 / 百萬 token | $0.27 / 百萬 token |
| 快取讀取(每百萬 token) | $0.01 / 百萬 token | - |
在 Novita 無伺服器模式下,Qwen3-Coder (30B-A3B) 在輸出密集型編碼場景下成本更低(輸出單價更低);而當上下文重複使用、適用快取讀取定價時,GLM-4.7-Flash 的成本效益更高。
快速開始:立即在 Playground 試用兩款模型
Novita AI 提供了互動式 Playground,你可以立即測試兩款模型,無需任何部署操作。
部署方式:API、SDK、第三方整合與本地部署
API
取得 API 金鑰
-
步驟 1:建立帳號或登入現有帳號 造訪
[**https://novita.ai**](https://novita.ai),註冊新帳號 或登入你現有的帳號 -
步驟 2:前往金鑰管理頁面 登入後,找到「API Keys」選項

-
步驟 3:建立新金鑰 點擊「Add New Key」按鈕。

-
步驟 4:立即保存你的金鑰 金鑰生成後請立即複製並妥善保存;它通常只會顯示一次,後續無法再次取得。請將金鑰存放在密碼管理器或加密筆記等安全位置
相容 OpenAI 的 API(Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
若你要構建代理工作流程(路由、交接、工具/函式調用),Novita 支援相容 OpenAI 的 SDK,只需少量修改即可適配:
- 即插即用:保留你現有的客戶端邏輯,只需修改 base_url 與 model 參數即可
- 支援編排:可輕鬆實現路由邏輯(預設使用 Flash,必要時升級至 GLM-4.7)
- 配置方式:將端點指向
https://api.novita.ai/openai,設置NOVITA_API_KEY環境變數,選擇zai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instruct模型
第三方平台
你也可以透過主流生態系統使用 Novita 托管的 GLM 模型:
- 代理框架與應用構建工具:跟隨 Novita 的逐步整合指南,連接主流工具如 Continue、AnythingLLM、LangChain 和 Langflow。
- Hugging Face Hub:Novita 已被列為 Hugging Face 的推理供應商,你可以透過 Hugging Face 的供應商工作流與生態系統運行受支援的模型。
- 相容 OpenAI 的 API:Novita 的 LLM 端點完全相容 OpenAI API 標準,可輕鬆遷移現有的 OpenAI 風格應用,並連接眾多 OpenAI 相容工具(Cline、Cursor、Trae 以及 Qwen Code)。
- 相容 Anthropic 的 API:Novita 也提供相容 Anthropic SDK 的存取方式,可將 Novita 支援的模型整合至 Claude Code 風格的代理編碼工作流程中。
- OpenCode:Novita AI 現已直接整合至 OpenCode 作為支援的供應商,使用者無需手動配置即可在 OpenCode 中選擇 Novita。
本地與私有部署
由於 GLM-4.7-Flash 與 Qwen3-Coder 30B (A3B) 相比前沿級模型體量較小,對於偏好本地化部署的團隊而言是務實的選擇——無論是出於隱私、合規要求,還是需要更嚴格的執行階段控制。
若你想享受本地部署的優勢,又不想費力維護自己的 GPU 硬體、驅動程式與 CUDA 技術棧,可以在 Novita GPU 實例上運行這些模型。Novita 也提供了不斷擴充的模板庫幫助你快速啟動,其中包含開箱即用的 GLM-4.7-Flash 模板。
結論
若你需要以下特性,可選擇 GLM-4.7-Flash:
- 快速、低延遲的互動體驗
- 強大的代理編碼與工具使用能力
- 大幅降低生產環境成本
若你需要以下特性,可選擇 Qwen3-Coder:
- 深度的長上下文推理能力
- 科學或分析場景的高可靠性
- 大規模程式碼倉庫的理解能力
在 Novita AI 上,兩款模型均已達到生產可用級別;但對於大多數互動式、對成本敏感的編碼工作負載而言,GLM-4.7-Flash 能提供最佳的綜合平衡。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面輕鬆部署 AI 模型,同時也提供高性價比、可靠的 GPU 雲端服務,用於構建與擴展 AI 應用。
常見問題
什麼是 GLM-4.7-Flash?
GLM-4.7-Flash 是由智譜 AI 開發的 300 億參數級混合專家(MoE)大型語言模型,專為提供高效能、低延遲的強推理、編碼與代理能力而設計。
什麼是 Qwen3-30B-A3B?
Qwen3-30B-A3B 是 Qwen3-Coder 系列的 300 億參數 MoE 編碼模型,每 token 僅活躍約 30 億參數,在效率與深度之間取得了平衡,擅長長上下文程式碼理解、大型倉庫分析與高精度推理。
GLM-4.7-Flash 的定價是多少?
在 Novita AI(無伺服器模式)上,GLM-4.7-Flash 的定價為輸入 token 每百萬 0.07 美元、快取讀取 token 每百萬 0.01 美元、輸出 token 每百萬 0.40 美元,在大上下文與高吞吐量工作負載下性價比極高。
Qwen3-30B-A3B 是否為多模態模型?
不是。Qwen3-30B-A3B 是純文字(編碼導向)模型,不支援圖像、音訊等多模態輸入,專為編碼、長上下文推理與程式碼倉庫級別分析場景設計。



