

プロダクション向けのコーディング特化型LLMを選ぶ際には、通常、次の3つの現実を天秤にかけることになります。
- 実際のエンジニアリングタスクにおけるコード品質
- インタラクティブな開発者体験のための速度とレイテンシ
- スケール時のコスト(特にコンテキストが長くなる場合)
この記事では、GLM-4.7-Flash と Qwen3-Coder-30B を、その観点から比較します。具体的には、ベンチマーク + 速度/レイテンシデータ(以下にプレースホルダを含む)、および Novita AIの公式価格 に基づいてコストを評価します。
基本紹介
| 項目 | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| 提供元 | Z.ai (GLMシリーズ) | Alibaba (Qwenシリーズ) |
| リリース日 | 2026年1月 | 2025年7月 |
| アーキテクチャ | MoE: 合計約30Bパラメータ / トークンあたり約3Bアクティブ | MoE: 合計約30Bパラメータ / トークンあたり約3Bアクティブ (A3B) |
| 入出力 | テキスト → テキスト | テキスト → テキスト |
| コンテキスト長 | 200K(出力128K) | ネイティブ262K(YaRNで最大1Mまで拡張可能) |
| 推論モード | 思考モード対応 | 思考モードなし |
| Novita Model ID | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
大まかなポイント: GLM-4.7-Flash は、プロダクションやインタラクティブなワークフローにおける 高速で制御しやすい実行 に最適化されています。一方、Qwen3-Coder-30B は、いくつかの「難しい」評価において より強力な深い推論シグナル に重点を置いており、その代償としてインタラクティブな環境でのレイテンシが高くなっています。
ベンチマーク比較
ベンチマークのストーリーは、基本的に 実行指向のコーディング と 深さ指向の推論 の間のトレードオフです。
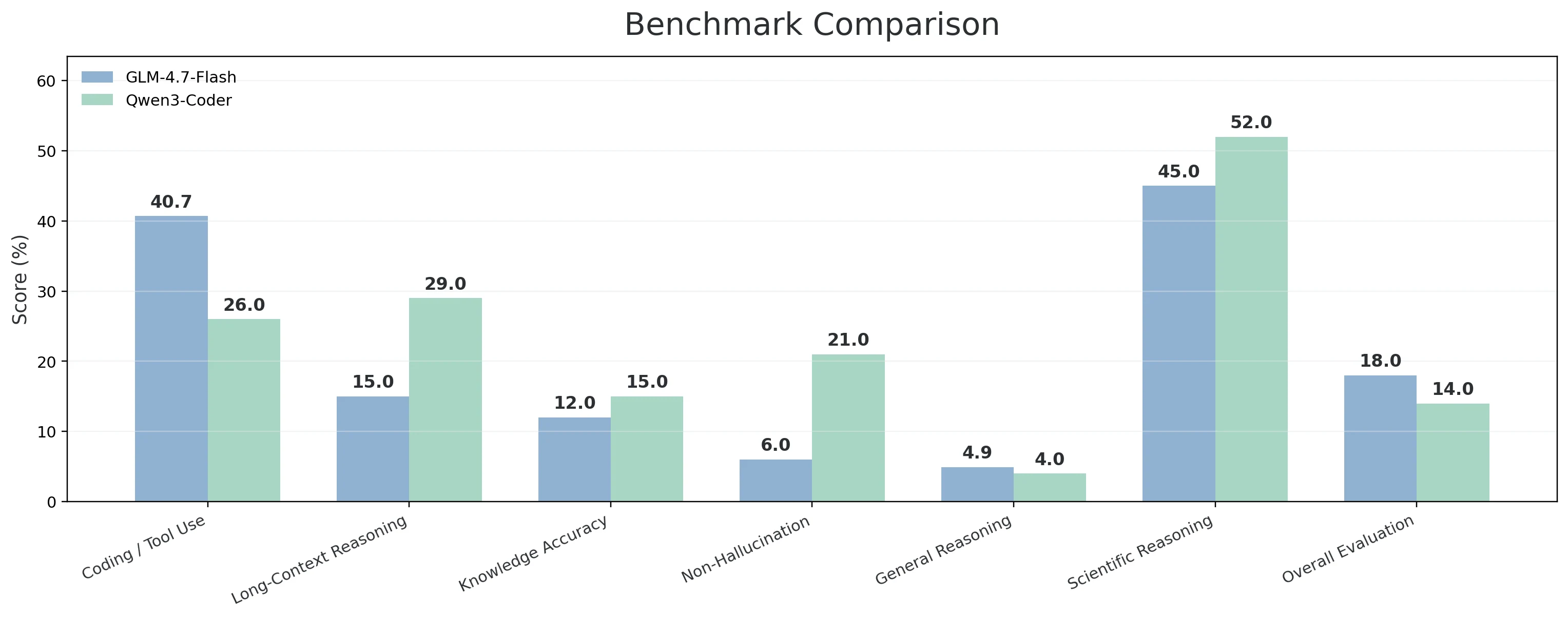
| 能力次元 | 含まれるベンチマーク | GLM-4.7-Flash | Qwen3-Coder |
| コーディング / ターミナル / ツール使用 | Terminal-Bench Hard; τ²-Bench Telecom; SciCode | 40.70% | 26.00% |
| 長文コンテキスト推論 | AA-LCR | 15.00% | 29.00% |
| 知識精度 | AA-Omniscience Accuracy | 12.00% | 15.00% |
| 非幻覚(信頼性) | AA-Omniscience Non-Hallucination Rate | 6.00% | 21.00% |
| 一般推論・知識 | Humanity’s Last Exam | 4.90% | 4.00% |
| 科学的推論 | GPQA Diamond | 45.00% | 52.00% |
| 総合判断 / 評価 | GDPval-AA | 18.00% | 14.00% |
- GLM-4.7-Flash は、最も「工学らしい」バケットである コーディング / ターミナル / ツール使用 で優れており、40.7% 対 26.0% というスコアを記録しています。この組み合わせ(Terminal-Bench Hard + τ²-Bench Telecom + SciCode)は、モデルが コードを書き、ツールと対話し、出力を解釈し、動き続ける 必要がある実際のワークフローによく対応しています。また、GDPval-AA による 総合判断 (18.0% 対 14.0%) でも強いシグナルを示しており、一般推論・知識 (Humanity’s Last Exam: 4.9% 対 4.0%) でもわずかに優れています。
- Qwen3-Coder-30B は、タスクが 長く、信頼性が重要な場合 に輝きます。長文コンテキスト推論 (29.0% 対 15.0%) でリードしており、これは大規模なリポジトリコンテキストや長い仕様を読み込んで、モデルに一貫性を保たせる必要がある場合に重要です。また、非幻覚 / 信頼性 (21.0% 対 6.0%) で大きなアドバンテージを持ち、知識精度 (15.0% 対 12.0%) でも控えめながらリードしており、誤った確信によるミスがコストになる場合により適しています。さらに、科学的推論 (GPQA Diamond: 52.0% 対 45.0%) でも強く、研究色が強かったり数学的に複雑なコーディングタスクで役立ちます。
GLM-4.7-Flash はツール多用のコーディング実行と実践的な意思決定に、Qwen3-Coder-30B は長文コンテキストでの深い理解と高い信頼性に、それぞれ適しています。
速度 & レイテンシ比較
コーディングアシスタントにとって、「十分な速さ」とは単なる生のスループットだけではありません。モデルが応答を開始する速さ (TTFT) と 典型的なターンがエンドツーエンドで完了するまでの時間 が重要です。
| 指標 | GLM-4.7-Flash | Qwen3-Coder-30B | 優位性(方向性) |
| レイテンシ (TTFT: 最初の回答トークンまでの時間) | 0.9 秒 | 1.5 秒 | 低いほど良い → GLM-4.7-Flash |
| エンドツーエンド応答時間 (出力500トークン) | 5.6 秒 | 6.3 秒 | 低いほど良い → GLM-4.7-Flash |
| 出力速度 (トークン/秒) | 106 tok/s | 104 tok/s | 高いほど良い → GLM-4.7-Flash |
解釈
- チャット/IDEでの「より機敏な初回応答」: GLM-4.7-Flash は最初の回答トークンに 0.9秒 で到達するのに対し、Qwen3-Coder は 1.5秒 です。そのため、インタラクティブなコーディングチャット、IDEのコパイロット、迅速なデバッグループでは、明らかに応答性が高くなります。
- 一般的なコーディングプロンプトでのターン完了が高速: 500トークンの応答の場合、GLM-4.7-Flash は 5.6秒 で完了するのに対し、Qwen3-Coder は 6.3秒 です。ユーザーが多くのターンで素早く反復する場合に、一貫したアドバンテージとなります。
- 同程度の復号スループット: 出力速度は近い(106 vs 104 tok/s)ため、主なユーザー体験上のアドバンテージは、主に レイテンシ + エンドツーエンド時間 であり、生のトークン/秒ではありません。
コスト比較
| コスト項目 (Novita Serverless) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| 入力価格 (100万トークンあたり) | $0.07 / Mt | $0.07 / Mt |
| 出力価格 (100万トークンあたり) | $0.40 / Mt | $0.27 / Mt |
| キャッシュ読み取り (100万トークンあたり) | $0.01 / Mt | - |
Novita Serverless では、Qwen3-Coder (30B-A3B) は出力の多いコーディング(出力 $/Mt が低い)で安価であり、GLM-4.7-Flash は繰り返しコンテキストに キャッシュ読み取り が適用される場合に、よりコスト効率が良くなります。
クイックスタート: Playground で両モデルを即座に試す
Novita AI は インタラクティブな Playground を提供しており、デプロイ不要で両方のモデルを即座にテストできます。
デプロイ方法: API、SDK、インテグレーション、ローカルデプロイ
API
API キーの取得
- ステップ 1: アカウントを作成またはログイン
[**https://novita.ai**](https://novita.ai) にアクセスし、サインアップするか、既存のアカウントにログインします。
- ステップ 2: キー管理に移動
ログイン後、「API Keys」を見つけます。

- ステップ 3: 新しいキーを作成
「Add New Key」ボタンをクリックします。

- ステップ 4: キーをすぐに保存
生成されたらすぐにキーをコピーして保存します。通常は一度だけ表示され、後で取得することはできません。パスワードマネージャーや暗号化されたメモなど、安全な場所に保管してください。
OpenAI 互換 API (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # または "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
エージェントワークフロー(ルーティング、ハンドオフ、ツール/関数呼び出し)を構築している場合、Novita は最小限の変更で OpenAI 互換 SDK と連携します。
- ドロップイン互換: 既存のクライアントロジックを維持し、base_url と model を変更するだけです。
- オーケストレーション準備完了: ルーティング(デフォルトで Flash → GLM-4.7 エスカレーション)を簡単に実装できます。
- セットアップ:
https://api.novita.ai/openaiを指すようにし、NOVITA_API_KEYを設定し、zai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instructを選択します。
サードパーティプラットフォーム
Novita がホストする GLM モデルは、人気のあるエコシステムを通じて実行することもできます。
- エージェントフレームワーク & アプリビルダー: Novita のステップバイステップの統合ガイドに従って、Continue、AnythingLLM、LangChain、Langflow などの人気ツールと接続できます。
- Hugging Face Hub: Novita は Hugging Face 上で Inference Provider としてリストされているため、Hugging Face のプロバイダーワークフローとエコシステムを通じてサポートされているモデルを実行できます。
- OpenAI 互換 API: Novita の LLM エンドポイントは OpenAI API 標準と互換性があるため、既存の OpenAI スタイルのアプリを簡単に移行でき、多くの OpenAI 互換ツール(Cline、Cursor、Trae、Qwen Code)と接続できます。
- Anthropic 互換 API: Novita は Anthropic SDK 互換のアクセスも提供しており、Novita バックエンドのモデルを Claude Code スタイルのエージェントコーディングワークフローに統合できます。
- OpenCode: Novita AI は現在、サポートされているプロバイダーとして OpenCode に直接統合されているため、手動設定なしで OpenCode 内で Novita を選択できます。
ローカル & プライベートデプロイ
GLM-4.7-Flash と Qwen3-Coder 30B (A3B) は、フロンティア規模のモデルと比較して比較的軽量であるため、プライバシー、コンプライアンス、またはランタイムのより厳密な制御を好むチームにとって、ローカルスタイルのデプロイには実用的な選択肢です。
独自の GPU ハードウェア、ドライバー、CUDA スタックを維持する手間をかけずにローカルデプロイの利点を得たい場合は、Novita GPU Instances で実行できます。Novita は、すぐに使える GLM-4.7-Flash テンプレートを含む、より迅速な起動を支援する テンプレートライブラリ も提供しています。
まとめ
次の場合は GLM-4.7-Flash を選択してください:
- 高速で低レイテンシなインタラクションが必要
- 強力なエージェント的コーディングとツール使用が必要
- プロダクションコストを大幅に抑えたい
次の場合は Qwen3-Coder を選択してください:
- 深い長文コンテキスト推論が必要
- 科学的または分析的な信頼性が必要
- 大規模リポジトリの理解が必要
Novita AI では、両モデルともプロダクション対応ですが、ほとんどのインタラクティブでコスト重視のコーディングワークロード**において、GLM-4.7-Flash が最良の総合バランスを提供します。
Novita AI は、AI クラウドプラットフォームです。開発者がシンプルな API を使用して AI モデルを簡単にデプロイできるようにすると同時に、手頃で信頼性の高い GPU クラウドを構築およびスケーリングのために提供します。
よくある質問
GLM-4.7-Flash とは何ですか?
GLM-4.7-Flash は、Zhipu AI によって開発された 30B クラスの Mixture-of-Experts (MoE) 大規模言語モデルで、強力な推論、コーディング、エージェント性能を高い効率と低レイテンシで提供するように設計されています。
Qwen3-30B-A3B とは何ですか?
Qwen3-30B-A3B は、Qwen3-Coder シリーズの 30B パラメータ MoE コーディングモデルです。トークンあたり約 3B のアクティブパラメータにより、効率と深さのバランスを取り、長文コード理解、大規模リポジトリ分析、高精度推論に優れています。
GLM-4.7-Flash の費用はいくらですか?
Novita AI (サーバーレス) では、GLM-4.7-Flash の価格は 入力トークン $0.07/M、キャッシュ読み取りトークン $0.01/M、出力トークン $0.40/M であり、大規模コンテキストや高スループットのワークロードにコスト効率が良いです。
Qwen3-30B-A3B はマルチモーダルですか?
いいえ。Qwen3-30B-A3B はテキスト専用(コード特化型)モデルです。画像や音声などのマルチモーダル入力はサポートしておらず、コーディング、長文コンテキスト推論、リポジトリレベルの分析専用に設計されています。



