

Si vous choisissez un LLM axé sur le développement pour la production, vous équilibrez généralement trois réalités :
- Qualité du code sur des tâches d’ingénierie réelles
- Vitesse et latence pour une expérience développeur interactive
- Coût à grande échelle (surtout lorsque le contexte devient long)
Dans cet article, nous comparons GLM-4.7-Flash et Qwen3-Coder-30B sous cet angle, en utilisant des benchmarks + des fichiers de vitesse/latence (des exemples sont inclus ci-dessous) et les tarifs officiels de Novita AI pour le coût.
Introduction générale
| Élément | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| Éditeur | Z.ai (série GLM) | Alibaba (série Qwen) |
| Date de sortie | Janvier 2026 | Juillet 2025 |
| Architecture | MoE : ~30 milliards de paramètres totaux / ~3 milliards de paramètres actifs par token | MoE : ~30 milliards de paramètres totaux / ~3 milliards de paramètres actifs par token (A3B) |
| Entrée / Sortie | Texte → Texte | Texte → Texte |
| Longueur de contexte | 200K (128K en sortie) | 262K natif (jusqu’à 1M avec YaRN) |
| Mode de raisonnement | Prend en charge les modes de réflexion | Pas de mode de réflexion |
| ID de modèle Novita | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
Point clé : Le GLM-4.7-Flash est optimisé pour une exécution rapide et contrôlable dans les environnements de production et les flux de travail interactifs, tandis que le Qwen3-Coder-30B mise sur des signaux de raisonnement approfondi plus forts sur plusieurs évaluations « difficiles » — au prix d’une latence plus élevée dans les environnements interactifs.
Comparaison des benchmarks
La comparaison des benchmarks repose essentiellement sur un compromis entre développement orienté exécution et raisonnement orienté profondeur.
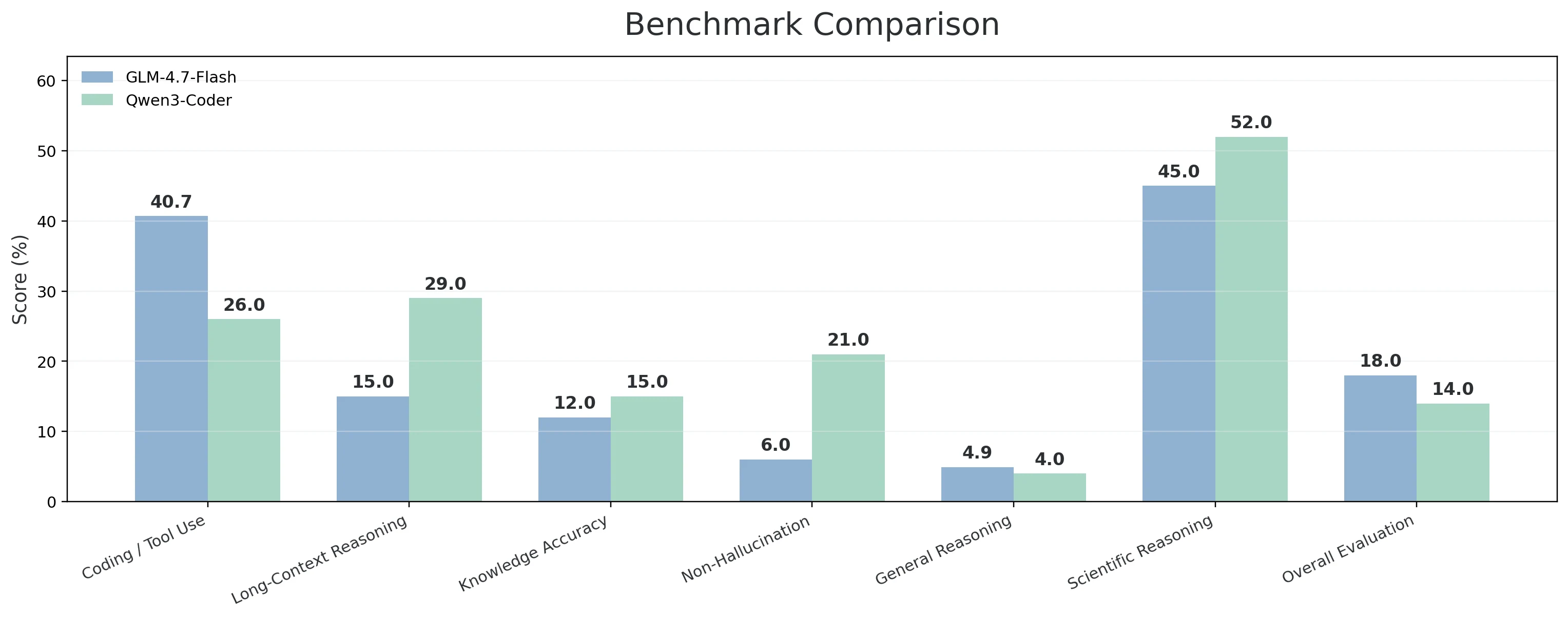
| Dimension de capacité | Benchmarks inclus | GLM-4.7-Flash | Qwen3-Coder |
| Développement / Terminal / Utilisation d’outils | Terminal-Bench Hard ; τ²-Bench Telecom ; SciCode | 40,70 % | 26,00 % |
| Raisonnement sur longs contextes | AA-LCR | 15,00 % | 29,00 % |
| Précision des connaissances | AA-Omniscience Accuracy | 12,00 % | 15,00 % |
| Non-hallucination (Fiabilité) | AA-Omniscience Non-Hallucination Rate | 6,00 % | 21,00 % |
| Raisonnement et connaissances générales | Humanity’s Last Exam | 4,90 % | 4,00 % |
| Raisonnement scientifique | GPQA Diamond | 45,00 % | 52,00 % |
| Jugement et évaluation globaux | GDPval-AA | 18,00 % | 14,00 % |
- Le GLM-4.7-Flash obtient de meilleurs résultats dans la catégorie la plus « axée ingénierie » — Développement / Terminal / Utilisation d’outils — avec un score de 40,7 % contre 26,0 %. Cette combinaison (Terminal-Bench Hard + τ²-Bench Telecom + SciCode) correspond bien aux flux de travail réels où le modèle doit écrire du code, interagir avec des outils, interpréter des résultats et continuer d’avancer. Il affiche également un signal plus fort sur le jugement global via GDPval-AA (18,0 % contre 14,0 %), ainsi qu’un léger avantage sur le raisonnement et les connaissances générales (Humanity’s Last Exam : 4,9 % contre 4,0 %).
- Le Qwen3-Coder-30B excelle lorsque les tâches sont longues et sensibles à la fiabilité. Il est en tête du raisonnement sur longs contextes (29,0 % contre 15,0 %), ce qui est important lorsque vous fournissez un contexte de dépôt important ou des spécifications longues et que vous avez besoin que le modèle reste cohérent. Il présente également un avantage majeur sur l’absence d’hallucination / fiabilité (21,0 % contre 6,0 %) et une avance modeste sur la précision des connaissances (15,0 % contre 12,0 %), ce qui en fait un meilleur choix lorsque les erreurs assertives sont coûteuses. Il est également plus performant en raisonnement scientifique (GPQA Diamond : 52,0 % contre 45,0 %), ce qui peut être important pour des tâches de développement plus orientées recherche ou mathématiquement complexes.
Vous pouvez choisir le GLM-4.7-Flash pour l’exécution de développement intensive en outils et la prise de décision pratique ; choisissez le Qwen3-Coder-30B pour la profondeur sur longs contextes et une fiabilité accrue.
Comparaison de la vitesse et de la latence
Pour les assistants de développement, « suffisamment rapide » ne concerne pas seulement le débit brut — il s’agit de la rapidité à laquelle le modèle commence à répondre (TTFT, Time To First Token) et de la durée d’un tour typique de bout en bout.
| Métrique | GLM-4.7-Flash | Qwen3-Coder-30B | Meilleur (direction) |
| Latence (TTFT : temps jusqu’au premier token de réponse) | 0,9 s | 1,5 s | Plus bas est mieux → GLM-4.7-Flash |
| Temps de réponse de bout en bout (500 tokens de sortie) | 5,6 s | 6,3 s | Plus bas est mieux → GLM-4.7-Flash |
| Vitesse de sortie (tokens par seconde) | 106 tok/s | 104 tok/s | Plus élevé est mieux → GLM-4.7-Flash |
Interprétation
- Réponse « initiale » plus réactive dans les chats/IDE : le GLM-4.7-Flash atteint le premier token de réponse en 0,9 s contre 1,5 s, ce qui le rend nettement plus réactif pour les chats de développement interactifs, les copilotes d’IDE et les boucles de débogage rapide.
- Achèvement des tours plus rapide pour les prompts de développement courants : pour une réponse de 500 tokens, le GLM-4.7-Flash termine en 5,6 s contre 6,3 s — un avantage constant lorsque les utilisateurs itèrent rapidement sur de nombreux tours.
- Débit de décodage similaire : la vitesse de sortie est proche (106 contre 104 tok/s), donc l’avantage principal pour l’expérience utilisateur est surtout la latence + le temps de bout en bout, et non le nombre brut de tokens par seconde.
Comparaison des coûts
| Élément de coût (Novita Serverless) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| Prix d’entrée (par million de tokens) | 0,07 $ / Mt | 0,07 $ / Mt |
| Prix de sortie (par million de tokens) | 0,40 $ / Mt | 0,27 $ / Mt |
| Lecture de cache (par million de tokens) | 0,01 $ / Mt | - |
Sur Novita Serverless, le Qwen3-Coder (30B-A3B) est moins cher pour le développement intensif en sortie (coût de sortie $/Mt plus bas), tandis que le GLM-4.7-Flash devient plus rentable lorsque la lecture de cache s’applique à des contextes répétés.
Démarrage rapide : Essayez les deux modèles instantanément sur le Playground
Novita AI propose un Playground interactif où vous pouvez tester les deux modèles instantanément — aucun déploiement nécessaire.
Comment déployer : API, SDK, intégrations et déploiement local
API
Obtenir une clé API
- Étape 1 : Créer un compte ou se connecter à votre compte existant
Rendez-vous sur [**https://novita.ai**](https://novita.ai) et inscrivez-vous ou connectez-vous à votre compte existant
- Étape 2 : Accéder à la gestion des clés
Après vous être connecté, recherchez « Clés API »

- Étape 3 : Créer une nouvelle clé
Cliquez sur le bouton « Ajouter une nouvelle clé ».

- Étape 4 : Enregistrez votre clé immédiatement
Copiez et stockez la clé dès qu’elle est générée ; elle n’est généralement affichée qu’une seule fois et ne peut pas être récupérée ultérieurement. Conservez la clé dans un emplacement sécurisé tel qu’un gestionnaire de mots de passe ou des notes chiffrées
API compatible OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Si vous développez des flux de travail agentiques (routage, transferts, appels d’outils/fonctions), Novita fonctionne avec des SDK compatibles OpenAI avec des modifications minimales :
- Compatible immédiat : conservez votre logique client existante ; modifiez simplement base_url + model
- Prêt pour l’orchestration : facile à mettre en place pour le routage (par défaut Flash → escalade vers GLM-4.7)
- Configuration : pointez vers
https://api.novita.ai/openai, définissezNOVITA_API_KEY, sélectionnezzai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instruct
Plateformes tierces
Vous pouvez également exécuter des modèles GLM hébergés par Novita via des écosystèmes populaires :
- Frameworks d’agents et outils de création d’applications : suivez les guides d’intégration pas à pas de Novita pour vous connecter à des outils populaires tels que Continue, AnythingLLM, LangChain et Langflow.
- Hub Hugging Face : Novita est répertorié comme fournisseur d’inférence sur Hugging Face, vous pouvez donc exécuter les modèles pris en charge via le flux de travail et l’écosystème de fournisseur de Hugging Face.
- API compatible OpenAI : les points de terminaison LLM de Novita sont compatibles avec la norme d’API OpenAI, ce qui facilite la migration d’applications existantes de style OpenAI et la connexion à de nombreux outils compatibles OpenAI ( Cline, Cursor , Trae et Qwen Code) .
- API compatible Anthropic : Novita propose également un accès compatible avec le SDK Anthropic pour que vous puissiez intégrer des modèles supportés par Novita dans des flux de travail de développement agentiques de style Claude Code.
- OpenCode : Novita AI est désormais intégré directement à OpenCode en tant que fournisseur pris en charge, donc les utilisateurs peuvent sélectionner Novita dans OpenCode sans configuration manuelle.
Déploiement local et privé
Étant donné que le GLM-4.7-Flash et le Qwen3-Coder 30B (A3B) sont relativement légers par rapport aux modèles de pointe, ce sont des options pratiques pour les équipes qui préfèrent un déploiement de type local — que ce soit pour des raisons de confidentialité, de conformité ou d’un contrôle plus strict sur l’environnement d’exécution.
Si vous souhaitez bénéficier des avantages du déploiement local sans les tracas liés à la maintenance de votre propre matériel GPU, pilotes et pile CUDA, vous pouvez les exécuter sur des Instances GPU Novita. Novita propose également une Bibliothèque de modèles en constante croissance pour vous aider à lancer plus rapidement, incluant un modèle GLM-4.7-Flash prêt à l’emploi.
Explorer la bibliothèque de modèles
Conclusion
Choisissez le GLM-4.7-Flash si vous avez besoin de :
- interaction rapide et à faible latence
- développement agentique et utilisation d’outils performants
- coût de production nettement plus bas
Choisissez le Qwen3-Coder si vous avez besoin de :
- raisonnement approfondi sur longs contextes
- fiabilité scientifique ou analytique
- compréhension de dépôts à grande échelle
Sur Novita AI, les deux modèles sont prêts pour la production — mais pour la plupart des charges de travail de développement interactives et sensibles aux coûts, le GLM-4.7-Flash offre le meilleur équilibre global.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.
Foire aux questions
Qu’est-ce que le GLM-4.7-Flash ?
Le GLM-4.7-Flash est un modèle de langage large de classe 30B de type Mélange d’Experts (MoE) développé par Zhipu AI, conçu pour offrir des performances élevées en raisonnement, développement et agentique, avec une grande efficacité et une faible latence.
Qu’est-ce que le Qwen3-30B-A3B ?
Le Qwen3-30B-A3B est un modèle de développement MoE de 30 milliards de paramètres issu de la gamme Qwen3-Coder. Avec ~3 milliards de paramètres actifs par token, il équilibre efficacité et profondeur, excelle dans la compréhension de code sur longs contextes, l’analyse de grands dépôts et le raisonnement de haute précision.
Combien coûte le GLM-4.7-Flash ?
Sur Novita AI (sans serveur), le GLM-4.7-Flash est tarifé à 0,07 $ par million de tokens d’entrée, 0,01 $ par million de tokens de lecture en cache et 0,40 $ par million de tokens de sortie, ce qui le rend rentable pour les charges de travail à grand contexte et haut débit.
Le Qwen3-30B-A3B est-il multimodal ?
Non. Le Qwen3-30B-A3B est un modèle texte uniquement (axé sur le code). Il ne prend pas en charge les entrées multimodales telles que des images ou de l’audio, et est conçu spécifiquement pour le développement, le raisonnement sur longs contextes et l’analyse au niveau du dépôt.



