

إذا كنت تختار نموذج لغة كبير مخصص للبرمجة للاستخدام الإنتاجي، فأنت عادة ما توازن بين ثلاث حقائق:
- جودة الكود في مهام الهندسة الحقيقية
- السرعة والكمون لتجربة مطور تفاعلية
- التكلفة عند التوسع (خاصة عندما يصبح السياق طويلاً)
في هذا المنشور، نقارن بين GLM-4.7-Flash و Qwen3-Coder-30B من خلال هذا المنظور—باستخدام ملفات المعايير + السرعة/الكمون (البيانات الوهمية مذكورة أدناه)، و أسعار Novita AI الرسمية لحساب التكلفة.
مقدمة أساسية
| البند | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| الناشر | Z.ai (سلسلة GLM) | Alibaba (سلسلة Qwen) |
| تاريخ الإصدار | يناير 2026 | يوليو 2025 |
| البنية | MoE: ~30B معامل إجمالي / ~3B معامل نشط لكل رمز | MoE: ~30B معامل إجمالي / ~3B معامل نشط لكل رمز (A3B) |
| الإدخال / الإخراج | نص ← نص | نص ← نص |
| طول السياق | 200 ألف (128 ألف إخراج) | 262 ألف أصلي (حتى 1 مليون مع YaRN) |
| وضع الاستدلال | يدعم أوضاع التفكير | يدعم فقط الأوضاع غير التفكير |
| معرف نموذج Novita | zai-org/glm-4.7-flash | qwen/qwen3-coder-30b-a3b-instruct |
الخلاصة العامة: تم تحسين GLM-4.7-Flash لـ تنفيذ سريع وقابل للتحكم في سير العمل الإنتاجي والتفاعلي، بينما يركز Qwen3-Coder-30B على إشارات استدلال عميقة أقوى في عدة تقييمات “صعبة”—بسعر كمون أعلى في الإعدادات التفاعلية.
مقارنة المعايير
قصة المعايير هي في الأساس مفاضلة بين البرمجة الموجهة للتنفيذ و الاستدلال الموجه للعمق.
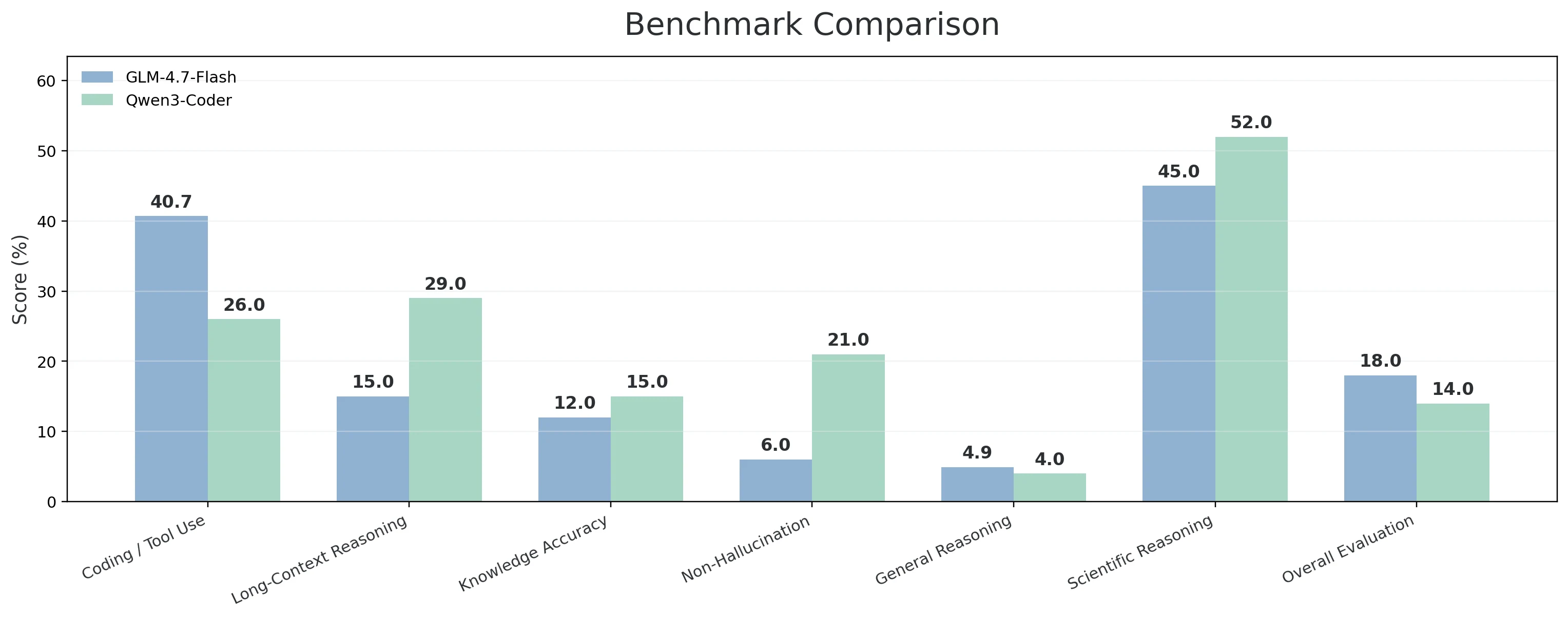
| بعد القدرة | المعايير المدرجة | GLM-4.7-Flash | Qwen3-Coder |
| البرمجة / الطرفية / استخدام الأدوات | Terminal-Bench Hard؛ τ²-Bench Telecom؛ SciCode | 40.70% | 26.00% |
| استدلال السياق الطويل | AA-LCR | 15.00% | 29.00% |
| دقة المعرفة | AA-Omniscience Accuracy | 12.00% | 15.00% |
| عدم التخيل (الموثوقية) | AA-Omniscience Non-Hallucination Rate | 6.00% | 21.00% |
| الاستدلال العام والمعرفة | Humanity’s Last Exam | 4.90% | 4.00% |
| الاستدلال العلمي | GPQA Diamond | 45.00% | 52.00% |
| الحكم العام / التقييم | GDPval-AA | 18.00% | 14.00% |
- يحقق GLM-4.7-Flash أداء أفضل في الفئة الأكثر “تشابهاً مع الهندسة”—البرمجة / الطرفية / استخدام الأدوات—بنتيجة 40.7% مقابل 26.0%. تتوافق هذه المجموعة (Terminal-Bench Hard + τ²-Bench Telecom + SciCode) جيداً مع سير العمل الحقيقي حيث يجب على النموذج كتابة الكود، التفاعل مع الأدوات، تفسير المخرجات، والاستمرار في التقدم. كما يظهر إشارة أقوى على الحكم العام عبر GDPval-AA (18.0% مقابل 14.0%)، بالإضافة إلى ميزة صغيرة في الاستدلال العام والمعرفة (Humanity’s Last Exam: 4.9% مقابل 4.0%).
- يتألق Qwen3-Coder-30B عندما تكون المهام طويلة وحساسة للموثوقية. يتقدم في استدلال السياق الطويل (29.0% مقابل 15.0%)، وهو أمر مهم عندما تقوم بتغذية سياق مستودع كبير أو مواصفات طويلة وتحتاج إلى أن يبقى النموذج متماسكاً. كما لديه ميزة كبيرة في عدم التخيل / الموثوقية (21.0% مقابل 6.0%) وتقدم متواضع في دقة المعرفة (15.0% مقابل 12.0%)، مما يجعله خياراً أفضل عندما تكون الأخطاء الواثقة مكلفة. كما أنه أقوى في الاستدلال العلمي (GPQA Diamond: 52.0% مقابل 45.0%)، والذي يمكن أن يهم في مهام البرمجة الأكثر اعتماداً على البحث أو المعقدة رياضياً.
يمكنك اختيار GLM-4.7-Flash للتنفيذ البرمجي الثقيل بالأدوات واتخاذ القرارات العملية؛ اختر Qwen3-Coder-30B لعمق السياق الطويل وموثوقية أعلى.
مقارنة السرعة والكمون
بالنسبة لمساعدي البرمجة، “سريع بدرجة كافية” لا يتعلق فقط بالسرعة الإنتاجية الخام—بل يتعلق بـ مدى سرعة بدء النموذج في الاستجابة (TTFT: الوقت حتى أول رمز إجابة) و مدة استغراق الدور النموذجي من البداية إلى النهاية.
| المقياس | GLM-4.7-Flash | Qwen3-Coder-30B | الأفضل (الاتجاه) |
| الكمون (TTFT: الوقت حتى أول رمز إجابة) | 0.9 ثانية | 1.5 ثانية | الأقل هو الأفضل ← GLM-4.7-Flash |
| وقت الاستجابة من البداية إلى النهاية (500 رمز إخراج) | 5.6 ثانية | 6.3 ثانية | الأقل هو الأفضل ← GLM-4.7-Flash |
| سرعة الإخراج (رموز/ثانية) | 106 رمز/ثانية | 104 رمز/ثانية | الأعلى هو الأفضل ← GLM-4.7-Flash |
التفسير
- استجابة “أولية” أسرع في الدردشة / بيئة التطوير المتكاملة: يصل GLM-4.7-Flash إلى أول رمز إجابة في 0.9 ثانية مقابل 1.5 ثانية، مما يجعله أكثر استجابة بشكل ملحوظ لدردشات البرمجة التفاعلية، ومساعدي الكتابة في بيئات التطوير المتكاملة، وحلقات تصحيح الأخطاء السريعة.
- إكمال أسرع للدور للمطالبات البرمجية الشائعة: لاستجابة من 500 رمز، ينتهي GLM-4.7-Flash في 5.6 ثانية مقابل 6.3 ثانية—ميزة متسقة عندما يتكرر المستخدمون بسرعة عبر العديد من الأدوار.
- سرعة فك الترميز متشابهة: سرعة الإخراج قريبة (106 مقابل 104 رمز/ثانية)، لذا فإن ميزة تجربة المستخدم الرئيسية هي في الغالب الكمون + الوقت من البداية إلى النهاية، وليس الرموز/ثانية الخام.
مقارنة التكلفة
| بند التكلفة (Novita Serverless) | GLM-4.7-Flash | Qwen3-Coder (30B-A3B) |
| سعر الإدخال (لكل مليون رمز) | $0.07 / مليون | $0.07 / مليون |
| سعر الإخراج (لكل مليون رمز) | $0.40 / مليون | $0.27 / مليون |
| قراءة الذاكرة المؤقتة (لكل مليون رمز) | $0.01 / مليون | - |
على Novita Serverless، يكون Qwen3-Coder (30B-A3B) أرخص للبرمجة الثقيلة بالإخراج (سعر إخراج أقل لكل مليون رمز)، بينما يصبح GLM-4.7-Flash أكثر كفاءة من حيث التكلفة عندما تنطبق قراءة الذاكرة المؤقتة على السياق المتكرر.
بداية سريعة: جرّب كلا النموذجين فوراً في مساحة اللعب
توفر Novita AI مساحة لعب تفاعلية حيث يمكنك اختبار كلا النموذجين فوراً—بدون الحاجة إلى نشر.
كيفية النشر: API، SDK، التكاملات والنشر المحلي
API
الحصول على مفتاح API
- الخطوة 1: إنشاء حساب أو تسجيل الدخول إلى حسابك الحالي
زر
[**https://novita.ai**](https://novita.ai)و سجل حساباً جديداً أو سجل الدخول إلى حسابك الحالي - الخطوة 2: الانتقال إلى إدارة المفاتيح
بعد تسجيل الدخول، ابحث عن “مفاتيح API”

- الخطوة 3: إنشاء مفتاح جديد
انقر على زر “إضافة مفتاح جديد”.

- الخطوة 4: احفظ مفتاحك فوراً انسخ المفتاح واحفظه فور توليده؛ عادة ما يظهر مرة واحدة فقط ولا يمكن استرداده لاحقاً. احتفظ بالمفتاح في مكان آمن مثل مدير كلمات المرور أو الملاحظات المشفرة
API متوافق مع OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash", # or "qwen/qwen3-coder-30b-a3b-instruct"
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
إذا كنت تبني سير عمل وكيل (التوجيه، التسليم بين الوكلاء، استدعاءات الأدوات / الوظائف)، تعمل Novita مع SDKs متوافقة مع OpenAI مع تغييرات طفيفة:
- متوافق فوراً: احتفظ بمنطق العميل الحالي الخاص بك؛ فقط قم بتغيير base_url + model
- جاهز للتنسيق: من السهل تنفيذ التوجيه (الافتراضي هو Flash → التصعيد إلى GLM-4.7)
- الإعداد: وجه إلى
https://api.novita.ai/openai، عيّنNOVITA_API_KEY، اخترzai-org/glm-4.7-flash/qwen/qwen3-coder-30b-a3b-instruct
منصات طرف ثالث
يمكنك أيضاً تشغيل نماذج GLM المستضافة على Novita عبر الأنظمة البيئية الشائعة:
- أطر الوكيل وبناة التطبيقات: اتبع أدلة التكامل خطوة بخطوة من Novita للاتصال بالأدوات الشائعة مثل Continue، AnythingLLM، LangChain، و Langflow.
- مركز Hugging Face: تم إدراج Novita كـ مزود استدلال على Hugging Face، لذا يمكنك تشغيل النماذج المدعومة عبر سير عمل ومجموعة أدوات مزود Hugging Face.
- API متوافق مع OpenAI: نقاط نهاية LLM الخاصة بـ Novita متوافقة مع معيار API لـ OpenAI، مما يسهل ترحيل التطبيقات الحالية ذات النمط OpenAI والاتصال بالعديد من الأدوات المتوافقة مع OpenAI ( Cline، Cursor ، Trae و Qwen Code).
- API متوافق مع Anthropic: توفر Novita أيضاً وصولاً متوافقاً مع Anthropic SDK حتى تتمكن من دمج النماذج المدعومة من Novita في سير عمل البرمجة الوكيل ذات النمط Claude Code.
- OpenCode: تم دمج Novita AI الآن مباشرة في OpenCode كـ مزود مدعوم، لذا يمكن للمستخدمين اختيار Novita في OpenCode دون تكوين يدوي.
النشر المحلي والخاص
بما أن GLM-4.7-Flash و Qwen3-Coder 30B (A3B) خفيفان نسبياً مقارنة بالنماذج ذات الحجم المتقدم، فهما خياران عمليان للفرق التي تفضل النشر المحلي—سواء للخصوصية، الامتثال، أو تحكم أكبر في وقت التشغيل.
إذا كنت تريد مزايا النشر المحلي بدون عناء صيانة عتاد GPU الخاص بك، وبرامج التشغيل، ومكدس CUDA، يمكنك تشغيلهما على مثيلات GPU من Novita. تقدم Novita أيضاً مكتبة قوالب متنامية لمساعدتك على الإطلاق بشكل أسرع، بما في ذلك قالب GLM-4.7-Flash الجاهز للاستخدام.
الخلاصة
اختر GLM-4.7-Flash إذا كنت بحاجة إلى:
- تفاعل سريع وكمون منخفض
- برمجة وكيل قوية واستخدام أدوات
- تكلفة إنتاجية أقل بشكل كبير
اختر Qwen3-Coder إذا كنت بحاجة إلى:
- استدلال عميق للسياق الطويل
- موثوقية علمية أو تحليلية
- فهم مستودعات على نطاق واسع
على Novita AI، كلا النموذجين جاهزان للإنتاج—لكن بالنسبة لمعظم أحمال عمل البرمجة التفاعلية والحساسة للتكلفة، يقدم GLM-4.7-Flash أفضل توازن عام.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.
الأسئلة الشائعة
ما هو GLM-4.7-Flash؟ GLM-4.7-Flash هو نموذج لغة كبير من فئة 30B من نوع Mixture-of-Experts (MoE) تم تطويره بواسطة Zhipu AI، مصمم لتقديم أداء قوي في الاستدلال، البرمجة، والأداء الوكيل مع كفاءة عالية وكمون منخفض.
ما هو Qwen3-30B-A3B؟ Qwen3-30B-A3B هو نموذج برمجة MoE من 30B معامل من سلسلة Qwen3-Coder. مع ~3B معامل نشط لكل رمز، فإنه يوازن بين الكفاءة والعمق، ويتفوق في فهم الكود للسياق الطويل، تحليل المستودعات الكبيرة، والاستدلال عالي الدقة.
كم تكلفة GLM-4.7-Flash؟ على Novita AI (بدون خادم)، يتم تسعير GLM-4.7-Flash بـ $0.07 لكل مليون رمز إدخال، $0.01 لكل مليون رمز قراءة من الذاكرة المؤقتة، و $0.40 لكل مليون رمز إخراج، مما يجعله فعالاً من حيث التكلفة لأحمال العمل ذات السياق الكبير والسرعة الإنتاجية العالية.
هل Qwen3-30B-A3B نموذج متعدد الوسائط؟ لا. Qwen3-30B-A3B هو نموذج نصي فقط (مخصص للبرمجة). لا يدعم مدخلات متعددة الوسائط مثل الصور أو الصوت، ومصمم خصيصاً للبرمجة، الاستدلال للسياق الطويل، والتحليل على مستوى المستودع.



