

GLM-4.1V-9B-Thinking 是一款突破性的 90 亿参数视觉语言模型,首次将推理优先方法引入多模态 AI。由 THUDM 开发,该模型通过独特的“思考范式”实现了透明的逐步推理过程,从而达成行业领先的性能。
尽管体积紧凑,GLM-4.1V-9B-Thinking 在 18 个基准测试中能够媲美甚至超越参数量大得多的 720 亿参数模型,展现出在多模态推理领域的卓越效率与能力。
限时优惠:新用户可领取 $10 免费额度,立即体验并利用 GLM-4.1V-9B-Thinking 进行开发。
以下是 GLM-4.1V-9B-Thinking API 在 Novita AI 的当前定价:$0.035 / M 输入 token,$0.138 / M 输出 token
什么是 GLM-4.1V-9B-Thinking?
视觉语言模型(VLM)已成为智能系统的基础组件。随着现实世界中的 AI 任务日益复杂,VLM 必须超越基本的多模态感知,展现出高级推理能力。这一演进聚焦于提升准确性、全面性和整体智能水平——为复杂问题求解、长上下文理解以及多模态智能体等应用铺平道路。
GLM-4.1V-9B-Thinking 是一款为满足这些需求而设计的下一代视觉语言模型,旨在推进通用多模态理解与推理。基于 GLM-4-9B-0414 基础模型,它引入了独特的“思考范式”,使其与众不同。
这一新范式允许模型在给出最终输出之前进行明确的、逐步的推理。与传统模型直接生成响应不同,GLM-4.1V-9B-Thinking 将其推理过程外部化,使之透明、可解释且可验证——为构建更可靠、能力更强的 AI 系统铺平道路。
主要特性与创新
灵活的输入处理:模型支持任意图像分辨率和宽高比。它集成了 2D-RoPE,能够有效处理极宽高比(超过 200:1)或高分辨率(超过 4K)的图像。
位置嵌入自适应:为保留预训练 ViT 的基础能力,模型保留了原始的可学习绝对位置嵌入。训练过程中,通过双三次插值将这些嵌入动态适应到可变分辨率输入。
时间理解:对于视频内容,模型在每个帧 token 后插入时间索引 token,时间索引通过将每帧的时间戳编码为字符串来实现。这种设计明确告知模型真实世界的时间戳以及帧之间的时间距离。
扩展上下文支持:模型支持 64K 上下文长度,并提供中英双语能力,在长文档理解和跨文化应用中表现强大。
相较前代模型的关键改进:
- 该系列首个专注于推理的模型,在多个子领域达到世界领先性能
- 支持 64K 上下文长度
- 处理任意宽高比和最高 4K 图像分辨率
- 提供支持中英双语的开放源代码版本
革命性训练框架
GLM-4.1V-9B-Thinking 采用创新训练方法,包含基于课程采样的强化学习(RLCS),系统性地提升了跨多个领域的推理能力。
阶段一:预训练基础
模型经过大规模预训练,具备强大的基础能力,涵盖大量包含准确事实知识的图像-文本对、自整理的交错图像与文本学术语料库,以及标注文档与图表。
阶段二:监督微调
该阶段作为强化学习的桥梁,将基础 VLM 转化为能够进行长思维链推理的模型。每个响应遵循标准结构,包含 thinking 和 <answer> 部分。
阶段三:强化学习创新
团队引入了基于课程采样的强化学习(RLCS),以推动大规模、跨领域的推理能力。RLCS 结合课程学习与难度感知采样,提升训练效率。
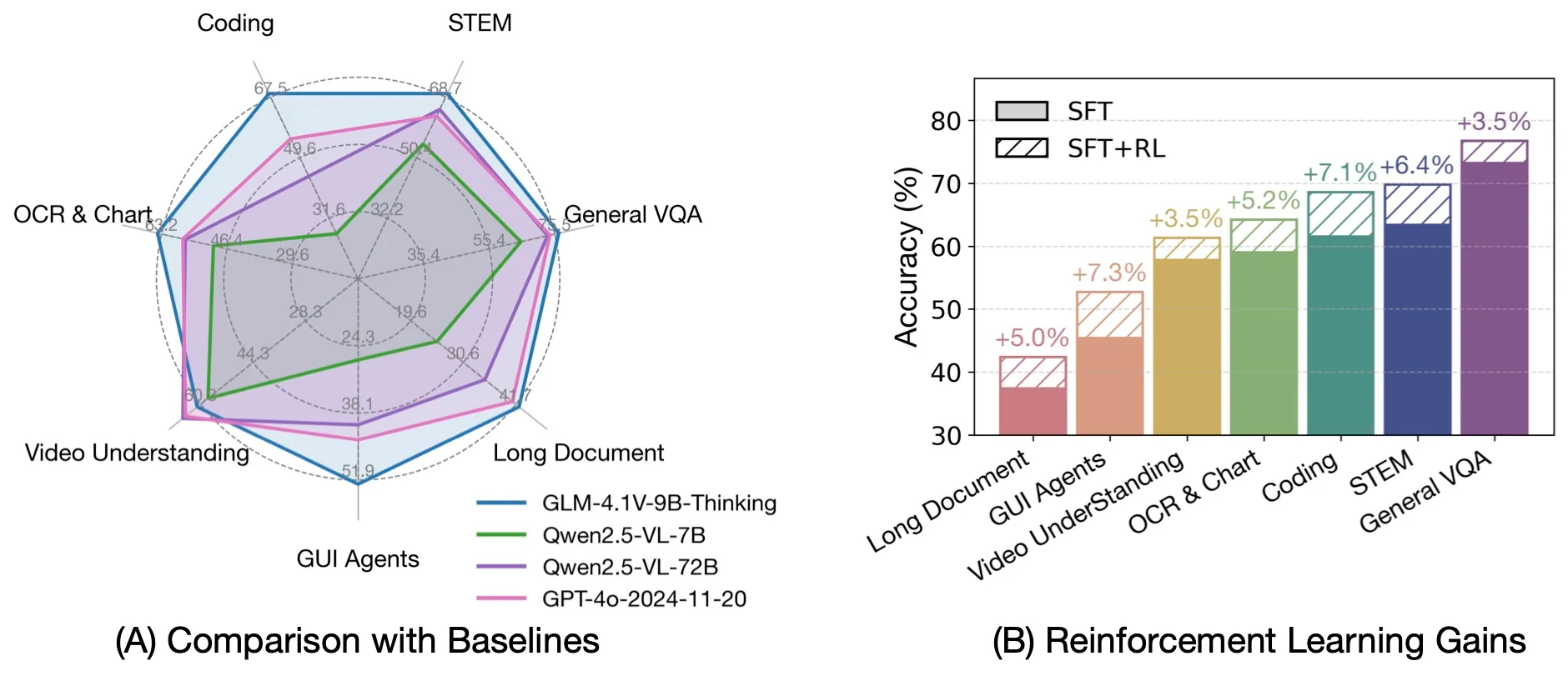
来源: THUDM
与其他高级 VLM 的对比
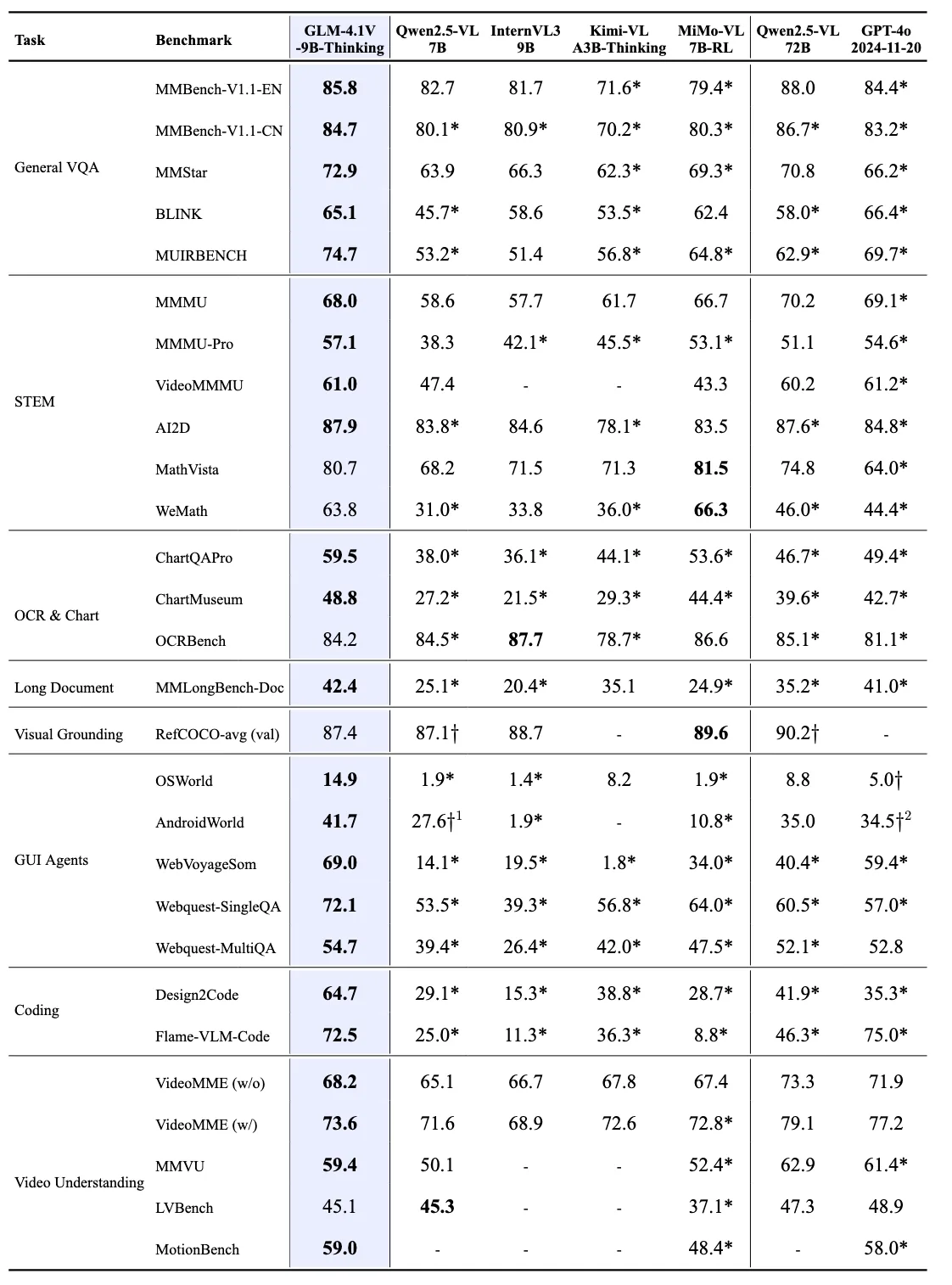
来源: THUDM
卓越效率:尽管体积相对紧凑,GLM-4.1V-9B-Thinking 在 28 个基准测试中的 18 个上超越了更大的 Qwen2.5-VL-72B 模型。这包括特别具有挑战性的任务,如 MMStar(72.9 vs 70.8)、MUIRBENCH(74.7 vs 62.9)、MMMU-Pro(57.1 vs 51.1)和 ChartMuseum(48.8 vs 39.6),展现了该模型的卓越效率与能力。
与专有模型的竞争性:与专有模型 GPT-4o 相比,GLM-4.1V-9B-Thinking 在大多数任务上取得了更优结果,包括 MMStar(72.9 vs 66.2)、MUIRBENCH(74.7 vs 69.7)、AI2D(87.9 vs 84.8)、MMMU-Pro(57.1 vs 54.6)、MathVista(80.7 vs 64.0)和 MotionBench(59.0 vs 58.0)。尽管 GPT-4o 规模更大且具有闭源优势,GLM-4.1V-9B-Thinking 仍取得了这样的性能。
在专项任务中的主导地位:该模型在 GUI 智能体任务中表现尤为突出:WebQuest-SingleQA 任务得分 72.1(对比 Qwen2.5-VL-72B 的 60.5 和 GPT-4o 的 57.0),WebVoyageSom 得分 69.0(对比 Qwen2.5-VL-72B 的 40.4 和 GPT-4o 的 59.4)。在编码任务中,Flame-VLM-Code 得分 72.5,大幅超越 72B 模型的 46.3,同时与 GPT-4o(75.0)保持竞争力。
最佳资源效率:这些发现强调了 GLM-4.1V-9B-Thinking 在性能与效率之间提供了出色的平衡。这使其成为计算资源受限的现实部署场景中极具吸引力的选择,在资源约束下提供了实用且强大的解决方案,同时在与更大规模系统的竞争中保持竞争力。
运行时需求
该模型高效架构支持在不同硬件配置下灵活部署,以下为官方规格说明。
推理
设备(单 GPU) |
框架 | 最小内存 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Token/秒 | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Token/秒 | BF16 |
微调
以下结果基于使用 LLaMA-Factory 工具包进行的图像微调。
| 设备(集群) | 策略 | 最小内存 / GPU 数量 | 批量大小(每 GPU) | 冻结 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPU | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPU | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPU | 1 | 不冻结 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPU | 1 | 不冻结 |
注意:使用 Zero2 微调可能导致零损失;建议使用 Zero3 以获得稳定训练。
如何在 Novita AI 上使用 GLM-4.1V-9B-Thinking
在 Novita AI 上开始使用 GLM-4.1V-9B-Thinking 快速、简单且无风险。通过推荐计划,你将获得 $10 的免费额度——足以全面探索 GLM-4.1V-9B-Thinking 的多模态推理能力、构建原型,甚至在无需前期成本的情况下启动你的第一个用例。
使用 Playground(无需编码)
即时访问:注册,领取免费额度,立即开始体验 GLM-4.1V-9B-Thinking 及其他顶级多模态模型。
交互式界面:实时测试图像理解、图表分析和透明推理工作流。通过直观界面体验模型独特的思考范式。
模型对比:轻松在 GLM-4.1V-9B-Thinking 与其他视觉语言模型及纯文本模型之间切换,找到最适合你多模态需求的模型。
通过 API 集成(适合开发者)
使用 Novita AI 的统一 REST API 将 GLM-4.1V-9B-Thinking 无缝集成到你的应用、工作流或聊天机器人中——无需管理模型权重或基础设施。
选项 1:直接 API 集成(Python 示例)
要开始使用多模态输入,只需使用下面的代码片段:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # 或 False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主要特性:
- 统一端点:
/v3/openai支持 OpenAI 的 Chat Completions API 格式。 - 灵活控制: 调整 temperature、top-p、惩罚项等,获得定制结果。
- 流式与批处理: 选择你偏好的响应模式。
选项 2:使用 OpenAI Agents SDK 构建多智能体工作流
通过将 Novita AI 与 OpenAI Agents SDK 集成,构建高级多模态智能体系统:
即插即用:在任何 OpenAI Agents 工作流中使用 GLM-4.1V-9B-Thinking 进行视觉语言任务。
支持交接、路由和工具使用:设计能够分析视觉内容、委派任务或运行函数的智能体,所有功能均由 GLM-4.1V-9B-Thinking 的推理能力驱动。
Python 集成:只需将 SDK 指向 Novita 的端点(https://api.novita.ai/v3/openai),并使用你的 API 密钥,即可实现无缝的多模态智能体工作流。
在第三方平台上连接 GLM-4.1V-9B-Thinking API
Hugging Face:通过 Novita AI 端点在 Spaces、pipelines 或 Transformers 库中使用 GLM-4.1V-9B-Thinking 进行多模态应用。
智能体与编排框架: 通过官方连接器和分步集成指南,轻松将 Novita AI 与合作伙伴平台如 Continue、AnythingLLM、LangChain、Dify 和 Langflow 连接。
兼容 OpenAI 的 API: 享受与 Cline 和 Cursor 等工具的无缝迁移与集成,这些工具专为 OpenAI API 标准设计。
结论
GLM-4.1V-9B-Thinking 是多模态 AI 领域的一个变革性里程碑,证明在 90 亿参数模型中也能高效实现高级推理能力。通过其创新的 RLCS 训练框架和独特思考范式,它在多个基准测试中媲美甚至超越更大的 720 亿参数系统。
立即在 Novita AI 上体验 GLM-4.1V-9B-Thinking 演示并 领取你的免费额度!
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时也提供经济且可靠的 GPU 云,用于构建和扩展应用。



