

GLM-4.1V-9B-Thinking es un modelo de lenguaje y visión de 9 mil millones de parámetros que introduce el primer enfoque centrado en el razonamiento para la IA multimodal. Desarrollado por THUDM, este modelo alcanza un rendimiento de vanguardia al implementar un “paradigma de pensamiento” único que permite procesos de razonamiento transparentes y paso a paso.
A pesar de su tamaño compacto, GLM-4.1V-9B-Thinking iguala o supera modelos mucho más grandes de 72B parámetros en 18 tareas de referencia, demostrando una eficiencia y capacidad excepcionales en el razonamiento multimodal.
Por tiempo limitado, los nuevos usuarios pueden reclamar $10 en créditos gratuitos para explorar y construir con GLM-4.1V-9B-Thinking.
Aquí está el precio actual de la API de GLM-4.1V-9B-Thinking en Novita AI: $0.035 / M tokens de entrada, $0.138 / M tokens de salida
¿Qué es GLM-4.1V-9B-Thinking?
Los Modelos de Lenguaje y Visión (VLMs) se han convertido en componentes fundamentales de los sistemas inteligentes. A medida que las tareas de IA en el mundo real se vuelven cada vez más complejas, los VLMs deben evolucionar más allá de la percepción multimodal básica para demostrar capacidades avanzadas de razonamiento. Esta evolución se centra en mejorar la precisión, la exhaustividad y la inteligencia general, allanando el camino para aplicaciones como la resolución de problemas complejos, la comprensión de contextos largos y los agentes multimodales.
GLM-4.1V-9B-Thinking es un Modelo de Lenguaje y Visión (VLM) de próxima generación diseñado para satisfacer estas demandas, avanzando en la comprensión y el razonamiento multimodal de propósito general. Construido sobre el modelo base GLM-4-9B-0414, introduce un “paradigma de pensamiento” revolucionario que lo distingue.
Este nuevo paradigma permite al modelo realizar un razonamiento explícito, paso a paso, antes de entregar las salidas finales. A diferencia de los modelos tradicionales que producen respuestas directas, GLM-4.1V-9B-Thinking externaliza su proceso de razonamiento, haciéndolo transparente, interpretable y verificable, allanando el camino para sistemas de IA más confiables y capaces.
Características Clave e Innovaciones
Manejo Flexible de Entradas: El modelo admite resoluciones de imagen arbitrarias y relaciones de aspecto. Integra 2D-RoPE, lo que permite procesar imágenes con relaciones de aspecto extremas (más de 200:1) o altas resoluciones (más de 4K).
Adaptación de Incrustación de Posición: Para preservar las capacidades fundamentales del ViT preentrenado, el modelo retiene las incrustaciones de posición absoluta aprendibles originales. Durante el entrenamiento, estas incrustaciones se adaptan dinámicamente a entradas de resolución variable mediante interpolación bicúbica.
Comprensión Temporal: Para contenido de video, el modelo inserta tokens de índice de tiempo después de cada token de fotograma, donde el índice de tiempo se implementa codificando la marca de tiempo de cada fotograma como una cadena. Este diseño informa explícitamente al modelo de las marcas de tiempo reales y las distancias temporales entre fotogramas.
Soporte de Contexto Extendido: El modelo admite una longitud de contexto de 64K y proporciona capacidades bilingües en chino e inglés, lo que lo hace potente para la comprensión de documentos largos y aplicaciones interculturales.
Mejoras Clave Respecto a Modelos Anteriores:
- Primer modelo centrado en el razonamiento en la serie que logra un rendimiento líder mundial en varios subdominios
- Admite una longitud de contexto de 64K
- Maneja relaciones de aspecto arbitrarias y resolución de imagen de hasta 4K
- Proporciona una versión de código abierto que admite uso bilingüe en chino e inglés
Marco de Entrenamiento Revolucionario
GLM-4.1V-9B-Thinking utiliza un enfoque de entrenamiento innovador que presenta Aprendizaje por Refuerzo con Muestreo Curricular (RLCS), que mejora sistemáticamente las capacidades de razonamiento en múltiples dominios.
Etapa 1: Fundamento de Preentrenamiento
El modelo se somete a un preentrenamiento a gran escala para equiparlo con capacidades fundamentales sólidas, que incluyen pares masivos de imagen-texto con conocimiento factual preciso, un corpus académico autogestionado con imágenes y texto intercalados, y documentos y diagramas anotados.
Etapa 2: Ajuste Fino Supervisado
Esta etapa funciona como un puente hacia el aprendizaje por refuerzo, transformando el VLM base en uno capaz de realizar inferencias de cadena de pensamiento larga (CoT). Cada respuesta sigue una estructura estandarizada con secciones de thinking y <answer>.
Etapa 3: Innovación en Aprendizaje por Refuerzo
El equipo introduce el Aprendizaje por Refuerzo con Muestreo Curricular (RLCS) para impulsar capacidades de razonamiento a gran escala y entre dominios. RLCS combina el aprendizaje curricular con un muestreo consciente de la dificultad para mejorar la eficiencia del entrenamiento.
Fuente: THUDM
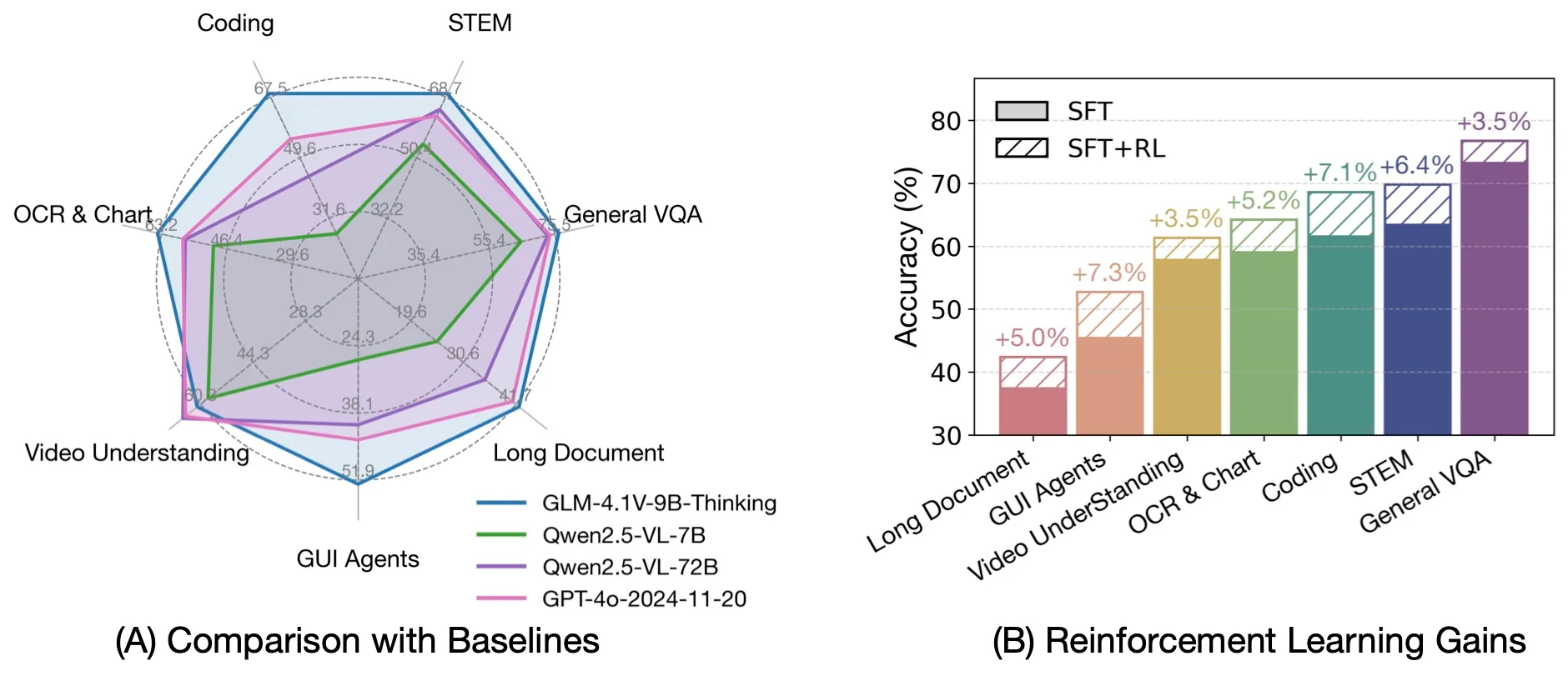
Comparación con Otros VLMs Avanzados
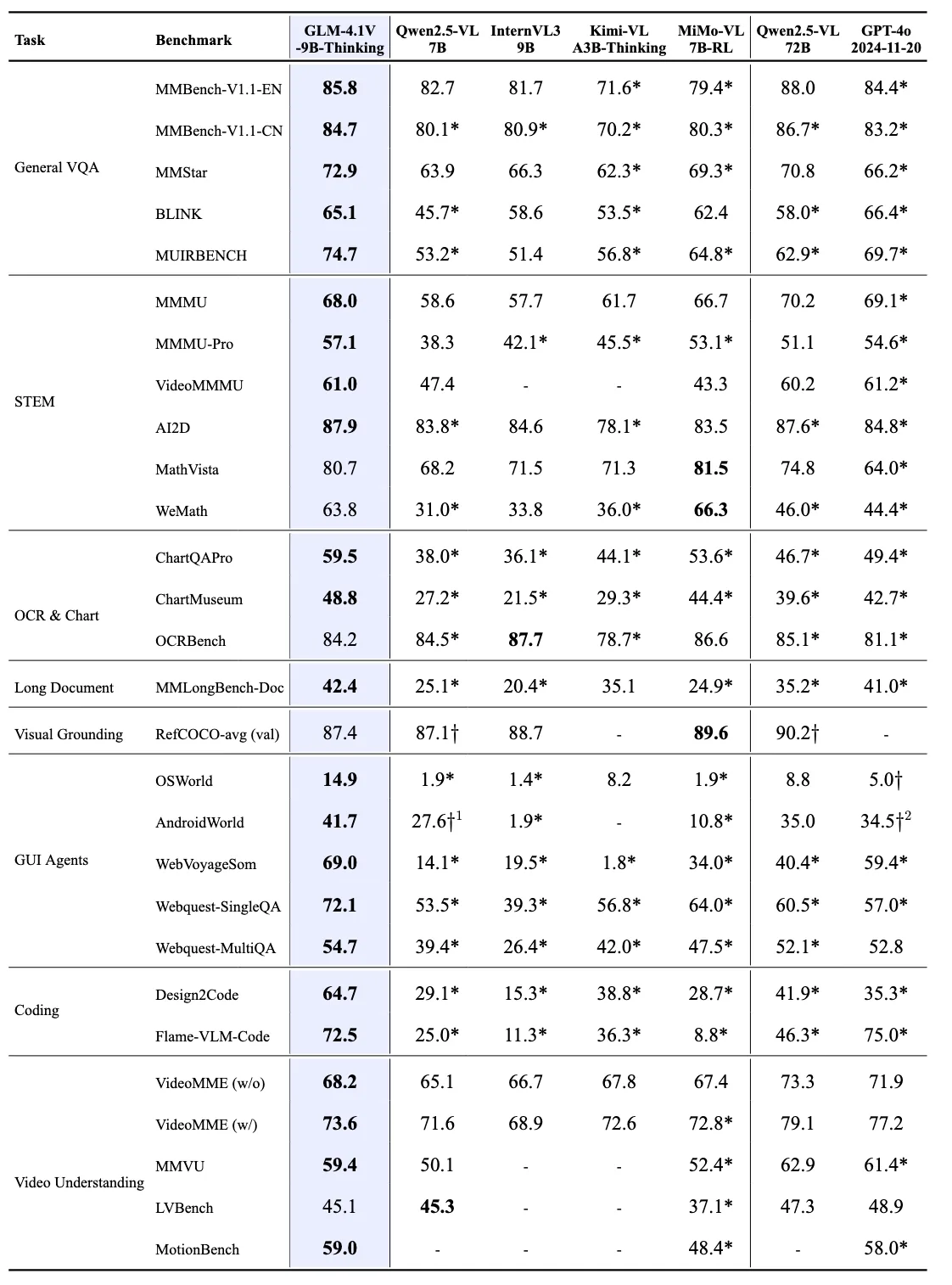
Fuente: THUDM
Eficiencia Excepcional: A pesar de su tamaño relativamente compacto, GLM-4.1V-9B-Thinking supera al modelo mucho más grande Qwen2.5-VL-72B en 18 de 28 puntos de referencia. Esto incluye tareas particularmente desafiantes como MMStar (72.9 vs 70.8), MUIRBENCH (74.7 vs 62.9), MMMU-Pro (57.1 vs 51.1) y ChartMuseum (48.8 vs 39.6), lo que ilustra la eficiencia y capacidad superior del modelo.
Competitivo Frente a Modelos Propietarios: En comparación con el propietario GPT-4o, GLM-4.1V-9B-Thinking logra resultados superiores en la mayoría de las tareas, incluyendo MMStar (72.9 vs 66.2), MUIRBENCH (74.7 vs 69.7), AI2D (87.9 vs 84.8), MMMU-Pro (57.1 vs 54.6), MathVista (80.7 vs 64.0) y MotionBench (59.0 vs 58.0). Este rendimiento se logra a pesar de la escala significativamente mayor de GPT-4o y su ventaja de código cerrado.
Dominio en Tareas Especializadas: El modelo muestra un rendimiento excepcional en tareas de agentes GUI, logrando 72.1 en WebQuest-SingleQA (vs 60.5 para Qwen2.5-VL-72B y 57.0 para GPT-4o), y 69.0 en WebVoyageSom (vs 40.4 para Qwen2.5-VL-72B y 59.4 para GPT-4o). En tareas de codificación, alcanza 72.5 en Flame-VLM-Code, superando significativamente al modelo de 72B (46.3) mientras se mantiene competitivo con GPT-4o (75.0).
Eficiencia Óptima de Recursos: Estos hallazgos enfatizan que GLM-4.1V-9B-Thinking ofrece un excelente equilibrio entre rendimiento y eficiencia. Esto lo convierte en una opción atractiva para el despliegue en el mundo real donde los recursos computacionales son limitados, proporcionando una solución práctica y potente bajo restricciones de recursos, manteniendo un rendimiento competitivo frente a sistemas mucho más grandes.
Explora la Demo de GLM-4.1V-9B-Thinking Ahora
Requisitos de Ejecución
La arquitectura eficiente del modelo permite opciones de despliegue flexibles en diversas configuraciones de hardware según las especificaciones oficiales.
Inferencia
Dispositivo (GPU única) |
Framework | Memoria Mínima | Velocidad | Precisión |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
Ajuste Fino
Los siguientes resultados se basan en el ajuste fino de imágenes utilizando el kit de herramientas LLaMA-Factory.
| Dispositivo (Clúster) | Estrategia | Memoria Mínima / # de GPUs | Tamaño de Lote (por GPU) | Congelación |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | Congelar VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | Congelar VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | Congelar VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | Sin Congelación |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | Sin Congelación |
Nota: El ajuste fino con Zero2 puede resultar en pérdida cero; se recomienda Zero3 para un entrenamiento estable.
Cómo Acceder a GLM-4.1V-9B-Thinking en Novita AI
Comenzar con GLM-4.1V-9B-Thinking es rápido, simple y sin riesgos en Novita AI. Gracias al Programa de Referidos, recibirás $10 en créditos gratuitos, suficientes para explorar completamente el poder de razonamiento multimodal de GLM-4.1V-9B-Thinking, crear prototipos e incluso lanzar tu primer caso de uso sin ningún costo inicial.
Usa el Playground (Sin Necesidad de Programar)
Acceso Instantáneo: Regístrate, reclama tus créditos gratuitos y comienza a experimentar con GLM-4.1V-9B-Thinking y otros modelos multimodales en segundos.
Interfaz de Usuario Interactiva: Prueba la comprensión de imágenes, el análisis de gráficos y los flujos de trabajo de razonamiento transparente en tiempo real. Experimenta el paradigma de pensamiento único del modelo a través de la interfaz intuitiva.
Comparación de Modelos: Cambia fácilmente entre GLM-4.1V-9B-Thinking, otros modelos de lenguaje y visión, y modelos solo de texto para encontrar la opción perfecta para tus necesidades multimodales.
Integra mediante API (Para Desarrolladores)
Conecta sin problemas GLM-4.1V-9B-Thinking a tus aplicaciones, flujos de trabajo o chatbots con la API REST unificada de Novita AI, sin necesidad de gestionar pesos de modelo o infraestructura.
Opción 1: Integración Directa de API (Ejemplo en Python)
Para comenzar con entradas multimodales, simplemente usa el fragmento de código a continuación:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Características Clave:
- Endpoint unificado:
/v3/openaies compatible con el formato de la API de Chat Completions de OpenAI. - Controles flexibles: Ajusta la temperatura, top-p, penalizaciones y más para obtener resultados personalizados.
- Streaming y lotes: Elige tu modo de respuesta preferido.
Opción 2: Flujos de Trabajo Multiagente con OpenAI Agents SDK
Construye sistemas de agentes multimodales avanzados integrando Novita AI con el OpenAI Agents SDK:
Plug-and-play: Usa GLM-4.1V-9B-Thinking en cualquier flujo de trabajo de OpenAI Agents para tareas de lenguaje y visión.
Admite traspasos, enrutamiento y uso de herramientas: Diseña agentes que puedan analizar contenido visual, delegar tareas o ejecutar funciones, todo potenciado por las capacidades de razonamiento de GLM-4.1V-9B-Thinking.
Integración Python: Simplemente apunta el SDK al endpoint de Novita (https://api.novita.ai/v3/openai) y usa tu clave API para flujos de trabajo de agentes multimodales sin interrupciones.
Conecta la API de GLM-4.1V-9B-Thinking en Plataformas de Terceros
Hugging Face: Usa GLM-4.1V-9B-Thinking en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI para aplicaciones multimodales.
Frameworks de Agentes y Orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
API Compatible con OpenAI: Disfruta de una migración e integración sin complicaciones con herramientas como Cline y Cursor, diseñadas para el estándar de la API de OpenAI.
Conclusión
GLM-4.1V-9B-Thinking representa un hito transformador en la IA multimodal, demostrando que las capacidades avanzadas de razonamiento pueden lograrse de manera eficiente en un modelo de 9 mil millones de parámetros. A través de su innovador marco de entrenamiento RLCS y su paradigma de pensamiento único, iguala o supera a sistemas mucho más grandes de 72B parámetros en diversos puntos de referencia.
¡Prueba la demo de GLM-4.1V-9B-Thinking en Novita AI ahora y reclama tus créditos gratuitos!
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.



