

GLM-4.1V-9B-Thinking is a groundbreaking 9-billion parameter vision-language model that introduces the first reasoning-focused approach to multimodal AI. Developed by THUDM, this model achieves state-of-the-art performance by implementing a unique “thinking paradigm” that enables transparent, step-by-step reasoning processes.
Despite its compact size, GLM-4.1V-9B-Thinking matches or surpasses much larger 72B parameter models across 18 benchmark tasks, demonstrating exceptional efficiency and capability in multimodal reasoning.
For a limited time, new users can claim **$10 in free credits**to explore and build with GLM-4.1V-9B-Thinking.
Here’s the current pricing of GLM-4.1V-9B-Thinking API on Novita AI: $0.035 / M input tokens, $0.138 / M output tokens
What is GLM-4.1V-9B-Thinking?
Vision-Language Models (VLMs) have become foundational components of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs must evolve beyond basic multimodal perception to demonstrate advanced reasoning capabilities. This evolution focuses on improving accuracy, comprehensiveness, and overall intelligence—paving the way for applications such as complex problem solving, long-context understanding, and multimodal agents.
GLM-4.1V-9B-Thinking is a next-generation Vision-Language Model (VLM) designed to meet these demands by advancing general-purpose multimodal understanding and reasoning. Built on the GLM-4-9B-0414 foundation model, it introduces a groundbreaking “thinking paradigm” that sets it apart.
This new paradigm allows the model to engage in explicit, step-by-step reasoning before delivering final outputs. Unlike traditional models that produce direct responses, GLM-4.1V-9B-Thinking externalizes its reasoning process, making it transparent, interpretable, and verifiable—paving the way for more trustworthy and capable AI systems.
Key Features and Innovations
Flexible Input Handling: The model supports arbitrary image resolutions and aspect ratios. It integrates 2D-RoPE, enabling effective processing of images with extreme aspect ratios (over 200:1) or high resolutions (beyond 4K).
Position Embedding Adaptation: To preserve foundational capabilities of the pre-trained ViT, the model retains original learnable absolute position embeddings. During training, these embeddings are dynamically adapted to variable-resolution inputs via bicubic interpolation.
Temporal Understanding: For video content, the model inserts time index tokens after each frame token, where the time index is implemented by encoding each frame’s timestamp as a string. This design explicitly informs the model of real-world timestamps and temporal distances between frames.
Extended Context Support: The model supports 64K context length and provides bilingual capabilities in Chinese and English, making it powerful for long-document understanding and cross-cultural applications.
Key Improvements Over Previous Models:
- First reasoning-focused model in the series achieving world-leading performance across various sub-domains
- Supports 64K context length
- Handles arbitrary aspect ratios and up to 4K image resolution
- Provides open-source version supporting both Chinese and English bilingual usage
Revolutionary Training Framework
GLM-4.1V-9B-Thinking uses an innovative training approach featuring Reinforcement Learning with Curriculum Sampling (RLCS), which systematically enhances reasoning capabilities across multiple domains.
Stage 1: Pre-training Foundation
The model undergoes large-scale pre-training to equip it with strong foundational capabilities, including massive image-text pairs with accurate factual knowledge, self-curated academic corpus with interleaved image and text, and annotated documents and diagrams.
Stage 2: Supervised Fine-tuning
This stage functions as a bridge to reinforcement learning, transforming the base VLM into one capable of long chain-of-thought (CoT) inference. Each response follows a standardized structure with <think> and <answer> sections.
Stage 3: Reinforcement Learning Innovation
The team introduces Reinforcement Learning with Curriculum Sampling (RLCS) to drive large-scale, cross-domain reasoning capabilities. RLCS combines curriculum learning with difficulty-aware sampling to improve training efficiency.
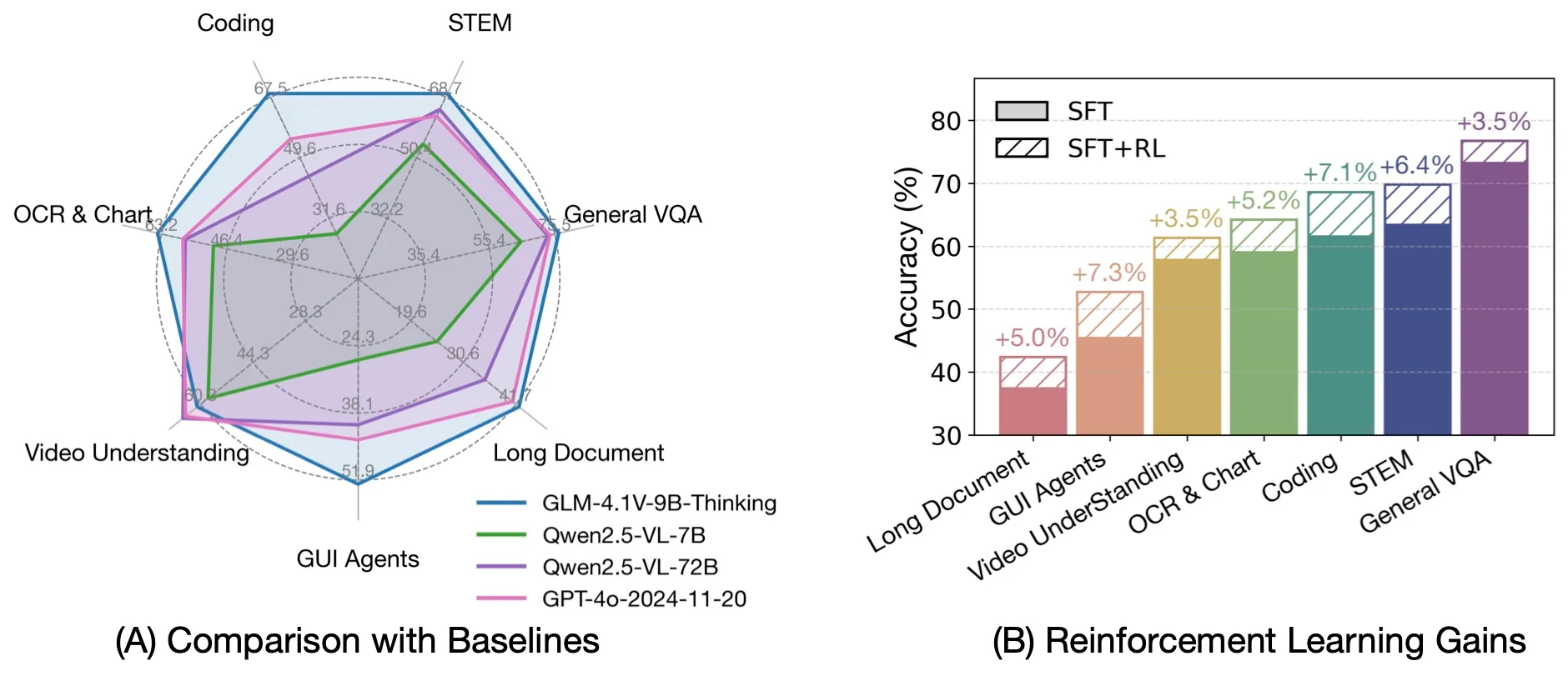
Source from: THUDM
Comparison to Other Advanced VLMs
Source from: THUDM
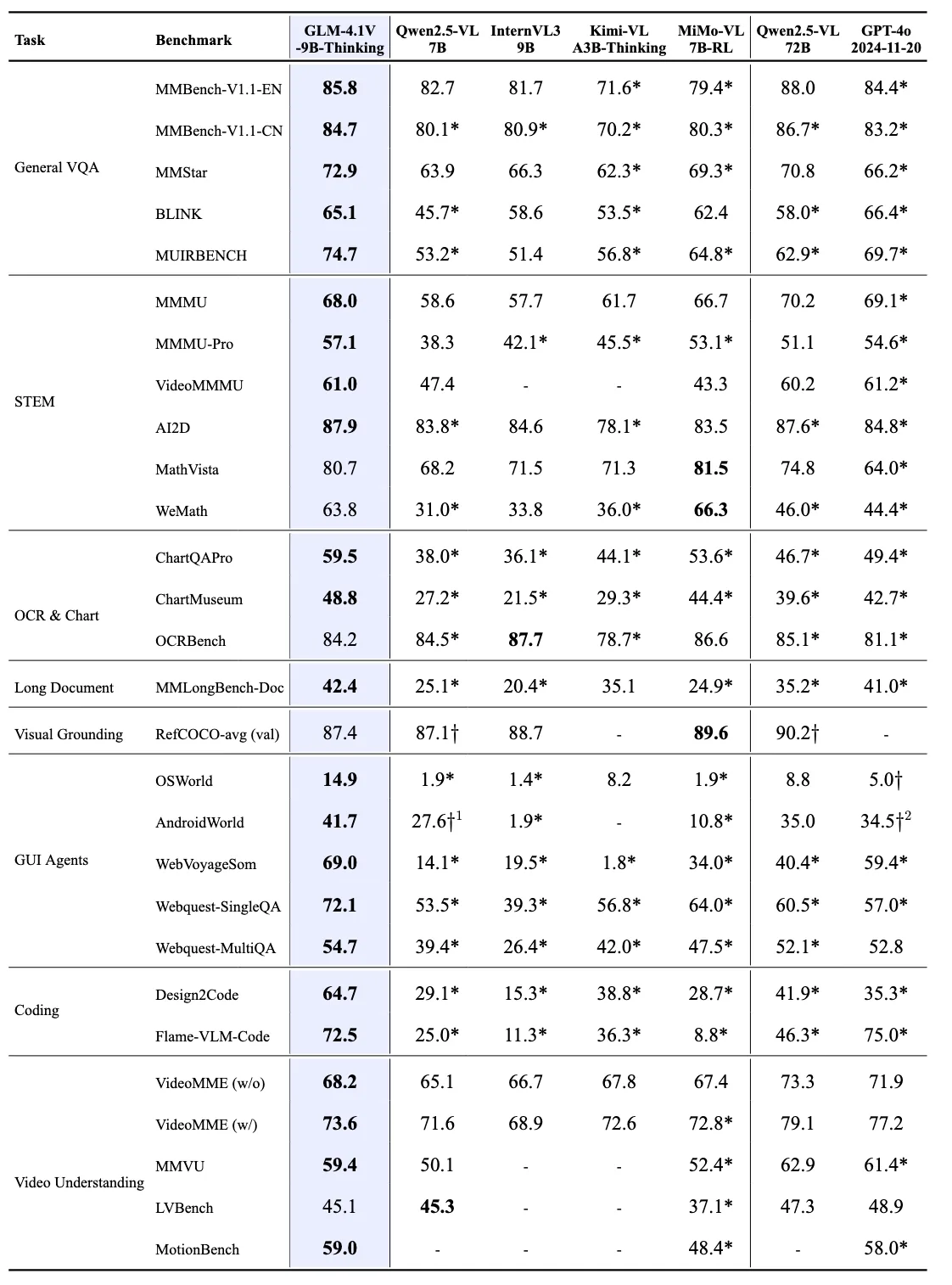
Exceptional Efficiency: Despite its relatively compact size, GLM-4.1V-9B-Thinking outperforms the much larger Qwen2.5-VL-72B model on 18 out of 28 benchmarks. This includes particularly challenging tasks such as MMStar (72.9 vs 70.8), MUIRBENCH (74.7 vs 62.9), MMMU-Pro (57.1 vs 51.1), and ChartMuseum (48.8 vs 39.6), illustrating the superior efficiency and capability of the model.
Competitive Against Proprietary Models: Compared with the proprietary GPT-4o, GLM-4.1V-9B-Thinking achieves superior results on most tasks including MMStar (72.9 vs 66.2), MUIRBENCH (74.7 vs 69.7), AI2D (87.9 vs 84.8), MMMU-Pro (57.1 vs 54.6), MathVista (80.7 vs 64.0), and MotionBench (59.0 vs 58.0). This performance is achieved despite GPT-4o’s significantly larger scale and closed-source advantage.
Dominance in Specialized Tasks: The model shows exceptional performance in GUI agent tasks, achieving 72.1 on WebQuest-SingleQA (vs 60.5 for Qwen2.5-VL-72B and 57.0 for GPT-4o), and 69.0 on WebVoyageSom (vs 40.4 for Qwen2.5-VL-72B and 59.4 for GPT-4o). In coding tasks, it achieves 72.5 on Flame-VLM-Code, significantly outperforming the 72B model (46.3) while remaining competitive with GPT-4o (75.0).
Optimal Resource Efficiency: These findings emphasize that GLM-4.1V-9B-Thinking offers an excellent trade-off between performance and efficiency. This makes it a compelling choice for real-world deployment where computational resources are constrained, providing a practical and powerful solution under resource constraints while maintaining competitive performance against much larger systems.
Explore GLM-4.1V-9B-Thinking Demo Now
Runtime Requirements
The model’s efficient architecture enables flexible deployment options across various hardware configurations based on the official specifications.
Inference
Device (Single GPU) | Framework | Min Memory | Speed | Precision |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
Fine-tuning
The following results are based on image fine-tuning using the LLaMA-Factory toolkit.
| Device (Cluster) | Strategy | Min Memory / # of GPUs | Batch Size (per GPU) | Freezing |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | No Freezing |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | No Freezing |
Note: Fine-tuning with Zero2 may result in zero loss; Zero3 is recommended for stable training.
How to Access GLM-4.1V-9B-Thinking on Novita AI
Getting started with GLM-4.1V-9B-Thinking is fast, simple, and risk-free on Novita AI. Thanks to the Referral Program, you’ll receive $10 in free credits—enough to fully explore GLM-4.1V-9B-Thinking’s multimodal reasoning power, build prototypes, and even launch your first use case without any upfront cost.
Use the Playground (No Coding Required)
Instant Access: Sign up, claim your free credits, and start experimenting with GLM-4.1V-9B-Thinking and other top multimodal models in seconds.
Interactive UI: Test image understanding, chart analysis, and transparent reasoning workflows in real time. Experience the model’s unique thinking paradigm through the intuitive interface.
Model Comparison: Effortlessly switch between GLM-4.1V-9B-Thinking, other vision-language models, and text-only models to find the perfect fit for your multimodal needs.
Integrate via API (For Developers)
Seamlessly connect GLM-4.1V-9B-Thinking to your applications, workflows, or chatbots with Novita AI’s unified REST API—no need to manage model weights or infrastructure.
Option 1: Direct API Integration (Python Example)
To get started with multimodal inputs, simply use the code snippet below:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Key Features:
- Unified endpoint:
/v3/openaisupports OpenAI’s Chat Completions API format. - Flexible controls: Adjust temperature, top-p, penalties, and more for tailored results.
- Streaming & batching: Choose your preferred response mode.
Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Build advanced multimodal agent systems by integrating Novita AI with the OpenAI Agents SDK:
Plug-and-play: Use GLM-4.1V-9B-Thinking in any OpenAI Agents workflow for vision-language tasks.
Supports handoffs, routing, and tool use: Design agents that can analyze visual content, delegate tasks, or run functions, all powered by GLM-4.1V-9B-Thinking’s reasoning capabilities.
Python integration: Simply point the SDK to Novita’s endpoint (https://api.novita.ai/v3/openai) and use your API key for seamless multimodal agent workflows.
Connect GLM-4.1V-9B-Thinking API on Third-Party Platforms
Hugging Face: Use GLM-4.1V-9B-Thinking in Spaces, pipelines, or with the Transformers library via Novita AI endpoints for multimodal applications.
Agent & Orchestration Frameworks: Easily connect Novita AI with partner platforms like Continue, AnythingLLM, LangChain, Dify and Langflow through official connectors and step-by-step integration guides.
OpenAI-Compatible API: Enjoy hassle-free migration and integration with tools such as Cline and Cursor, designed for the OpenAI API standard.
Conclusion
GLM-4.1V-9B-Thinking represents a transformative milestone in multimodal AI, demonstrating that advanced reasoning capabilities can be achieved efficiently in a 9-billion parameter model. Through its innovative RLCS training framework and unique thinking paradigm, it matches or surpasses much larger 72B parameter systems across diverse benchmarks.
Try the GLM-4.1V-9B-Thinking demo on Novita AI now and claim your free credits!
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



