

GLM-4.1V-9B-Thinking は、90億パラメータの革新的な視覚言語モデルであり、マルチモーダルAIに初めて推論特化型アプローチを導入しました。THUDM によって開発されたこのモデルは、独自の「思考パラダイム」を実装することで、透明性のある段階的な推論プロセスを可能にし、最先端のパフォーマンスを実現しています。
コンパクトなサイズにもかかわらず、GLM-4.1V-9B-Thinking は18のベンチマークタスクにおいて、はるかに大規模な720億パラメータモデルに匹敵するか、それを上回る性能を示し、マルチモーダル推論における卓越した効率性と能力を示しています。
期間限定で、新規ユーザーは $10分の無料クレジット を請求して、GLM-4.1V-9B-Thinking を探索・構築することができます。
Novita AI 上の GLM-4.1V-9B-Thinking API の現在の価格は以下のとおりです: 入力トークン $0.035 / M、出力トークン $0.138 / M
GLM-4.1V-9B-Thinking とは何か?
視覚言語モデル(VLM)は、インテリジェントシステムの基盤コンポーネントとなっています。現実世界のAIタスクがますます複雑になるにつれて、VLMは基本的なマルチモーダル知覚を超え、高度な推論能力を発揮できるように進化する必要があります。この進化は、精度、包括性、そして全体的なインテリジェンスの向上に焦点を当てており、複雑な問題解決、長文脈理解、マルチモーダルエージェントなどのアプリケーションへの道を切り開きます。
GLM-4.1V-9B-Thinking は、汎用マルチモーダル理解と推論を推進することで、これらの要求に応えるために設計された次世代の視覚言語モデル(VLM)です。GLM-4-9B-0414 基盤モデルをベースに構築されており、画期的な「思考パラダイム」を導入している点が特徴です。
この新しいパラダイムにより、モデルは最終出力を生成する前に、明示的かつ段階的な推論を行うことができます。直接応答を生成する従来のモデルとは異なり、GLM-4.1V-9B-Thinking は推論プロセスを外部化し、透明性、解釈可能性、検証可能性を実現し、より信頼性が高く有能なAIシステムへの道を切り開きます。
主な機能と革新性
柔軟な入力処理: 任意の画像解像度とアスペクト比をサポートします。2D-RoPE を統合しており、極端なアスペクト比(200:1超過)や高解像度(4K超)の画像を効果的に処理できます。
位置埋め込みの適応: 事前学習済みViTの基盤能力を維持するため、モデルは元の学習可能な絶対位置埋め込みを保持します。学習中、これらの埋め込みはバイキュービック補間を介して可変解像度入力に動的に適応されます。
時間的理解: 動画コンテンツの場合、各フレームトークンの後に時間インデックストークンが挿入されます。時間インデックスは、各フレームのタイムスタンプを文字列としてエンコードすることで実装されています。この設計により、モデルは現実世界のタイムスタンプとフレーム間の時間的距離を明示的に認識できます。
拡張コンテキストサポート: 64Kのコンテキスト長をサポートし、中国語と英語のバイリンガル機能を提供するため、長文書理解や異文化アプリケーションに強力です。
従来モデルからの主な改良点:
- シリーズ初の推論特化モデルであり、様々なサブドメインで世界をリードするパフォーマンスを達成
- 64Kコンテキスト長をサポート
- 任意のアスペクト比と最大4K画像解像度を処理可能
- 中国語と英語のバイリンガル使用をサポートするオープンソース版を提供
革新的なトレーニングフレームワーク
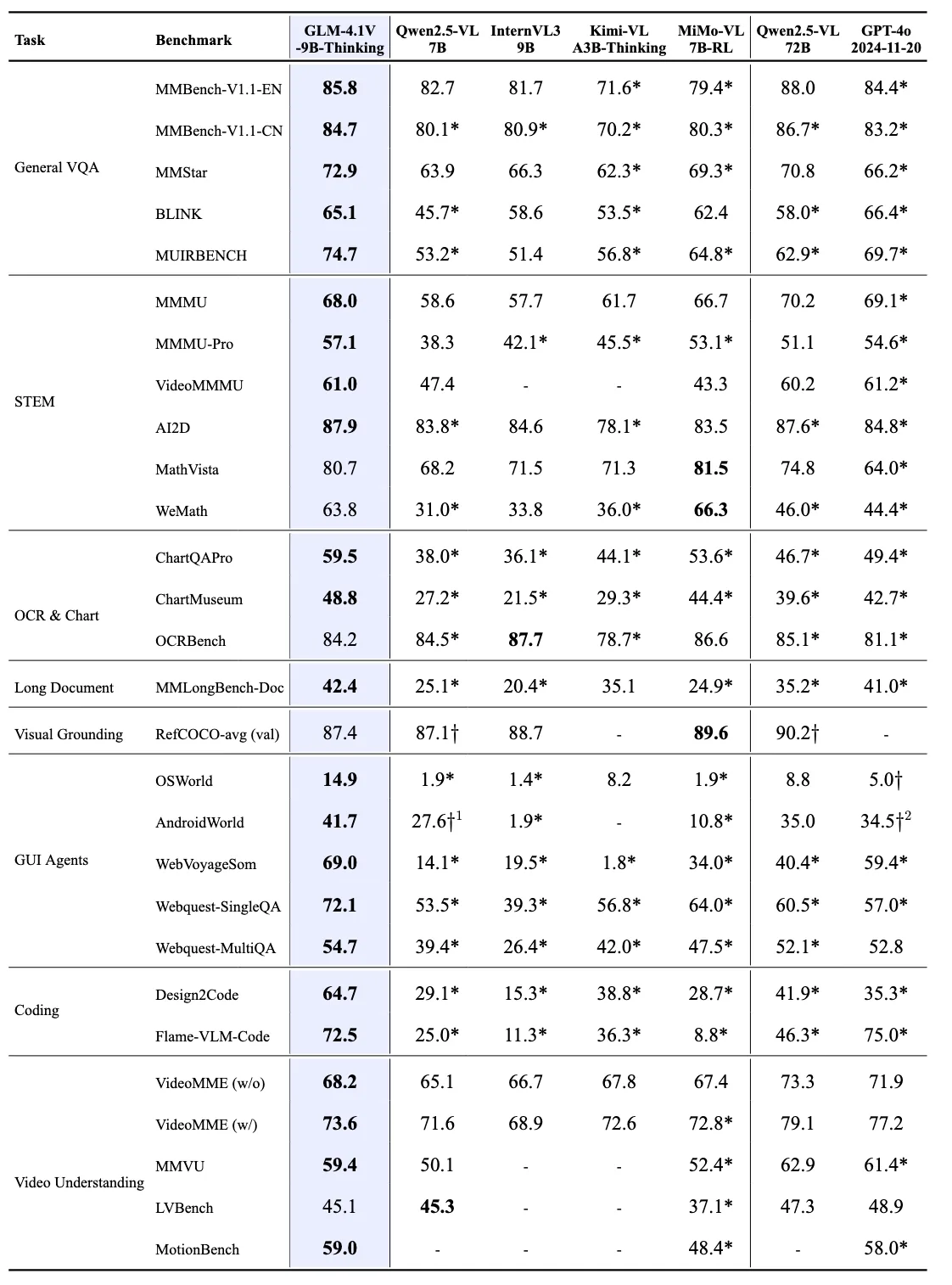
GLM-4.1V-9B-Thinking は、カリキュラムサンプリングを用いた強化学習(RLCS)を特徴とする革新的なトレーニングアプローチを採用しており、複数のドメインにわたって推論能力を体系的に強化します。
ステージ1: 事前学習の基盤
モデルは大規模な事前学習を受け、正確な事実知識を含む大規模な画像テキストペア、画像とテキストがインターリーブされた自己キュレーションの学術コーパス、注釈付きドキュメントや図など、強力な基盤能力を備えます。
ステージ2: 教師ありファインチューニング
このステージは強化学習へのブリッジとして機能し、ベースVLMを長い思考連鎖(CoT)推論が可能なものに変換します。各応答は thinking と <answer> セクションを含む標準化された構造に従います。
ステージ3: 強化学習の革新
チームはカリキュラムサンプリングを用いた強化学習(RLCS)を導入し、大規模でクロスドメインな推論能力を推進します。RLCS はカリキュラム学習と難易度認識サンプリングを組み合わせ、トレーニング効率を向上させます。
出典: THUDM
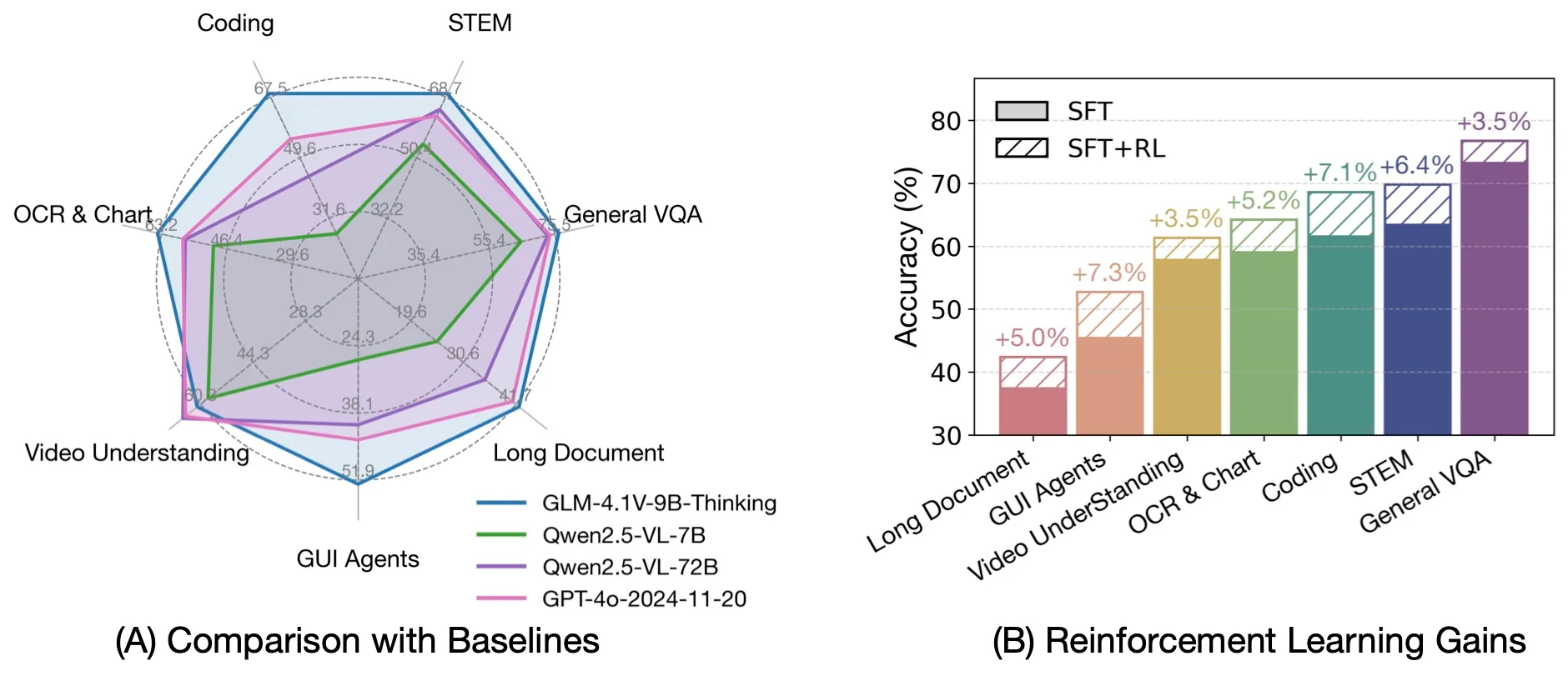
他の高度なVLMとの比較
出典: THUDM
卓越した効率性: 比較的コンパクトなサイズにもかかわらず、GLM-4.1V-9B-Thinking は、はるかに大規模な Qwen2.5-VL-72B モデルを28のベンチマーク中18で上回っています。これには特に困難なタスクである MMStar (72.9 vs 70.8)、MUIRBENCH (74.7 vs 62.9)、MMMU-Pro (57.1 vs 51.1)、ChartMuseum (48.8 vs 39.6) が含まれており、モデルの優れた効率性と能力を示しています。
プロプライエタリモデルに対する競争力: プロプライエタリな GPT-4o と比較して、GLM-4.1V-9B-Thinking は MMStar (72.9 vs 66.2)、MUIRBENCH (74.7 vs 69.7)、AI2D (87.9 vs 84.8)、MMMU-Pro (57.1 vs 54.6)、MathVista (80.7 vs 64.0)、MotionBench (59.0 vs 58.0) を含むほとんどのタスクで優れた結果を達成しています。このパフォーマンスは、GPT-4o の大幅に大規模なスケールとクローズドソースの利点にもかかわらず達成されています。
専門タスクでの優位性: モデルはGUIエージェントタスクで卓越した性能を示し、WebQuest-SingleQA で72.1(Qwen2.5-VL-72B は60.5、GPT-4o は57.0)、WebVoyageSom で69.0(Qwen2.5-VL-72B は40.4、GPT-4o は59.4)を達成しています。コーディングタスクでは、Flame-VLM-Code で72.5を達成し、72Bモデル(46.3)を大幅に上回り、GPT-4o(75.0)に匹敵する性能を維持しています。
最適なリソース効率: これらの発見は、GLM-4.1V-9B-Thinking がパフォーマンスと効率の間で優れたトレードオフを提供することを強調しています。これにより、計算リソースが制約されている現実世界のデプロイメントにおいて魅力的な選択肢となり、リソース制約下で実用的かつ強力なソリューションを提供しながら、はるかに大規模なシステムに対して競争力のあるパフォーマンスを維持します。
ランタイム要件
モデルの効率的なアーキテクチャにより、公式仕様に基づいて様々なハードウェア構成での柔軟なデプロイメントオプションが可能です。
推論
デバイス(単一GPU) |
フレームワーク | 最小メモリ | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 トークン / 秒 | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 トークン / 秒 | BF16 |
ファインチューニング
以下の結果は、LLaMA-Factory ツールキットを使用した画像ファインチューニングに基づいています。
| デバイス(クラスター) | 戦略 | 最小メモリ / GPU数 | バッチサイズ(GPUあたり) | フリーズ |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | VIT固定 |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPU | 1 | VIT固定 |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPU | 1 | VIT固定 |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPU | 1 | 固定なし |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPU | 1 | 固定なし |
注: Zero2でのファインチューニングはロスがゼロになる可能性があります。安定したトレーニングにはZero3を推奨します。
Novita AIでGLM-4.1V-9B-Thinkingにアクセスする方法
Novita AI での GLM-4.1V-9B-Thinking の利用開始は、迅速、簡単、そしてリスクフリーです。紹介プログラムにより、$10分の無料クレジットを受け取ることができます。これで GLM-4.1V-9B-Thinking のマルチモーダル推論力を十分に探求し、プロトタイプを構築し、初期費用なしで最初のユースケースを立ち上げることさえ可能です。
プレイグラウンドを使用する(コーディング不要)
インスタントアクセス: サインアップして無料クレジットを請求し、すぐに GLM-4.1V-9B-Thinking や他のトップマルチモーダルモデルの実験を開始できます。
インタラクティブUI: 画像理解、チャート分析、透明性のある推論ワークフローをリアルタイムでテストできます。直感的なインターフェースを通じて、モデルのユニークな思考パラダイムを体験できます。
モデル比較: GLM-4.1V-9B-Thinking、他の視覚言語モデル、テキスト専用モデルを簡単に切り替えて、マルチモーダルニーズに最適なものを見つけることができます。
API経由で統合する(開発者向け)
Novita AI の統合REST APIを使用して、GLM-4.1V-9B-Thinking をアプリケーション、ワークフロー、チャットボットにシームレスに接続できます。モデルウェイトやインフラストラクチャを管理する必要はありません。
オプション1: 直接API統合(Python例)
マルチモーダル入力を始めるには、以下のコードスニペットを使用するだけです。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # または False
max_tokens = 4000
system_content = ""役立つアシスタントになってください""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "こんにちは!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主な機能:
- 統合エンドポイント:
/v3/openaiは OpenAI の Chat Completions API 形式をサポートしています。 - 柔軟な制御: temperature、top-p、ペナルティなどを調整して、結果をカスタマイズできます。
- ストリーミングとバッチ処理: 好みの応答モードを選択できます。
オプション2: OpenAI Agents SDK を使用したマルチエージェントワークフロー
Novita AI を OpenAI Agents SDK と統合することで、高度なマルチモーダルエージェントシステムを構築できます。
プラグアンドプレイ: 視覚言語タスクのために、任意の OpenAI Agents ワークフローで GLM-4.1V-9B-Thinking を使用できます。
ハンドオフ、ルーティング、ツール使用をサポート: 視覚コンテンツを分析したり、タスクを委任したり、関数を実行したりできるエージェントを設計できます。これらはすべて GLM-4.1V-9B-Thinking の推論能力によって実現されます。
Python統合: SDK を Novita のエンドポイント(https://api.novita.ai/v3/openai)に向け、APIキーを使用するだけで、シームレスなマルチモーダルエージェントワークフローが実現します。
サードパーティプラットフォームでGLM-4.1V-9B-Thinking APIに接続する
Hugging Face: Novita AI エンドポイントを介して、Spaces、パイプライン、または Transformers ライブラリで GLM-4.1V-9B-Thinking をマルチモーダルアプリケーションに使用できます。
エージェントおよびオーケストレーションフレームワーク: 公式コネクタとステップバイステップの統合ガイドを通じて、Novita AI を Continue、AnythingLLM、LangChain、Dify、Langflow などのパートナープラットフォームに簡単に接続できます。
OpenAI互換API: OpenAI API標準向けに設計された Cline や Cursor などのツールとの、手間のかからない移行と統合をお楽しみいただけます。
結論
GLM-4.1V-9B-Thinking は、マルチモーダルAIにおける変革的なマイルストーンであり、高度な推論能力が90億パラメータモデルで効率的に達成可能であることを実証しています。革新的なRLCSトレーニングフレームワークと独自の思考パラダイムを通じて、多様なベンチマークにおいて、はるかに大規模な720億パラメータシステムに匹敵するか、それを上回る性能を発揮します。
今すぐ Novita AI で GLM-4.1V-9B-Thinking デモ を試して、無料クレジットを請求 しましょう!
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、同時に手頃な価格で信頼性の高いGPUクラウドを構築およびスケーリングのために提供します。



