

GLM-4.1V-9B-Thinking 是一款突破性的 90 億參數視覺語言模型,為多模態 AI 引入了首個以推理為核心的方法。該模型由 THUDM 開發,透過實作獨特的「思考範式」實現了最先進的效能,支援透明、逐步的推理過程。
儘管體積小巧,GLM-4.1V-9B-Thinking 在 18 個基準測試任務上達到或超越規模更大的 720 億參數模型,展現出在多模態推理方面的卓越效率與能力。
限時優惠:新用戶可領取 $10 免費額度 來探索並使用 GLM-4.1V-9B-Thinking 進行開發。
以下是目前 Novita AI 上 GLM-4.1V-9B-Thinking API 的定價:$0.035 / 百萬輸入 Token,$0.138 / 百萬輸出 Token
什麼是 GLM-4.1V-9B-Thinking?
視覺語言模型(VLM)已成為智慧系統的基礎元件。隨著真實世界的 AI 任務日益複雜,VLM 必須超越基本的多模態感知,展現進階推理能力。這一演進聚焦於提升準確性、全面性與整體智慧——為複雜問題解決、長上下文理解以及多模態代理等應用鋪平道路。
GLM-4.1V-9B-Thinking 是為滿足這些需求而設計的次世代視覺語言模型(VLM),其目標是推進通用多模態理解與推理。該模型基於 GLM-4-9B-0414 基礎模型構建,引入了獨特的「思考範式」,使其與眾不同。
此新範式允許模型在產出最終結果之前,進行明確且逐步的推理。與直接回應的傳統模型不同,GLM-4.1V-9B-Thinking 將推理過程外部化,使其透明、可解釋且可驗證——為更值得信賴、能力更強的 AI 系統鋪平道路。
主要功能與創新
靈活的輸入處理:模型支援任意圖像解析度與寬高比。整合了 2D-RoPE,使其能有效處理極端寬高比(超過 200:1)或高解析度(超過 4K)的圖像。
位置嵌入適配:為保留預訓練 ViT 的基礎能力,模型保留了原始的可學習絕對位置嵌入。在訓練過程中,透過 bicubic 插值將這些嵌入動態適配至可變解析度的輸入。
時間理解:對於影片內容,模型在每個畫面 token 後插入時間索引 token,時間索引透過將每個畫面的時間戳編碼為字串來實現。此設計明確告知模型真實世界的時間戳以及畫面間的時間距離。
擴展上下文支援:模型支援 64K 上下文長度,並提供中英文雙語能力,使其在長文檔理解與跨文化應用中表現出色。
相較於前代模型的關鍵改進:
- 該系列首個以推理為核心的模型,在多個子領域達到世界領先效能
- 支援 64K 上下文長度
- 處理任意寬高比與高達 4K 的圖像解析度
- 提供開源版本,支援中英文雙語使用
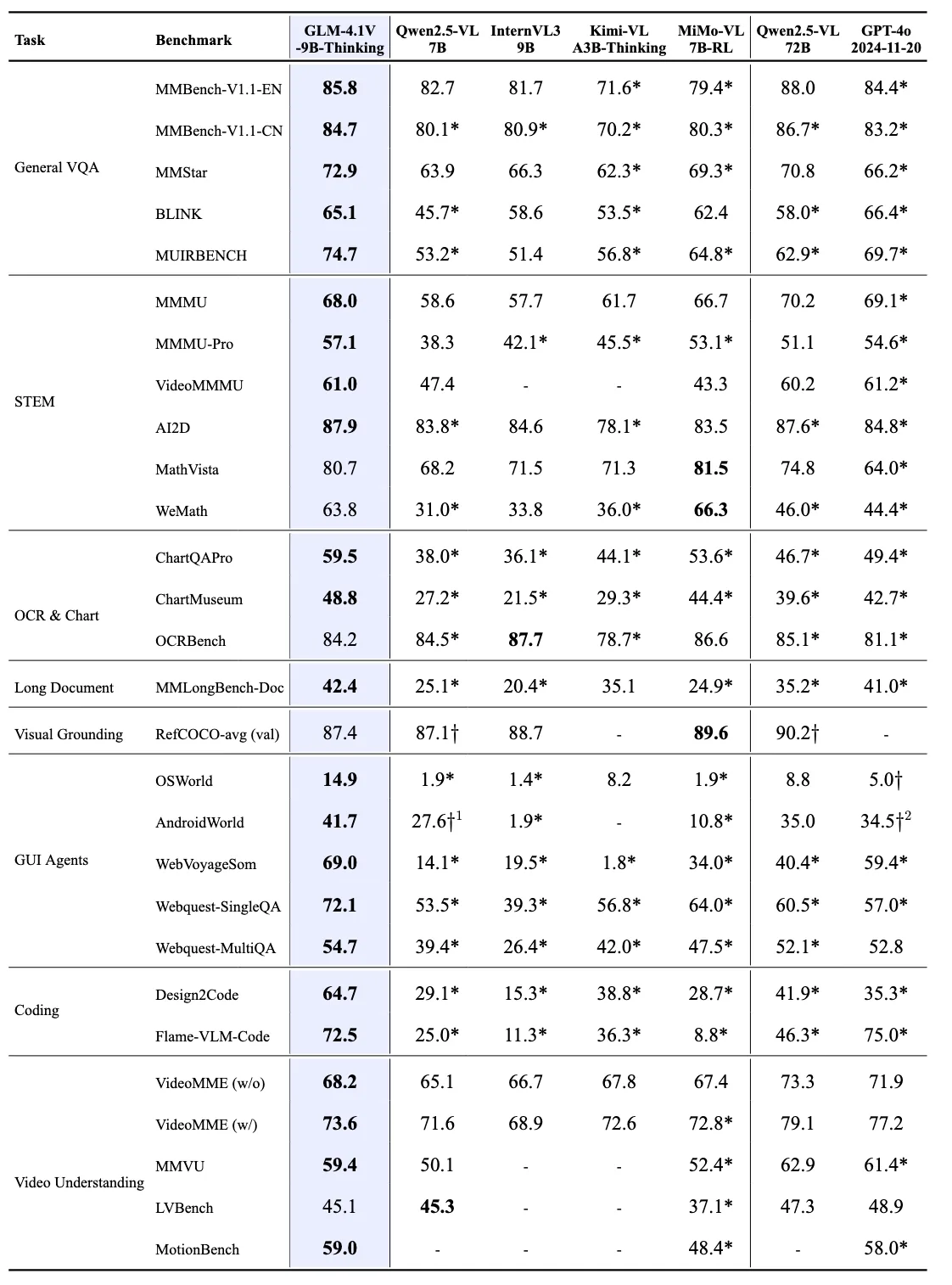
革命性的訓練框架
GLM-4.1V-9B-Thinking 採用創新的訓練方法,包含課程取樣強化學習(RLCS),系統性地提升跨領域推理能力。
階段一:預訓練基礎
模型進行大規模預訓練,以獲得強大的基礎能力,包含大規模圖像文本對(具有準確事實知識)、自行策劃的學術語料庫(交織圖像與文本),以及帶註解的文檔與圖表。
階段二:監督式微調
此階段作為強化學習的橋樑,將基礎 VLM 轉變為能夠進行長鏈思維(CoT)推理的模型。每個回應遵循標準化結構,包含 思考 與 <答案> 部分。
階段三:強化學習創新
團隊引入課程取樣強化學習(RLCS),以驅動大規模、跨領域的推理能力。RLCS 結合課程學習與難度感知取樣,提升訓練效率。
資料來源: THUDM
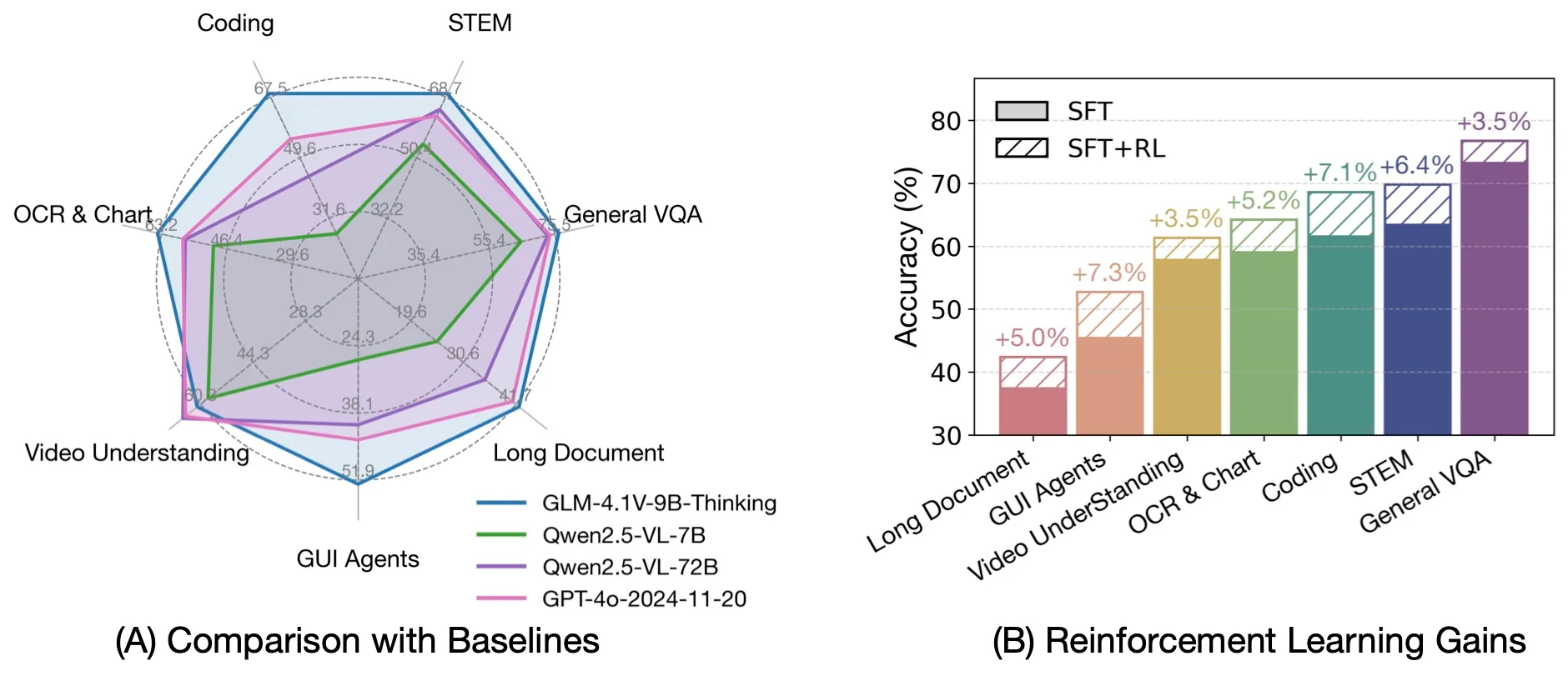
與其他進階 VLM 的比較
資料來源: THUDM
卓越效率:儘管尺寸相對緊湊,GLM-4.1V-9B-Thinking 在 28 個基準測試中的 18 項上優於規模更大的 Qwen2.5-VL-72B 模型。這些測試包含特別具挑戰性的任務,如 MMStar(72.9 vs 70.8)、MUIRBENCH(74.7 vs 62.9)、MMMU-Pro(57.1 vs 51.1)以及 ChartMuseum(48.8 vs 39.6),展現了該模型卓越的效率與能力。
與專有模型的競爭力:與專有模型 GPT-4o 相比,GLM-4.1V-9B-Thinking 在多數任務上取得了更優異的結果,包括 MMStar(72.9 vs 66.2)、MUIRBENCH(74.7 vs 69.7)、AI2D(87.9 vs 84.8)、MMMU-Pro(57.1 vs 54.6)、MathVista(80.7 vs 64.0)以及 MotionBench(59.0 vs 58.0)。儘管 GPT-4o 的規模明顯更大且為封閉原始碼,GLM-4.1V-9B-Thinking 仍達成了此效能。
在專業任務中的主導地位:該模型在 GUI 代理任務中表現優異,在 WebQuest-SingleQA 上達到 72.1(Qwen2.5-VL-72B 為 60.5,GPT-4o 為 57.0),在 WebVoyageSom 上達到 69.0(Qwen2.5-VL-72B 為 40.4,GPT-4o 為 59.4)。在程式碼任務中,於 Flame-VLM-Code 達到 72.5,大幅超越 72B 模型(46.3),同時與 GPT-4o(75.0)保持競爭力。
最佳資源效率:這些發現強調 GLM-4.1V-9B-Thinking 在效能與效率之間提供了絕佳的平衡。這使其成為在計算資源受限的真實部署環境中極具吸引力的選擇,在資源受限的情況下提供實用且強大的解決方案,同時保持與規模大得多的系統相競爭的效能。
執行環境需求
根據官方規格,該模型的效率架構支援在多種硬體配置下進行靈活的部署。
推理
裝置(單 GPU) |
框架 | 最小記憶體 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / 秒 | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / 秒 | BF16 |
微調
以下結果基於使用 LLaMA-Factory 工具進行的圖像微調。
| 裝置(叢集) | 策略 | 最小記憶體 / GPU 數量 | 批次大小(每 GPU) | 凍結 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | 凍結 VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPU | 1 | 凍結 VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPU | 1 | 凍結 VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPU | 1 | 不凍結 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPU | 1 | 不凍結 |
注意:使用 Zero2 進行微調可能導致損失歸零;建議使用 Zero3 以確保訓練穩定。
如何在 Novita AI 上使用 GLM-4.1V-9B-Thinking
開始使用 GLM-4.1V-9B-Thinking 在 Novita AI 上非常快速、簡單且無風險。透過推薦計畫,您將獲得 $10 免費額度——足以充分探索 GLM-4.1V-9B-Thinking 的多模態推理能力、建立原型,甚至推出您的第一個使用案例,無需任何前期成本。
使用 Playground(無需編碼)
即時存取:註冊、領取免費額度,並在幾秒內開始體驗 GLM-4.1V-9B-Thinking 及其他頂尖多模態模型。
互動式界面:即時測試圖像理解、圖表分析與透明推理工作流程。透過直覺的界面體驗模型獨特的思考範式。
模型比較:輕鬆在 GLM-4.1V-9B-Thinking、其他視覺語言模型以及純文字模型之間切換,以找到最符合您多模態需求的選擇。
透過 API 整合(開發者適用)
透過 Novita AI 的統一 REST API 無縫將 GLM-4.1V-9B-Thinking 連接到您的應用程式、工作流程或聊天機器人——無需管理模型權重或基礎架構。
選項一:直接 API 整合(Python 範例)
要開始使用多模態輸入,只需使用以下程式碼片段:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # 或 False
max_tokens = 4000
system_content = "你是一個有用的助手"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "你好!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主要功能:
- 統一端點:
/v3/openai支援 OpenAI 的 Chat Completions API 格式。 - 彈性控制: 調整 temperature、top-p、懲罰等參數以獲得客製化結果。
- 串流與批次: 選擇您偏好的回應模式。
選項二:使用 OpenAI Agents SDK 進行多代理工作流程
透過將 Novita AI 與 OpenAI Agents SDK 整合,建立進階的多模態代理系統:
即插即用:在任何 OpenAI Agents 工作流程中使用 GLM-4.1V-9B-Thinking 進行視覺語言任務。
支援轉接、路由與工具使用:設計能夠分析視覺內容、委派任務或執行功能的代理,全部由 GLM-4.1V-9B-Thinking 的推理能力驅動。
Python 整合:只需將 SDK 指向 Novita 端點(https://api.novita.ai/v3/openai)並使用您的 API 金鑰,即可實現無縫的多模態代理工作流程。
在第三方平台上連接 GLM-4.1V-9B-Thinking API
Hugging Face:透過 Novita AI 端點,在 Spaces、pipeline 或使用 Transformers 庫中運用 GLM-4.1V-9B-Thinking 進行多模態應用。
代理與編排框架:透過官方連接器與逐步整合指南,輕鬆將 Novita AI 連接到 Continue、AnythingLLM、LangChain、Dify 及 Langflow 等合作平台。
OpenAI 相容 API:享受與 Cline 和 Cursor 等專為 OpenAI API 標準設計的工具進行無痛遷移與整合。
結論
GLM-4.1V-9B-Thinking 代表了多模態 AI 中的一個變革性里程碑,證明了在 90 億參數模型中可以有效實現先進推理能力。透過其創新的 RLCS 訓練框架與獨特的思考範式,它在多樣化的基準測試中達到或超越了規模更大的 720 億參數系統。
立即在 Novita AI 上試用 GLM-4.1V-9B-Thinking 展示,並 領取您的免費額度!
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的便利方式,同時也提供經濟實惠且可靠的 GPU 雲端來建置與擴展應用。



