

GLM-4.1V-9B-Thinking ist ein bahnbrechendes Vision-Language-Modell mit 9 Milliarden Parametern, das den ersten reasoning-orientierten Ansatz für multimodale KI einführt. Das von THUDM entwickelte Modell erzielt eine Spitzenleistung, indem es ein einzigartiges “Denkparadigma” implementiert, das transparente, schrittweise Denkprozesse ermöglicht.
Trotz seiner kompakten Größe erreicht GLM-4.1V-9B-Thinking in 18 Benchmark-Aufgaben die Leistung von – oder übertrifft – wesentlich größere Modelle mit 72B Parametern. Dies demonstriert eine außergewöhnliche Effizienz und Leistungsfähigkeit im multimodalen Reasoning.
Für eine begrenzte Zeit können neue Nutzer $10 in kostenlosen Credits erhalten, um GLM-4.1V-9B-Thinking zu erkunden und damit zu bauen.
Hier ist die aktuelle Preisgestaltung der GLM-4.1V-9B-Thinking API auf Novita AI: $0,035 / M Input-Token, $0,138 / M Output-Token
Was ist GLM-4.1V-9B-Thinking?
Vision-Language-Modelle (VLMs) sind zu grundlegenden Komponenten intelligenter Systeme geworden. Da reale KI-Aufgaben immer komplexer werden, müssen sich VLMs über die grundlegende multimodale Wahrnehmung hinaus weiterentwickeln, um fortgeschrittene Reasoning-Fähigkeiten zu demonstrieren. Diese Entwicklung konzentriert sich auf die Verbesserung von Genauigkeit, Vollständigkeit und allgemeiner Intelligenz – und ebnet den Weg für Anwendungen wie komplexe Problemlösung, Langzeitkontextverständnis und multimodale Agenten.
GLM-4.1V-9B-Thinking ist ein Vision-Language-Modell (VLM) der nächsten Generation, das diese Anforderungen erfüllen soll, indem es das allgemeine multimodale Verständnis und Reasoning vorantreibt. Aufbauend auf dem GLM-4-9B-0414-Basismodell führt es ein bahnbrechendes “Denkparadigma” ein, das es von anderen abhebt.
Dieses neue Paradigma ermöglicht es dem Modell, explizite, schrittweise Denkschritte durchzuführen, bevor es endgültige Ausgaben liefert. Im Gegensatz zu traditionellen Modellen, die direkte Antworten produzieren, externalisiert GLM-4.1V-9B-Thinking seinen Denkprozess, was ihn transparent, interpretierbar und überprüfbar macht – und den Weg für vertrauenswürdigere und leistungsfähigere KI-Systeme ebnet.
Hauptmerkmale und Innovationen
Flexible Eingabehandhabung: Das Modell unterstützt beliebige Bildauflösungen und Seitenverhältnisse. Es integriert 2D-RoPE, was eine effektive Verarbeitung von Bildern mit extremen Seitenverhältnissen (über 200:1) oder hohen Auflösungen (über 4K) ermöglicht.
Anpassung der Positions-Embeddings: Um die grundlegenden Fähigkeiten des vortrainierten ViT zu bewahren, behält das Modell die ursprünglichen lernbaren absoluten Positions-Embeddings bei. Während des Trainings werden diese Embeddings durch bikubische Interpolation dynamisch an Eingaben mit variabler Auflösung angepasst.
Zeitliches Verständnis: Für Videoinhalte fügt das Modell nach jedem Frame-Token Zeitindex-Token ein, wobei der Zeitindex durch Kodierung des Zeitstempels jedes Frames als Zeichenfolge implementiert wird. Dieses Design informiert das Modell explizit über reale Zeitstempel und zeitliche Abstände zwischen den Frames.
Erweiterte Kontextunterstützung: Das Modell unterstützt eine Kontextlänge von 64K und bietet zweisprachige Fähigkeiten in Chinesisch und Englisch, was es leistungsstark für das Verständnis langer Dokumente und interkulturelle Anwendungen macht.
Wichtige Verbesserungen gegenüber früheren Modellen:
- Erstes reasoning-fokussiertes Modell der Serie, das weltweit führende Leistungen in verschiedenen Teilbereichen erzielt
- Unterstützt 64K Kontextlänge
- Verarbeitet beliebige Seitenverhältnisse und Bildauflösungen bis zu 4K
- Bietet eine Open-Source-Version, die sowohl Chinesisch als auch Englisch zweisprachig unterstützt
Revolutionäres Training Framework
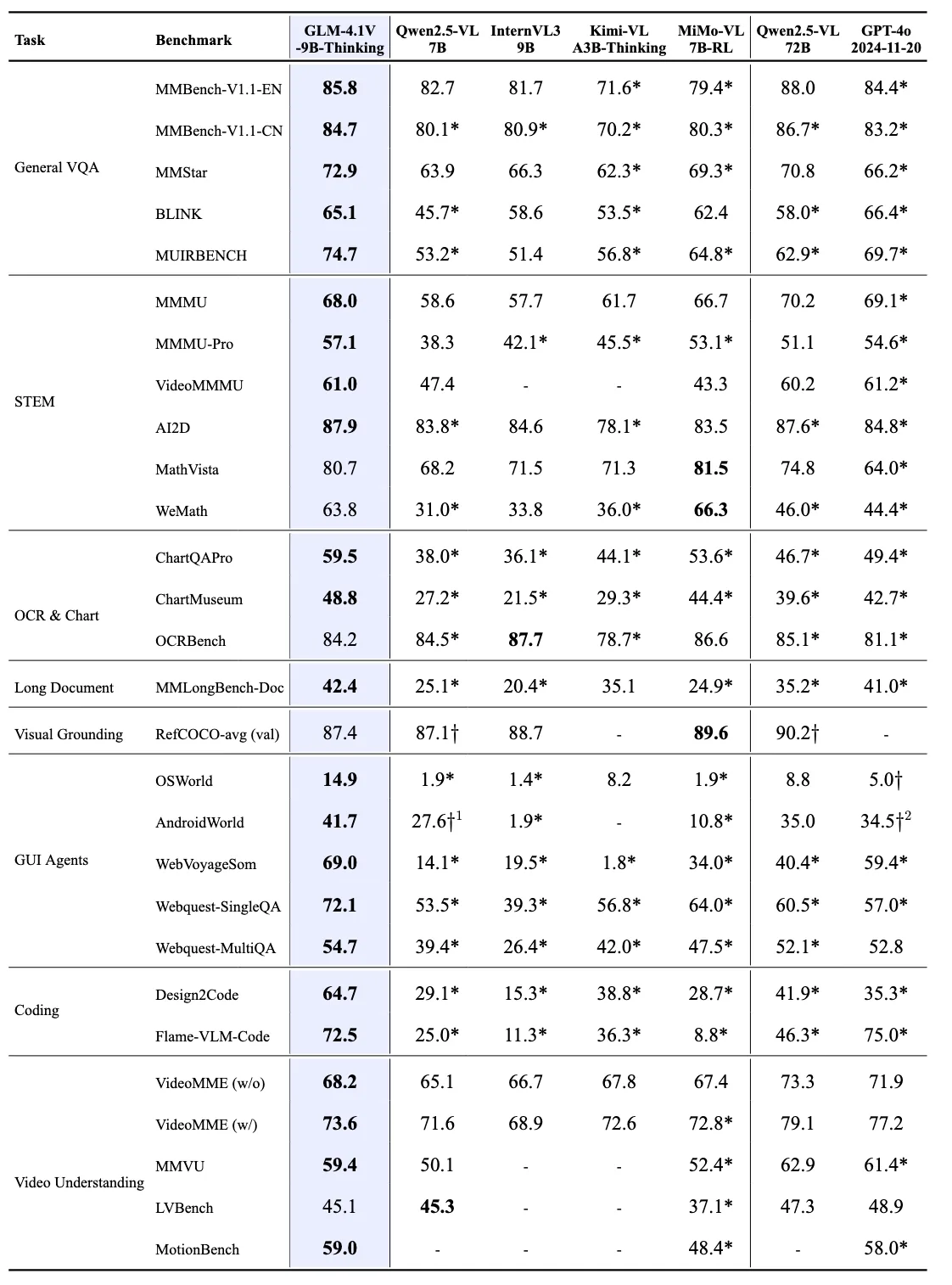
GLM-4.1V-9B-Thinking verwendet einen innovativen Trainingsansatz mit Reinforcement Learning with Curriculum Sampling (RLCS), der die Reasoning-Fähigkeiten systematisch über mehrere Domänen hinweg verbessert.
Stufe 1: Pre-Training-Grundlage
Das Modell durchläuft ein groß angelegtes Pre-Training, um es mit starken grundlegenden Fähigkeiten auszustatten, darunter massive Bild-Text-Paare mit genauen Faktenwissen, ein selbst kuratiertes akademisches Korpus mit verschachtelten Bildern und Texten sowie annotierte Dokumente und Diagramme.
Stufe 2: Überwachtes Feintuning
Diese Stufe fungiert als Brücke zum Reinforcement Learning und verwandelt das Basis-VLM in eines, das lange Chain-of-Thought (CoT) Inferenz durchführen kann. Jede Antwort folgt einer standardisierten Struktur mit thinking- und <answer>-Abschnitten.
Stufe 3: Reinforcement Learning Innovation
Das Team führt Reinforcement Learning with Curriculum Sampling (RLCS) ein, um groß angelegte, domänenübergreifende Reasoning-Fähigkeiten voranzutreiben. RLCS kombiniert Curriculum Learning mit schwierigkeitsbewusstem Sampling, um die Trainingseffizienz zu verbessern.
Quelle: THUDM
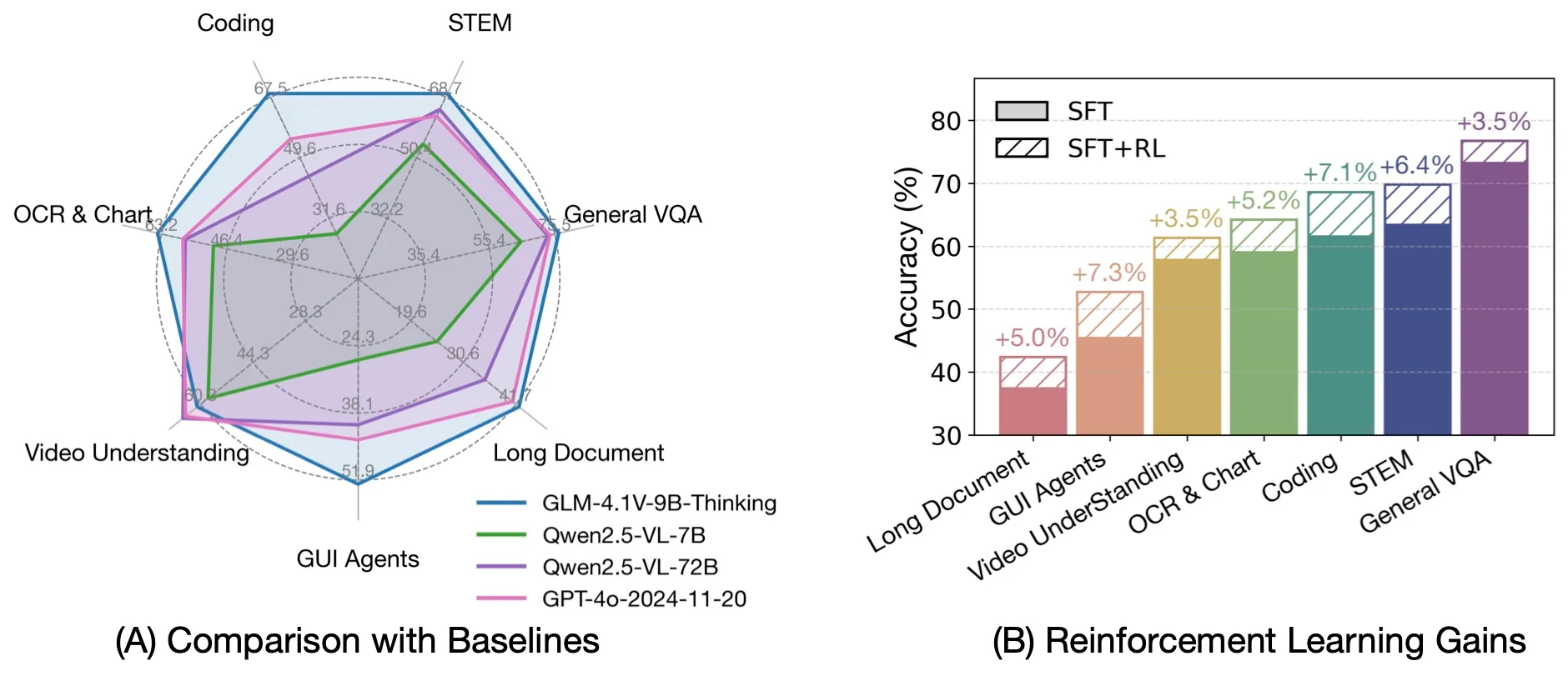
Vergleich mit anderen fortschrittlichen VLMs
Quelle: THUDM
Außergewöhnliche Effizienz: Trotz seiner relativ kompakten Größe übertrifft GLM-4.1V-9B-Thinking das wesentlich größere Modell Qwen2.5-VL-72B in 18 von 28 Benchmarks. Dies umfasst besonders anspruchsvolle Aufgaben wie MMStar (72,9 vs 70,8), MUIRBENCH (74,7 vs 62,9), MMMU-Pro (57,1 vs 51,1) und ChartMuseum (48,8 vs 39,6), was die überlegene Effizienz und Leistungsfähigkeit des Modells verdeutlicht.
Wettbewerbsfähig gegenüber proprietären Modellen: Im Vergleich mit dem proprietären GPT-4o erzielt GLM-4.1V-9B-Thinking bei den meisten Aufgaben überlegene Ergebnisse, darunter MMStar (72,9 vs 66,2), MUIRBENCH (74,7 vs 69,7), AI2D (87,9 vs 84,8), MMMU-Pro (57,1 vs 54,6), MathVista (80,7 vs 64,0) und MotionBench (59,0 vs 58,0). Diese Leistung wird trotz des deutlich größeren Maßstabs und des Closed-Source-Vorteils von GPT-4o erzielt.
Dominanz bei spezialisierten Aufgaben: Das Modell zeigt außergewöhnliche Leistung bei GUI-Agenten-Aufgaben mit 72,1 in WebQuest-SingleQA (vs 60,5 für Qwen2.5-VL-72B und 57,0 für GPT-4o) und 69,0 in WebVoyageSom (vs 40,4 für Qwen2.5-VL-72B und 59,4 für GPT-4o). Bei Codierungsaufgaben erreicht es 72,5 in Flame-VLM-Code, was das 72B-Modell (46,3) deutlich übertrifft, während es mit GPT-4o (75,0) wettbewerbsfähig bleibt.
Optimale Ressourceneffizienz: Diese Ergebnisse unterstreichen, dass GLM-4.1V-9B-Thinking einen hervorragenden Kompromiss zwischen Leistung und Effizienz bietet. Dies macht es zu einer überzeugenden Wahl für den realen Einsatz, bei dem Rechenressourcen begrenzt sind, und bietet eine praktische und leistungsstarke Lösung unter Ressourcenbeschränkungen, während es gleichzeitig wettbewerbsfähig gegenüber viel größeren Systemen bleibt.
Jetzt GLM-4.1V-9B-Thinking Demo erkunden
Laufzeitanforderungen
Die effiziente Architektur des Modells ermöglicht flexible Bereitstellungsoptionen auf verschiedenen Hardwarekonfigurationen basierend auf den offiziellen Spezifikationen.
Inferenz
Gerät (Single GPU) |
Framework | Min. Speicher | Geschwindigkeit | Genauigkeit |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
Feintuning
Die folgenden Ergebnisse basieren auf Bild-Feintuning mit dem LLaMA-Factory-Toolkit.
| Gerät (Cluster) | Strategie | Min. Speicher / # GPUs | Batch-Größe (pro GPU) | Einfrieren |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1 GPU | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4 GPUs | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4 GPUs | 1 | Freeze VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4 GPUs | 1 | Kein Einfrieren |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4 GPUs | 1 | Kein Einfrieren |
Hinweis: Feintuning mit Zero2 kann zu Nullverlust führen; Zero3 wird für stabiles Training empfohlen.
Wie Sie auf GLM-4.1V-9B-Thinking auf Novita AI zugreifen
Der Einstieg in GLM-4.1V-9B-Thinking ist auf Novita AI schnell, einfach und risikofrei. Dank des Empfehlungsprogramms erhalten Sie $10 in kostenlosen Credits – genug, um die multimodale Reasoning-Kraft von GLM-4.1V-9B-Thinking vollständig zu erkunden, Prototypen zu bauen und sogar Ihren ersten Anwendungsfall ohne Vorabkosten zu starten.
Nutzen Sie das Playground (Keine Codierung erforderlich)
Sofortiger Zugang: Melden Sie sich an, beanspruchen Sie Ihre kostenlosen Credits und beginnen Sie sofort mit dem Experimentieren mit GLM-4.1V-9B-Thinking und anderen führenden multimodalen Modellen.
Interaktive Benutzeroberfläche: Testen Sie Bildverständnis, Diagrammanalyse und transparente Reasoning-Workflows in Echtzeit. Erleben Sie das einzigartige Denkparadigma des Modells über die intuitive Oberfläche.
Modellvergleich: Wechseln Sie mühelos zwischen GLM-4.1V-9B-Thinking, anderen Vision-Language-Modellen und textbasierten Modellen, um die perfekte Lösung für Ihre multimodalen Anforderungen zu finden.
Integration über API (Für Entwickler)
Verbinden Sie GLM-4.1V-9B-Thinking nahtlos mit Ihren Anwendungen, Workflows oder Chatbots über die einheitliche REST API von Novita AI – ohne Verwaltung von Modellgewichten oder Infrastruktur.
Option 1: Direkte API-Integration (Python-Beispiel)
Um mit multimodalen Eingaben zu beginnen, verwenden Sie einfach das folgende Code-Snippet:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = "Sei ein hilfreicher Assistent"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Hauptmerkmale:
- Einheitlicher Endpunkt:
/v3/openaiunterstützt das OpenAI Chat Completions API-Format. - Flexible Steuerung: Passen Sie Temperatur, top-p, Penalties und mehr für maßgeschneiderte Ergebnisse an.
- Streaming & Batching: Wählen Sie Ihren bevorzugten Antwortmodus.
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Bauen Sie fortschrittliche multimodale Agentensysteme auf, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
Plug-and-Play: Verwenden Sie GLM-4.1V-9B-Thinking in jedem OpenAI Agents-Workflow für Vision-Language-Aufgaben.
Unterstützt Handoffs, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die visuelle Inhalte analysieren, Aufgaben delegieren oder Funktionen ausführen können – angetrieben von den Reasoning-Fähigkeiten von GLM-4.1V-9B-Thinking.
Python-Integration: Richten Sie das SDK einfach auf Novitas Endpunkt (https://api.novita.ai/v3/openai) aus und verwenden Sie Ihren API-Schlüssel für nahtlose multimodale Agenten-Workflows.
Verbinden Sie die GLM-4.1V-9B-Thinking API auf Drittanbieter-Plattformen
Hugging Face: Verwenden Sie GLM-4.1V-9B-Thinking in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte für multimodale Anwendungen.
Agent- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI ganz einfach mit Partnerplattformen wie Continue, AnythingLLM, LangChain, Dify und Langflow über offizielle Konnektoren und Schritt-für-Schritt-Integrationsleitfäden.
OpenAI-kompatible API: Genießen Sie eine problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI API-Standard entwickelt wurden.
Fazit
GLM-4.1V-9B-Thinking stellt einen transformativen Meilenstein in der multimodalen KI dar. Es demonstriert, dass fortgeschrittene Reasoning-Fähigkeiten effizient in einem Modell mit 9 Milliarden Parametern erreicht werden können. Durch das innovative RLCS-Training-Framework und das einzigartige Denkparadigma erreicht oder übertrifft es wesentlich größere 72B-Parameter-Systeme in verschiedenen Benchmarks.
Probieren Sie jetzt die GLM-4.1V-9B-Thinking Demo auf Novita AI aus und sichern Sie sich Ihre kostenlosen Credits!
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig erschwingliche und zuverlässige GPU-Cloud zum Bauen und Skalieren bietet.



