

在处理多语言文档解析时感到困难?需要从复杂文档中提取文本、表格、公式和图表,却不想投资昂贵的基础设施?
Novita AI GPU实例上的PaddleOCR-VL 就是您的答案。这一先进的OCR解决方案只需5分钟设置即可提供企业级的文档解析能力——无需复杂配置、无需硬件投资、无需麻烦。
凭借 109种语言支持、对包括手写文本和历史文档在内的复杂元素的识别能力,以及 快速的推理速度,PaddleOCR-VL实现了传统OCR系统无法企及的:在一个紧凑的包中同时拥有准确性、效率和多功能性。
👉 立即开始部署PaddleOCR-VL ,使用我们预配置的GPU模板。
这份分步指南将准确地向您展示如何在Novita AI GPU实例上部署PaddleOCR-VL,运行您的第一次OCR推理,并立即开始处理文档。无论您是在数字化发票、分析研究论文还是从表单中提取数据,都能在几分钟内拥有一个生产就绪的解决方案。
什么是PaddleOCR-VL?
PaddleOCR-VL是一个SOTA(最先进)且资源高效的视觉语言模型,专门为文档解析而设计。与消耗大量计算资源或在复杂布局上挣扎的传统OCR系统不同,PaddleOCR-VL在保持最小资源消耗的同时提供出色的准确性。
PaddleOCR-VL背后的技术
核心上,PaddleOCR-VL-0.9B 结合了:
- NaViT风格的动态分辨率视觉编码器,用于精确的图像处理
- ERNIE-4.5-0.3B语言模型,用于智能文本理解
- 紧凑架构(0.9B参数),实现快速高效的推理
这种创新的集成使模型能够识别跨109种语言的复杂文档元素——文本、表格、公式、图表——而无需昂贵的GPU硬件或漫长的处理时间。
经过验证的性能
通过对广泛使用的公开基准测试和内部测试的全面评估,PaddleOCR-VL在页面级文档解析和元素级识别方面均达到了SOTA性能。该模型显著优于现有的基于管道的解决方案,并与顶级视觉语言模型(VLM)表现出强大的竞争力,使其成为生产环境的首选。
为什么选择PaddleOCR-VL进行文档解析?
1. 紧凑而强大的架构
资源效率与高性能兼具。 PaddleOCR-VL新颖的视觉语言架构专为资源高效的推理而设计,同时实现出色的元素识别结果。
将NaViT风格的动态高分辨率视觉编码器与轻量级的ERNIE-4.5-0.3B语言模型集成,显著增强了识别能力和解码效率。您可以在 减少计算需求的同时获得高准确性——非常适合经济高效、实用的文档处理应用。
2. 在复杂文档上表现SOTA
在最关键的场景下提供最佳准确性。 PaddleOCR-VL在以下方面达到了最先进的性能:
- 页面级文档解析:完整的文档理解和结构识别
- 元素级识别:精确提取各个组件
该模型擅长识别传统OCR系统难以处理的有挑战性的内容:
- ✅ 带有合并单元格和嵌套结构的复杂表格
- ✅ 数学公式和方程式
- ✅ 图表、图形和示意图
- ✅ 风格各异的手写文本
- ✅ 质量退化的历史文档
- ✅ 混合语言文档
这种多功能性使得PaddleOCR-VL适用于您遇到的几乎任何文档类型或场景。
3. 广泛的多语言支持(109种语言)
真正的全球覆盖。 PaddleOCR-VL支持 109种语言,包括:
- 主要全球语言:中文、英语、日语、韩语、拉丁语系
- 多种文字:俄语(西里尔字母)、阿拉伯语、印地语(天城文)、泰语
- 地区语言:以及更多
这种广泛的语言覆盖显著增强了系统在 多语言和全球化文档处理场景中的适用性。无需切换工具或模型,即可处理来自任何市场、任何地区、任何语言的文档。
4. 快速推理速度
时间就是金钱。 PaddleOCR-VL提供快速的推理速度,使其非常适合实际场景中的部署。紧凑的0.9B参数模型在不牺牲准确性的前提下快速处理文档,支持高吞吐量的文档处理工作流。
如何在Novita AI上部署PaddleOCR-VL(5分钟指南)
准备好将PaddleOCR-VL部署到Novita AI GPU实例上了吗?请按照以下8个简单步骤,在几分钟内让您的SOTA OCR服务运行起来。
步骤 1:访问PaddleOCR-VL模板
您可以直接访问 PaddleOCR-VL GPU模板。
步骤 2:配置您的GPU实例
设置基础设施参数以匹配您的处理需求:
- 内存分配:根据工作负载选择RAM容量
- 存储需求:为模型文件和处理分配磁盘空间
- 网络设置:配置API访问的连接
选择 部署 以实施您的配置。
专业提示:从典型文档处理工作负载的推荐设置开始,然后根据需要扩展。
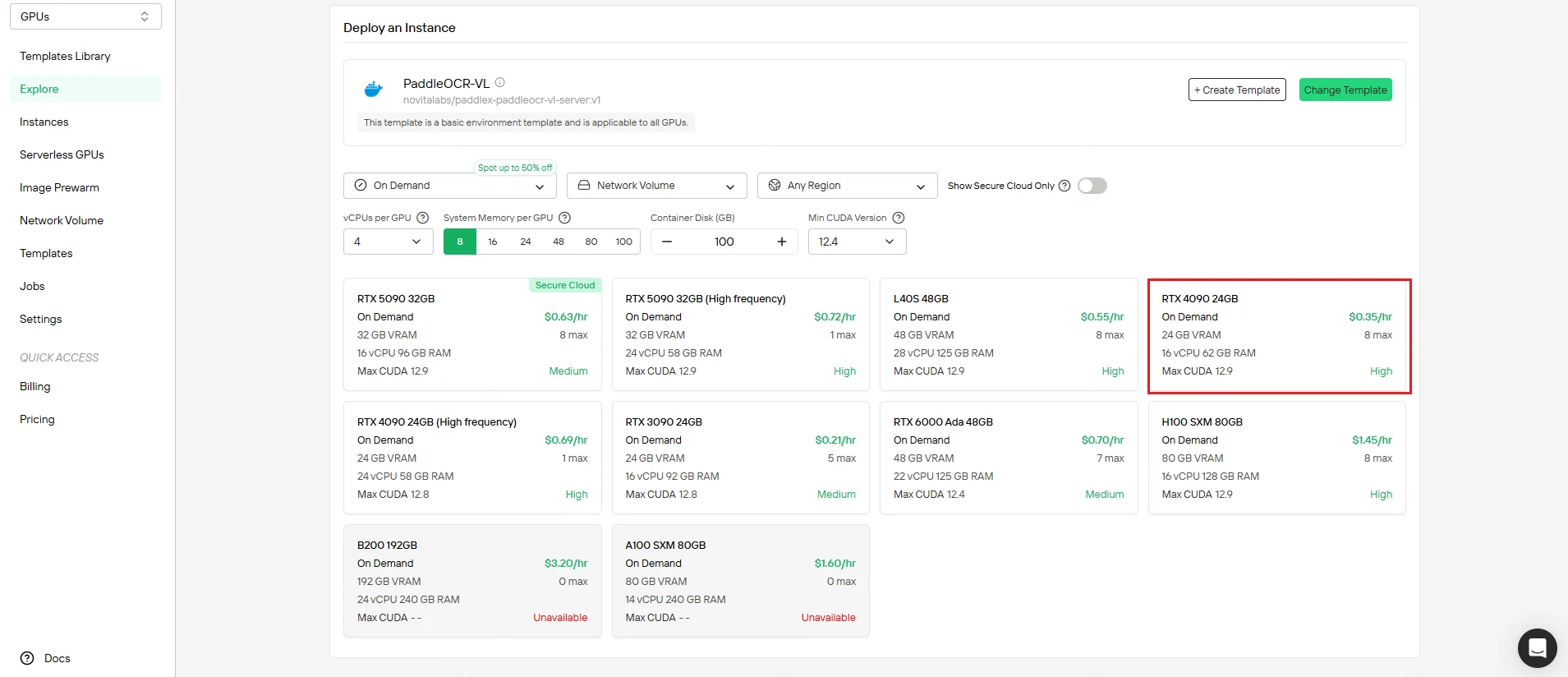
步骤 3:审查配置并部署
在部署前再次检查您的设置:
- 验证计算资源是否满足要求
- 审查成本摘要以确保预算匹配
- 确认网络和存储配置
满意后,点击 部署 开始创建过程。Novita AI会自动处理所有后端复杂性。
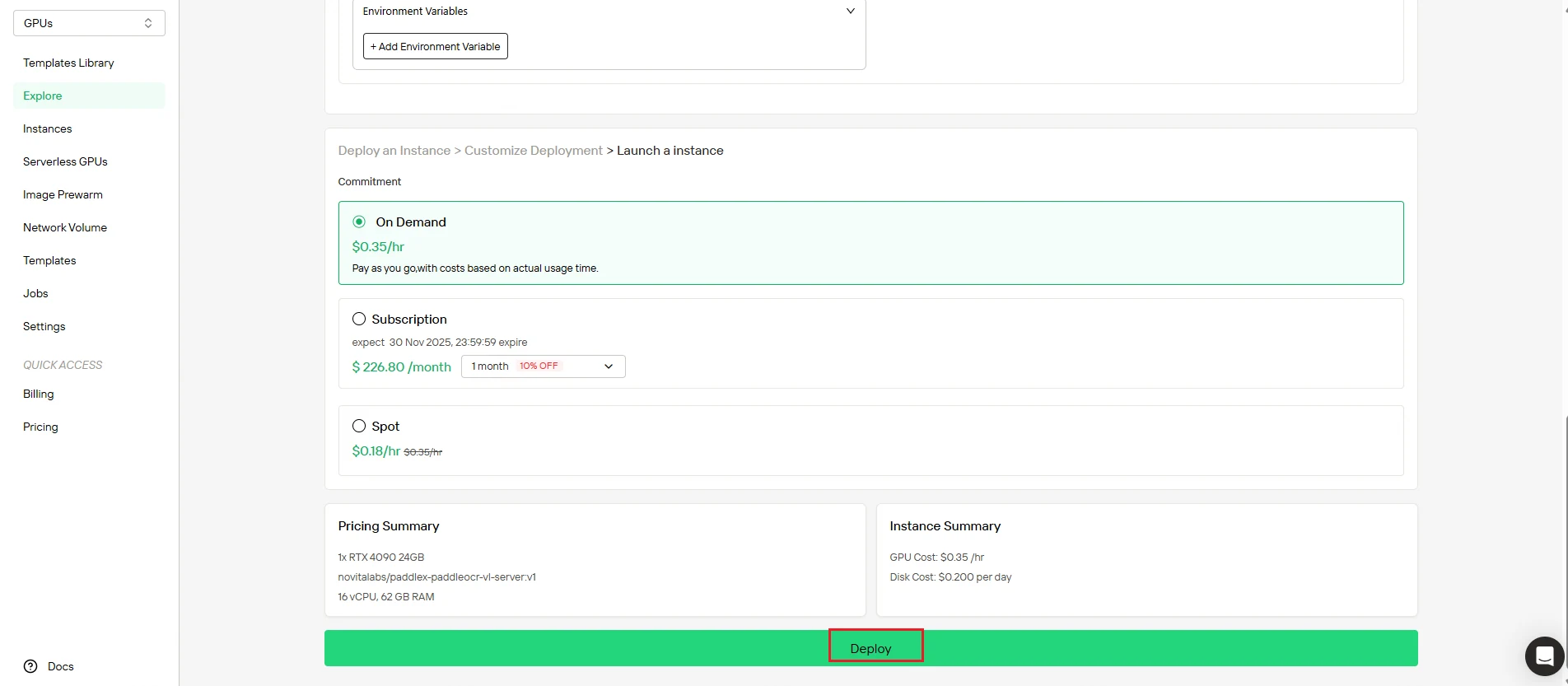
步骤 4:监控实例创建
启动部署后,系统会自动将您重定向 到实例管理页面。您的实例在后台创建——无需手动干预。
从仪表板实时跟踪进度。
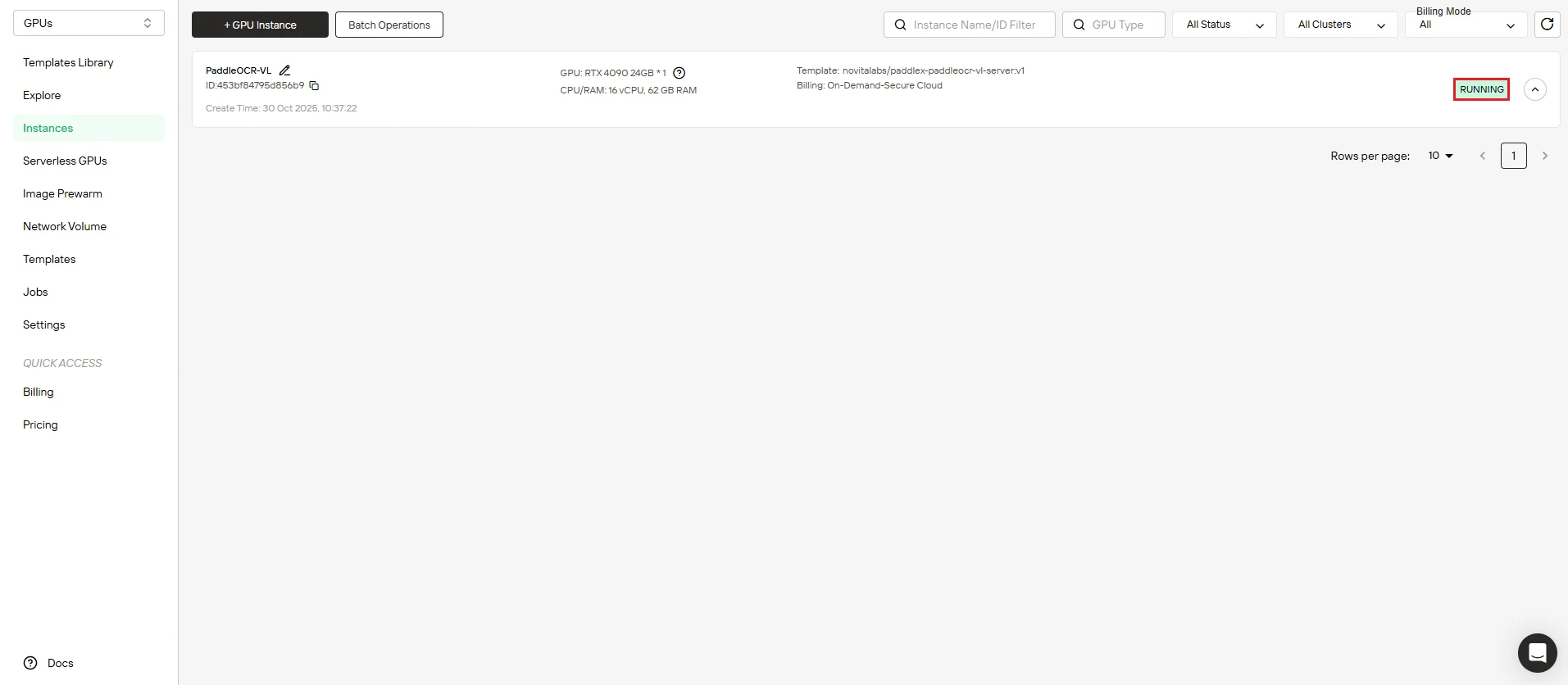
步骤 5:跟踪镜像下载进度
查看您的实例上线。 仪表板实时显示PaddleOCR-VL镜像下载的进度。部署成功完成后,您的实例状态将从 “Pulling” 转变为 “Running”。
点击实例名称旁边的 箭头图标 查看详细的进度信息和部署日志。
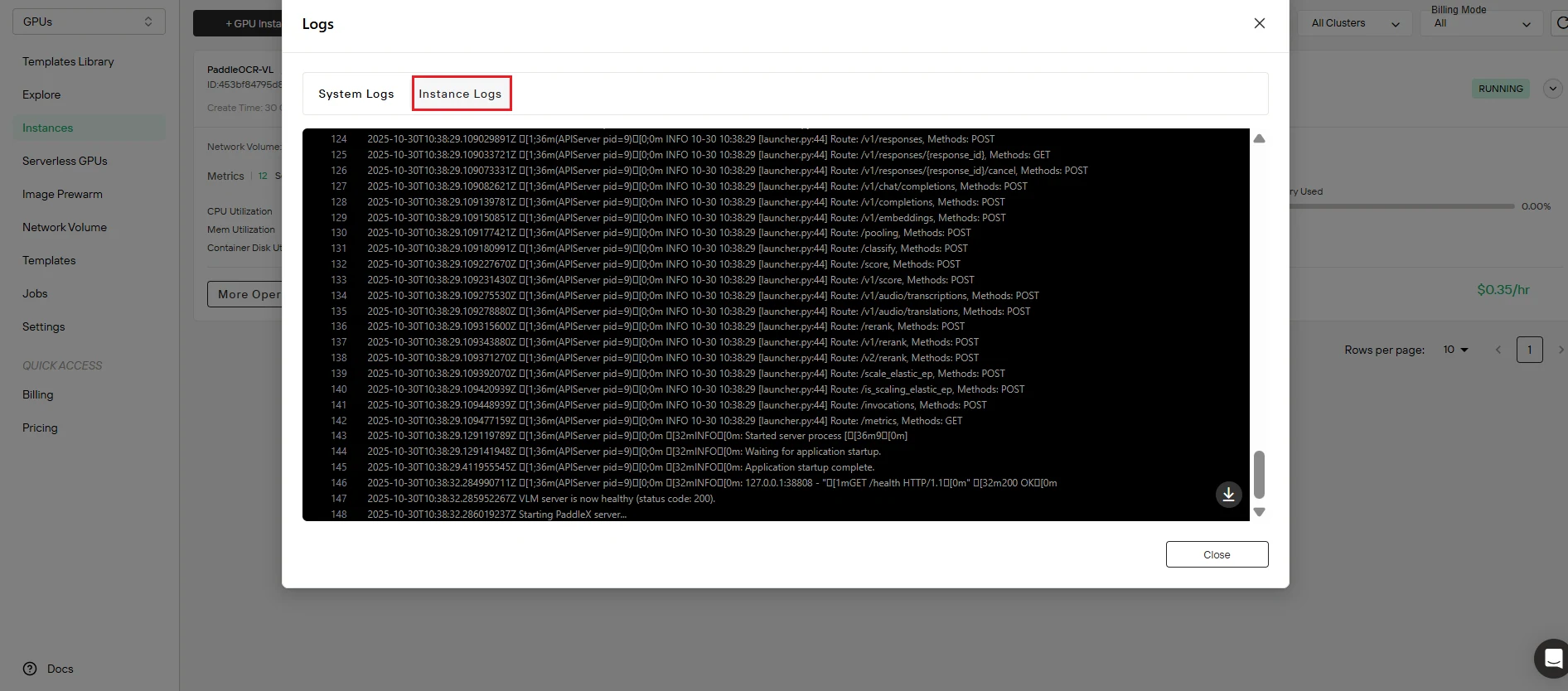
步骤 6:验证服务状态
确认部署成功。 点击 Logs 按钮访问实例日志,并验证PaddleOCR-VL服务已正确启动。查找确认以下内容的初始化消息:
- 服务启动完成
- API端点已激活并正在监听
- 模型加载成功
步骤 7:访问开发环境
启动您的工作区。 导航到 Connect 界面,初始化 Start Web Terminal 以获得实例的命令行访问权限。
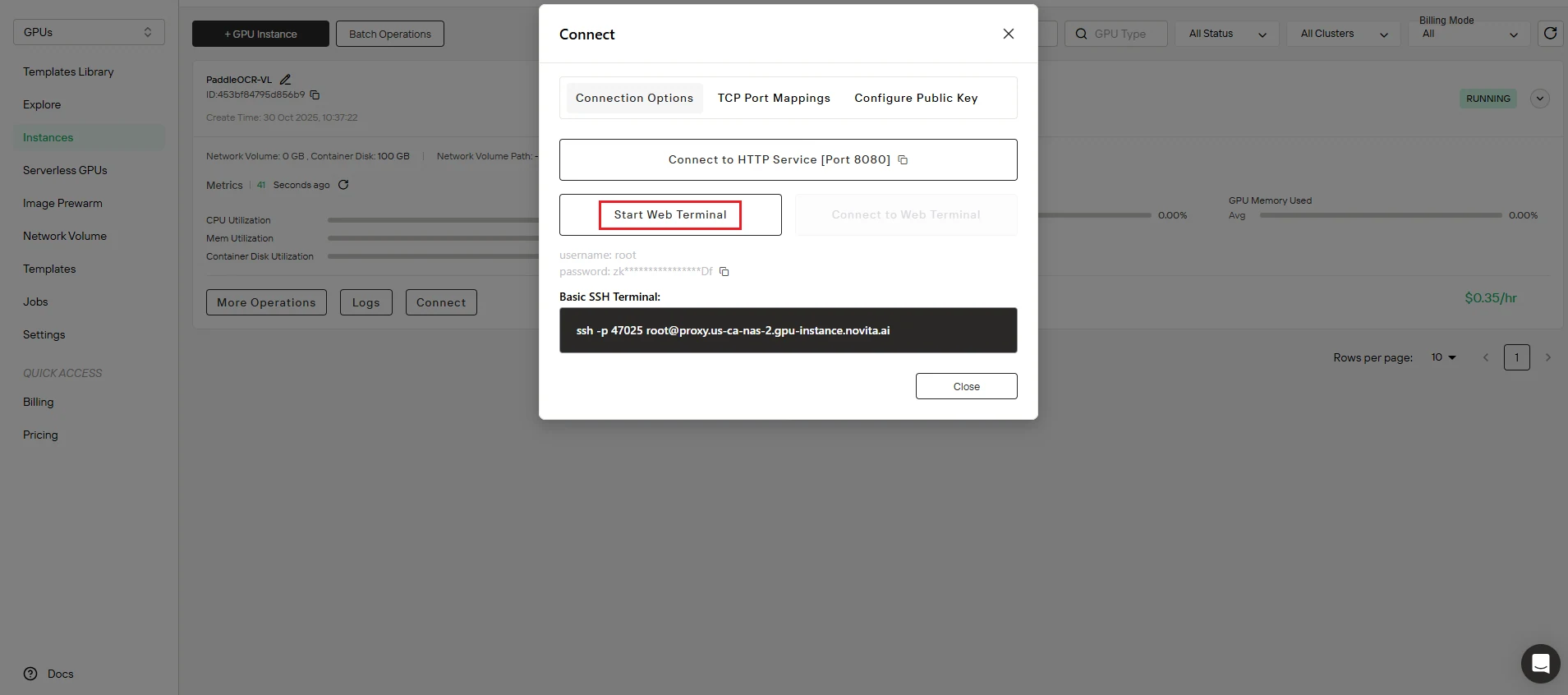
🎉 恭喜! 您的PaddleOCR-VL服务现已完全运行,可以处理OCR请求。总用时:大约5分钟。
运行您的第一次OCR推理
现在您的PaddleOCR-VL实例已在Novita AI GPU上运行,让我们处理您的第一个文档。本演示展示了从图像准备到结果提取的完整工作流程。
步骤 1:创建Python测试脚本
创建一个名为 test.py 的文件,内容如下:
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # 服务URL
image_path = "./demo.jpg"
# 将本地图像编码为Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64编码的文件内容或文件URL
"fileType": 1, # 文件类型,1表示图像文件
}
# 调用API
response = requests.post(API_URL, json=payload)
# 处理API响应数据
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown文档已保存至 {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"输出图像已保存至 {img_path}")
该脚本的作用:
- 将您的图像编码为Base64格式
- 将其发送到PaddleOCR-VL API端点
- 接收结构化的解析结果
- 将提取的内容保存为Markdown文档
- 导出嵌入的图像
步骤 2:下载测试图像
使用 官方PaddleOCR测试用例 进行第一次推理:
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
这会下载一个示例文档图像(book.jpg)来测试您的OCR设置。官方测试文件位于:PaddleOCR GitHub仓库
步骤 3:配置API端点
使用正确的端点更新您的脚本:
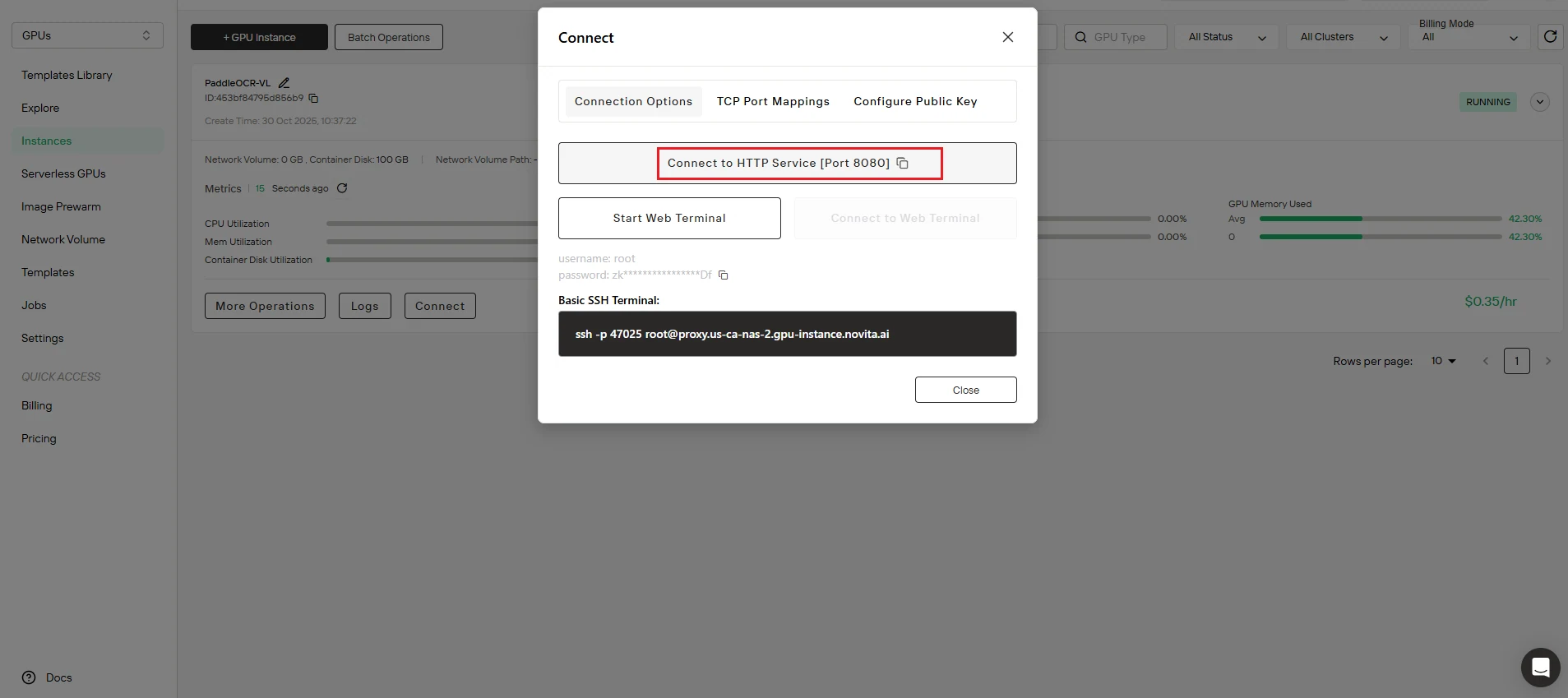
- 从您的Novita AI实例仪表板复制 端口映射地址
- 将
test.py中的http://localhost:8080/layout-parsing替换为您的实际API端点URL
示例:您的端点可能看起来像 http://your-instance-id.novita.ai:8080/layout-parsing
步骤 4:执行OCR处理
运行您的测试脚本:
python test.py
预期输出:
- 控制台显示提取的文本结构
- Markdown文档保存到
markdown_0/doc.md - 嵌入的图像提取到单独的文件
- 显示输出文件位置的确认消息
就这样! 您已成功在Novita AI GPU实例上使用PaddleOCR-VL处理了您的第一个文档。
实际应用场景
在Novita AI GPU实例上部署PaddleOCR-VL,为各种文档处理工作流提供支持:
金融服务
- 发票处理:提取行项目、总额、供应商信息
- 收据数字化:自动化费用报告和对账
- 银行对账单解析:将对账单转换为结构化数据
学术与研究
- 研究论文分析:从出版物中提取文本、公式、表格
- 教科书数字化:将教育材料转换为可搜索格式
- 历史文档保存:对文本质量退化的档案进行数字化
法律与合规
- 合同分析:提取条款、条件、签名
- 监管文档处理:解析合规申报和报告
- 法律发现:将案件文档转换为可搜索文本
医疗保健
- 医疗记录数字化:将患者图表转换为结构化数据
- 处方处理:从表单中提取药物信息
- 保险理赔解析:自动化理赔文档处理
电子商务与零售
- 产品目录提取:解析供应商数据表和规格
- 多语言产品描述:处理国际目录
- 库存文档处理:数字化库存清单和舱单
政府服务
- 表单处理:自动化公民服务文档处理
- 身份验证:从身份文档中提取信息
- 许可证处理:解析申请文档
109种语言支持 和 复杂元素识别 使PaddleOCR-VL成为处理多样化文档类型的全球组织的理想选择。
结论
在5分钟内将PaddleOCR-VL部署到Novita AI GPU实例,无需基础设施复杂性即可解锁最先进的文档解析能力。凭借SOTA性能、109种语言支持和高效的资源使用,您将获得既强大又实用的企业级OCR。
关键要点:
✅ 5分钟部署,使用预配置模板
✅ SOTA准确性,适用于文本、表格、公式和图表
✅ 109种语言,用于全球文档处理
✅ 复杂元素识别,包括手写和历史文档
✅ 快速推理速度,用于高吞吐量工作流
✅ 资源高效,配备紧凑的0.9B参数模型
无论您是在处理发票、数字化研究论文、分析法律文档还是处理多语言内容,Novita AI上的PaddleOCR-VL都能从第一天起提供生产就绪的结果。
准备转变您的文档工作流了吗?
不要让复杂的OCR设置拖慢您的速度。 立即在Novita AI GPU实例上部署PaddleOCR-VL,在几分钟(而非几小时)内开始处理文档。
立即访问预配置的PaddleOCR-VL模板,包含所有依赖和优化。只需点击、配置和部署——您的SOTA OCR服务将在5分钟内运行。
为什么数千名开发者选择Novita AI:
- 零基础设施管理
- 即用即付定价,无前期成本
- 预配置模板,即时部署
- 按需可扩展的GPU资源
- 全天候支持和全面文档
立即开始部署——您的第一次OCR推理只需5分钟。
常见问题解答
在Novita AI上部署PaddleOCR-VL需要多长时间?
从模板选择到运行实例大约需要5分钟。
PaddleOCR-VL支持哪些语言?
109种语言,包括中文、英语、日语、韩语、俄语、阿拉伯语、印地语、泰语等。
PaddleOCR-VL能否识别手写文本?
可以,PaddleOCR-VL在识别手写文本和质量退化的历史文档方面表现出色。
PaddleOCR-VL可以提取哪些类型的文档元素?
文本、表格、数学公式、图表以及其他复杂文档元素。
在Novita AI上部署是否需要GPU经验?
不需要,预配置的模板会自动处理所有技术设置。只需点击 PaddleOCR-VL GPU模板 链接并按照简单步骤操作即可。
在Novita AI上运行PaddleOCR-VL需要多少费用?
Novita AI提供即用即付定价。您只需按实际使用的GPU时间付费,无前期成本或长期承诺。
Novita AI是一个AI云平台,为开发者提供通过简单API部署AI模型的便捷方式,同时提供经济实惠且可靠的GPU云用于构建和扩展。




{kind=link}