

Vous avez du mal avec l’analyse de documents multilingues ? Vous avez besoin d’extraire du texte, des tableaux, des formules et des graphiques de documents complexes sans investir dans une infrastructure coûteuse ?
PaddleOCR-VL sur une instance GPU Novita AI est la solution. Cette solution OCR de pointe offre une analyse de documents de qualité entreprise en seulement 5 minutes de configuration : pas de paramétrage complexe, pas d’investissement matériel, pas de tracas.
Avec une prise en charge de 109 langues, la reconnaissance d’éléments complexes incluant du texte manuscrit et des documents historiques, et des vitesses d’inférence rapides, PaddleOCR-VL réalise ce que les systèmes OCR traditionnels ne peuvent pas : précision, efficacité et polyvalence dans un package compact.
👉 Commencez à déployer PaddleOCR-VL maintenant avec notre modèle GPU préconfiguré.
Ce guide étape par étape vous montre exactement comment déployer PaddleOCR-VL sur une instance GPU Novita AI, exécuter votre première inférence OCR et commencer à traiter des documents immédiatement. Que vous numérisiez des factures, analysiez des articles de recherche ou extrayiez des données de formulaires, vous aurez une solution prête pour la production en quelques minutes.
Qu’est-ce que PaddleOCR-VL ?
PaddleOCR-VL est un modèle vision-langage de pointe (SOTA) et économe en ressources spécialement conçu pour l’analyse de documents. Contrairement aux systèmes OCR traditionnels qui consomment d’énormes ressources de calcul ou peinent avec des mises en page complexes, PaddleOCR-VL offre une précision exceptionnelle tout en maintenant une consommation de ressources minimale.
La technologie derrière PaddleOCR-VL
Au cœur de PaddleOCR-VL-0.9B se combine :
- Encodeur visuel à résolution dynamique de type NaViT pour un traitement d’image précis
- Modèle de langage ERNIE-4.5-0.3B pour une compréhension intelligente du texte
- Architecture compacte (0,9 milliard de paramètres) pour une inférence rapide et efficace
Cette intégration innovante permet au modèle de reconnaître des éléments de documents complexes — texte, tableaux, formules, graphiques — dans 109 langues sans nécessiter de matériel GPU coûteux ou des temps de traitement longs.
Performances éprouvées
Grâce à des évaluations complètes sur des benchmarks publics largement utilisés et des tests internes, PaddleOCR-VL atteint des performances de pointe (SOTA) à la fois pour l’analyse de documents au niveau de la page et la reconnaissance au niveau des éléments. Le modèle surpasse de manière significative les solutions basées sur des pipelines existantes et présente une forte compétitivité face aux modèles vision-langage de haut niveau (VLM), ce qui en fait le choix privilégié pour les environnements de production.
Pourquoi choisir PaddleOCR-VL pour l’analyse de documents ?
1. Une architecture compacte mais puissante
Efficacité des ressources rencontre haute performance. La nouvelle architecture vision-langage de PaddleOCR-VL est spécialement conçue pour une inférence économe en ressources tout en obtenant des résultats de reconnaissance d’éléments exceptionnels.
L’intégration d’un encodeur visuel dynamique haute résolution de type NaViT avec le modèle de langage léger ERNIE-4.5-0.3B améliore considérablement les capacités de reconnaissance et l’efficacité de décodage. Vous obtenez une haute précision avec des demandes de calcul réduites — parfait pour des applications de traitement de documents pratiques et rentables.
2. Performances de pointe (SOTA) sur des documents complexes
Précision de meilleure classe là où ça compte le plus. PaddleOCR-VL atteint des performances de pointe dans :
- Analyse de documents au niveau de la page : compréhension complète du document et reconnaissance de la structure
- Reconnaissance au niveau des éléments : extraction précise des composants individuels
Le modèle excelle dans la reconnaissance de contenus difficiles qui font échouer les systèmes OCR traditionnels :
- ✅ Tableaux complexes avec cellules fusionnées et structures imbriquées
- ✅ Formules mathématiques et équations
- ✅ Graphiques, schémas et diagrammes
- ✅ Texte manuscrit avec des styles variés
- ✅ Documents historiques avec une qualité dégradée
- ✅ Documents multilingues
Cette polyvalence fait de PaddleOCR-VL un outil adapté à pratiquement tout type de document ou scénario que vous rencontrez.
3. Prise en charge multilingue étendue (109 langues)
Portée véritablement mondiale. PaddleOCR-VL prend en charge 109 langues, couvrant :
- Langues mondiales majeures : chinois, anglais, japonais, coréen, latin
- Écritures variées : russe (cyrillique), arabe, hindi (devanagari), thaï
- Langues régionales : et bien d’autres
Cette large couverture linguistique améliore considérablement l’applicabilité du système à des scénarios de traitement de documents multilingues et mondialisés. Traitez des documents de n’importe quel marché, n’importe quelle région, n’importe quelle langue — sans changer d’outils ou de modèles.
4. Vitesses d’inférence rapides
Le temps, c’est de l’argent. PaddleOCR-VL offre des vitesses d’inférence rapides qui le rendent très adapté au déploiement pratique dans des scénarios réels. Le modèle compact de 0,9 milliard de paramètres traite les documents rapidement sans sacrifier la précision, permettant des flux de travail de traitement de documents à haut débit.
Comment déployer PaddleOCR-VL sur Novita AI (guide de 5 minutes)
Prêt à déployer PaddleOCR-VL sur une instance GPU Novita AI ? Suivez ces 8 étapes simples pour mettre votre service OCR de pointe (SOTA) en service en quelques minutes.
Étape 1 : Accédez au modèle PaddleOCR-VL
Vous pouvez accéder directement au modèle GPU PaddleOCR-VL .
Étape 2 : Configurez votre instance GPU
Configurez les paramètres d’infrastructure pour correspondre à vos besoins de traitement :
- Allocation de mémoire : choisissez la capacité de RAM en fonction de la charge de travail
- Besoins de stockage : allouez de l’espace disque pour les fichiers de modèle et le traitement
- Paramètres réseau : configurez la connectivité pour l’accès à l’API
Sélectionnez Déployer pour appliquer votre configuration.
Conseil pro : commencez avec les paramètres recommandés pour des charges de travail de traitement de documents typiques, puis adaptez l’échelle selon vos besoins.
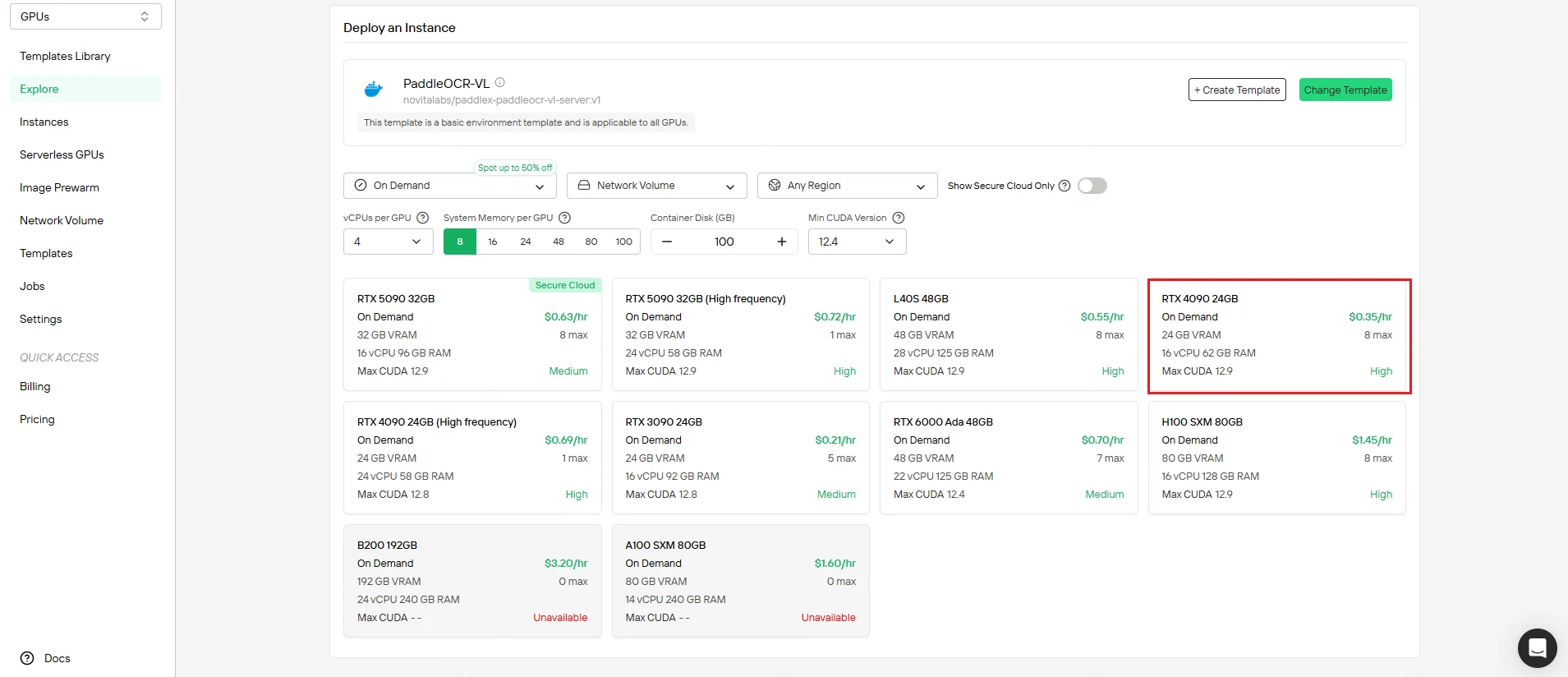
Étape 3 : Vérifiez la configuration et déployez
Vérifiez deux fois vos paramètres avant le déploiement :
- Vérifiez que les ressources de calcul correspondent à vos besoins
- Vérifiez le récapitulatif des coûts pour vous assurer de l’alignement avec votre budget
- Confirmez les configurations réseau et de stockage
Lorsque vous êtes satisfait, cliquez sur Déployer pour lancer le processus de création. Novita AI gère toute la complexité du backend automatiquement.
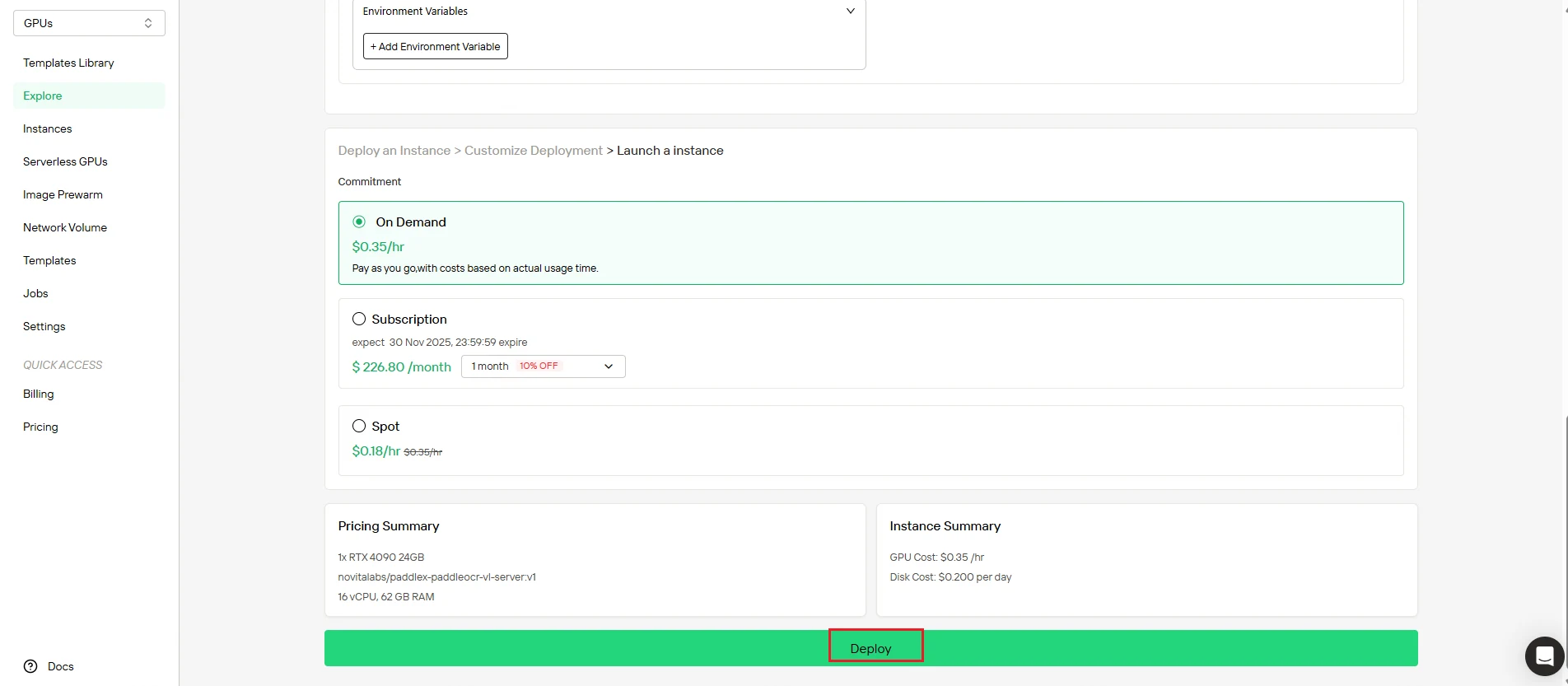
Étape 4 : Surveillez la création de l’instance
Après avoir lancé le déploiement, le système vous redirige automatiquement vers la page de gestion des instances. Votre instance est créée en arrière-plan — aucune intervention manuelle n’est requise.
Suivez la progression en temps réel depuis le tableau de bord.
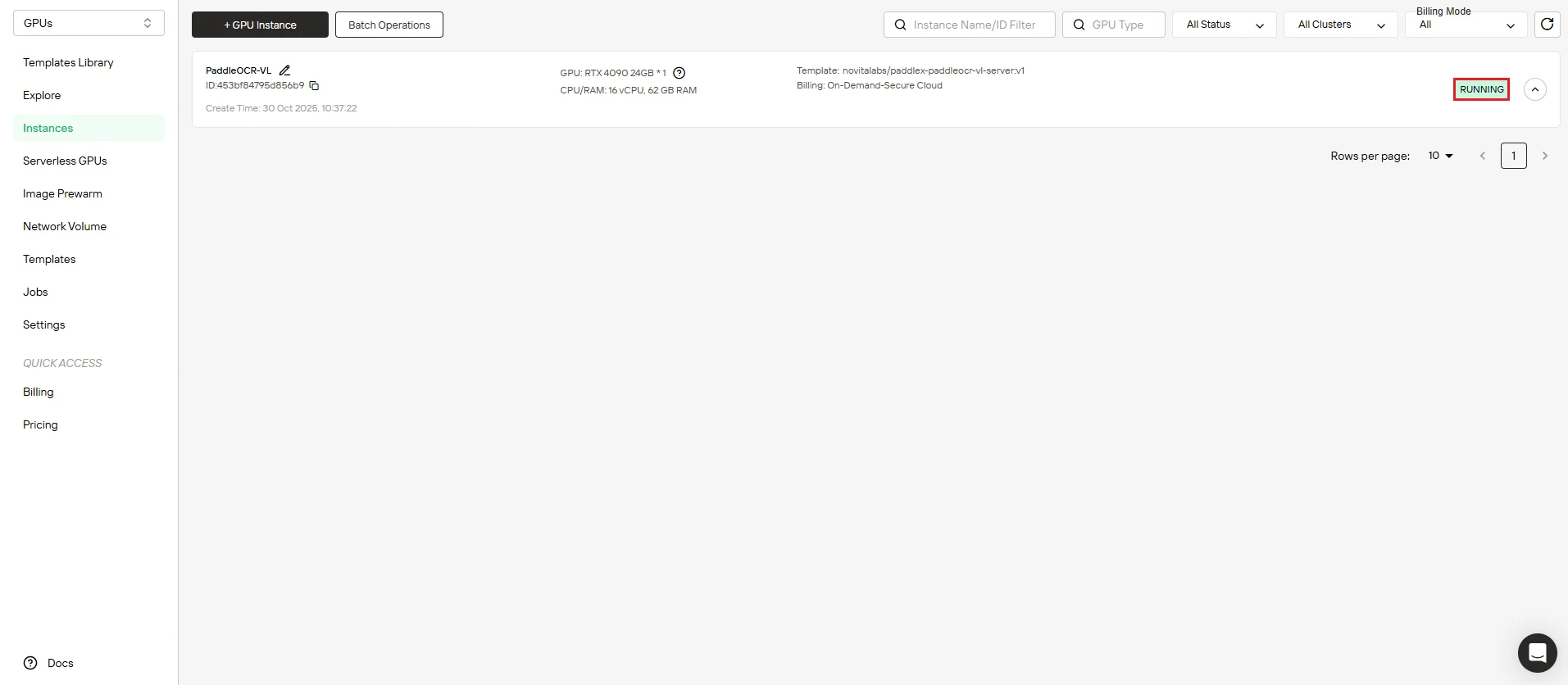
Étape 5 : Suivez la progression du téléchargement de l’image
Regardez votre instance se mettre en ligne. Le tableau de bord affiche la progression en temps réel du téléchargement de l’image PaddleOCR-VL. L’état de votre instance passe de “Téléchargement” à “En cours d’exécution” une fois le déploiement terminé avec succès.
Cliquez sur l’icône flèche à côté du nom de votre instance pour afficher des informations de progression détaillées et les journaux de déploiement.
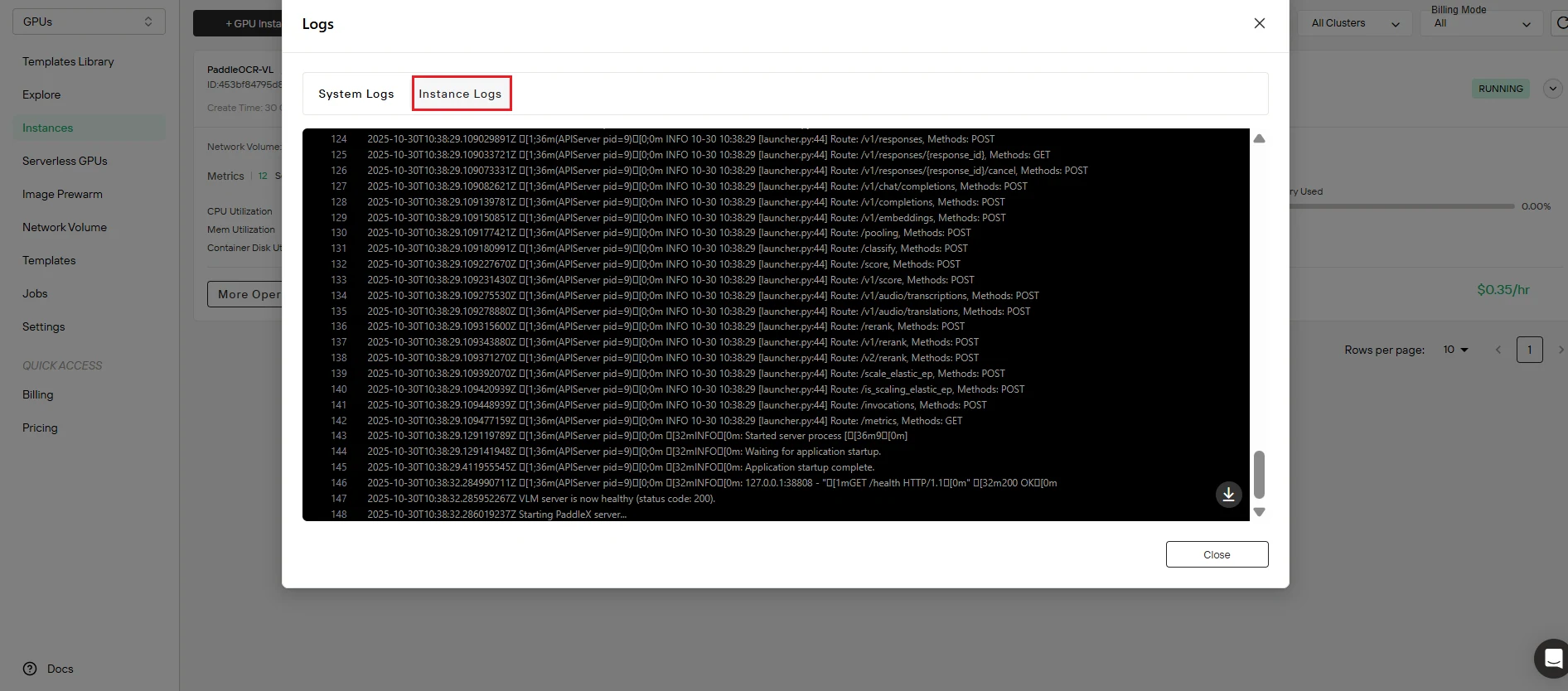
Étape 6 : Vérifiez l’état du service
Confirmez le déploiement réussi. Cliquez sur le bouton Journaux pour accéder aux journaux de l’instance et vérifier que le service PaddleOCR-VL a démarré correctement. Recherchez des messages d’initialisation confirmant :
- Lancement du service terminé
- Point de terminaison API actif et à l’écoute
- Modèle chargé avec succès
Étape 7 : Accédez à l’environnement de développement
Lancez votre espace de travail. Accédez à l’interface Connecter et initialisez Démarrer le terminal Web pour obtenir un accès en ligne de commande à votre instance.
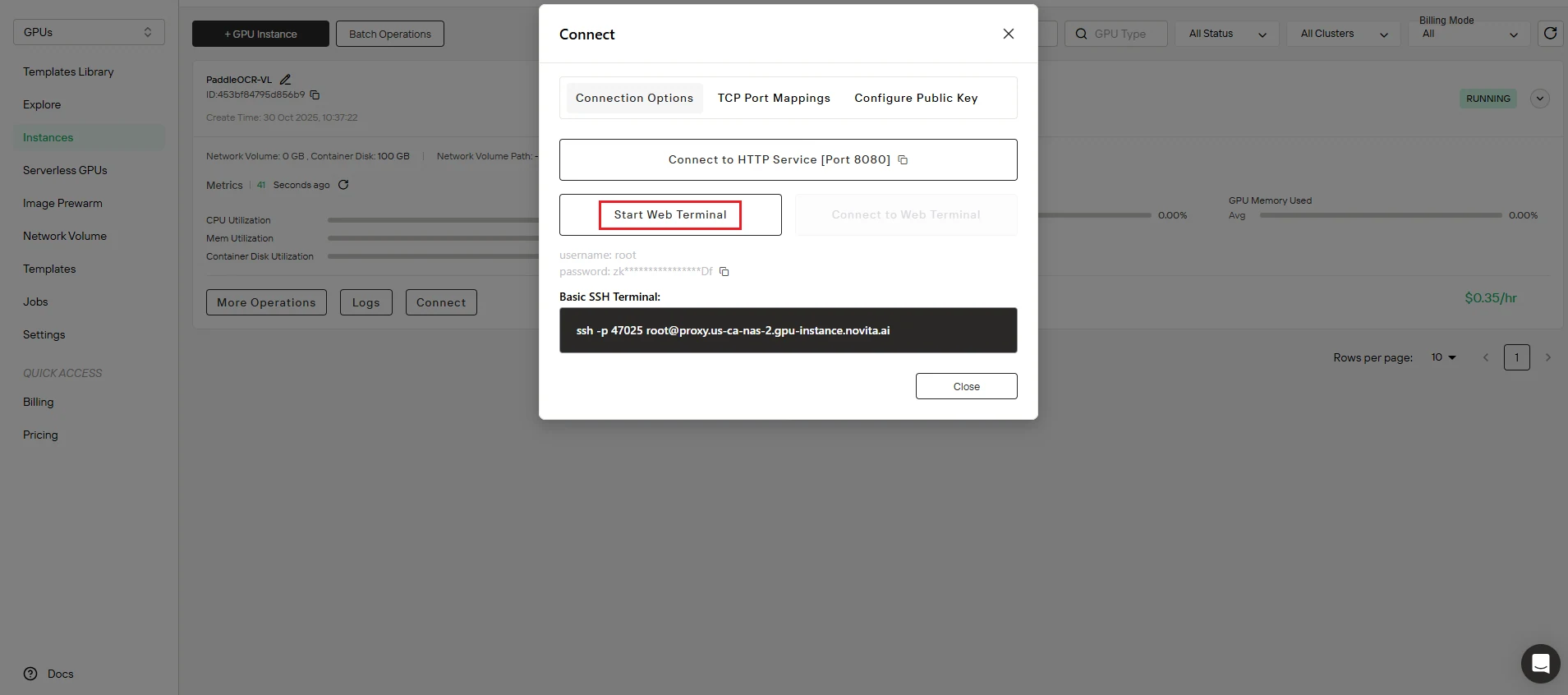
🎉 Félicitations ! Votre service PaddleOCR-VL est maintenant entièrement opérationnel et prêt à traiter les demandes OCR. Temps total : environ 5 minutes.
Exécutez votre première inférence OCR
Maintenant que votre instance PaddleOCR-VL est en cours d’exécution sur le GPU Novita AI, traitons votre premier document. Cette démo présente le flux de travail complet, de la préparation de l’image à l’extraction des résultats.
Étape 1 : Créez un script de test Python
Créez un fichier nommé test.py avec le code suivant :
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
Ce que fait ce script :
- Encode votre image au format Base64
- L’envoie au point de terminaison de l’API PaddleOCR-VL
- Reçoit des résultats d’analyse structurés
- Enregistre le contenu extrait sous forme de documents Markdown
- Exporte les images intégrées
Étape 2 : Téléchargez l’image de test
Utilisez le cas de test officiel PaddleOCR pour votre première inférence :
bash
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
Ceci télécharge une image de document exemple (book.jpg) pour tester votre configuration OCR. Le fichier de test officiel est disponible sur : Dépôt GitHub PaddleOCR
Étape 3 : Configurez le point de terminaison de l’API
Mettez à jour votre script avec le point de terminaison correct :
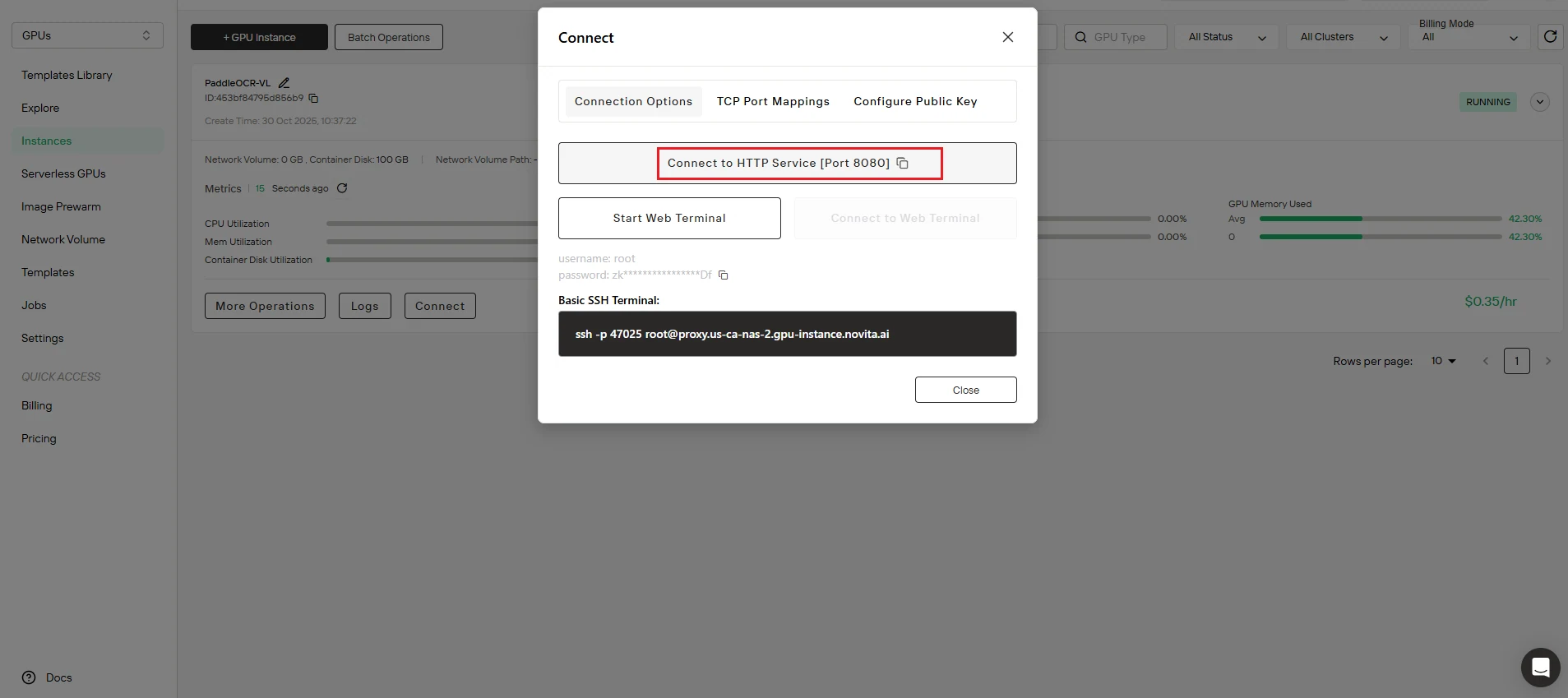
- Copiez l’adresse de mappage de port depuis votre tableau de bord d’instance Novita AI
- Remplacez
http://localhost:8080/layout-parsingdanstest.pypar l’URL réelle de votre point de terminaison d’API
Exemple : votre point de terminaison peut ressembler à http://your-instance-id.novita.ai:8080/layout-parsing
Étape 4 : Exécutez le traitement OCR
Exécutez votre script de test :
bash
python test.py
Résultat attendu :
- La console affiche la structure du texte extrait
- Documents Markdown enregistrés dans
markdown_0/doc.md - Images intégrées extraites vers des fichiers séparés
- Messages de confirmation indiquant les emplacements des fichiers de sortie
C’est tout ! Vous avez traité avec succès votre premier document avec PaddleOCR-VL sur une instance GPU Novita AI.
Applications concrètes
Déployez PaddleOCR-VL sur une instance GPU Novita AI pour alimenter divers flux de travail de traitement de documents :
Services financiers
- Traitement des factures : extrayez les lignes d’articles, les totaux, les informations sur les fournisseurs
- Numérisation des reçus : automatisez les rapports de dépenses et la réconciliation
- Analyse des relevés bancaires : convertissez les relevés en données structurées
Académique et recherche
- Analyse d’articles de recherche : extrayez du texte, des formules, des tableaux des publications
- Numérisation de manuels scolaires : convertissez les matériels éducatifs en formats consultables
- Préservation de documents historiques : numérisez des archives avec une qualité de texte dégradée
Juridique et conformité
- Analyse de contrats : extrayez des clauses, des conditions, des signatures
- Traitement de documents réglementaires : analysez les dépôts de conformité et les rapports
- Découverte juridique : convertissez les documents d’affaires en texte consultable
Santé
- Numérisation de dossiers médicaux : convertissez les dossiers patients en données structurées
- Traitement d’ordonnances : extrayez les informations sur les médicaments des formulaires
- Analyse de demandes d’assurance : automatisez le traitement des documents de demande
E-commerce et commerce de détail
- Extraction de catalogues produits : analysez les fiches techniques et les spécifications des fournisseurs
- Descriptions de produits multilingues : traitez les catalogues internationaux
- Traitement de documents d’inventaire : numérisez les listes de stock et les manifestes
Services publics
- Traitement de formulaires : automatisez le traitement des documents de service aux citoyens
- Vérification d’identité : extrayez des informations des documents d’identification
- Traitement de permis et licences : analysez les documents de demande
La prise en charge de 109 langues et la reconnaissance d’éléments complexes font de PaddleOCR-VL l’outil idéal pour les organisations mondiales traitant des types de documents variés.
Conclusion
Déployez PaddleOCR-VL sur une instance GPU Novita AI en 5 minutes et débloquez des capacités d’analyse de documents de pointe sans complexité d’infrastructure. Avec des performances SOTA, une prise en charge de 109 langues et une utilisation efficace des ressources, vous obtenez un OCR de qualité entreprise à la fois puissant et pratique.
Points clés à retenir :
✅ Déploiement en 5 minutes avec des modèles préconfigurés
✅ Précision SOTA pour le texte, les tableaux, les formules et les graphiques
✅ 109 langues pour le traitement de documents mondial
✅ Reconnaissance d’éléments complexes incluant des documents manuscrits et historiques
✅ Vitesses d’inférence rapides pour des flux de travail à haut débit
✅ Économe en ressources avec un modèle compact de 0,9 milliard de paramètres
Que vous traitiez des factures, numérisiez des articles de recherche, analysiez des documents juridiques ou gériez du contenu multilingue, PaddleOCR-VL sur Novita AI fournit des résultats prêts pour la production dès le premier jour.
Prêt à transformer votre flux de travail documentaire ?
Ne laissez pas une configuration OCR complexe vous ralentir. Déployez PaddleOCR-VL sur une instance GPU Novita AI aujourd’hui et commencez à traiter des documents en minutes, pas en heures.
👉 Déployez le modèle GPU PaddleOCR-VL maintenant
Obtenez un accès instantané au modèle PaddleOCR-VL préconfiguré avec toutes les dépendances et optimisations incluses. Il suffit de cliquer, de configurer et de déployer — votre service OCR de pointe (SOTA) sera en service en 5 minutes.
Pourquoi des milliers de développeurs choisissent Novita AI :
- Aucune gestion d’infrastructure
- Tarification à l’usage sans coûts initiaux
- Modèles préconfigurés pour un déploiement instantané
- Ressources GPU évolutives à la demande
- Assistance 24/7 et documentation complète
Commencez votre déploiement maintenant — votre première inférence OCR n’est qu’à 5 minutes.
Foire aux questions
Combien de temps faut-il pour déployer PaddleOCR-VL sur Novita AI ?
Environ 5 minutes, de la sélection du modèle à l’instance en cours d’exécution.
Quelles langues PaddleOCR-VL prend-il en charge ?
109 langues, dont le chinois, l’anglais, le japonais, le coréen, le russe, l’arabe, le hindi, le thaï et bien d’autres.
PaddleOCR-VL peut-il reconnaître du texte manuscrit ?
Oui, PaddleOCR-VL excelle dans la reconnaissance de texte manuscrit et de documents historiques avec une qualité dégradée.
Quels types d’éléments de documents PaddleOCR-VL peut-il extraire ?
Texte, tableaux, formules mathématiques, graphiques et autres éléments de documents complexes.
Ai-je besoin d’expérience en GPU pour déployer sur Novita AI ?
Non, le modèle préconfiguré gère toute la configuration technique automatiquement. Il suffit de cliquer sur le lien du modèle GPU PaddleOCR-VL et de suivre les étapes simples.
Combien coûte l’exécution de PaddleOCR-VL sur Novita AI ?
Novita AI propose une tarification à l’usage. Vous ne payez que pour le temps GPU que vous utilisez réellement, sans coûts initiaux ni engagements à long terme.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.




{kind=link}