

複数言語にわたる文書解析に悩んでいませんか?高額なインフラに投資せずに、テキスト、表、数式、グラフを複雑な文書から抽出する必要がありますか?
Novita AI GPUインスタンス上のPaddleOCR-VL がその答えです。この最先端のOCRソリューションは、わずか5分のセットアップでエンタープライズグレードの文書解析を提供します。複雑な設定、ハードウェア投資、面倒な手間は一切不要です。
109言語対応、手書きテキストや歴史的文書を含む複雑な要素の認識、そして高速な推論速度により、PaddleOCR-VLは従来のOCRシステムでは不可能だった正確性、効率性、汎用性を1つのコンパクトなパッケージで実現します。
👉 事前構成済みのGPUテンプレートを使ってPaddleOCR-VLを今すぐデプロイ
このステップバイステップガイドでは、Novita AI GPUインスタンスにPaddleOCR-VLをデプロイし、最初のOCR推論を実行し、すぐに文書処理を開始する方法を正確に説明します。請求書のデジタル化、研究論文の分析、フォームからのデータ抽出など、数分で本番環境で動作するソリューションが手に入ります。
PaddleOCR-VLとは?
PaddleOCR-VLは、文書解析専用に設計されたSOTA(最先端)でリソース効率の高い視覚言語モデルです。大量の計算リソースを消費したり、複雑なレイアウトに苦戦したりする従来のOCRシステムとは異なり、PaddleOCR-VLは最小限のリソース消費で卓越した精度を提供します。
PaddleOCR-VLの背後にあるテクノロジー
中核となるPaddleOCR-VL-0.9Bは、以下を組み合わせています:
- 正確な画像処理のためのNaViTスタイルの動的解像度視覚エンコーダ
- インテリジェントなテキスト理解のためのERNIE-4.5-0.3B言語モデル
- 高速で効率的な推論のためのコンパクトなアーキテクチャ(0.9Bパラメータ)
この革新的な統合により、モデルは高価なGPUハードウェアや長時間の処理を必要とせずに、109言語にわたる複雑な文書要素(テキスト、表、数式、グラフ)を認識できます。
実証されたパフォーマンス
広く使用されている公開ベンチマークと社内テストでの包括的な評価を通じて、PaddleOCR-VLはページレベルの文書解析と要素レベルの認識の両方でSOTAパフォーマンスを達成しています。このモデルは既存のパイプラインベースのソリューションを大幅に上回り、トップクラスの視覚言語モデル(VLM)に対して強い競争力を示しており、本番環境での頼りになる選択肢となっています。
なぜ文書解析にPaddleOCR-VLを選ぶのか?
1. コンパクトでありながら強力なアーキテクチャ
リソース効率と高性能の両立。 PaddleOCR-VLの新しい視覚言語アーキテクチャは、リソース効率の高い推論のために特別に設計されており、優れた要素認識結果を達成します。
NaViTスタイルの動的高解像度視覚エンコーダと軽量なERNIE-4.5-0.3B言語モデルの統合により、認識能力と復号効率が大幅に向上します。計算要件を抑えながら高精度を実現し、費用対効果の高い実用的な文書処理アプリケーションに最適です。
2. 複雑な文書に対するSOTAパフォーマンス
最も重要な場面で最高クラスの精度。 PaddleOCR-VLは以下で最先端のパフォーマンスを達成します:
- ページレベル文書解析:文書全体の理解と構造認識
- 要素レベル認識:個々のコンポーネントの正確な抽出
このモデルは、従来のOCRシステムを悩ませる挑戦的なコンテンツの認識に優れています:
- ✅ セル結合やネスト構造を含む複雑な表
- ✅ 数式や方程式
- ✅ グラフ、チャート、図表
- ✅ さまざまなスタイルの手書きテキスト
- ✅ 品質が低下した歴史的文書
- ✅ 多言語が混在した文書
この汎用性により、PaddleOCR-VLは遭遇するあらゆる文書タイプやシナリオに適しています。
3. 広範な多言語対応(109言語)
真のグローバルリーチ。 PaddleOCR-VLは109言語をサポートしており、以下を含みます:
- 主要なグローバル言語:中国語、英語、日本語、韓国語、ラテン語
- 多様な文字体系:ロシア語(キリル文字)、アラビア語、ヒンディー語(デーヴァナーガリー)、タイ語
- 地域言語:その他多数
この広範な言語カバレッジにより、多言語・グローバルな文書処理シナリオへのシステムの適用性が大幅に向上します。ツールやモデルを切り替えることなく、あらゆる市場、あらゆる地域、あらゆる言語の文書を処理できます。
4. 高速な推論速度
時間は金なり。 PaddleOCR-VLは高速な推論速度を提供し、実世界のシナリオでの実用的な展開に非常に適しています。コンパクトな0.9Bパラメータモデルは、精度を犠牲にすることなく文書を迅速に処理し、高スループットの文書処理ワークフローを可能にします。
Novita AIにPaddleOCR-VLをデプロイする方法(5分ガイド)
Novita AI GPUインスタンスにPaddleOCR-VLをデプロイする準備はできましたか?以下の8つの簡単なステップに従って、SOTA OCRサービスを数分で稼働させましょう。
ステップ1:PaddleOCR-VLテンプレートにアクセス
PaddleOCR-VL GPUテンプレート に直接アクセスできます。
ステップ2:GPUインスタンスを構成する
処理要件に合わせてインフラストラクチャパラメータを設定します:
- メモリ割り当て:ワークロードに基づいてRAM容量を選択
- ストレージ要件:モデルファイルと処理用のディスク容量を割り当て
- ネットワーク設定:APIアクセス用の接続を構成
デプロイを選択して構成を実装します。
プロのヒント:標準的な文書処理ワークロードには推奨設定から始め、必要に応じてスケーリングしてください。
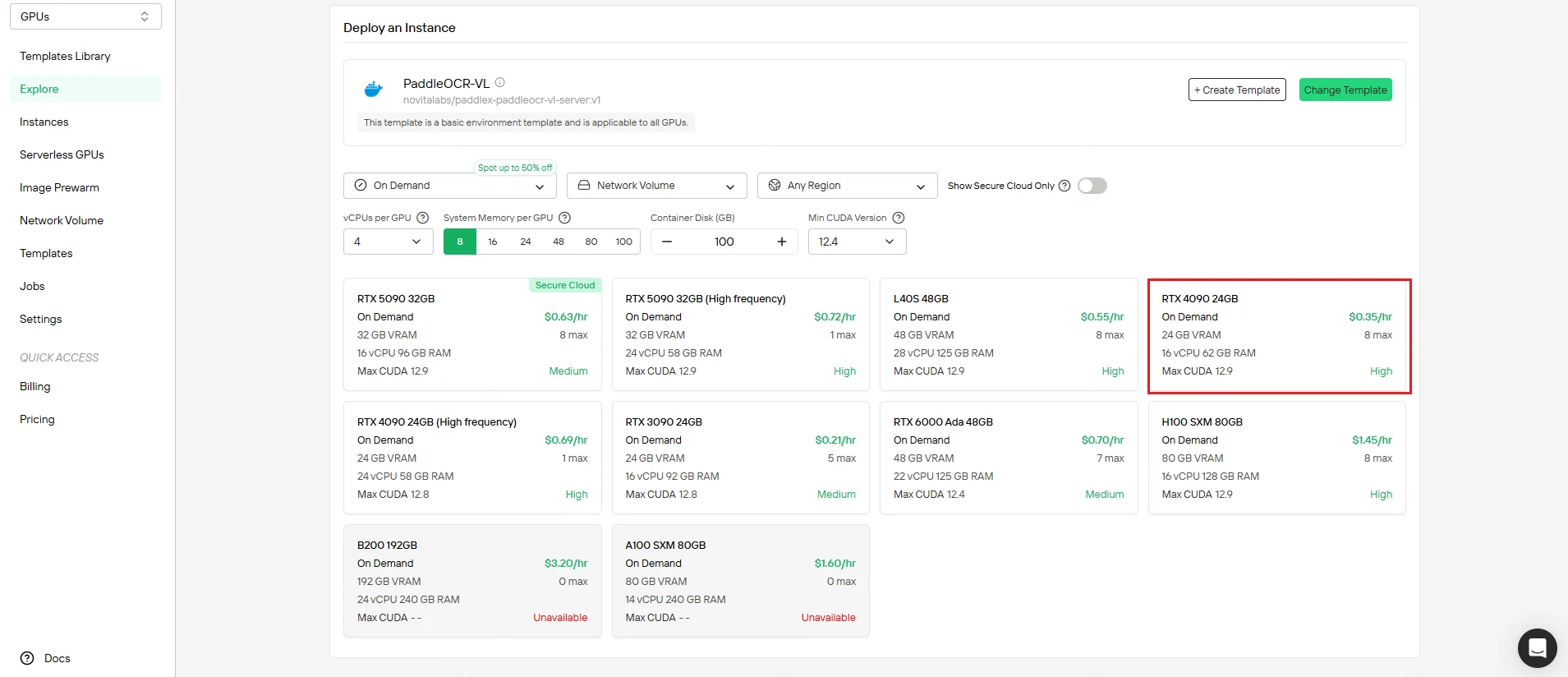
ステップ3:構成を確認してデプロイ
デプロイ前に設定を再確認してください:
- 計算リソースが要件を満たしていることを確認
- コスト概要を確認して予算に合致しているか確認
- ネットワークとストレージの構成を確認
満足したら、デプロイをクリックして作成プロセスを開始します。Novita AIがバックエンドの複雑な処理をすべて自動的に処理します。
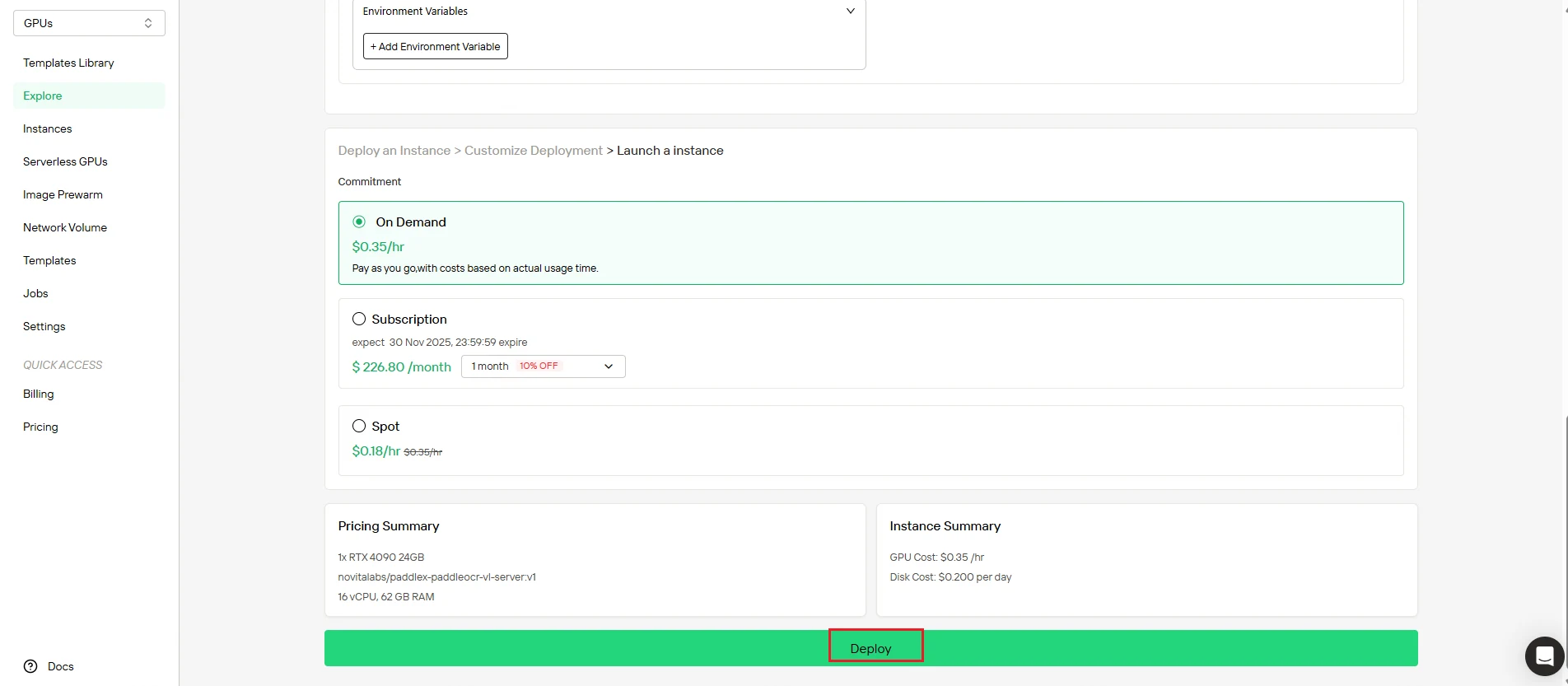
ステップ4:インスタンス作成を監視
デプロイを開始すると、システムが自動的にインスタンス管理ページにリダイレクトします。インスタンスはバックグラウンドで作成されます。手動での介入は不要です。
ダッシュボードからリアルタイムで進行状況を追跡します。
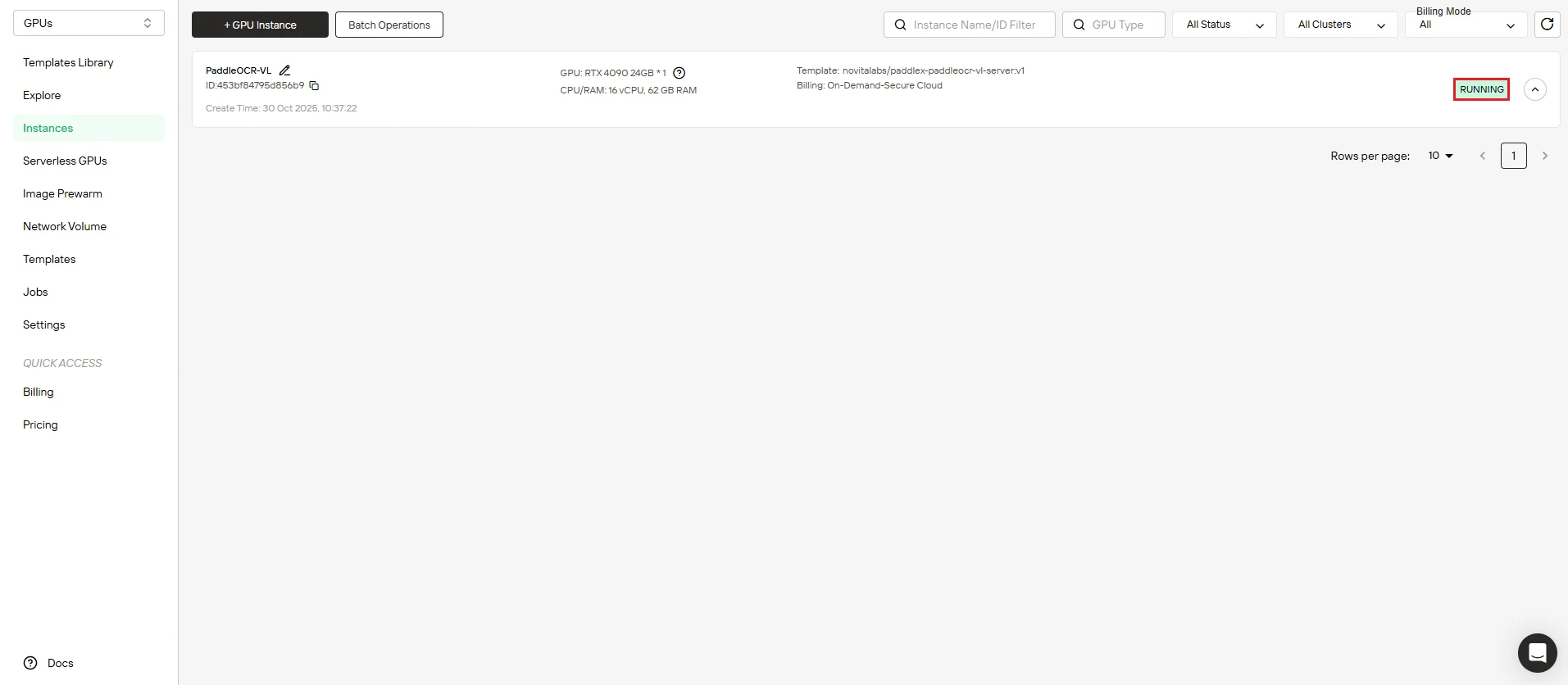
ステップ5:イメージダウンロードの進行状況を追跡
インスタンスがオンラインになるのを見守ります。 ダッシュボードにはPaddleOCR-VLイメージのダウンロードのリアルタイム進行状況が表示されます。デプロイが正常に完了すると、インスタンスステータスが “Pulling” から “Running” に遷移します。
インスタンス名の横にある矢印アイコンをクリックすると、詳細な進行状況とデプロイログが表示されます。
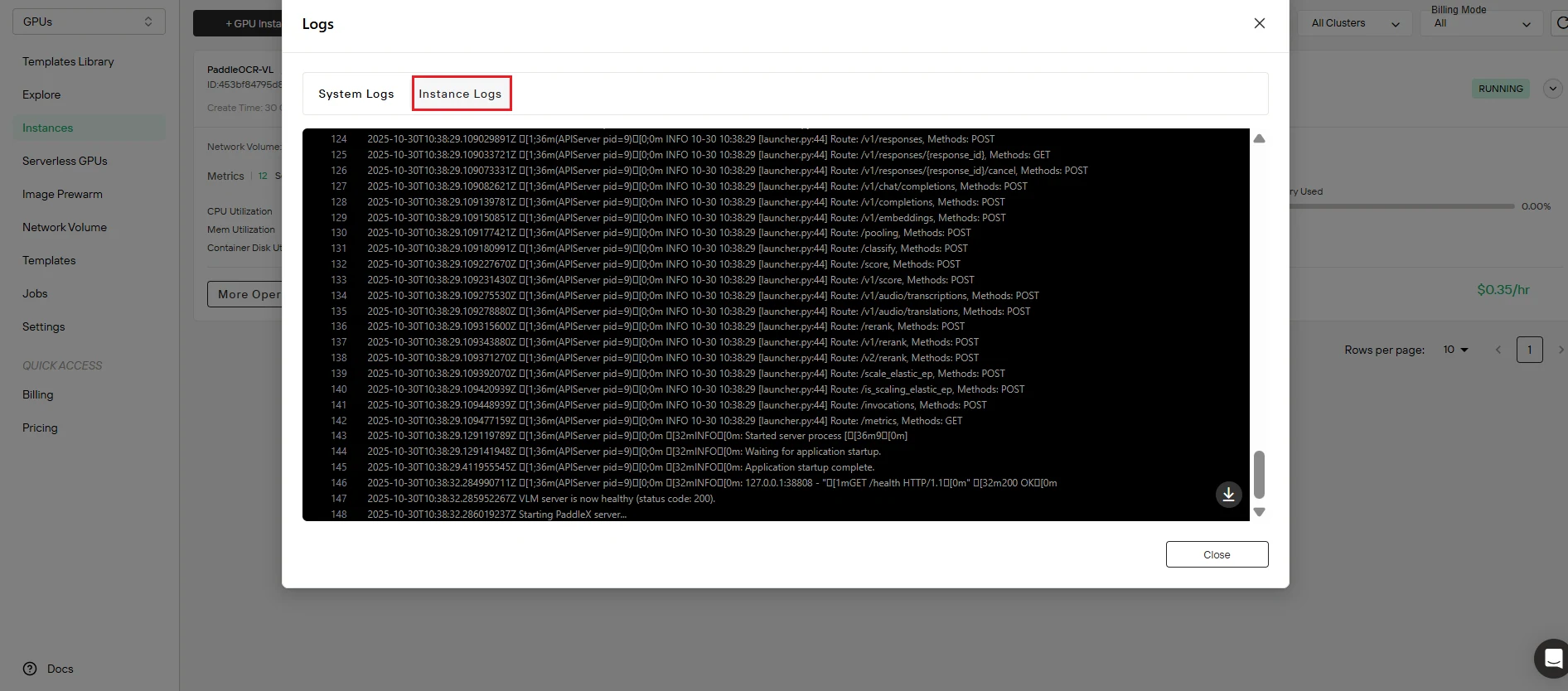
ステップ6:サービスのステータスを確認
デプロイの成功を確認します。 ログボタンをクリックしてインスタンスログにアクセスし、PaddleOCR-VLサービスが正常に起動したことを確認します。以下の確認メッセージを探します:
- サービス起動完了
- APIエンドポイントがアクティブでリッスン中
- モデルが正常にロードされました
ステップ7:開発環境にアクセス
ワークスペースを起動します。 接続インターフェースに移動し、Webターミナルを起動を初期化して、インスタンスへのコマンドラインアクセスを取得します。
🎉 おめでとうございます! PaddleOCR-VLサービスが完全に稼働し、OCRリクエストを処理する準備が整いました。所要時間:約5分です。
最初のOCR推論を実行する
Novita AI GPUでPaddleOCR-VLインスタンスが実行されているので、最初の文書を処理しましょう。このデモでは、画像の準備から結果の抽出までの完全なワークフローを示します。
ステップ1:Pythonテストスクリプトを作成
以下のコードで test.py というファイルを作成します:
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
このスクリプトの動作:
- 画像をBase64形式にエンコード
- PaddleOCR-VL APIエンドポイントに送信
- 構造化された解析結果を受信
- 抽出されたコンテンツをMarkdownドキュメントとして保存
- 埋め込み画像を個別のファイルにエクスポート
ステップ2:テスト画像をダウンロード
最初の推論には公式のPaddleOCRテストケースを使用します:
bash
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
これにより、OCRセットアップをテストするためのサンプル文書画像(book.jpg)がダウンロードされます。公式テストファイルはこちらから入手できます:PaddleOCR GitHubリポジトリ
ステップ3:APIエンドポイントを設定
スクリプトを正しいエンドポイントで更新します:
- Novita AIインスタンスダッシュボードからポートマッピングアドレスをコピー
test.pyのhttp://localhost:8080/layout-parsingを実際のAPIエンドポイントURLに置き換え
例:エンドポイントは http://your-instance-id.novita.ai:8080/layout-parsing のようになります。
ステップ4:OCR処理を実行
テストスクリプトを実行します:
bash
python test.py
期待される出力:
- コンソールに抽出されたテキスト構造が表示
- Markdownドキュメントは
markdown_0/doc.mdに保存 - 埋め込み画像は個別のファイルに抽出
- 出力ファイルの場所を示す確認メッセージ
これで完了です! Novita AI GPUインスタンスでPaddleOCR-VLを使った最初の文書処理に成功しました。
実際のユースケース
Novita AI GPUインスタンスにPaddleOCR-VLをデプロイして、多様な文書処理ワークフローを強化します:
金融サービス
- 請求書処理:明細行、合計額、ベンダー情報を抽出
- 領収書のデジタル化:経費報告と照合を自動化
- 銀行明細書の解析:明細書を構造化データに変換
学術・研究
- 研究論文の分析:出版物からテキスト、数式、表を抽出
- 教科書のデジタル化:教育資料を検索可能な形式に変換
- 歴史的文書の保存:品質の低下したテキストのアーカイブをデジタル化
法務・コンプライアンス
- 契約書分析:条項、条件、署名を抽出
- 規制文書処理:コンプライアンス提出書類やレポートを解析
- 法的発見:訴訟文書を検索可能なテキストに変換
ヘルスケア
- 医療記録のデジタル化:患者カルテを構造化データに変換
- 処方箋処理:フォームから医薬品情報を抽出
- 保険請求解析:請求書文書処理を自動化
Eコマース・小売
- 製品カタログ抽出:サプライヤーデータシートと仕様書を解析
- 多言語製品説明:国際カタログを処理
- 在庫文書処理:在庫リストとマニフェストをデジタル化
政府サービス
- フォーム処理:市民サービス文書の取り扱いを自動化
- 身分証明書検証:身分証明書から情報を抽出
- 許可証・ライセンス処理:申請書類を解析
109言語対応と複雑な要素認識により、PaddleOCR-VLは多様な文書タイプを扱うグローバル組織に最適です。
結論
Novita AI GPUインスタンスにPaddleOCR-VLを5分でデプロイし、インフラの複雑さを気にすることなく、最先端の文書解析機能を活用できます。SOTAパフォーマンス、109言語対応、効率的なリソース使用により、強力かつ実用的なエンタープライズグレードのOCRが実現します。
主なポイント:
✅ 5分でデプロイ可能な事前構成済みテンプレート
✅ テキスト、表、数式、グラフに対するSOTA精度
✅ グローバル文書処理のための109言語
✅ 手書き文書や歴史的文書を含む複雑な要素認識
✅ 高スループットワークフローのための高速推論
✅ コンパクトな0.9Bパラメータモデルによるリソース効率
請求書の処理、研究論文のデジタル化、法務文書の分析、多言語コンテンツの処理など、PaddleOCR-VL on Novita AIは初日から本番環境で使える結果を提供します。
文書ワークフローを変革する準備はできましたか?
複雑なOCRセットアップに時間を取られないでください。 今すぐNovita AI GPUインスタンスにPaddleOCR-VLをデプロイし、数時間ではなく数分で文書処理を始めましょう。
👉 PaddleOCR-VL GPUテンプレートを今すぐデプロイ
すべての依存関係と最適化が含まれた事前構成済みのPaddleOCR-VLテンプレートに即座にアクセスできます。クリックして構成し、デプロイするだけで、SOTA OCRサービスが5分で稼働します。
何千人もの開発者がNovita AIを選ぶ理由:
- インフラ管理が不要
- 前払い金なしの従量課金制
- 即時デプロイ可能な事前構成済みテンプレート
- オンデマンドでスケーラブルなGPUリソース
- 年中無休のサポートと包括的なドキュメント
今すぐデプロイを開始してください。最初のOCR推論まであと5分です。
よくある質問
PaddleOCR-VLをNovita AIにデプロイするのにどのくらい時間がかかりますか?
テンプレート選択からインスタンス実行まで約5分です。
PaddleOCR-VLはどの言語をサポートしていますか?
中国語、英語、日本語、韓国語、ロシア語、アラビア語、ヒンディー語、タイ語など109言語に対応しています。
PaddleOCR-VLは手書きテキストを認識できますか?
はい、PaddleOCR-VLは手書きテキストや品質が低下した歴史的文書の認識に優れています。
PaddleOCR-VLはどのような文書要素を抽出できますか?
テキスト、表、数式、グラフ、その他の複雑な文書要素を抽出できます。
Novita AIにデプロイするにはGPUの経験が必要ですか?
いいえ、事前構成済みテンプレートがすべての技術設定を自動的に処理します。PaddleOCR-VL GPUテンプレート のリンクをクリックして、簡単な手順に従うだけです。
Novita AIでPaddleOCR-VLを実行するのにどれくらいの費用がかかりますか?
Novita AIは従量課金制を提供しています。実際に使用したGPU時間に対してのみ支払い、前払い金や長期契約は不要です。
Novita AIは、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃な価格で信頼性の高いGPUクラウドを提供して、構築とスケーリングを支援します。




{kind=link}