

¿Tienes problemas para analizar documentos en varios idiomas? ¿Necesitas extraer texto, tablas, fórmulas y gráficos de documentos complejos sin invertir en infraestructura costosa?
PaddleOCR-VL en una instancia GPU de Novita AI es tu solución. Esta solución OCR de última generación ofrece análisis de documentos de nivel empresarial con solo 5 minutos de configuración: sin configuración compleja, sin inversión en hardware, sin complicaciones.
Con soporte para 109 idiomas, reconocimiento de elementos complejos como texto manuscrito y documentos históricos, y velocidades de inferencia rápidas, PaddleOCR-VL logra lo que los sistemas OCR tradicionales no pueden: precisión, eficiencia y versatilidad en un solo paquete compacto.
👉 Empieza a desplegar PaddleOCR-VL ahora con nuestra plantilla GPU preconfigurada.
Esta guía paso a paso te muestra exactamente cómo desplegar PaddleOCR-VL en una instancia GPU de Novita AI, ejecutar tu primera inferencia OCR y empezar a procesar documentos de inmediato. Ya sea que estés digitalizando facturas, analizando documentos de investigación o extrayendo datos de formularios, tendrás una solución lista para producción en cuestión de minutos.
¿Qué es PaddleOCR-VL?
PaddleOCR-VL es un modelo de lenguaje y visión de última generación (SOTA) y eficiente en recursos diseñado específicamente para el análisis de documentos. A diferencia de los sistemas OCR tradicionales que consumen enormes recursos computacionales o tienen dificultades con diseños complejos, PaddleOCR-VL ofrece una precisión excepcional mientras mantiene un consumo mínimo de recursos.
La tecnología detrás de PaddleOCR-VL
En esencia, PaddleOCR-VL-0.9B combina:
- Codificador visual de resolución dinámica estilo NaViT para un procesamiento preciso de imágenes
- Modelo de lenguaje ERNIE-4.5-0.3B para una comprensión inteligente del texto
- Arquitectura compacta (0.9 mil millones de parámetros) para una inferencia rápida y eficiente
Esta integración innovadora permite al modelo reconocer elementos complejos de documentos (texto, tablas, fórmulas, gráficos) en 109 idiomas sin requerir hardware GPU costoso ni tiempos de procesamiento prolongados.
Rendimiento probado
A través de evaluaciones exhaustivas en pruebas de referencia públicas ampliamente utilizadas y pruebas internas, PaddleOCR-VL logra un rendimiento SOTA tanto en el análisis de documentos a nivel de página como en el reconocimiento a nivel de elementos. El modelo supera significativamente a las soluciones existentes basadas en pipelines y muestra una fuerte competitividad frente a modelos de lenguaje y visión (VLM) de primer nivel, lo que lo convierte en la opción ideal para entornos de producción.
¿Por qué elegir PaddleOCR-VL para el análisis de documentos?
1. Arquitectura compacta pero potente
Eficiencia de recursos combinada con alto rendimiento. La novedosa arquitectura de lenguaje y visión de PaddleOCR-VL está diseñada específicamente para una inferencia eficiente en recursos mientras logra resultados sobresalientes en el reconocimiento de elementos.
La integración de un codificador visual de alta resolución dinámica estilo NaViT con el modelo de lenguaje ligero ERNIE-4.5-0.3B mejora significativamente las capacidades de reconocimiento y la eficiencia de decodificación. Obtienes alta precisión con demandas computacionales reducidas, perfecto para aplicaciones de procesamiento de documentos rentables y prácticas.
2. Rendimiento SOTA en documentos complejos
Precisión de primer nivel donde más importa. PaddleOCR-VL logra un rendimiento de última generación en:
- Análisis de documentos a nivel de página: comprensión completa del documento y reconocimiento de la estructura
- Reconocimiento a nivel de elementos: extracción precisa de componentes individuales
El modelo destaca en el reconocimiento de contenido desafiante que desconcierta a los sistemas OCR tradicionales:
- ✅ Tablas complejas con celdas fusionadas y estructuras anidadas
- ✅ Fórmulas matemáticas y ecuaciones
- ✅ Gráficos, diagramas y esquemas
- ✅ Texto manuscrito con estilos variados
- ✅ Documentos históricos con calidad degradada
- ✅ Documentos con varios idiomas
Esta versatilidad hace que PaddleOCR-VL sea adecuado para prácticamente cualquier tipo de documento o escenario que encuentres.
3. Amplio soporte multilingüe (109 idiomas)
Alcance verdaderamente global. PaddleOCR-VL admite 109 idiomas, que incluyen:
- Idiomas globales principales: chino, inglés, japonés, coreano, latín
- Escrituras diversas: ruso (cirílico), árabe, hindi (devanagari), tailandés
- Idiomas regionales: y muchos más
Esta amplia cobertura de idiomas aumenta sustancialmente la aplicabilidad del sistema para escenarios de procesamiento de documentos multilingües y globalizados. Procesa documentos de cualquier mercado, región o idioma sin cambiar de herramientas o modelos.
4. Velocidades de inferencia rápidas
El tiempo es dinero. PaddleOCR-VL ofrece velocidades de inferencia rápidas que lo hacen muy adecuado para el despliegue práctico en escenarios del mundo real. El modelo compacto de 0.9 mil millones de parámetros procesa documentos rápidamente sin sacrificar la precisión, lo que permite flujos de trabajo de procesamiento de documentos de alto rendimiento.
Cómo desplegar PaddleOCR-VL en Novita AI (Guía de 5 minutos)
¿Listo para desplegar PaddleOCR-VL en una instancia GPU de Novita AI? Sigue estos 8 sencillos pasos para tener tu servicio OCR SOTA funcionando en minutos.
Paso 1: Ve a la plantilla de PaddleOCR-VL
Puedes acceder directamente a la Plantilla GPU de PaddleOCR-VL.
Paso 2: Configura tu instancia GPU
Establece los parámetros de infraestructura según tus requisitos de procesamiento:
- Asignación de memoria: elige la capacidad de RAM según la carga de trabajo
- Requisitos de almacenamiento: asigna espacio en disco para los archivos del modelo y el procesamiento
- Configuración de red: configura la conectividad para el acceso a la API
Selecciona Desplegar para implementar tu configuración.
Consejo profesional: comienza con la configuración recomendada para cargas de trabajo típicas de procesamiento de documentos y luego escala según sea necesario.
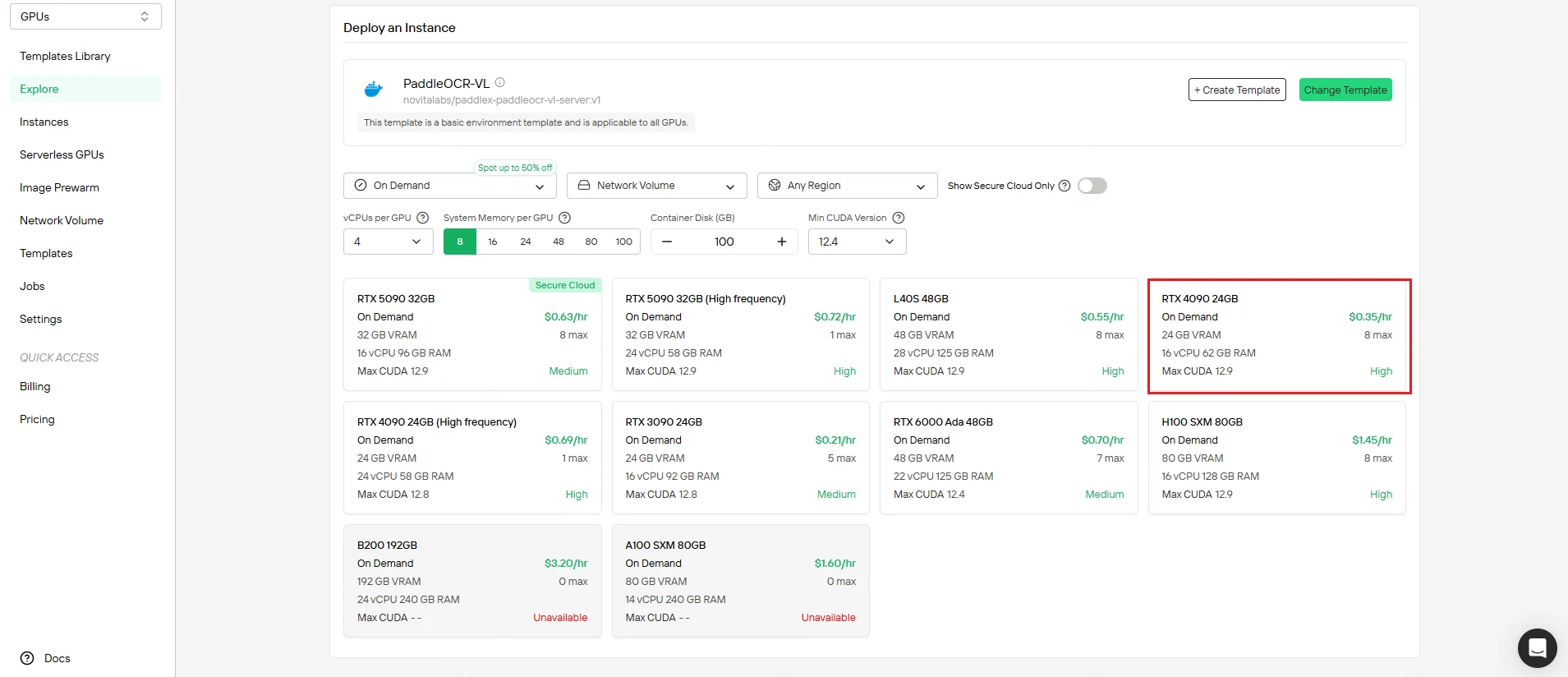
Paso 3: Revisa la configuración y despliega
Verifica dos veces tu configuración antes del despliegue:
- Verifica que los recursos de cómputo coincidan con tus requisitos
- Revisa el resumen de costos para asegurarte de que se ajuste al presupuesto
- Confirma las configuraciones de red y almacenamiento
Cuando estés satisfecho, haz clic en Desplegar para iniciar el proceso de creación. Novita AI maneja automáticamente toda la complejidad del backend.
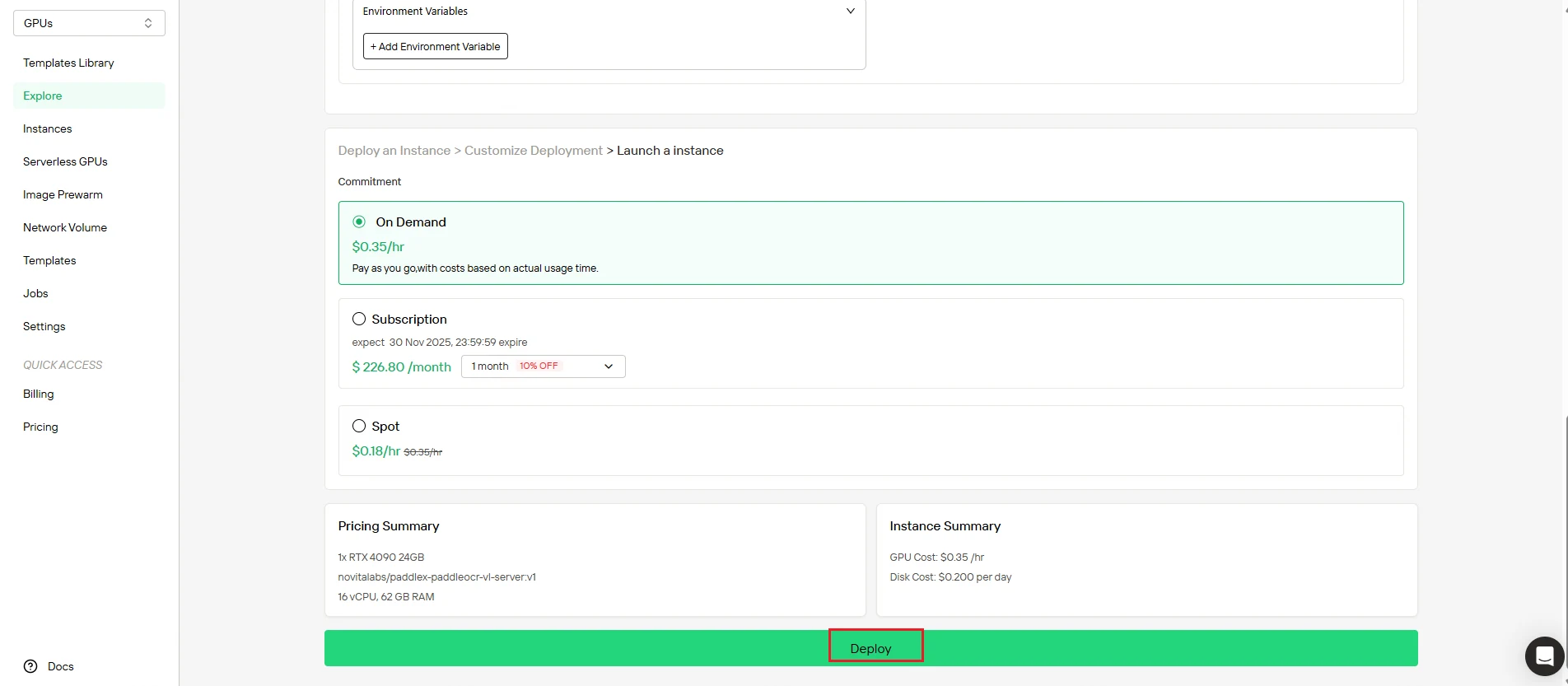
Paso 4: Monitorea la creación de la instancia
Tras iniciar el despliegue, el sistema te redirige automáticamente a la página de gestión de instancias. Tu instancia se crea en segundo plano, sin intervención manual.
Sigue el progreso en tiempo real desde el panel de control.
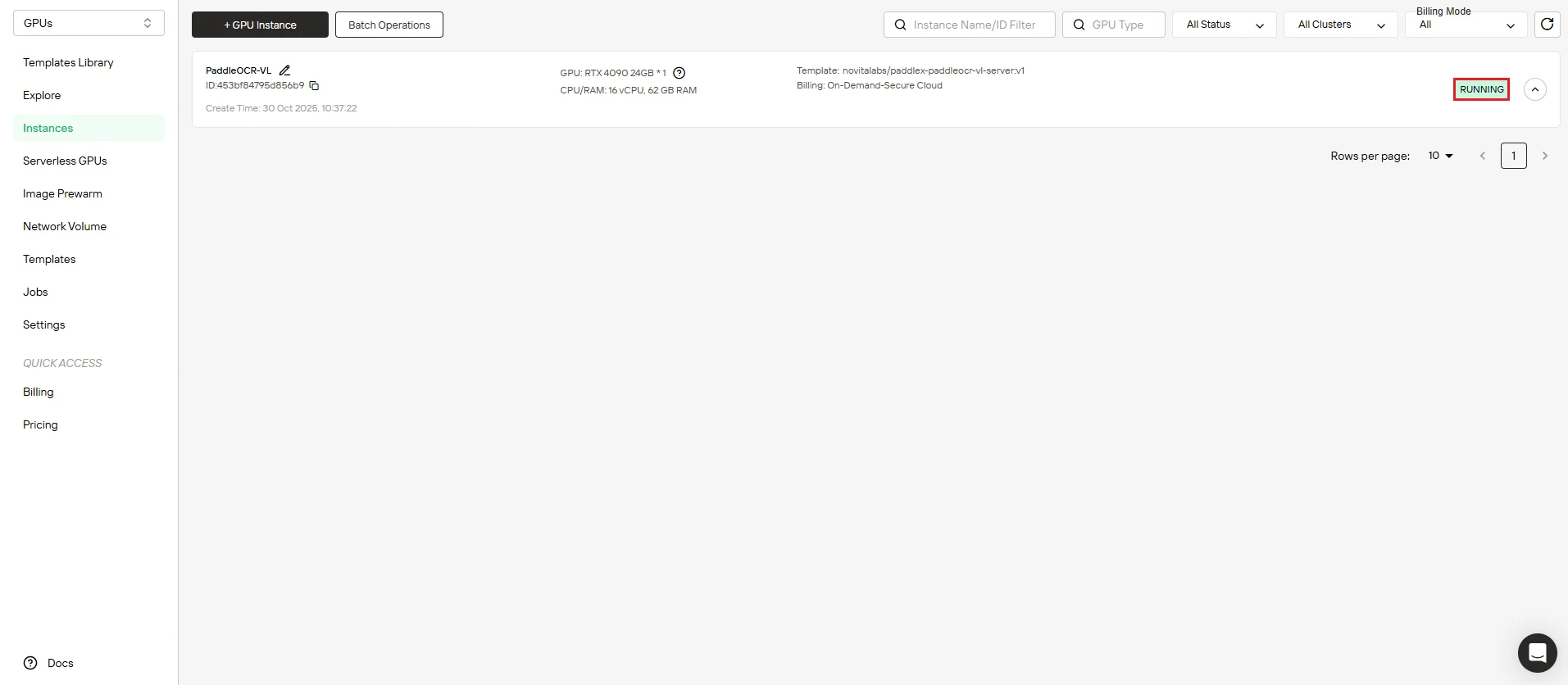
Paso 5: Sigue el progreso de la descarga de la imagen
Observa cómo tu instancia se activa. El panel de control muestra el progreso en tiempo real de la descarga de la imagen de PaddleOCR-VL. El estado de tu instancia pasa de “Extrayendo” a “Ejecutándose” una vez que el despliegue se completa correctamente.
Haz clic en el icono de flecha junto al nombre de tu instancia para ver información detallada del progreso y los registros de despliegue.
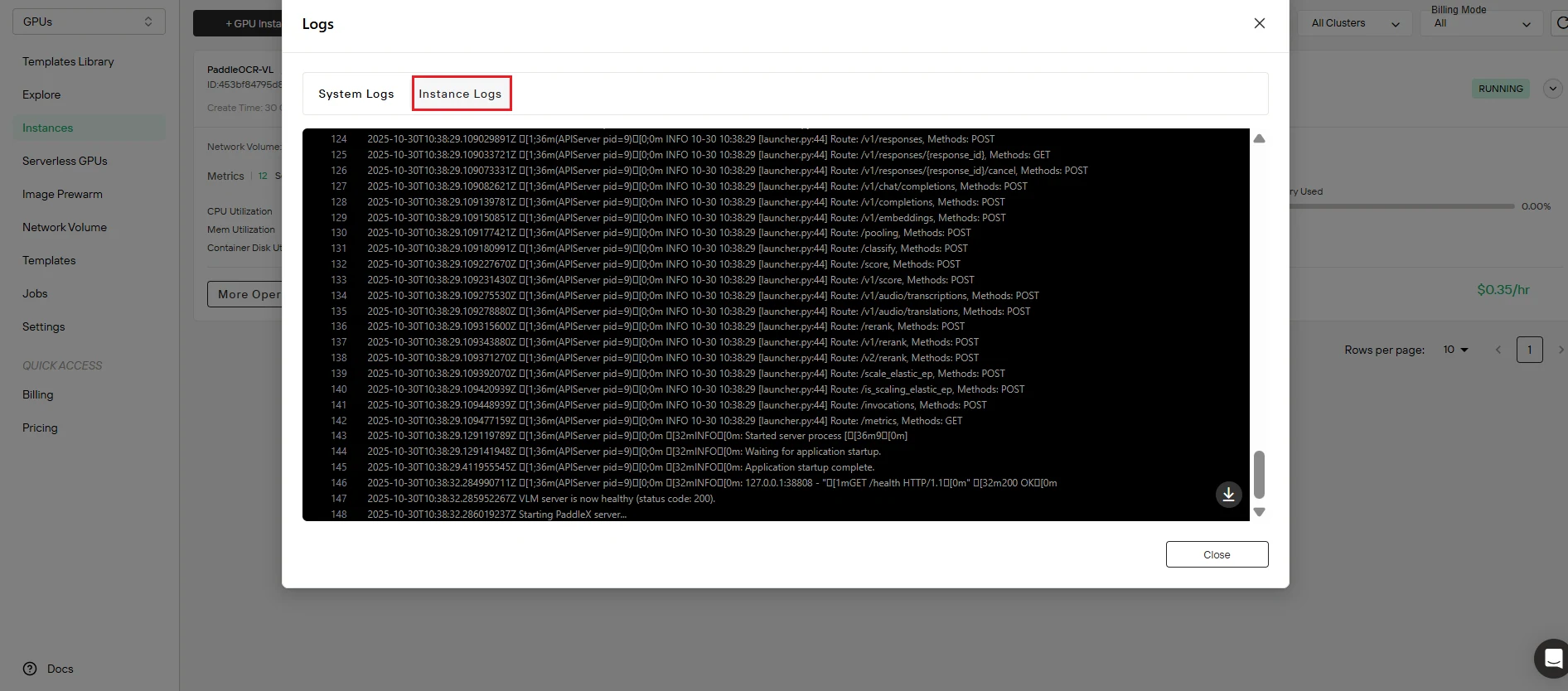
Paso 6: Verifica el estado del servicio
Confirma que el despliegue fue exitoso. Haz clic en el botón Registros para acceder a los registros de la instancia y verificar que el servicio de PaddleOCR-VL se haya iniciado correctamente. Busca mensajes de inicialización que confirmen:
- Finalización del lanzamiento del servicio
- Punto final de la API activo y a la escucha
- Modelo cargado correctamente
Paso 7: Accede al entorno de desarrollo
Inicia tu espacio de trabajo. Navega a la interfaz Conectar e inicia Iniciar terminal web para obtener acceso de línea de comandos a tu instancia.
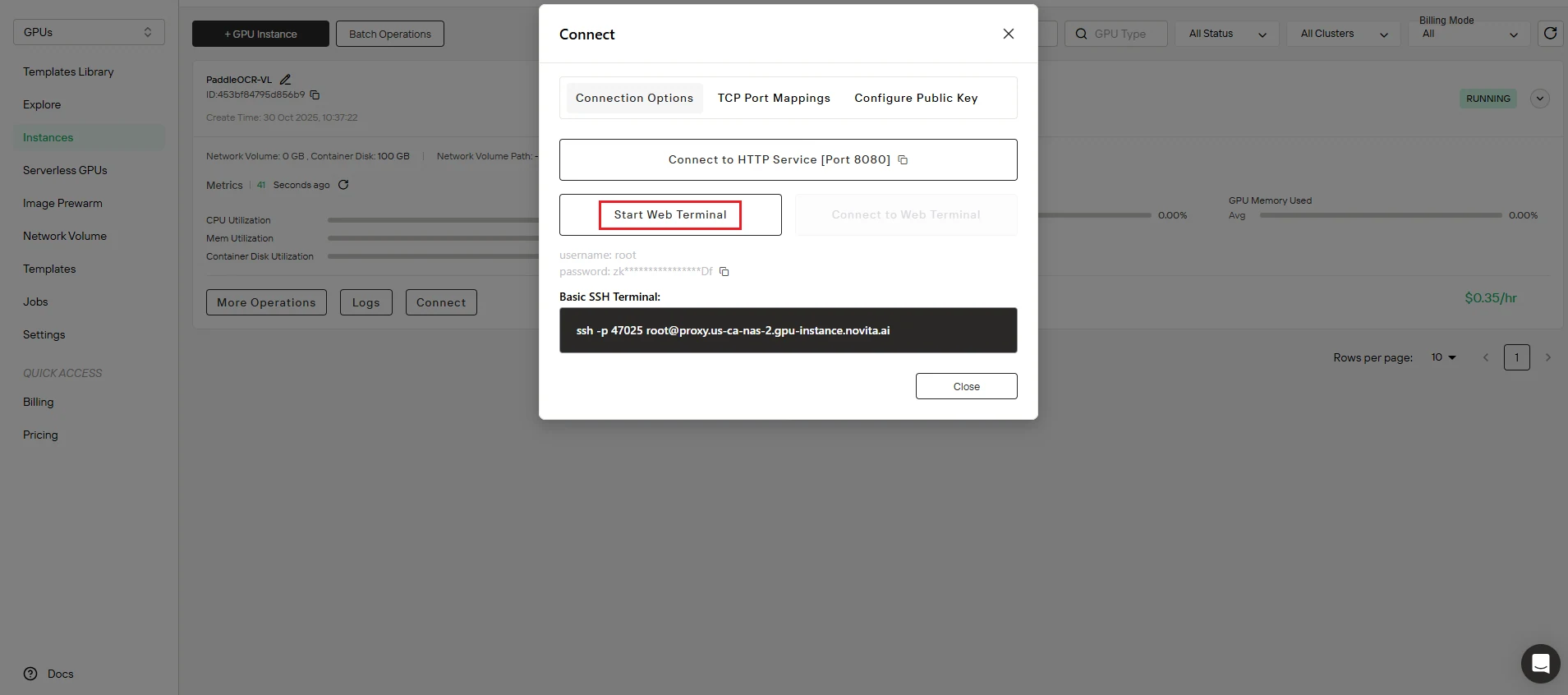
🎉 ¡Felicidades! Tu servicio de PaddleOCR-VL ya está completamente operativo y listo para procesar solicitudes OCR. Tiempo total: aproximadamente 5 minutos.
Ejecutando tu primera inferencia OCR
Ahora que tu instancia de PaddleOCR-VL se está ejecutando en la GPU de Novita AI, procesemos tu primer documento. Esta demo muestra el flujo de trabajo completo, desde la preparación de la imagen hasta la extracción de resultados.
Paso 1: Crea un script de prueba en Python
Crea un archivo llamado test.py con el siguiente código:
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # URL del servicio
image_path = "./demo.jpg"
# Codifica la imagen local a Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Contenido del archivo codificado en Base64 o URL del archivo
"fileType": 1, # Tipo de archivo, 1 significa archivo de imagen
}
# Llama a la API
response = requests.post(API_URL, json=payload)
# Procesa los datos de respuesta de la API
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Documento Markdown guardado en {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Imagen de salida guardada en {img_path}")
Lo que hace este script:
- Codifica tu imagen al formato Base64
- La envía al punto final de la API de PaddleOCR-VL
- Recibe resultados estructurados del análisis
- Guarda el contenido extraído como documentos Markdown
- Exporta las imágenes incrustadas
Paso 2: Descarga una imagen de prueba
Usa el caso de prueba oficial de PaddleOCR para tu primera inferencia:
bash
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
Esto descarga una imagen de documento de muestra (book.jpg) para probar tu configuración OCR. El archivo de prueba oficial está disponible en: Repositorio de GitHub de PaddleOCR
Paso 3: Configura el punto final de la API
Actualiza tu script con el punto final correcto:
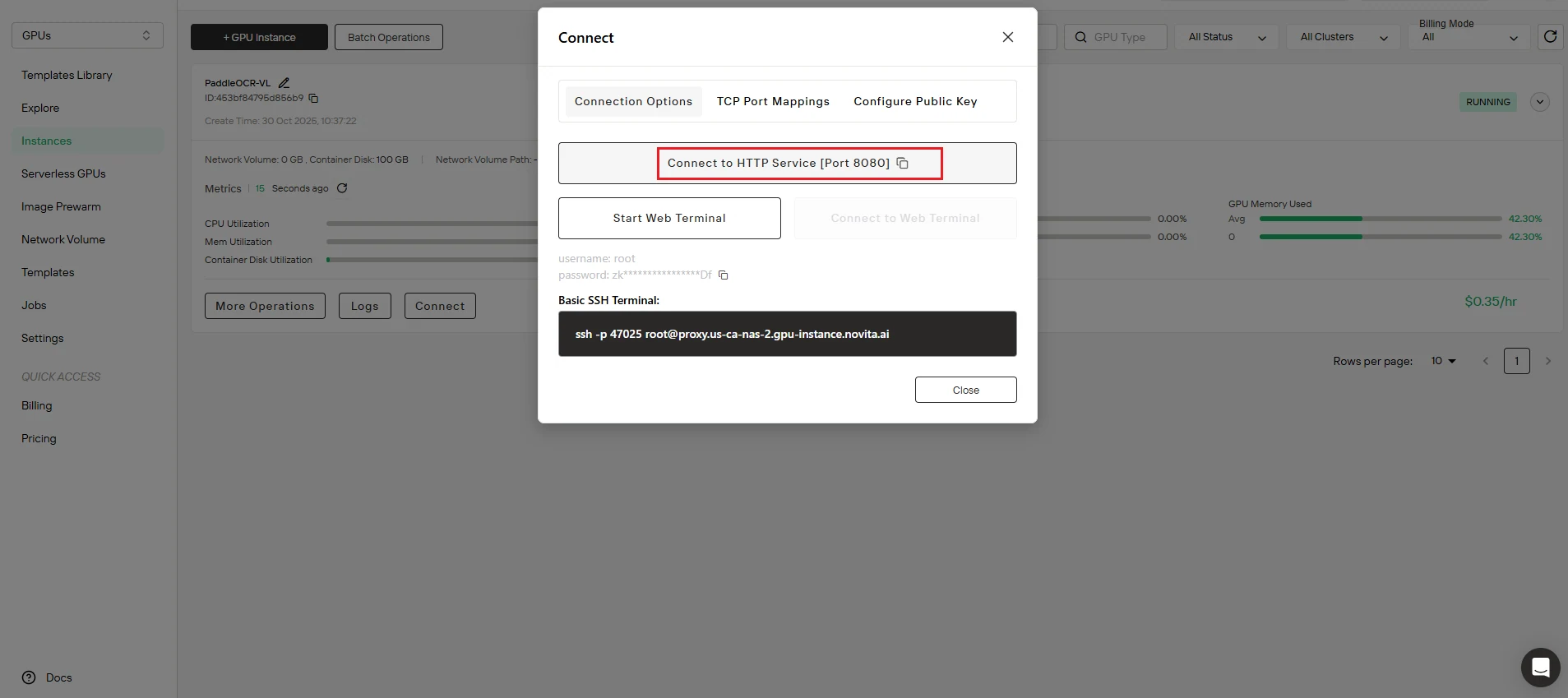
- Copia la dirección de mapeo de puertos desde el panel de control de tu instancia de Novita AI
- Reemplaza
http://localhost:8080/layout-parsingentest.pycon la URL real de tu punto final de API
Ejemplo: tu punto final podría verse como http://tu-id-de-instancia.novita.ai:8080/layout-parsing
Paso 4: Ejecuta el procesamiento OCR
Ejecuta tu script de prueba:
bash
python test.py
Salida esperada:
- La consola muestra la estructura de texto extraída
- Documentos Markdown guardados en
markdown_0/doc.md - Imágenes incrustadas extraídas en archivos separados
- Mensajes de confirmación que muestran las ubicaciones de los archivos de salida
¡Eso es todo! Has procesado con éxito tu primer documento con PaddleOCR-VL en una instancia GPU de Novita AI.
Aplicaciones del mundo real
Despliega PaddleOCR-VL en una instancia GPU de Novita AI para potenciar diversos flujos de trabajo de procesamiento de documentos:
Servicios financieros
- Procesamiento de facturas: extrae líneas de pedido, totales, información del proveedor
- Digitalización de recibos: automatiza informes de gastos y conciliaciones
- Análisis de extractos bancarios: convierte extractos en datos estructurados
Académico e investigación
- Análisis de documentos de investigación: extrae texto, fórmulas, tablas de publicaciones
- Digitalización de libros de texto: convierte materiales educativos a formatos buscables
- Preservación de documentos históricos: digitaliza archivos con calidad de texto degradada
Legal y cumplimiento
- Análisis de contratos: extrae cláusulas, términos, firmas
- Procesamiento de documentos regulatorios: analiza presentaciones de cumplimiento e informes
- Descubrimiento legal: convierte documentos de casos en texto buscable
Salud
- Digitalización de registros médicos: convierte historias clínicas de pacientes en datos estructurados
- Procesamiento de recetas: extrae información de medicamentos de formularios
- Análisis de reclamaciones de seguros: automatiza el procesamiento de documentos de reclamaciones
Comercio electrónico y venta minorista
- Extracción de catálogos de productos: analiza fichas técnicas y especificaciones de proveedores
- Descripciones de productos multilingües: procesa catálogos internacionales
- Procesamiento de documentos de inventario: digitaliza listas de existencias y manifiestos
Servicios gubernamentales
- Procesamiento de formularios: automatiza la gestión de documentos para servicios ciudadanos
- Verificación de identidad: extrae información de documentos de identificación
- Procesamiento de permisos y licencias: analiza documentos de solicitud
El soporte para 109 idiomas y el reconocimiento de elementos complejos hacen de PaddleOCR-VL la opción ideal para organizaciones globales que manejan diversos tipos de documentos.
Conclusión
Despliega PaddleOCR-VL en una instancia GPU de Novita AI en 5 minutos y desbloquea capacidades de análisis de documentos de última generación sin la complejidad de la infraestructura. Con rendimiento SOTA, soporte para 109 idiomas y uso eficiente de recursos, obtienes un OCR de nivel empresarial que es potente y práctico.
Puntos clave:
✅ Despliegue en 5 minutos con plantillas preconfiguradas
✅ Precisión SOTA para texto, tablas, fórmulas y gráficos
✅ 109 idiomas para procesamiento global de documentos
✅ Reconocimiento de elementos complejos incluyendo texto manuscrito y documentos históricos
✅ Velocidades de inferencia rápidas para flujos de trabajo de alto rendimiento
✅ Eficiente en recursos con modelo compacto de 0.9 mil millones de parámetros
Ya sea que estés procesando facturas, digitalizando documentos de investigación, analizando documentos legales o manejando contenido multilingüe, PaddleOCR-VL en Novita AI ofrece resultados listos para producción desde el primer día.
¿Listo para transformar tu flujo de trabajo de documentos?
No dejes que la configuración compleja de OCR te retrase. Despliega PaddleOCR-VL en una instancia GPU de Novita AI hoy y comienza a procesar documentos en minutos, no en horas.
👉 Despliega la plantilla GPU de PaddleOCR-VL ahora
Obtén acceso instantáneo a la plantilla preconfigurada de PaddleOCR-VL con todas las dependencias y optimizaciones incluidas. Solo haz clic, configura y despliega: tu servicio OCR SOTA estará funcionando en 5 minutos.
Por qué miles de desarrolladores eligen Novita AI:
- Gestión de infraestructura cero
- Precios de pago por uso sin costos iniciales
- Plantillas preconfiguradas para despliegue instantáneo
- Recursos GPU escalables bajo demanda
- Soporte 24/7 y documentación completa
Comienza tu despliegue ahora—tu primera inferencia OCR está a solo 5 minutos de distancia.
Preguntas frecuentes
¿Cuánto tiempo se tarda en desplegar PaddleOCR-VL en Novita AI?
Aproximadamente 5 minutos desde la selección de la plantilla hasta que la instancia está en funcionamiento.
¿Qué idiomas admite PaddleOCR-VL?
109 idiomas, incluyendo chino, inglés, japonés, coreano, ruso, árabe, hindi, tailandés y muchos más.
¿Puede PaddleOCR-VL reconocer texto manuscrito?
Sí, PaddleOCR-VL destaca en el reconocimiento de texto manuscrito y documentos históricos con calidad degradada.
¿Qué tipos de elementos de documentos puede extraer PaddleOCR-VL?
Texto, tablas, fórmulas matemáticas, gráficos y otros elementos complejos de documentos.
¿Necesito experiencia con GPU para desplegar en Novita AI?
No, la plantilla preconfigurada maneja toda la configuración técnica automáticamente. Simplemente haz clic en el enlace de la Plantilla GPU de PaddleOCR-VL y sigue los sencillos pasos.
¿Cuánto cuesta ejecutar PaddleOCR-VL en Novita AI?
Novita AI ofrece precios de pago por uso. Solo pagas por el tiempo de GPU que realmente utilizas, sin costos iniciales ni compromisos a largo plazo.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA utilizando nuestra API simple, además de proporcionar computación en la nube GPU asequible y confiable para construir y escalar.




{kind=link}