

Haben Sie Schwierigkeiten beim Dokumentenparsing in mehreren Sprachen? Müssen Sie Text, Tabellen, Formeln und Diagramme aus komplexen Dokumenten extrahieren, ohne in teure Infrastruktur zu investieren?
PaddleOCR-VL auf Novita AI GPU-Instanz ist die Lösung. Diese moderne OCR-Lösung bietet ein unternehmensgerechtes Dokumentenparsing in nur 5 Minuten Einrichtungszeit – keine komplexe Konfiguration, keine Hardware-Investition, kein Aufwand.
Mit Unterstützung von 109 Sprachen, der Erkennung komplexer Elemente einschließlich handschriftlichem Text und historischen Dokumenten sowie schnellen Inferenzgeschwindigkeiten erreicht PaddleOCR-VL, was herkömmliche OCR-Systeme nicht können: Genauigkeit, Effizienz und Vielseitigkeit in einem kompakten Paket.
👉 Starten Sie jetzt die Bereitstellung von PaddleOCR-VL mit unserem vorkonfigurierten GPU-Template.
Diese Schritt-für-Schritt-Anleitung zeigt Ihnen genau, wie Sie PaddleOCR-VL auf einer Novita AI GPU-Instanz bereitstellen, Ihre erste OCR-Inferenz ausführen und sofort mit der Verarbeitung von Dokumenten beginnen. Egal, ob Sie Rechnungen digitalisieren, Forschungsarbeiten analysieren oder Daten aus Formularen extrahieren – Sie haben in wenigen Minuten eine produktionsbereite Lösung.
Was ist PaddleOCR-VL?
PaddleOCR-VL ist ein SOTA (State-of-the-Art) und ressourceneffizientes Vision-Language-Modell, das speziell für das Dokumentenparsing entwickelt wurde. Im Gegensatz zu herkömmlichen OCR-Systemen, die enorme Rechenressourcen verbrauchen oder mit komplexen Layouts Schwierigkeiten haben, liefert PaddleOCR-VL außergewöhnliche Genauigkeit bei minimalem Ressourcenverbrauch.
Die Technologie hinter PaddleOCR-VL
Im Kern kombiniert PaddleOCR-VL-0.9B:
- NaViT-artiger dynamischer Auflösungs-Visual-Encoder für genaue Bildverarbeitung
- ERNIE-4.5-0.3B Sprachmodell für intelligentes Textverständnis
- Kompakte Architektur (0,9 Milliarden Parameter) für schnelle, effiziente Inferenz
Diese innovative Integration ermöglicht es dem Modell, komplexe Dokumentelemente – Text, Tabellen, Formeln, Diagramme – in 109 Sprachen zu erkennen, ohne dass teure GPU-Hardware oder lange Verarbeitungszeiten erforderlich sind.
Nachgewiesene Leistung
Durch umfassende Bewertungen anhand weit verbreiteter öffentlicher Benchmarks und interner Tests erreicht PaddleOCR-VL SOTA-Leistung sowohl beim Dokumentenparsing auf Seitenebene als auch bei der elementweisen Erkennung. Das Modell übertrifft bestehende pipeline-basierte Lösungen deutlich und zeigt eine starke Wettbewerbsfähigkeit gegenüber erstklassigen Vision-Language-Modellen (VLMs), was es zur ersten Wahl für Produktionsumgebungen macht.
Warum PaddleOCR-VL für das Dokumentenparsing wählen?
1. Kompakte und dennoch leistungsstarke Architektur
Ressourceneffizienz trifft auf hohe Leistung. Die neuartige Vision-Language-Architektur von PaddleOCR-VL ist speziell für ressourceneffiziente Inferenz konzipiert und erzielt gleichzeitig herausragende Ergebnisse bei der Elementerkennung.
Die Integration eines NaViT-artigen dynamischen Hochauflösungs-Visual-Encoders mit dem leichtgewichtigen ERNIE-4.5-0.3B Sprachmodell verbessert die Erkennungsfähigkeiten und die Dekodierungseffizienz erheblich. Sie erhalten hohe Genauigkeit bei reduziertem Rechenaufwand – perfekt für kostengünstige, praktische Dokumentenverarbeitungsanwendungen.
2. SOTA-Leistung bei komplexen Dokumenten
Best-in-Class-Genauigkeit dort, wo es am wichtigsten ist. PaddleOCR-VL erreicht State-of-the-Art-Leistung bei:
- Dokumentenparsing auf Seitenebene: Vollständiges Dokumentverständnis und Strukturerkennung
- Elementweise Erkennung: Genaue Extraktion einzelner Komponenten
Das Modell zeichnet sich durch die Erkennung von anspruchsvollem Inhalt aus, der herkömmliche OCR-Systeme vor Probleme stellt:
- ✅ Komplexe Tabellen mit zusammengeführten Zellen und verschachtelten Strukturen
- ✅ Mathematische Formeln und Gleichungen
- ✅ Diagramme, Grafiken und Zeichnungen
- ✅ Handsichtlicher Text mit unterschiedlichen Schriftarten
- ✅ Historische Dokumente mit beeinträchtigter Qualität
- ✅ Mehrsprachige Dokumente
Diese Vielseitigkeit macht PaddleOCR-VL für praktisch jeden Dokumenttyp oder jedes Szenario geeignet, dem Sie begegnen.
3. Umfangreiche mehrsprachige Unterstützung (109 Sprachen)
Echte globale Reichweite. PaddleOCR-VL unterstützt 109 Sprachen, darunter:
- Wichtige globale Sprachen: Chinesisch, Englisch, Japanisch, Koreanisch, Latein
- Verschiedene Schriftsysteme: Russisch (Kyrillisch), Arabisch, Hindi (Devanagari), Thailändisch
- Regionale Sprachen: Und viele weitere
Diese breite Sprachabdeckung verbessert die Anwendbarkeit des Systems für mehrsprachige und globalisierte Dokumentenverarbeitungsszenarien erheblich. Verarbeiten Sie Dokumente aus jedem Markt, jeder Region, jeder Sprache – ohne Tools oder Modelle wechseln zu müssen.
4. Schnelle Inferenzgeschwindigkeiten
Zeit ist Geld. PaddleOCR-VL bietet schnelle Inferenzgeschwindigkeiten, die es für den praktischen Einsatz in realen Szenarien sehr geeignet machen. Das kompakte Modell mit 0,9 Milliarden Parametern verarbeitet Dokumente schnell, ohne Genauigkeit zu opfern, und ermöglicht so Dokumentenverarbeitungs-Workflows mit hohem Durchsatz.
So stellen Sie PaddleOCR-VL auf Novita AI bereit (5-Minuten-Anleitung)
Bereit, PaddleOCR-VL auf einer Novita AI GPU-Instanz bereitzustellen? Folgen Sie diesen 8 einfachen Schritten, um Ihren SOTA-OCR-Dienst in wenigen Minuten zum Laufen zu bringen.
Schritt 1: Rufen Sie das PaddleOCR-VL-Template auf
Sie können direkt auf das PaddleOCR-VL GPU-Template zugreifen.
Schritt 2: Konfigurieren Sie Ihre GPU-Instanz
Richten Sie die Infrastrukturparameter entsprechend Ihren Verarbeitungsanforderungen ein:
- Speicherzuweisung: Wählen Sie die RAM-Kapazität basierend auf der Arbeitslast
- Speicheranforderungen: Weisen Sie Festplattenspeicher für Modelldateien und die Verarbeitung zu
- Netzwerkeinstellungen: Konfigurieren Sie die Konnektivität für den API-Zugriff
Wählen Sie Bereitstellen, um Ihre Konfiguration zu übernehmen.
Pro-Tipp: Beginnen Sie mit den empfohlenen Einstellungen für typische Dokumentenverarbeitungs-Workloads und skalieren Sie bei Bedarf.
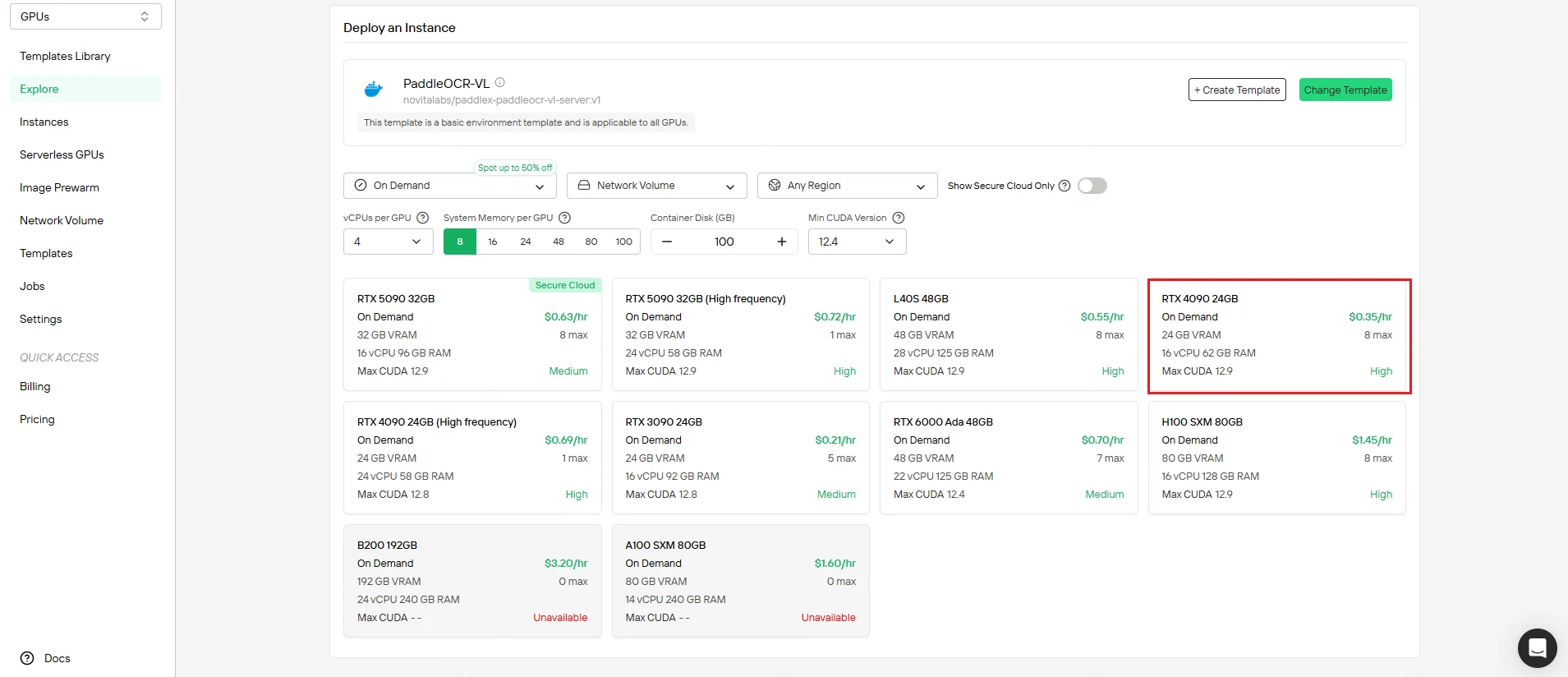
Schritt 3: Überprüfen Sie die Konfiguration und stellen Sie sie bereit
Überprüfen Sie Ihre Einstellungen doppelt, bevor Sie die Bereitstellung starten:
- Überprüfen Sie, ob die Rechenressourcen Ihren Anforderungen entsprechen
- Prüfen Sie die Kostenübersicht, um die Budgetkonformität sicherzustellen
- Bestätigen Sie die Netzwerk- und Speicherkonfigurationen
Wenn Sie zufrieden sind, klicken Sie auf Bereitstellen, um den Erstellungsprozess zu starten. Novita AI übernimmt die gesamte Backend-Komplexität automatisch.
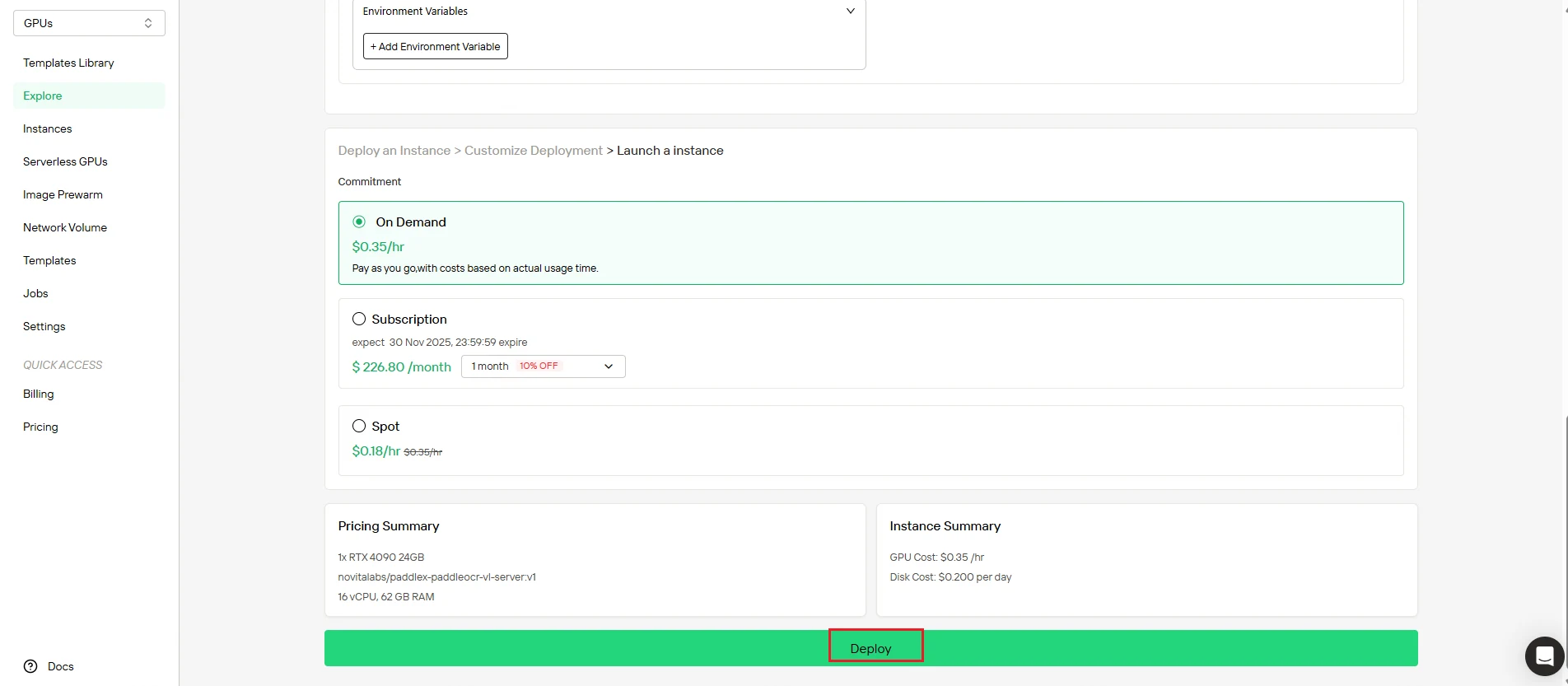
Schritt 4: Überwachen Sie die Instanzerstellung
Nach Einleitung der Bereitstellung werden Sie automatisch zur Instanzverwaltungsseite weitergeleitet. Ihre Instanz wird im Hintergrund erstellt – kein manueller Eingriff erforderlich.
Verfolgen Sie den Fortschritt in Echtzeit über das Dashboard.
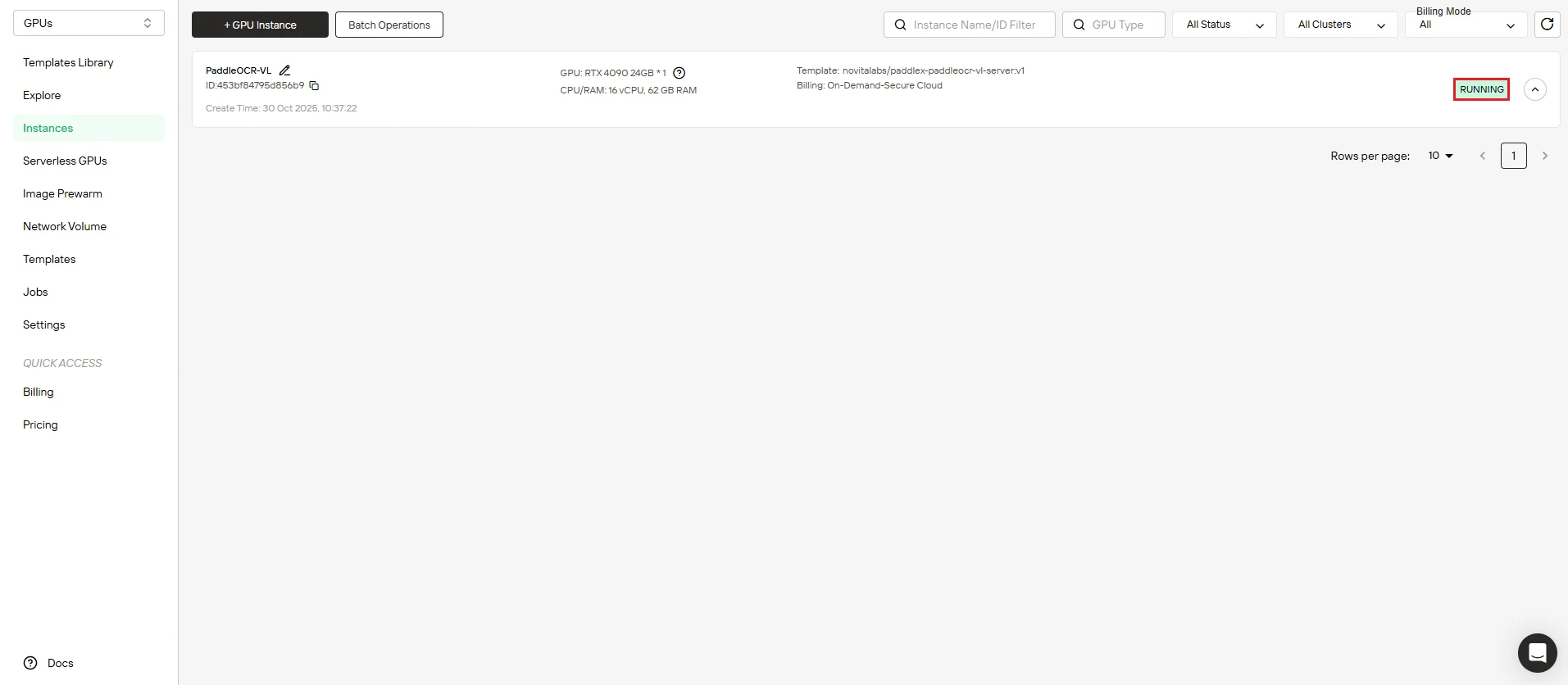
Schritt 5: Verfolgen Sie den Bild-Download-Fortschritt
Sehen Sie zu, wie Ihre Instanz online geht. Das Dashboard zeigt den Echtzeit-Fortschritt des PaddleOCR-VL-Image-Downloads an. Der Status Ihrer Instanz wechselt von “Pulling” zu “Running”, sobald die Bereitstellung erfolgreich abgeschlossen ist.
Klicken Sie auf das Pfeilsymbol neben dem Namen Ihrer Instanz, um detaillierte Fortschrittsinformationen und Bereitstellungsprotokolle anzuzeigen.
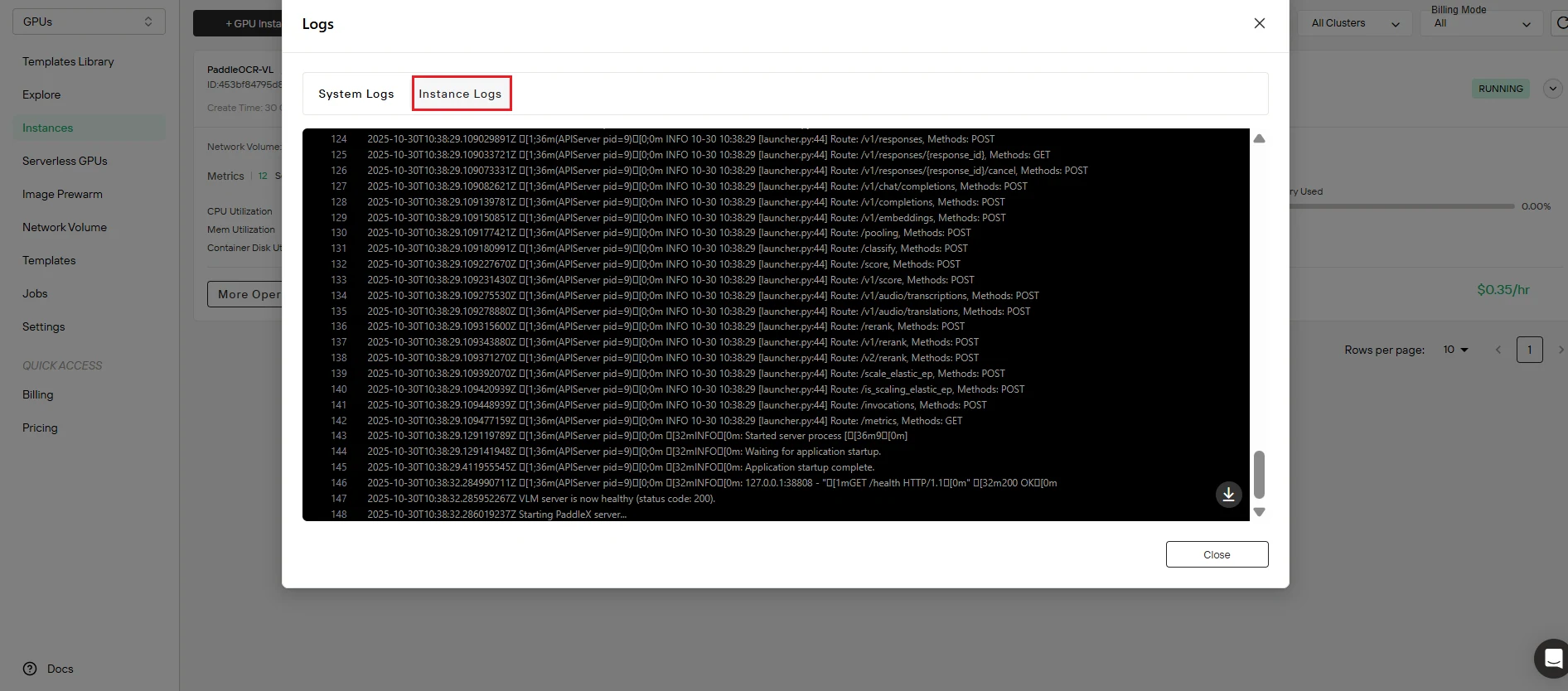
Schritt 6: Überprüfen Sie den Dienststatus
Bestätigen Sie die erfolgreiche Bereitstellung. Klicken Sie auf die Schaltfläche Logs, um auf die Instanzprotokolle zuzugreifen und zu überprüfen, ob der PaddleOCR-VL-Dienst ordnungsgemäß gestartet wurde. Suchen Sie nach Initialisierungsmeldungen, die bestätigen:
- Dienststart abgeschlossen
- API-Endpunkt aktiv und lauscht
- Modell erfolgreich geladen
Schritt 7: Zugriff auf die Entwicklungsumgebung
Starten Sie Ihren Arbeitsbereich. Navigieren Sie zur Connect-Oberfläche und initialisieren Sie Start Web Terminal, um Befehlszeilenzugriff auf Ihre Instanz zu erhalten.
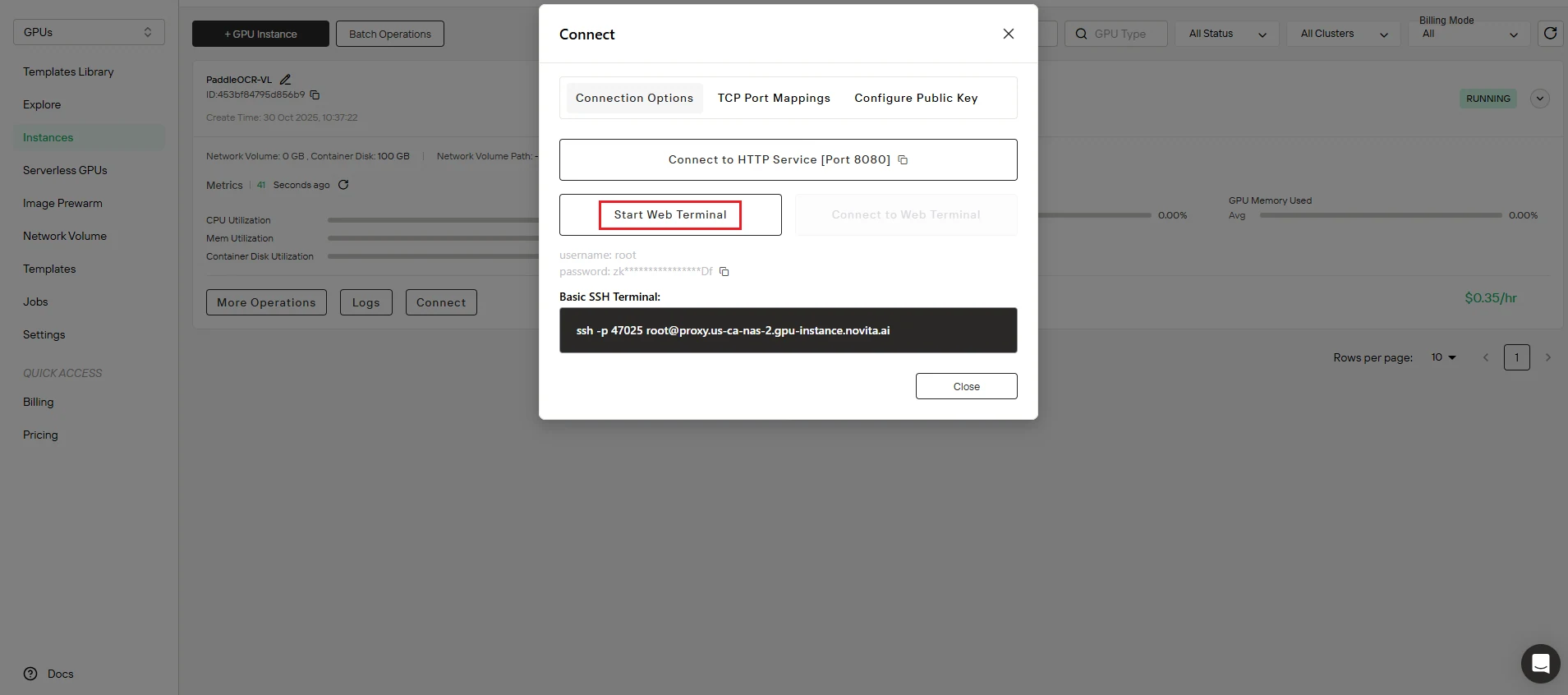
🎉 Herzlichen Glückwunsch! Ihr PaddleOCR-VL-Dienst ist jetzt voll funktionsfähig und bereit zur Verarbeitung von OCR-Anfragen. Gesamtzeit: ca. 5 Minuten.
Ausführen Ihrer ersten OCR-Inferenz
Da Ihre PaddleOCR-VL-Instanz jetzt auf Novita AI GPU läuft, verarbeiten wir Ihr erstes Dokument. Diese Demo zeigt den vollständigen Workflow von der Bildvorbereitung bis zur Ergebnisextraktion.
Schritt 1: Erstellen Sie ein Python-Testskript
Erstellen Sie eine Datei namens test.py mit dem folgenden Code:
import base64
import requests
import pathlib
API_URL = "http://localhost:8080/layout-parsing" # Service URL
image_path = "./demo.jpg"
# Encode local image to Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {
"file": image_data, # Base64 encoded file content or file URL
"fileType": 1, # File type, 1 means image file
}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response data
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["layoutParsingResults"]):
print(res["prunedResult"])
md_dir = pathlib.Path(f"markdown_{i}")
md_dir.mkdir(exist_ok=True)
(md_dir / "doc.md").write_text(res["markdown"]["text"])
for img_path, img in res["markdown"]["images"].items():
img_path = md_dir / img_path
img_path.parent.mkdir(parents=True, exist_ok=True)
img_path.write_bytes(base64.b64decode(img))
print(f"Markdown document saved at {md_dir / 'doc.md'}")
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
pathlib.Path(img_path).parent.mkdir(exist_ok=True)
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
Was dieses Skript tut:
- Kodiert Ihr Bild in das Base64-Format
- Sendet es an den PaddleOCR-VL-API-Endpunkt
- Empfängt strukturierte Parsing-Ergebnisse
- Speichert den extrahierten Inhalt als Markdown-Dokumente
- Exportiert eingebettete Bilder
Schritt 2: Testbild herunterladen
Verwenden Sie den offiziellen PaddleOCR-Testfall für Ihre erste Inferenz:
bash
curl https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/main/tests/test_files/book.jpg -o demo.jpg
Dies lädt ein Beispiel-Dokumentenbild (book.jpg) herunter, um Ihren OCR-Aufbau zu testen. Die offizielle Testdatei ist verfügbar unter: PaddleOCR GitHub-Repository
Schritt 3: API-Endpunkt konfigurieren
Aktualisieren Sie Ihr Skript mit dem korrekten Endpunkt:
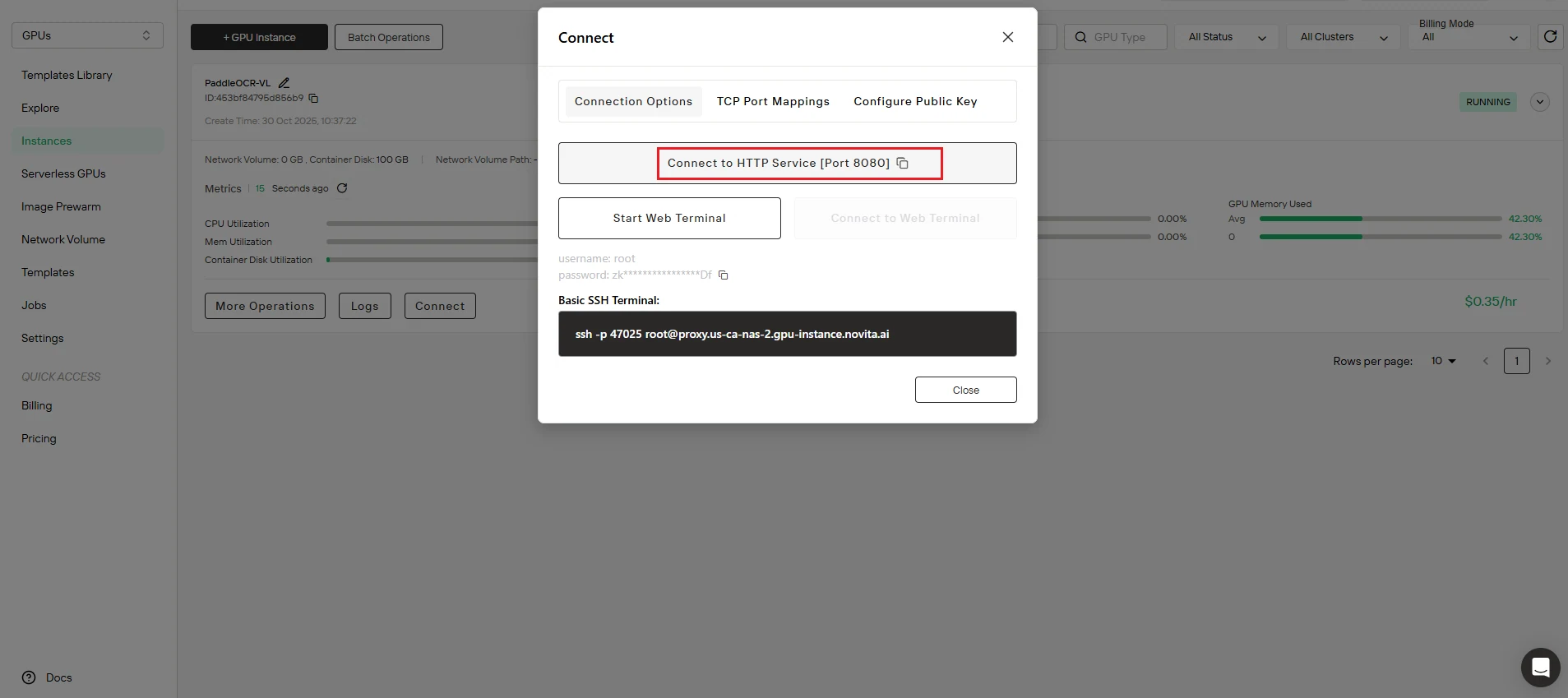
- Kopieren Sie die Port-Mapping-Adresse aus Ihrem Novita AI-Instanz-Dashboard
- Ersetzen Sie
http://localhost:8080/layout-parsingintest.pydurch Ihre tatsächliche API-Endpunkt-URL
Beispiel: Ihr Endpunkt könnte wie folgt aussehen: http://ihre-instanz-id.novita.ai:8080/layout-parsing
Schritt 4: OCR-Verarbeitung ausführen
Führen Sie Ihr Testskript aus:
bash
python test.py
Erwartete Ausgabe:
- Die Konsole zeigt die extrahierte Textstruktur an
- Markdown-Dokumente werden unter
markdown_0/doc.mdgespeichert - Eingebettete Bilder werden in separate Dateien extrahiert
- Bestätigungsmeldungen, die die Speicherorte der Ausgabedateien anzeigen
Das war’s! Sie haben Ihr erstes Dokument erfolgreich mit PaddleOCR-VL auf einer Novita AI GPU-Instanz verarbeitet.
Praktische Anwendungsfälle
Stellen Sie PaddleOCR-VL auf einer Novita AI GPU-Instanz bereit, um unterschiedliche Dokumentenverarbeitungs-Workflows zu unterstützen:
Finanzdienstleistungen
- Rechnungsverarbeitung: Extrahieren von Positionen, Gesamtbeträgen und Lieferanteninformationen
- Belegdigitalisierung: Automatisierung von Spesenabrechnung und Abgleich
- Kontoauszugsanalyse: Umwandlung von Kontoauszügen in strukturierte Daten
Wissenschaft & Forschung
- Analyse von Forschungsarbeiten: Extrahieren von Text, Formeln und Tabellen aus Veröffentlichungen
- Lehrbuchdigitalisierung: Umwandlung von Lehrmaterialien in durchsuchbare Formate
- Erhaltung historischer Dokumente: Digitalisierung von Archiven mit beeinträchtigter Textqualität
Recht & Compliance
- Vertragsanalyse: Extrahieren von Klauseln, Bedingungen und Unterschriften
- Verarbeitung von Regulierungsdokumenten: Analyse von Compliance-Einreichungen und Berichten
- Rechtliche Beweisaufnahme: Umwandlung von Falldokumenten in durchsuchbaren Text
Gesundheitswesen
- Digitalisierung von Krankenakten: Umwandlung von Patientendaten in strukturierte Daten
- Rezeptverarbeitung: Extrahieren von Medikamenteninformationen aus Formularen
- Analyse von Versicherungsanträgen: Automatisierung der Verarbeitung von Antragsdokumenten
E-Commerce & Einzelhandel
- Produktkatalog-Extraktion: Analyse von Lieferanten-Datenblättern und Spezifikationen
- Mehrsprachige Produktbeschreibungen: Verarbeitung internationaler Kataloge
- Verarbeitung von Bestandsdokumenten: Digitalisierung von Lagerlisten und Manifesten
Öffentliche Verwaltung
- Formularverarbeitung: Automatisierung der Bearbeitung von Dokumenten für Bürgerdienste
- Ausweisprüfung: Extrahieren von Informationen aus Ausweisdokumenten
- Verarbeitung von Genehmigungen und Lizenzen: Analyse von Antragsdokumenten
Die Unterstützung von 109 Sprachen und die Erkennung komplexer Elemente machen PaddleOCR-VL ideal für globale Organisationen, die mit unterschiedlichen Dokumenttypen arbeiten.
Fazit
Stellen Sie PaddleOCR-VL in 5 Minuten auf einer Novita AI GPU-Instanz bereit und nutzen Sie modernste Dokumentenparsing-Funktionen ohne Infrastrukturkomplexität. Mit SOTA-Leistung, Unterstützung von 109 Sprachen und effizienter Ressourcennutzung erhalten Sie eine unternehmensgerechte OCR-Lösung, die sowohl leistungsstark als auch praktisch ist.
Wichtige Erkenntnisse:
✅ 5-Minuten-Bereitstellung mit vorkonfigurierten Templates
✅ SOTA-Genauigkeit für Text, Tabellen, Formeln und Diagramme
✅ 109 Sprachen für die globale Dokumentenverarbeitung
✅ Erkennung komplexer Elemente einschließlich handschriftlicher und historischer Dokumente
✅ Schnelle Inferenzgeschwindigkeiten für Workflows mit hohem Durchsatz
✅ Ressourceneffizient mit kompaktem 0,9-Milliarden-Parameter-Modell
Egal, ob Sie Rechnungen verarbeiten, Forschungsarbeiten digitalisieren, Rechtsdokumente analysieren oder mehrsprachige Inhalte verarbeiten – PaddleOCR-VL auf Novita AI liefert vom ersten Tag an produktionsbereite Ergebnisse.
Bereit, Ihren Dokumenten-Workflow zu transformieren?
Lassen Sie sich nicht von einer komplexen OCR-Einrichtung aufhalten. Stellen Sie PaddleOCR-VL noch heute auf einer Novita AI GPU-Instanz bereit und beginnen Sie in Minuten statt Stunden mit der Dokumentenverarbeitung.
👉 Stellen Sie jetzt das PaddleOCR-VL GPU-Template bereit
Erhalten Sie sofortigen Zugriff auf das vorkonfigurierte PaddleOCR-VL-Template mit allen Abhängigkeiten und Optimierungen. Klicken, konfigurieren, bereitstellen – Ihr SOTA-OCR-Dienst läuft in 5 Minuten.
Warum Tausende von Entwicklern Novita AI wählen:
- Keine Infrastrukturverwaltung
- Pay-as-you-go-Preise ohne Vorabkosten
- Vorkonfigurierte Templates für sofortige Bereitstellung
- Skalierbare GPU-Ressourcen auf Abruf
- 24/7 Support und umfassende Dokumentation
Starten Sie Ihre Bereitstellung jetzt – Ihre erste OCR-Inferenz ist nur 5 Minuten entfernt.
Häufig gestellte Fragen
Wie lange dauert die Bereitstellung von PaddleOCR-VL auf Novita AI?
Ca. 5 Minuten von der Auswahl des Templates bis zur laufenden Instanz.
Welche Sprachen unterstützt PaddleOCR-VL?
109 Sprachen, darunter Chinesisch, Englisch, Japanisch, Koreanisch, Russisch, Arabisch, Hindi, Thailändisch und viele weitere.
Kann PaddleOCR-VL handschriftlichen Text erkennen?
Ja, PaddleOCR-VL zeichnet sich durch die Erkennung von handschriftlichem Text und historischen Dokumenten mit beeinträchtigter Qualität aus.
Welche Arten von Dokumentelementen kann PaddleOCR-VL extrahieren?
Text, Tabellen, mathematische Formeln, Diagramme und andere komplexe Dokumentelemente.
Benötige ich GPU-Erfahrung, um auf Novita AI bereitzustellen?
Nein, das vorkonfigurierte Template übernimmt die gesamte technische Einrichtung automatisch. Klicken Sie einfach auf den Link PaddleOCR-VL GPU-Template und folgen Sie den einfachen Schritten.
Wie viel kostet die Ausführung von PaddleOCR-VL auf Novita AI?
Novita AI bietet Pay-as-you-go-Preise. Sie zahlen nur für die GPU-Zeit, die Sie tatsächlich nutzen, ohne Vorabkosten oder langfristige Verpflichtungen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Entwicklung und Skalierung bereitstellt.




{kind=link}