

自 2025 年 5 月发布以来,DeepSeek R1 0528 已成为 AI 界最受关注的开源模型之一。凭借 **6850 亿参数 ** 以及媲美顶级专有模型的性能,它在 推理、编码和数学能力 方面给开发者和研究人员留下了深刻印象。
但随着越来越多人争相尝试,一个关键问题不断浮现:
运行这个庞大的模型实际需要多少成本?继续阅读。
DeepSeek R1 0528 模型卡
DeepSeek R1 0528 于 2025 年 5 月 28 日发布,是一款功能强大的开源 AI 模型,以其先进的推理能力、卓越的性能和成本效益而闻名。
关键特性
- 规模: 6850 亿参数(比 OpenAI o3 更大)。
- 开源: 完全开源,遵循 MIT 许可证;权重可在 Hugging Face 上获取。
- 架构: 使用专家混合(MoE)实现动态参数激活,提升效率。
- 语言支持: 在英文和中文上表现最佳。
- 多模态能力: 仅文本(不支持图像/音频输入)。
- 训练改进: 通过优化的后训练方法增强了推理和推断能力。
性能亮点
- 推理和编程:
- 在高级数学、逻辑和编程任务上表现出色。
- 数学基准:
- HMMT 2025: Pass@1 从 41.7% 提升至 79.4%。
- AIME 2025: Pass@1 从 70.0% 提升至 87.5%。
- 编码基准:
- Codeforces-Div1 评分: 1530 → 1930。
- Aider-Polyglot 准确率: 53.3% → 71.6%。
- LiveCodeBench Pass@1: 63.5% → 73.3%。
- 调试和代码生成:
- 在代码生成过程中自我修正,减少错误。
- 思维链推理:
- 提供逐步推理,确保准确性和透明度。
- 工具集成:
- 支持 API 集成,提供 JSON 输出和函数调用。
- Tau-Bench Pass@1 得分:航空 (53.5%),零售 (63.9%)。
- 减少幻觉:
- 提高了关键用例的可靠性。
部署选项
- 完整模型(685B):
- 需要 24 块 NVIDIA H100 GPU(每块 80GB)、512GB–1TB 内存以及强大的基础设施。
- 蒸馏版本(Qwen3 8B):
- 可在单块 NVIDIA RTX 4090 GPU(24GB 显存)上运行。
DeepSeek R1 0528 的 API 成本
何时使用 API 访问?
当以下情况时使用 API:
- 您希望零设置或无需维护基础设施
- 您正在运行批量推理或微调任务
- 您更喜欢按需、可扩展的工作负载
- 您看重基于令牌的定价(输入/输出)
DeepSeek R1 0528 API 定价对比
| 提供商 | 输入 ($/M) | 输出 ($/M) |
|---|---|---|
| Novita AI | 0.70 | 2.50 |
| Fireworks AI | 3.00 | 8.00 |
| Nebius AI Studio | 0.80 | 2.40 |
| Parasail | 0.79 | 4 |
✅ Novita AI 提供最低的 API Token 成本。适用于成本敏感且可扩展的任务,如 LLMOps、批量推理或非交互式批量管道。
API 使用指南
要开始使用,只需使用以下代码片段:
- 统一端点:
/v3/openai支持 OpenAI 的 Chat Completions API 格式。 - 灵活控制: 可调整 temperature、top-p、惩罚参数等,以获得定制结果。
- 流式与批处理: 选择您偏好的响应模式。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_Ntg-O34ZOS-q5bNnkb3IcixmWnmxEQBxwKWMW3es3CD7KG4PEhFE1yRTRMGS3s8zZ52hrMdz14MmI4oalaDJTw==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # 或 False
max_tokens = 2048
system_content = "你是一个乐于助人的助手"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "你好!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
您也可以在第三方平台上连接 DeepSeek R1 0528 API
- Hugging Face:通过 Novita AI 端点在 Spaces、管道或 Transformers 库中使用 DeepSeek R1 0528。
- Agent 与编排框架: 通过官方连接器和逐步集成指南,轻松将 Novita AI 与合作伙伴平台(如 Continue、AnythingLLM、LangChain、Dify 和 Langflow)连接。
- 兼容 OpenAI 的 API: 能够与 Cline 和 Cursor 等工具无缝迁移和集成,这些工具专为 OpenAI API 标准设计。
DeepSeek R1 0528 的 GPU 云成本
何时使用 GPU 实例?
在以下情况下使用云 GPU:
- 您需要对模型执行拥有完全控制权
- 您想运行自定义微调
- 您需要更长时间的会话或持久推理服务器
- 您正在使用量化模型或加速框架
GPU 租赁定价对比(每小时)
| 提供商 | GPU 类型 | 价格/小时 |
|---|---|---|
| Novita AI | A100 SXM | $1.60 |
| H100 SXM | $2.41 | |
| H200 SXM | $2.99 | |
| Lambda Cloud | H100 SXM | $3.29 |
| RunPod | A100 SXM | $1.74 |
| H100 SXM | $2.69 | |
| H200 | $3.99 | |
| Fireworks AI | H100 | $5.8 |
| H200 | $6.99 |
✅ 从成本效益来看,Novita AI 是所有 GPU 类型中最佳的提供商,而 A100 GPU 是预算有限的用户最友好的选择。
Cloud GPU 使用指南
第 1 步:注册账户
通过我们的网站创建您的 Novita AI 账户。注册后,导航到左侧边栏的“Explore”部分,查看我们的 GPU 产品并开始您的 AI 开发之旅。

第 2 步:探索模板和 GPU 服务器
选择符合您项目需求的模板,如 PyTorch、TensorFlow 或 CUDA。然后选择您偏好的 GPU 配置——选项包括强大的 L40S、RTX 4090 或 A100 SXM4,每种配置都有不同的显存、内存和存储规格。
第 3 步:定制您的部署
通过选择您偏好的操作系统和配置选项来定制您的环境,以确保为特定 AI 工作负载和开发需求提供最佳性能。
第 4 步:启动实例
选择“启动实例”开始您的部署。几分钟内即可准备好的高性能 GPU 环境,让您立即开始机器学习、渲染或计算项目。
DeepSeek R1 0528 的本地部署成本
何时本地部署?
仅在以下情况下考虑 本地部署:
- 您需要 完全的数据控制
- 您已经有 数据中心级别的基础设施
- 您计划运行 大规模、持续的推理
- 您是拥有数百万美元预算的研究实验室或企业
本地部署完整 DeepSeek R1 0528 的预估成本
| 组件 | 规格/数量 | 成本 (USD) |
|---|---|---|
| NVIDIA A100 GPU | 116 × A100 80GB | $2,577,251.96 |
| 服务器节点(双 A100) | 58 × $50K | $2,900,000 |
| InfiniBand 网络 | 高速结构 | $100,000 |
| NVMe SSD 存储(100TB) | 4–6GB/s 读写 | $20,000 |
| 液冷 + 机架 | 企业级系统 | $80,000 + $10,000 |
| 软件与许可证 | 框架 + 操作系统 | $10,000 |
| 电力基础设施 | UPS + 电力输送 | $50,000 |
| 电力(年) | 每 GPU 700W | $50,000 |
| 维护与支持 | 年度合同 | $100,000 |
| **总估算 ** | $5.89M+ |
DeepSeek R1 0528 与其他模型对比
DeepSeek R1 0528 vs 其他模型:价格
| 模型 | 输入成本 ($/M) | 输出成本 ($/M) |
|---|---|---|
| DeepSeek R1 0528 | 0.70 | 2.50 |
| Gemini 2.5 Pro | 1.25–2.50 | 10–15 |
| OpenAI o3-pro | 20.00 | 80.00 |
DeepSeek R1‑0528 vs 其他模型:性能
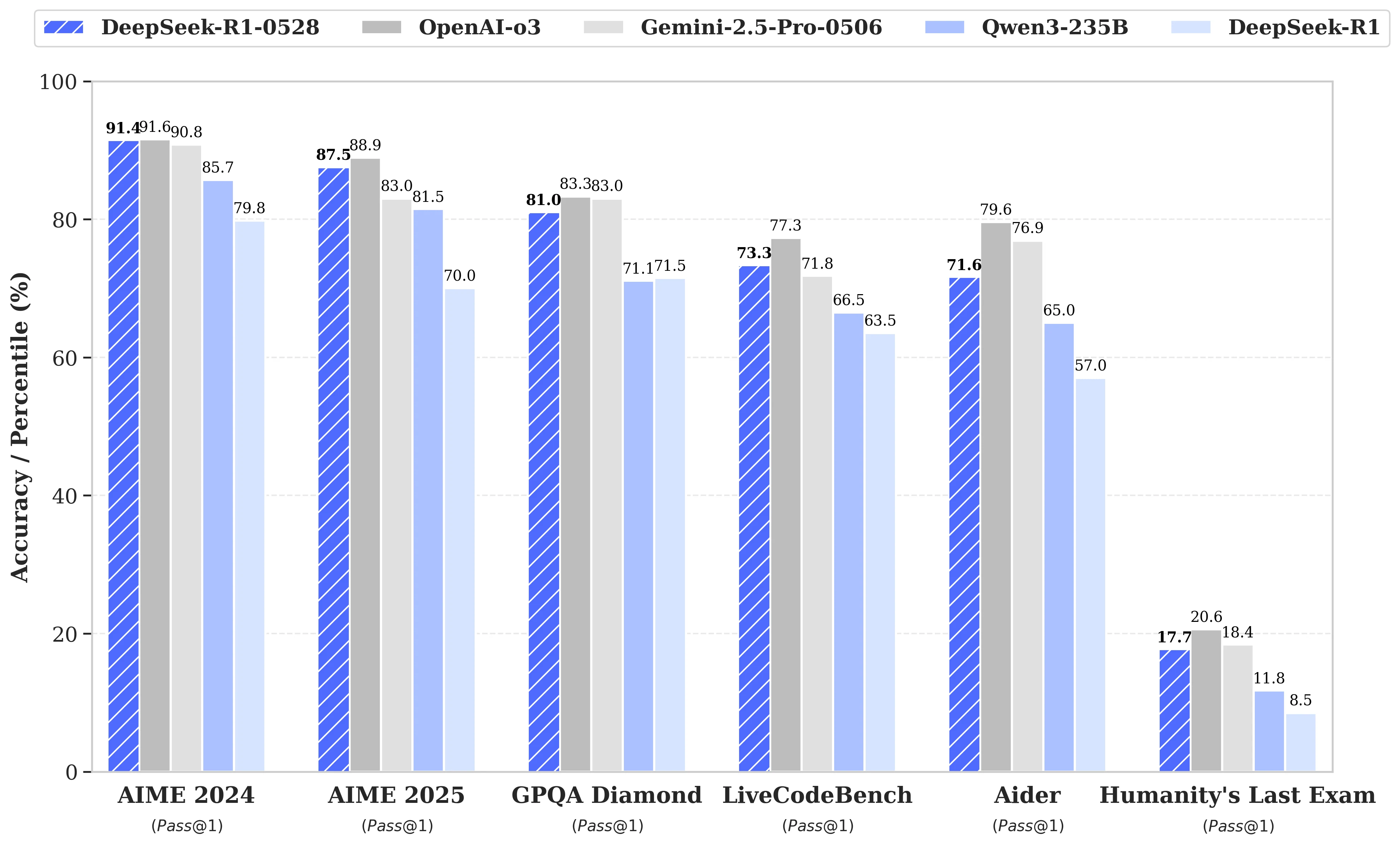
DeepSeek R1 0528 性能接近顶级模型,价格却降低了多达 32 倍,是当前市场上最具成本效益的选择。
结论
无论您是构建可扩展的 AI 管道、微调模型,还是在生产环境中部署 LLM,Novita AI 上的 DeepSeek R1 0528 都提供了最具成本效益和灵活的解决方案——而无需承担基础设施负担。
| 使用场景 | 最佳选择 | 原因 |
|---|---|---|
| 批量推理 / Token 效率 | Novita AI API | 最低的输入/输出费率 |
| 长时间运行 / 微调任务 | Novita AI GPU | 最低的每小时 GPU 租赁费用 |
| 私密、安全、大规模运营 | 本地部署(预算允许) | 完全控制,高复杂度 |
| 需要高精度和成本控制 | DeepSeek R1 0528 | 在价格上击败 Gemini/OpenAI |
常见问题解答
微调 DeepSeek R1 0528 的成本是多少?
构建您自己基础设施的预估成本约为 $5.89M。然而,使用 Novita AI 的云 GPU 可以显著降低前期成本,H100 GPU 起价仅为 $2.41/小时。
如何确保微调后的模型满足我的需求?
准备一个 **干净、相关的数据集 **,并使用 **LoRA 适配器 ** 或 PEFT 方法 高效微调模型的特定层。这可以在不发生过拟合的情况下确保高性能。
我可以在 Novita AI 上部署我微调后的模型吗?
可以。Novita AI 支持将微调后的模型部署为 专用端点,并提供自动缩放、多 LoRA 设置和 API 集成选项,以便在您的应用中无缝使用。
Novita AI 是一个 AI 云平台,为开发者提供使用简单 API 部署 AI 模型的便捷方式,同时也提供价格实惠且可靠的 GPU 云服务,用于构建和扩展。



