

Desde su lanzamiento en mayo de 2025, DeepSeek R1 0528 se ha convertido en uno de los modelos de código abierto más comentados en el mundo de la IA. Con 685 mil millones de parámetros y un rendimiento que rivaliza con los mejores modelos propietarios, ha impresionado a desarrolladores e investigadores por igual por sus capacidades de razonamiento, codificación y matemáticas.
Pero a medida que más personas se apresuran a probarlo, surge una pregunta clave:
¿Cuánto cuesta realmente ejecutar este enorme modelo? Sigue leyendo.
Ficha técnica del modelo DeepSeek R1 0528
DeepSeek R1 0528, lanzado el 28 de mayo de 2025, es un potente modelo de IA de código abierto conocido por su razonamiento avanzado, rendimiento excepcional y eficiencia de costos.
Características principales
- Tamaño: 685 mil millones de parámetros (más grande que OpenAI o3).
- Código abierto: Completamente abierto bajo la licencia MIT; pesos disponibles en Hugging Face.
- Arquitectura: Utiliza Mixture of Experts (MoE) para activación dinámica de parámetros, lo que aumenta la eficiencia.
- Idiomas compatibles: Mejor rendimiento en inglés y chino.
- Capacidad multimodal: Solo texto (sin soporte de entrada de imagen/audio).
- Mejoras en el entrenamiento: Razonamiento e inferencia mejorados mediante métodos de post-entrenamiento optimizados.
Aspectos destacados de rendimiento
-
Razonamiento y programación:
-
Sólido en tareas avanzadas de matemáticas, lógica y programación.
-
Puntos de referencia matemáticos:
- HMMT 2025: Pass@1 mejoró de 41.7% → 79.4%.
- AIME 2025: Pass@1 aumentó de 70.0% → 87.5%.
-
Puntos de referencia de codificación:
- Codeforces-Div1 Rating: 1530 → 1930.
- Aider-Polyglot Accuracy: 53.3% → 71.6%.
- LiveCodeBench Pass@1: 63.5% → 73.3%.
-
-
Depuración y generación de código:
- Se autocorrige durante la generación de código, reduciendo errores.
-
Razonamiento en cadena de pensamiento:
- Proporciona razonamiento paso a paso para precisión y transparencia.
-
Integración de herramientas:
- Soporta integración API con salida JSON y llamadas a funciones.
- Puntuaciones Tau-Bench Pass@1: Aerolínea (53.5%), Comercio minorista (63.9%).
-
Reducción de alucinaciones:
- Mayor fiabilidad para casos de uso críticos.
Opciones de implementación
-
Modelo completo (685B):
- Requiere 24 GPU NVIDIA H100 (80GB cada una), 512GB–1TB de RAM e infraestructura robusta.
-
Versión destilada (Qwen3 8B):
- Se ejecuta en una sola GPU NVIDIA RTX 4090 (24GB VRAM).
Costo de API de DeepSeek R1 0528
¿Cuándo usar acceso por API?
Usa la API cuando:
- No quieras configuración ni mantenimiento de infraestructura
- Estés ejecutando inferencia por lotes o trabajos de ajuste fino
- Prefieras cargas de trabajo bajo demanda y escalables
- Valores el precio basado en tokens (entrada/salida)
Comparativa de precios de API de DeepSeek R1 0528
| Proveedor | Entrada ($/M) | Salida ($/M) |
|---|---|---|
| Novita AI | 0.70 | 2.50 |
| Fireworks AI | 3.00 | 8.00 |
| Nebius AI Studio | 0.80 | 2.40 |
| Parasail | 0.79 | 4 |
✅ Novita AI ofrece el costo de token API más bajo. Ideal para tareas sensibles al costo y escalables como LLMOps, inferencia masiva o pipelines por lotes no interactivos.
Guía de uso de la API
Para comenzar, simplemente usa el fragmento de código a continuación:
- Endpoint unificado:
/v3/openaisoporta el formato de la API Chat Completions de OpenAI. - Controles flexibles: Ajusta temperatura, top-p, penalizaciones y más para obtener resultados personalizados.
- Streaming y procesamiento por lotes: Elige tu modo de respuesta preferido.
Prueba la API rápida de DeepSeek R1 0528 ahora
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_Ntg-O34ZOS-q5bNnkb3IcixmWnmxEQBxwKWMW3es3CD7KG4PEhFE1yRTRMGS3s8zZ52hrMdz14MmI4oalaDJTw==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
También puedes conectar DeepSeek R1 0528 API en plataformas de terceros
- Hugging Face: Usa DeepSeek R1 0528 en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
- Frameworks de agentes y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM, LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
- API compatible con OpenAI: Disfruta de una migración e integración sin problemas con herramientas como Cline y Cursor, diseñadas para el estándar de la API de OpenAI.
Costo de la nube de GPU de DeepSeek R1 0528
¿Cuándo usar instancias de GPU?
Usa GPU en la nube si:
- Necesitas control total sobre la ejecución del modelo
- Quieres ejecutar ajuste fino personalizado
- Necesitas sesiones más largas o servidores de inferencia persistentes
- Estás utilizando modelos cuantizados o frameworks acelerados
Comparativa de precios de alquiler de GPU (por hora)
| Proveedor | Tipo de GPU | Precio/hora |
|---|---|---|
| Novita AI | A100 SXM | $1.60 |
| H100 SXM | $2.41 | |
| H200 SXM | $2.99 | |
| Lambda Cloud | H100 SXM | $3.29 |
| RunPod | A100 SXM | $1.74 |
| H100 SXM | $2.69 | |
| H200 | $3.99 | |
| Fireworks AI | H100 | $5.8 |
| H200 | $6.99 |
✅ Para eficiencia de costos, Novita AI es el mejor proveedor en todos los tipos de GPU, mientras que la GPU A100 es la opción más económica para los usuarios.
Guía de uso de GPU en la nube
Paso 1: Registra una cuenta
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explorar” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje de desarrollo de IA.

Paso 2: Explorar plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se adapten a las necesidades de tu proyecto. Luego selecciona tu configuración de GPU preferida: opciones incluyen la potente L40S, RTX 4090 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
Paso 3: Personaliza tu implementación
Personaliza tu entorno seleccionando tu sistema operativo preferido y opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo de IA específicas y necesidades de desarrollo.
Paso 4: Iniciar una instancia
Selecciona “Iniciar instancia” para comenzar tu implementación. Tu entorno GPU de alto rendimiento estará listo en minutos, permitiéndote comenzar inmediatamente tus proyectos de aprendizaje automático, renderizado o computacionales.
Costo de implementación local de DeepSeek R1 0528
¿Cuándo implementar localmente?
Considera la implementación local solo si:
- Necesitas control total de los datos
- Ya cuentas con infraestructura de nivel de centro de datos
- Planeas ejecutar inferencia continua a gran escala
- Eres un laboratorio de investigación o empresa con presupuestos de $MM
Costo estimado para implementar DeepSeek R1 0528 completo localmente
| Componente | Especificaciones / Cantidad | Costo (USD) |
|---|---|---|
| GPU NVIDIA A100 | 116 × A100 80GB | $2,577,251.96 |
| Nodos de servidor (Dual A100) | 58 × $50K | $2,900,000 |
| Red InfiniBand | Tejido de alta velocidad | $100,000 |
| Almacenamiento SSD NVMe (100TB) | 4–6GB/s Lectura/Escritura | $20,000 |
| Refrigeración líquida + Rack | Sistemas de nivel empresarial | $80,000 + $10,000 |
| Software y licencias | Frameworks + SO | $10,000 |
| Infraestructura eléctrica | UPS + Distribución de energía | $50,000 |
| Electricidad (anual) | 700W por GPU | $50,000 |
| Mantenimiento y soporte | Contratos anuales | $100,000 |
| Estimación total | $5.89M+ |
DeepSeek R1 0528 vs otros modelos
DeepSeek R1 0528 vs otros modelos: Precio
| Modelo | Costo de entrada ($/M) | Costo de salida ($/M) |
|---|---|---|
| DeepSeek R1 0528 | 0.70 | 2.50 |
| Gemini 2.5 Pro | 1.25–2.50 | 10–15 |
| OpenAI o3-pro | 20.00 | 80.00 |
DeepSeek R1‑0528 vs otros modelos: Rendimiento
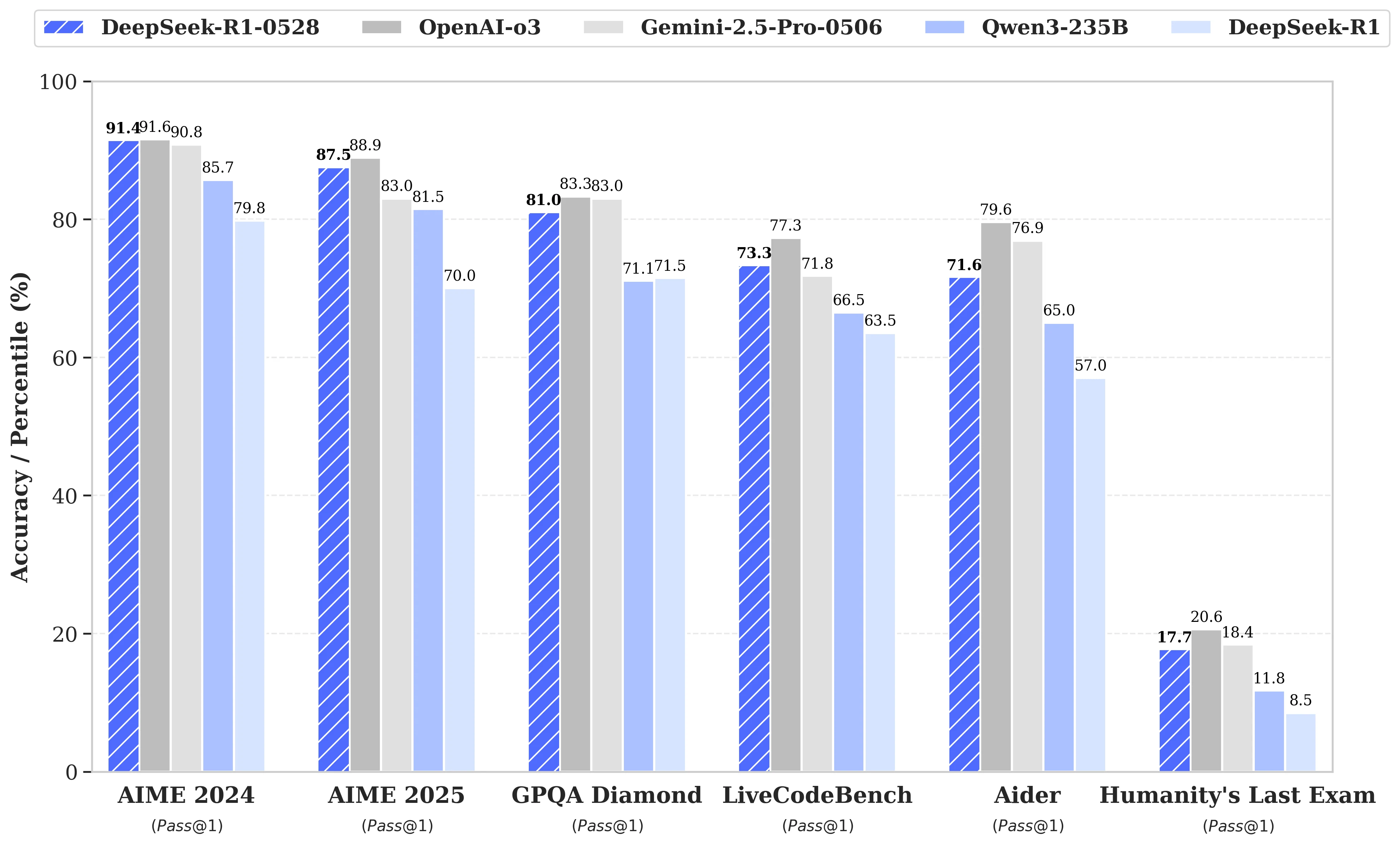
DeepSeek R1 0528, con un rendimiento cercano a los modelos de primer nivel, logra una reducción de precio de hasta 32 veces, lo que lo convierte en la opción más rentable en el mercado actual.
Conclusión
Ya sea que estés construyendo pipelines de IA escalables, ajustando modelos o implementando LLMs en producción, DeepSeek R1 0528 en Novita AI ofrece la solución más rentable y flexible, sin la carga de la infraestructura.
| Caso de uso | Mejor opción | ¿Por qué? |
|---|---|---|
| Inferencia por lotes / Eficiencia de tokens | API de Novita AI | Tarifas de entrada/salida más baratas |
| Tareas de larga duración / ajuste fino | GPU de Novita AI | Alquiler de GPU por hora más bajo |
| Operaciones privadas, seguras y a gran escala | Local (si el presupuesto lo permite) | Control total, alta complejidad |
| Necesidad de alta precisión y control de costos | DeepSeek R1 0528 | Supera a Gemini/OpenAI en precio |
Preguntas frecuentes
¿Cuál es el costo de ajustar DeepSeek R1 0528?
El costo estimado para construir tu propia infraestructura es de aproximadamente $5.89M. Sin embargo, usar las GPU en la nube de Novita AI reduce significativamente los costos iniciales, con GPU H100 desde $2.41/hora.
¿Cómo puedo asegurarme de que el modelo ajustado cumpla con mis necesidades?
Prepara un conjunto de datos limpio y relevante y utiliza adaptadores LoRA o métodos PEFT para ajustar de manera eficiente capas específicas del modelo. Esto garantiza un alto rendimiento sin sobreajuste.
¿Puedo implementar mi modelo ajustado en Novita AI?
Sí, Novita AI admite la implementación de modelos ajustados como endpoints dedicados, con opciones de escalado automático, configuraciones multi-LoRA e integración API para un uso fluido en tus aplicaciones.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.



