

Depuis sa sortie en mai 2025, DeepSeek R1 0528 est devenu l’un des modèles open‑source les plus discutés dans le monde de l’IA. Avec 685 milliards de paramètres et des performances rivalisant avec les meilleurs modèles propriétaires, il a impressionné les développeurs et les chercheurs par ses capacités de raisonnement, de codage et de mathématiques.
Mais alors que de plus en plus de personnes se précipitent pour l’essayer, une question clé revient sans cesse :
Combien coûte réellement l’exécution de ce modèle massif ? Lisez la suite.
Fiche du modèle DeepSeek R1 0528
DeepSeek R1 0528, publié le 28 mai 2025, est un puissant modèle d’IA open‑source connu pour son raisonnement avancé, ses performances exceptionnelles et son efficacité économique.
Principales caractéristiques
- Taille : 685 milliards de paramètres (plus grand qu’OpenAI o3).
- Open Source : Entièrement open‑source sous licence MIT ; poids disponibles sur Hugging Face.
- Architecture : Utilise Mixture of Experts (MoE) pour une activation dynamique des paramètres, améliorant l’efficacité.
- Support linguistique : Meilleures performances en anglais et en chinois.
- Capacité multimodale : Texte uniquement (pas de support d’entrée image/audio).
- Améliorations de l’entraînement : Raisonnement et inférence améliorés grâce à des méthodes de post‑entraînement optimisées.
Points forts des performances
-
Raisonnement et programmation :
-
Performances solides en mathématiques avancées, logique et programmation.
-
Benchmarks mathématiques :
- HMMT 2025 : Pass@1 amélioré de 41,7 % → 79,4 %.
- AIME 2025 : Pass@1 augmenté de 70,0 % → 87,5 %.
-
Benchmarks de codage :
- Codeforces‑Div1 Rating : 1530 → 1930.
- Aider‑Polyglot Accuracy : 53,3 % → 71,6 %.
- LiveCodeBench Pass@1 : 63,5 % → 73,3 %.
-
-
Débogage et génération de code :
- Auto‑correction pendant la génération de code, réduisant les erreurs.
-
Raisonnement en chaîne de pensée :
- Fournit un raisonnement étape par étape pour la précision et la transparence.
-
Intégration d’outils :
- Prend en charge l’intégration API avec sortie JSON et appel de fonctions.
- Scores Tau‑Bench Pass@1 : Airline (53,5 %), Retail (63,9 %).
-
Hallucinations réduites :
- Fiabilité améliorée pour les cas d’utilisation critiques.
Options de déploiement
-
Modèle complet (685B) :
- Nécessite 24 GPU NVIDIA H100 (80 Go chacun), 512 Go–1 To de RAM et une infrastructure robuste.
-
Version distillée (Qwen3 8B) :
- Fonctionne sur un seul GPU NVIDIA RTX 4090 (24 Go de VRAM).
Coût API de DeepSeek R1 0528
Quand utiliser l’accès API ?
Utilisez l’API lorsque :
- Vous ne voulez aucune configuration ou maintenance d’infrastructure
- Vous exécutez des travaux d’inférence par lots ou de fine‑tuning
- Vous préférez des charges de travail à la demande et évolutives
- Vous valorisez la tarification basée sur les tokens (entrée/sortie)
Comparaison des tarifs API DeepSeek R1 0528
| Fournisseur | Entrée ($/M) | Sortie ($/M) |
|---|---|---|
| Novita AI | 0,70 | 2,50 |
| Fireworks AI | 3,00 | 8,00 |
| Nebius AI Studio | 0,80 | 2,40 |
| Parasail | 0,79 | 4 |
✅ Novita AI propose le coût token API le plus bas. Idéal pour les tâches évolutives et sensibles aux coûts comme le LLMOps, l’inférence en masse ou les pipelines batch non interactifs.
Guide d’utilisation de l’API
Pour commencer, utilisez simplement l’extrait de code ci‑dessous :
- Point d’accès unifié :
/v3/openaiprend en charge le format de l’API Chat Completions d’OpenAI. - Contrôles flexibles : Réglez la température, top‑p, les pénalités et plus encore pour des résultats adaptés.
- Streaming et traitement par lots : Choisissez votre mode de réponse préféré.
Essayez l’API rapide DeepSeek R1 0528 dès maintenant
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_Ntg-O34ZOS-q5bNnkb3IcixmWnmxEQBxwKWMW3es3CD7KG4PEhFE1yRTRMGS3s8zZ52hrMdz14MmI4oalaDJTw==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Vous pouvez aussi connecter l’API DeepSeek R1 0528 sur des plateformes tierces
- Hugging Face: Utilisez DeepSeek R1 0528 dans Spaces, pipelines ou avec la bibliothèque Transformers via les points d’accès Novita AI.
- Frameworks d’agents et d’orchestration : Connectez facilement Novita AI aux plateformes partenaires comme Continue, AnythingLLM, LangChain, Dify et Langflow grâce à des connecteurs officiels et des guides d’intégration étape par étape.
- API compatible OpenAI : Profitez d’une migration et d’une intégration sans effort avec des outils comme Cline et Cursor, conçus pour le standard API OpenAI.
Coût du cloud GPU pour DeepSeek R1 0528
Quand utiliser des instances GPU ?
Utilisez le cloud GPU si :
- Vous avez besoin d’un contrôle total sur l’exécution du modèle
- Vous souhaitez effectuer un fine‑tuning personnalisé
- Vous avez besoin de sessions plus longues ou de serveurs d’inférence persistants
- Vous utilisez des modèles quantifiés ou des frameworks accélérés
Comparaison des tarifs de location GPU (par heure)
| Fournisseur | Type de GPU | Prix/heure |
|---|---|---|
| Novita AI | A100 SXM | 1,60 $ |
| H100 SXM | 2,41 $ | |
| H200 SXM | 2,99 $ | |
| Lambda Cloud | H100 SXM | 3,29 $ |
| RunPod | A100 SXM | 1,74 $ |
| H100 SXM | 2,69 $ | |
| H200 | 3,99 $ | |
| Fireworks AI | H100 | 5,8 $ |
| H200 | 6,99 $ |
✅ Pour un bon rapport qualité‑prix, Novita AI est le meilleur fournisseur pour tous les types de GPU, tandis que le GPU A100 est l’option la plus économique pour les utilisateurs.
Guide d’utilisation du cloud GPU
Étape 1 : Créez un compte
Créez votre compte Novita AI sur notre site web. Après l’inscription, naviguez vers la section « Explorer » dans la barre latérale gauche pour voir nos offres GPU et commencer votre développement IA.

Étape 2 : Explorez les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent à vos besoins. Sélectionnez ensuite votre configuration GPU préférée – parmi les options puissantes comme L40S, RTX 4090 ou A100 SXM4, chacune avec différentes spécifications de VRAM, RAM et stockage.
Étape 3 : Personnalisez votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation et vos options de configuration pour garantir des performances optimales pour vos charges de travail IA spécifiques.
Étape 4 : Lancez une instance
Sélectionnez « Lancer l’instance » pour démarrer votre déploiement. Votre environnement GPU haute performance sera prêt en quelques minutes, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.
Coût de déploiement local de DeepSeek R1 0528
Quand déployer en local ?
N’envisagez un déploiement sur site que si :
- Vous avez besoin d’un contrôle total des données
- Vous disposez déjà d’une infrastructure de niveau centre de données
- Vous prévoyez d’exécuter une inférence à très grande échelle et en continu
- Vous êtes un laboratoire de recherche ou une entreprise disposant de budgets de plusieurs millions de dollars
Estimation du coût de déploiement local complet de DeepSeek R1 0528
| Composant | Spécifications / Qté | Coût (USD) |
|---|---|---|
| GPU NVIDIA A100 | 116 × A100 80 Go | 2 577 251,96 $ |
| Nœuds de serveur (Dual A100) | 58 × 50 000 $ | 2 900 000 $ |
| Réseau InfiniBand | Fibre haute vitesse | 100 000 $ |
| Stockage NVMe SSD (100 To) | 4–6 Go/s en lecture/écriture | 20 000 $ |
| Refroidissement liquide + baie | Systèmes de qualité entreprise | 80 000 $ + 10 000 $ |
| Logiciels et licences | Frameworks + OS | 10 000 $ |
| Infrastructure électrique | UPS + Distribution | 50 000 $ |
| Électricité (annuelle) | 700 W par GPU | 50 000 $ |
| Maintenance et support | Contrats annuels | 100 000 $ |
| Estimation totale | 5,89 M$+ |
DeepSeek R1 0528 vs autres modèles
DeepSeek R1 0528 vs autres modèles : Prix
| Modèle | Coût d’entrée ($/M) | Coût de sortie ($/M) |
|---|---|---|
| DeepSeek R1 0528 | 0,70 | 2,50 |
| Gemini 2.5 Pro | 1,25–2,50 | 10–15 |
| OpenAI o3‑pro | 20,00 | 80,00 |
DeepSeek R1‑0528 vs autres modèles : Performances
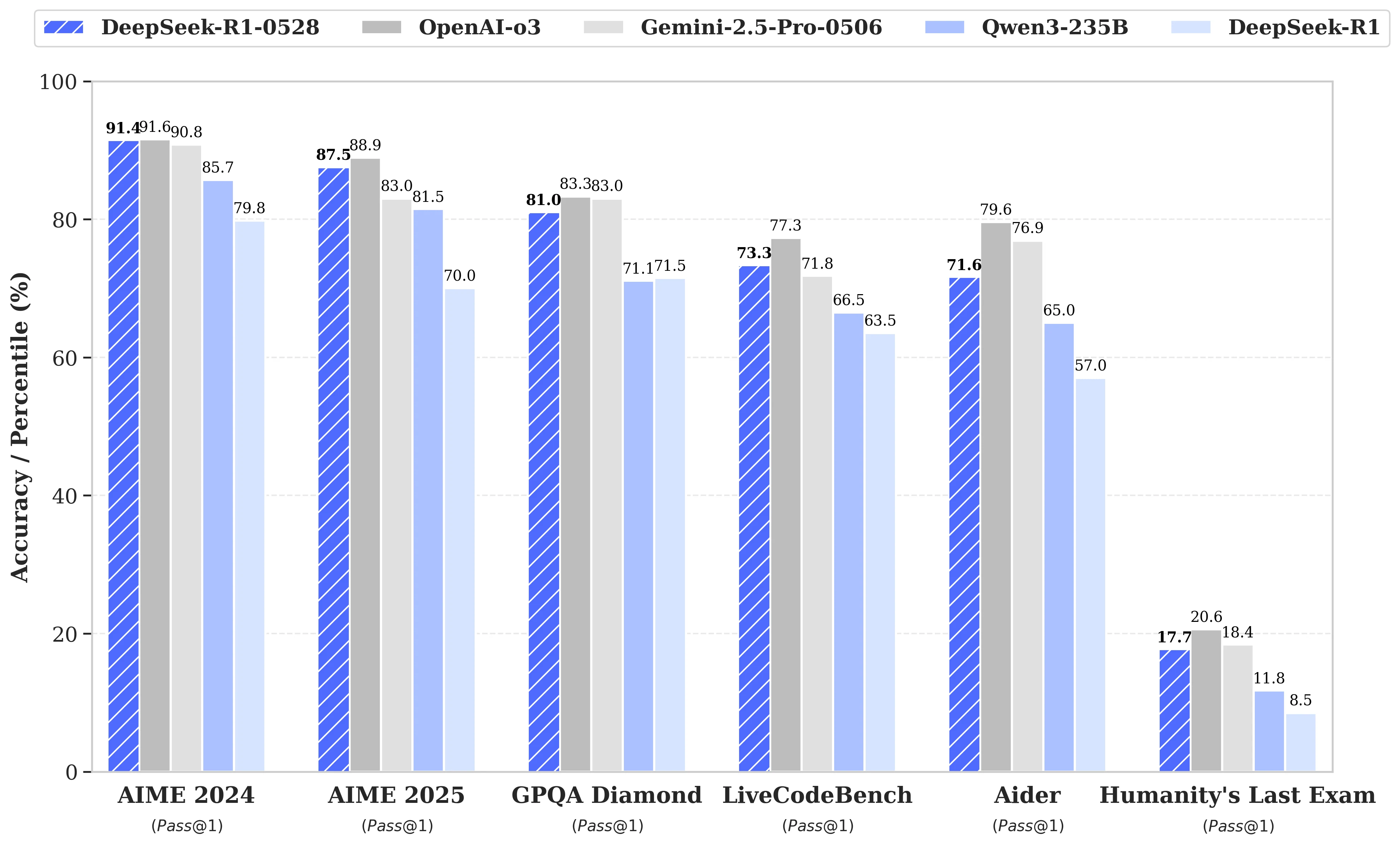
DeepSeek R1 0528, avec des performances proches des modèles de premier plan, réalise une réduction de prix allant jusqu’à 32 fois, ce qui en fait le choix le plus rentable du marché actuel.
Conclusion
Que vous construisiez des pipelines IA évolutifs, que vous effectuiez du fine‑tuning ou que vous déployiez des LLM en production, DeepSeek R1 0528 sur Novita AI offre la solution la plus rentable et la plus flexible, sans le fardeau de l’infrastructure.
| Cas d’utilisation | Meilleur choix | Pourquoi ? |
|---|---|---|
| Inférence par lot / Efficacité token | API Novita AI | Tarifs d’entrée/sortie les plus bas |
| Tâches longues / fine‑tuning | GPU Novita AI | Location GPU horaire la plus basse |
| Opérations privées, sécurisées et à grande échelle | Sur site (si budget le permet) | Contrôle total, complexité élevée |
| Haute précision et contrôle des coûts | DeepSeek R1 0528 | Bat Gemini/OpenAI en prix |
Essayez Novita AI dès maintenant
Foire aux questions
Quel est le coût du fine‑tuning de DeepSeek R1 0528 ?
Le coût estimé pour construire votre propre infrastructure est d’environ 5,89 M$. Cependant, l’utilisation des GPU cloud de Novita AI réduit considérablement les coûts initiaux, les GPU H100 commençant à 2,41 $/heure.
Comment puis‑je m’assurer que le modèle fine‑tuné répond à mes besoins ?
Préparez un ensemble de données propre et pertinent et utilisez des adaptateurs LoRA ou des méthodes PEFT pour fine‑tuner efficacement des couches spécifiques du modèle. Cela garantit des performances élevées sans surapprentissage.
Puis‑je déployer mon modèle fine‑tuné sur Novita AI ?
Oui, Novita AI prend en charge le déploiement de modèles fine‑tunés en tant que points d’accès dédiés, avec des options de mise à l’échelle automatique, de configurations multi‑LoRA et d’intégration API pour une utilisation transparente dans vos applications.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



