

منذ إصداره في مايو 2025، أصبح DeepSeek R1 0528 أحد أكثر النماذج مفتوحة المصدر التي يُتحدث عنها في عالم الذكاء الاصطناعي. مع 685 مليار بارامتر وأداء ينافس أفضل النماذج المملوكة، أثار إعجاب المطورين والباحثين على حد سواء بقدراته في الاستدلال، البرمجة، والرياضيات.
ولكن مع تزايد إقبال الناس على تجربته، يبرز سؤال رئيسي مرارًا:
ما التكلفة الفعلية لتشغيل هذا النموذج الضخم؟ تابع القراءة.
بطاقة نموذج Deepseek R1 0528
DeepSeek R1 0528، الذي صدر في 28 مايو 2025، هو نموذج ذكاء اصطناعي مفتوح المصدر قوي معروف باستدلاله المتقدم وأدائه الاستثنائي وكفاءته من حيث التكلفة.
الميزات الرئيسية
- الحجم: 685 مليار بارامتر (أكبر من OpenAI o3).
- مفتوح المصدر: مفتوح المصدر بالكامل بموجب ترخيص MIT؛ الأوزان متاحة على Hugging Face.
- البنية: يستخدم Mixture of Experts (MoE) لتفعيل البارامترات ديناميكيًا، مما يعزز الكفاءة.
- دعم اللغات: يؤدي أفضل ما لديه في اللغتين الإنجليزية والصينية.
- القدرة متعددة الوسائط: نص فقط (لا يدعم إدخال الصور/الصوت).
- تحسينات التدريب: استدلال واستدلال محسّن عبر أساليب ما بعد التدريب المُحسّنة.
أبرز الأداء
-
الاستدلال والبرمجة:
-
قوي في المهام الرياضية المتقدمة والمنطقية والبرمجية.
-
معايير الرياضيات:
- HMMT 2025: Pass@1 تحسّن من 41.7% → 79.4%.
- AIME 2025: Pass@1 ارتفع من 70.0% → 87.5%.
-
معايير البرمجة:
- Codeforces-Div1 Rating: 1530 → 1930.
- Aider-Polyglot Accuracy: 53.3% → 71.6%.
- LiveCodeBench Pass@1: 63.5% → 73.3%.
-
-
تصحيح الأخطاء وتوليد الكود:
- يصحح نفسه أثناء توليد الكود، مما يقلل الأخطاء.
-
الاستدلال التسلسلي (Chain-of-Thought):
- يوفر استدلالًا خطوة بخطوة لتحقيق الدقة والشفافية.
-
تكامل الأدوات:
- يدعم تكامل API مع إخراج JSON واستدعاء الدوال.
- نتائج Tau-Bench Pass@1: Airline (53.5%)، Retail (63.9%).
-
تقليل الهلوسات:
- موثوقية محسّنة لحالات الاستخدام الحرجة.
خيارات النشر
-
النموذج الكامل (685B):
- يتطلب 24 وحدة معالجة رسومية NVIDIA H100 (80GB لكل منها)، وذاكرة وصول عشوائي 512GB–1TB، وبنية تحتية قوية.
-
الإصدار المُقطّر (Qwen3 8B):
- يعمل على وحدة معالجة رسومية واحدة NVIDIA RTX 4090 (ذاكرة وصول عشوائي 24GB).
تكلفة API الخاصة بـ Deepseek R1 0528
متى تستخدم الوصول عبر API؟
استخدم API عندما:
- تريد عدم وجود إعداد أو صيانة للبنية التحتية
- تقوم بتشغيل استدلال دفعي أو وظائف ضبط دقيق
- تفضل أحمال العمل عند الطلب والقابلة للتوسع
- تقدر التسعير القائم على الرموز (الإدخال/الإخراج)
مقارنة تسعير API لـ DeepSeek R1 0528
| المزوّد | الإدخال ($/مليون) | الإخراج ($/مليون) |
|---|---|---|
| Novita AI | 0.70 | 2.50 |
| Fireworks AI | 3.00 | 8.00 |
| Nebius AI Studio | 0.80 | 2.40 |
| Parasail | 0.79 | 4 |
✅ Novita AI تقدم أقل تكلفة لرموز API. مثالية للمهام الحساسة للتكلفة والقابلة للتوسع مثل LLMOps، الاستدلال الجماعي، أو خطوط الأنابيب الدفعية غير التفاعلية.
دليل استخدام API
للبدء، ما عليك سوى استخدام مقتطف الكود أدناه:
- نقطة نهاية موحدة:
/v3/openaiتدعم تنسيق API Chat Completions من OpenAI. - تحكمات مرنة: اضبط درجة الحرارة، top-p، العقوبات، والمزيد للحصول على نتائج مخصصة.
- البث والتجميع: اختر وضع الاستجابة المفضل لديك.
جرب Fast API لـ Deepseek R1 0528 الآن
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_Ntg-O34ZOS-q5bNnkb3IcixmWnmxEQBxwKWMW3es3CD7KG4PEhFE1yRTRMGS3s8zZ52hrMdz14MmI4oalaDJTw==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يمكنك أيضًا توصيل DeepSeek R1 0528 API على منصات طرف ثالث
- Hugging Face: استخدم DeepSeek R1 0528 في Spaces أو pipelines أو مع مكتبة Transformers عبر نقاط نهاية Novita AI.
- أطر العوامل والتنسيق: قم بتوصيل Novita AI بسهولة مع منصات شريكة مثل Continue و AnythingLLM و LangChain و Dify و Langflow من خلال الموصلات الرسمية وأدلة التكامل خطوة بخطوة.
- API متوافق مع OpenAI: استمتع بالترحيل والتكامل الخالي من المتاعب مع أدوات مثل Cline و Cursor، المصممة لمعيار API من OpenAI.
تكلفة سحابة GPU لـ Deepseek R1 0528
متى تستخدم مثيلات GPU؟
استخدم سحابة GPU إذا:
- كنت بحاجة إلى تحكم كامل في تنفيذ النموذج
- تريد تشغيل ضبط دقيق مخصص
- تحتاج إلى جلسات أطول أو خوادم استدلال مستمرة
- تستخدم نماذج مُكمّمة أو أطر عمل متسارعة
مقارنة أسعار تأجير GPU (لكل ساعة)
| المزوّد | نوع GPU | السعر/الساعة |
|---|---|---|
| Novita AI | A100 SXM | 1.60$ |
| H100 SXM | 2.41$ | |
| H200 SXM | 2.99$ | |
| Lambda Cloud | H100 SXM | 3.29$ |
| RunPod | A100 SXM | 1.74$ |
| H100 SXM | 2.69$ | |
| H200 | 3.99$ | |
| Fireworks AI | H100 | 5.8$ |
| H200 | 6.99$ |
✅ بالنسبة لكفاءة التكلفة، Novita AI هي أفضل مزود عبر جميع أنواع GPU، بينما GPU A100 هو الخيار الأكثر ملاءمة للميزانية للمستخدمين.
دليل استخدام سحابة GPU
الخطوة 1: تسجيل حساب
قم بإنشاء حساب Novita AI الخاص بك عبر موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “Explore” في الشريط الجانبي الأيسر لعرض عروض GPU الخاصة بنا وبدء رحلة تطوير الذكاء الاصطناعي.

الخطوة 2: استكشاف القوالب وخوادم GPU
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم حدد تكوين GPU المفضل لديك—تتضمن الخيارات L40S القوي أو RTX 4090 أو A100 SXM4، ولكل منها مواصفات مختلفة لذاكرة VRAM وذاكرة الوصول العشوائي والتخزين.
الخطوة 3: تخصيص النشر الخاص بك
قم بتخصيص بيئتك عن طريق تحديد نظام التشغيل المفضل لديك وخيارات التكوين لضمان الأداء الأمثل لأحمال عمل الذكاء الاصطناعي الخاصة بك واحتياجات التطوير.
الخطوة 4: تشغيل مثيل
حدد “Launch Instance” لبدء النشر الخاص بك. ستكون بيئة GPU عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي أو العرض أو الحوسبة.
تكلفة النشر المحلي لـ Deepseek R1 0528
متى تنشر محليًا؟
لا تفكر في النشر المحلي إلا إذا:
- كنت بحاجة إلى تحكم كامل في البيانات
- لديك بالفعل بنية تحتية على مستوى مراكز البيانات
- تخطط لتشغيل استدلال مستمر واسع النطاق
- كنت مختبرًا بحثيًا أو مؤسسة بميزانيات بالملايين
التكلفة التقديرية لنشر DeepSeek R1 0528 الكامل محليًا
| المكون | المواصفات / الكمية | التكلفة (دولار أمريكي) |
|---|---|---|
| وحدات معالجة رسومية NVIDIA A100 | 116 × A100 80GB | 2,577,251.96$ |
| عقد الخوادم (A100 مزدوج) | 58 × 50,000$ | 2,900,000$ |
| شبكات InfiniBand | نسيج عالي السرعة | 100,000$ |
| تخزين NVMe SSD (100TB) | قراءة/كتابة 4–6GB/s | 20,000$ |
| تبريد سائل + رف | أنظمة على مستوى المؤسسات | 80,000$ + 10,000$ |
| البرمجيات والتراخيص | الأطر + نظام التشغيل | 10,000$ |
| البنية التحتية للطاقة | UPS + توصيل الطاقة | 50,000$ |
| الكهرباء (سنويًا) | 700W لكل GPU | 50,000$ |
| الصيانة والدعم | عقود سنوية | 100,000$ |
| إجمالي التقدير | 5.89 مليون دولار+ |
DeepSeek R1 0528 مقارنة بالنماذج الأخرى
DeepSeek R1 0528 مقابل النماذج الأخرى: السعر
| النموذج | تكلفة الإدخال ($/مليون) | تكلفة الإخراج ($/مليون) |
|---|---|---|
| DeepSeek R1 0528 | 0.70 | 2.50 |
| Gemini 2.5 Pro | 1.25–2.50 | 10–15 |
| OpenAI o3-pro | 20.00 | 80.00 |
DeepSeek R1‑0528 مقابل النماذج الأخرى: الأداء
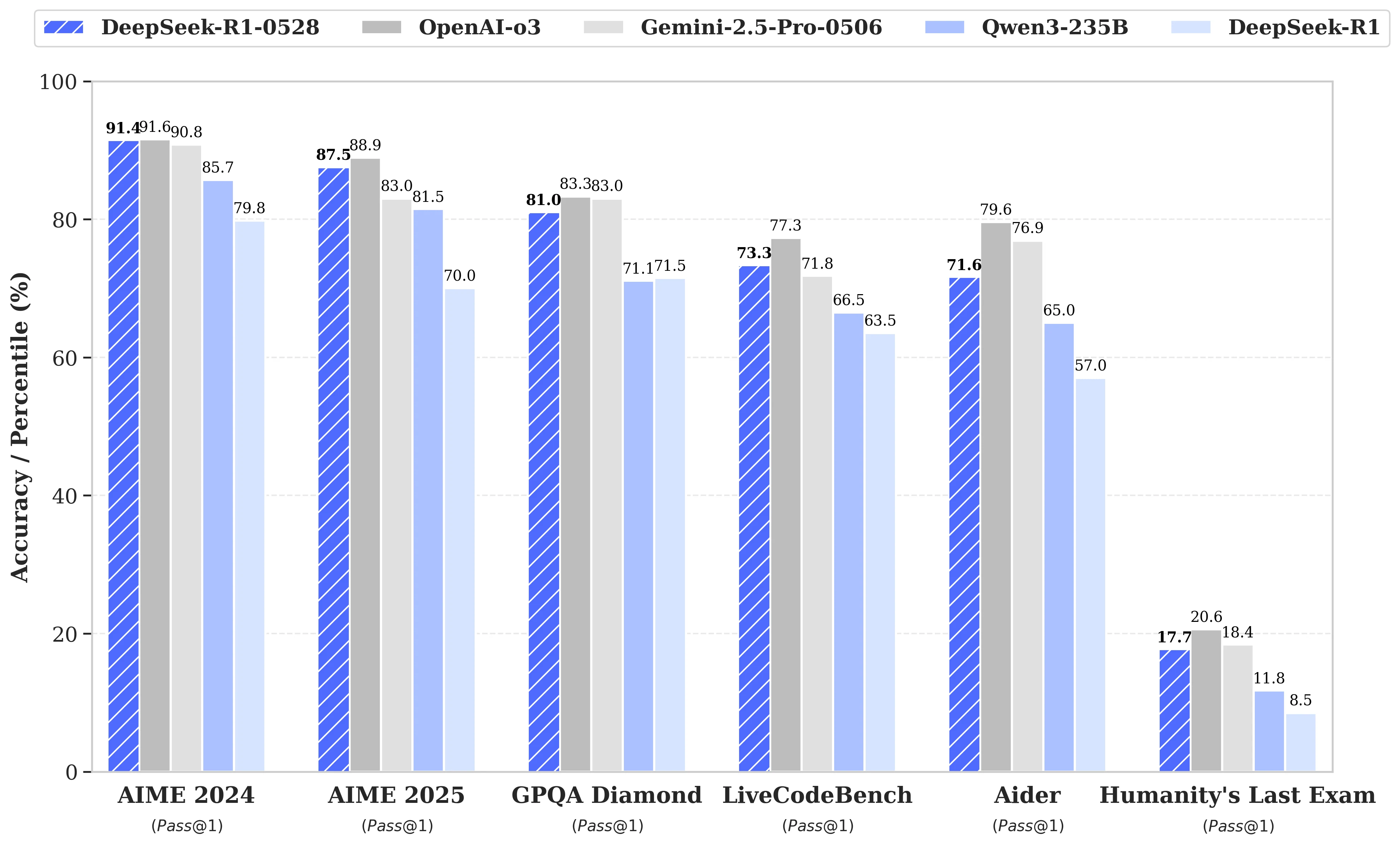
DeepSeek R1 0528، بأداء قريب من النماذج الرائدة، يحقق تخفيضًا في السعر يصل إلى 32 مرة، مما يجعله الخيار الأكثر فعالية من حيث التكلفة في السوق الحالي.
الخاتمة
سواء كنت تبني خطوط أنابيب ذكاء اصطناعي قابلة للتوسع، أو تضبط النماذج بدقة، أو تنشر LLMs في الإنتاج، فإن DeepSeek R1 0528 على Novita AI يقدم الحل الأكثر فعالية من حيث التكلفة والمرونة—بدون عبء البنية التحتية.
| حالة الاستخدام | الخيار الأفضل | لماذا؟ |
|---|---|---|
| الاستدلال الدفعي / كفاءة الرموز | Novita AI API | أرخص معدلات الإدخال/الإخراج |
| المهام طويلة الأمد / الضبط الدقيق | Novita AI GPU | أقل إيجار ساعي لـ GPU |
| عمليات خاصة وآمنة وواسعة النطاق | محلي (إذا كانت الميزانية تسمح) | تحكم كامل، تعقيد عالٍ |
| الحاجة إلى دقة عالية وتحكم في التكلفة | DeepSeek R1 0528 | يتفوق على Gemini/OpenAI في السعر |
الأسئلة الشائعة
ما هي تكلفة الضبط الدقيق لـ DeepSeek R1 0528؟
التكلفة التقديرية لبناء البنية التحتية الخاصة بك تبلغ حوالي 5.89 مليون دولار. ومع ذلك، فإن استخدام سحابة GPU من Novita AI يقلل بشكل كبير من التكاليف الأولية، حيث تبدأ أسعار H100 من 2.41 دولار/الساعة.
كيف يمكنني التأكد من أن النموذج المُضبّط بدقة يلبي احتياجاتي؟
قم بإعداد مجموعة بيانات نظيفة وذات صلة واستخدم محولات LoRA أو طرق PEFT لضبط طبقات معينة من النموذج بكفاءة. وهذا يضمن أداءً عاليًا دون الإفراط في التجهيز.
هل يمكنني نشر نموذجي المُضبّط بدقة على Novita AI؟
نعم، تدعم Novita AI نشر النماذج المُضبّطة بدقة كنقاط نهاية مخصصة، مع خيارات للتحجيم التلقائي وإعدادات LoRA المتعددة وتكامل API للاستخدام السلس في تطبيقاتك.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.



