

Desde seu lançamento em maio de 2025, o DeepSeek R1 0528 se tornou um dos modelos open-source mais comentados no mundo da IA. Com 685 bilhões de parâmetros e desempenho rivalizando com os principais modelos proprietários, ele impressionou desenvolvedores e pesquisadores com suas capacidades de raciocínio, codificação e matemática.
Mas, com mais pessoas correndo para testá-lo, uma pergunta chave continua surgindo:
Quanto custa realmente para executar esse modelo massivo? Continue lendo.
Ficha Técnica do DeepSeek R1 0528
O DeepSeek R1 0528, lançado em 28 de maio de 2025, é um modelo de IA open-source poderoso, conhecido por seu raciocínio avançado, desempenho excepcional e custo-benefício.
Principais Características
- Tamanho: 685 bilhões de parâmetros (maior que o OpenAI o3).
- Código Aberto: Totalmente open-source sob licença MIT; pesos disponíveis no Hugging Face.
- Arquitetura: Usa Mixture of Experts (MoE) para ativação dinâmica de parâmetros, aumentando a eficiência.
- Suporte a Idiomas: Melhor desempenho em inglês e chinês.
- Capacidade Multimodal: Apenas texto (sem suporte a entrada de imagem/áudio).
- Melhorias no Treinamento: Raciocínio e inferência aprimorados por meio de métodos de pós-treinamento otimizados.
Destaques de Desempenho
-
Raciocínio e Programação:
-
Forte em tarefas avançadas de matemática, lógica e programação.
-
Benchmarks de Matemática:
- HMMT 2025: Pass@1 melhorou de 41,7% → 79,4%.
- AIME 2025: Pass@1 aumentou de 70,0% → 87,5%.
-
Benchmarks de Codificação:
- Codeforces-Div1 Rating: 1530 → 1930.
- Aider-Polyglot Accuracy: 53,3% → 71,6%.
- LiveCodeBench Pass@1: 63,5% → 73,3%.
-
-
Depuração e Geração de Código:
- Autocorreção durante a geração de código, reduzindo erros.
-
Raciocínio em Cadeia de Pensamento (Chain-of-Thought):
- Fornece raciocínio passo a passo para precisão e transparência.
-
Integração de Ferramentas:
- Suporta integração com API via saída JSON e chamada de funções.
- Tau-Bench Pass@1: Airline (53,5%), Retail (63,9%).
-
Alucinações Reduzidas:
- Maior confiabilidade para casos de uso críticos.
Opções de Implantação
-
Modelo Completo (685B):
- Requer 24 GPUs NVIDIA H100 (80GB cada), 512GB–1TB de RAM e infraestrutura robusta.
-
Versão Destilada (Qwen3 8B):
- Executa em uma única GPU NVIDIA RTX 4090 (24GB VRAM).
Custo de API do DeepSeek R1 0528
Quando Usar Acesso por API?
Use a API quando:
- Você quer zero configuração ou manutenção de infraestrutura
- Você está executando inferência em lote ou trabalhos de fine-tuning
- Você prefere cargas de trabalho sob demanda e escaláveis
- Você valoriza precificação baseada em tokens (entrada/saída)
Comparação de Preços de API do DeepSeek R1 0528
| Provedor | Entrada ($/M) | Saída ($/M) |
|---|---|---|
| Novita AI | 0,70 | 2,50 |
| Fireworks AI | 3,00 | 8,00 |
| Nebius AI Studio | 0,80 | 2,40 |
| Parasail | 0,79 | 4 |
✅ Novita AI oferece o menor custo de token via API. Ideal para tarefas sensíveis a custo e escaláveis, como LLMOps, inferência em massa ou pipelines em lote não interativos.
Guia de Uso da API
Para começar, basta usar o trecho de código abaixo:
- Endpoint unificado:
/v3/openaisuporta o formato da API Chat Completions da OpenAI. - Controles flexíveis: Ajuste temperatura, top-p, penalidades e mais para resultados personalizados.
- Streaming e batching: Escolha o modo de resposta preferido.
Experimente a Fast API do DeepSeek R1 0528 Agora
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_Ntg-O34ZOS-q5bNnkb3IcixmWnmxEQBxwKWMW3es3CD7KG4PEhFE1yRTRMGS3s8zZ52hrMdz14MmI4oalaDJTw==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Você Também Pode Conectar a API do DeepSeek R1 0528 em Plataformas de Terceiros
- Hugging Face: Use o DeepSeek R1 0528 em Spaces, pipelines ou com a biblioteca Transformers por meio dos endpoints da Novita AI.
- Frameworks de Agentes e Orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM, LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
- API Compatível com OpenAI: Desfrute de migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão da API OpenAI.
Custo de GPU em Nuvem do DeepSeek R1 0528
Quando Usar Instâncias GPU?
Use GPU em nuvem se:
- Você precisa de controle total sobre a execução do modelo
- Você deseja executar fine-tuning personalizado
- Você precisa de sessões mais longas ou servidores de inferência persistentes
- Você está usando modelos quantizados ou frameworks acelerados
Comparação de Preços de Aluguel de GPU (por hora)
| Provedor | Tipo de GPU | Preço/hora |
|---|---|---|
| Novita AI | A100 SXM | $1,60 |
| H100 SXM | $2,41 | |
| H200 SXM | $2,99 | |
| Lambda Cloud | H100 SXM | $3,29 |
| RunPod | A100 SXM | $1,74 |
| H100 SXM | $2,69 | |
| H200 | $3,99 | |
| Fireworks AI | H100 | $5,8 |
| H200 | $6,99 |
✅ Para custo-benefício, a Novita AI é a melhor provedora em todos os tipos de GPU, enquanto a GPU A100 é a opção mais econômica para os usuários.
Guia de Uso da GPU em Nuvem
Passo 1: Crie uma conta
Crie sua conta Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e iniciar sua jornada de desenvolvimento em IA.

Passo 2: Explore Templates e Servidores GPU
Escolha entre templates como PyTorch, TensorFlow ou CUDA que atendam às necessidades do seu projeto. Em seguida, selecione a configuração de GPU preferida — opções incluem as poderosas L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
Passo 3: Personalize sua Implantação
Personalize seu ambiente selecionando o sistema operacional e as opções de configuração preferidos para garantir o desempenho ideal para suas cargas de trabalho específicas de IA e necessidades de desenvolvimento.
Passo 4: Inicie uma Instância
Selecione “Iniciar Instância” para começar sua implantação. Seu ambiente GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computacionais.
Custo de Implantação Local do DeepSeek R1 0528
Quando Implantar Localmente?
Considere a implantação no local apenas se:
- Você precisa de controle total dos dados
- Você já possui infraestrutura de nível de datacenter
- Você planeja executar inferência contínua em escala massiva
- Você é um laboratório de pesquisa ou empresa com orçamentos de milhões de dólares
Custo Estimado para Implantar o DeepSeek R1 0528 Completo Localmente
| Componente | Especificações / Qtd | Custo (USD) |
|---|---|---|
| GPUs NVIDIA A100 | 116 × A100 80GB | $2.577.251,96 |
| Nós de Servidor (Dual A100) | 58 × $50K | $2.900.000 |
| Rede InfiniBand | Fibra de alta velocidade | $100.000 |
| Armazenamento NVMe SSD (100TB) | 4–6GB/s Leitura/Gravação | $20.000 |
| Resfriamento Líquido + Rack | Sistemas de nível empresarial | $80.000 + $10.000 |
| Software e Licenças | Frameworks + SO | $10.000 |
| Infraestrutura de Energia | UPS + Distribuição de Energia | $50.000 |
| Eletricidade (Anual) | 700W por GPU | $50.000 |
| Manutenção e Suporte | Contratos anuais | $100.000 |
| Estimativa Total | $5,89M+ |
DeepSeek R1 0528 vs Outros Modelos
DeepSeek R1 0528 vs Outros Modelos: Preço
| Modelo | Custo de Entrada ($/M) | Custo de Saída ($/M) |
|---|---|---|
| DeepSeek R1 0528 | 0,70 | 2,50 |
| Gemini 2.5 Pro | 1,25–2,50 | 10–15 |
| OpenAI o3-pro | 20,00 | 80,00 |
DeepSeek R1 0528 vs Outros Modelos: Desempenho
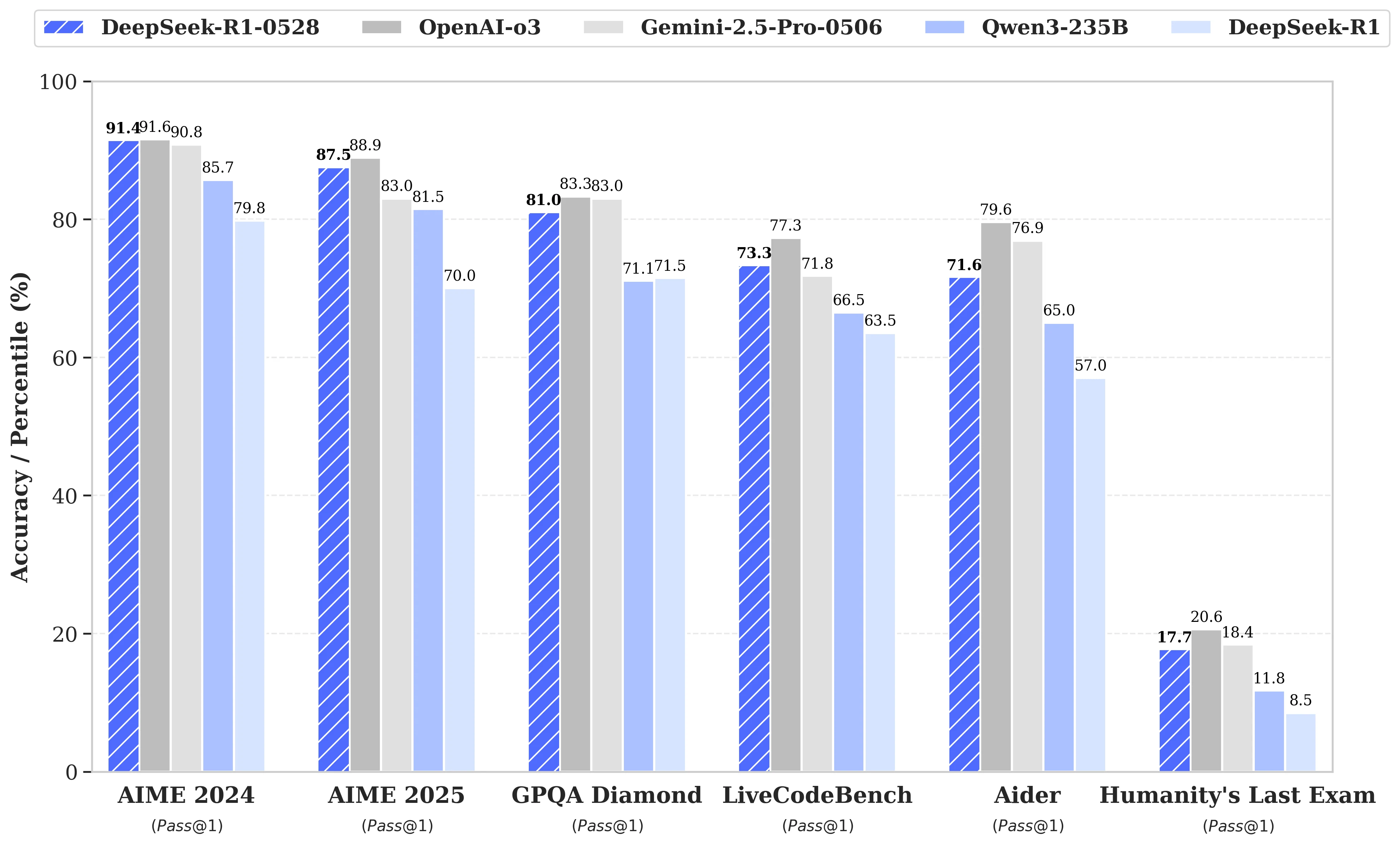
O DeepSeek R1 0528, com desempenho próximo aos modelos de ponta, alcança até 32 vezes de redução de preço, tornando-se a escolha mais econômica no mercado atual.
Conclusão
Seja construindo pipelines de IA escaláveis, fazendo fine-tuning de modelos ou implantando LLMs em produção, o DeepSeek R1 0528 na Novita AI oferece a solução mais econômica e flexível — sem o fardo da infraestrutura.
| Caso de Uso | Melhor Escolha | Por quê? |
|---|---|---|
| Inferência em Lote / Eficiência de Token | API Novita AI | Taxas de entrada/saída mais baratas |
| Tarefas de longa duração / fine-tuning | GPU Novita AI | Menor aluguel por hora de GPU |
| Operações privadas, seguras e em larga escala | On-Premise (se orçamento permitir) | Controle total, alta complexidade |
| Precisa de alta precisão e controle de custos | DeepSeek R1 0528 | Supera Gemini/OpenAI em preço |
Perguntas Frequentes
Qual é o custo do fine-tuning do DeepSeek R1 0528?
O custo estimado para construir sua própria infraestrutura é de cerca de $5,89M. No entanto, usar as GPUs em nuvem da Novita AI reduz significativamente os custos iniciais, com GPUs H100 a partir de $2,41/hora.
Como posso garantir que o modelo ajustado atenda às minhas necessidades?
Prepare um conjunto de dados limpo e relevante e use adaptadores LoRA ou métodos PEFT para ajustar eficientemente camadas específicas do modelo. Isso garante alto desempenho sem overfitting.
Posso implantar meu modelo ajustado na Novita AI?
Sim, a Novita AI suporta a implantação de modelos ajustados como endpoints dedicados, com opções de escalonamento automático, configurações multi-LoRA e integração via API para uso contínuo em suas aplicações.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a GPU em nuvem acessível e confiável para construir e escalar.



