

2025년 5월 출시 이후, DeepSeek R1 0528 은 AI 세계에서 가장 화제가 된 오픈소스 모델 중 하나가 되었습니다. **6850억 개의 파라미터 ** 와 최고 독점 모델에 필적하는 성능으로, 추론, 코딩, 수학 능력 면에서 개발자와 연구자 모두에게 깊은 인상을 남겼습니다.
하지만 더 많은 사람들이 이 모델을 사용해보려고 하면서, 핵심 질문이 계속 제기됩니다.
이 거대한 모델을 실행하는 데 실제로 얼마나 비용이 들까요? 계속 읽어보세요.
Deepseek R1 0528 모델 카드
DeepSeek R1 0528(2025년 5월 28일 출시)은 고급 추론, 뛰어난 성능 및 비용 효율성으로 알려진 강력한 오픈소스 AI 모델입니다.
주요 특징
- 크기: 6850억 개의 파라미터(OpenAI o3보다 큼).
- 오픈 소스: MIT 라이선스에 따라 완전히 오픈소스이며, 가중치는 Hugging Face에서 제공됩니다.
- 아키텍처: 동적 파라미터 활성화를 위해 MoE(Mixture of Experts)를 사용하여 효율성을 높입니다.
- 언어 지원: 영어와 중국어에서 최고의 성능을 발휘합니다.
- 멀티모달 기능: 텍스트 전용(이미지/오디오 입력 미지원).
- 훈련 개선 사항: 최적화된 포스트 트레이닝 방법을 통해 향상된 추론 및 추론 성능.
성능 하이라이트
-
추론 및 프로그래밍:
-
고급 수학, 논리 및 프로그래밍 작업에 강함.
-
수학 벤치마크:
- HMMT 2025: Pass@1 41.7% → 79.4%로 향상.
- AIME 2025: Pass@1 70.0% → 87.5%로 증가.
-
코딩 벤치마크:
- Codeforces-Div1 레이팅: 1530 → 1930.
- Aider-Polyglot 정확도: 53.3% → 71.6%.
- LiveCodeBench Pass@1: 63.5% → 73.3%.
-
-
디버깅 및 코드 생성:
- 코드 생성 중 자체 수정을 통해 오류 감소.
-
Chain-of-Thought 추론:
- 정확성과 투명성을 위한 단계별 추론 제공.
-
도구 통합:
- JSON 출력 및 함수 호출을 사용한 API 통합 지원.
- Tau-Bench Pass@1 점수: Airline (53.5%), Retail (63.9%).
-
환각 현상 감소:
- 중요 사용 사례에 대한 신뢰성 향상.
배포 옵션
-
전체 모델 (685B):
- 24개의 NVIDIA H100 GPU(각 80GB), 512GB–1TB RAM 및 강력한 인프라 필요.
-
경량화 버전 (Qwen3 8B):
- 단일 NVIDIA RTX 4090 GPU(24GB VRAM)에서 실행 가능.
Deepseek R1 0528의 API 비용
API 액세스를 사용해야 하는 경우
다음과 같은 경우 API를 사용하세요:
- 설정이나 인프라 유지 관리가 전혀 필요하지 않은 경우
- 배치 추론이나 파인튜닝 작업을 실행하는 경우
- 온디맨드, 확장 가능한 워크로드를 선호하는 경우
- 토큰 기반 가격(입력/출력)을 중시하는 경우
DeepSeek R1 0528 API 가격 비교
| 제공자 | 입력 ($/M) | 출력 ($/M) |
|---|---|---|
| Novita AI | 0.70 | 2.50 |
| Fireworks AI | 3.00 | 8.00 |
| Nebius AI Studio | 0.80 | 2.40 |
| Parasail | 0.79 | 4 |
✅ Novita AI 는 가장 낮은 API 토큰 비용을 제공합니다. LLMOps, 대량 추론 또는 대화형이 아닌 배치 파이프라인과 같은 비용에 민감하고 확장 가능한 작업에 이상적입니다.
API 사용 가이드
시작하려면 아래 코드 스니펫을 사용하세요:
- 통합 엔드포인트:
/v3/openai는 OpenAI의 Chat Completions API 형식을 지원합니다. - 유연한 제어: 온도, top-p, 패널티 등을 조정하여 맞춤형 결과를 얻을 수 있습니다.
- 스트리밍 및 배치: 원하는 응답 모드를 선택하세요.
지금 Deepseek R1 0528의 빠른 API 사용해보기
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_Ntg-O34ZOS-q5bNnkb3IcixmWnmxEQBxwKWMW3es3CD7KG4PEhFE1yRTRMGS3s8zZ52hrMdz14MmI4oalaDJTw==",
)
model = "deepseek/deepseek-r1-0528"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
DeepSeek R1 0528 API 를 타사 플랫폼에도 연결할 수 있습니다
- Hugging Face: Novita AI 엔드포인트를 통해 Spaces, 파이프라인 또는 Transformers 라이브러리에서 DeepSeek R1 0528을 사용하세요.
- 에이전트 및 오케스트레이션 프레임워크: 공식 커넥터와 단계별 통합 가이드를 통해 Novita AI를 Continue, AnythingLLM, LangChain, Dify 및 Langflow와 같은 파트너 플랫폼에 쉽게 연결하세요.
- OpenAI 호환 API: OpenAI API 표준에 맞게 설계된 Cline 및 Cursor와 같은 도구와의 손쉬운 마이그레이션 및 통합을 경험하세요.
Deepseek R1 0528의 GPU 클라우드 비용
GPU 인스턴스를 사용해야 하는 경우
다음과 같은 경우 클라우드 GPU를 사용하세요:
- 모델 실행에 대한 완전한 제어가 필요한 경우
- 맞춤형 파인튜닝을 실행하려는 경우
- 장기 세션이나 지속적인 추론 서버가 필요한 경우
- 양자화 모델이나 가속 프레임워크를 사용하는 경우
GPU 임대 가격 비교 (시간당)
| 제공자 | GPU 유형 | 시간당 가격 |
|---|---|---|
| Novita AI | A100 SXM | $1.60 |
| H100 SXM | $2.41 | |
| H200 SXM | $2.99 | |
| Lambda Cloud | H100 SXM | $3.29 |
| RunPod | A100 SXM | $1.74 |
| H100 SXM | $2.69 | |
| H200 | $3.99 | |
| Fireworks AI | H100 | $5.8 |
| H200 | $6.99 |
✅ 비용 효율성 측면에서 Novita AI 는 모든 GPU 유형에 걸쳐 최고의 제공업체이며, A100 GPU는 사용자에게 가장 예산 친화적인 옵션입니다.
Cloud GPU 사용 가이드
1단계: 계정 등록
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바에서 “Explore” 섹션으로 이동하여 GPU 상품을 확인하고 AI 개발 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow 또는 CUDA와 같은 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하세요. 강력한 L40S, RTX 4090 또는 A100 SXM4 등 다양한 VRAM, RAM 및 스토리지 사양을 제공합니다.
3단계: 배포 맞춤 설정
원하는 운영 체제와 구성 옵션을 선택하여 환경을 맞춤 설정하고 특정 AI 워크로드 및 개발 요구 사항에 최적의 성능을 보장하세요.
4단계: 인스턴스 시작
"Launch Instance"를 선택하여 배포를 시작하세요. 고성능 GPU 환경이 몇 분 내에 준비되어 머신 러닝, 렌더링 또는 컴퓨테이셔널 프로젝트를 즉시 시작할 수 있습니다.
Deepseek R1 0528의 로컬 배포 비용
로컬 배포 시기
다음과 같은 경우에만 온프레미스 배포 를 고려하세요:
- 완전한 데이터 제어 가 필요한 경우
- 이미 데이터센터급 인프라 를 보유한 경우 대규모 지속 추론 을 실행할 계획인 경우
- 연구소 또는 수백만 달러 예산 을 가진 기업인 경우
전체 DeepSeek R1 0528 로컬 배포 예상 비용
| 구성 요소 | 사양 / 수량 | 비용 (USD) |
|---|---|---|
| NVIDIA A100 GPU | 116 × A100 80GB | $2,577,251.96 |
| 서버 노드 (듀얼 A100) | 58 × $50K | $2,900,000 |
| InfiniBand 네트워킹 | 고속 패브릭 | $100,000 |
| NVMe SSD 스토리지 (100TB) | 4–6GB/s 읽기/쓰기 | $20,000 |
| 액체 냉각 + 랙 | 엔터프라이즈급 시스템 | $80,000 + $10,000 |
| 소프트웨어 및 라이선스 | 프레임워크 + OS | $10,000 |
| 전원 인프라 | UPS + 전원 공급 | $50,000 |
| 전기료 (연간) | GPU당 700W | $50,000 |
| 유지보수 및 지원 | 연간 계약 | $100,000 |
| **총 추정 비용 ** | $5.89M+ |
DeepSeek R1 0528 vs 다른 모델
DeepSeek R1 0528 vs 다른 모델: 가격
| 모델 | 입력 비용 ($/M) | 출력 비용 ($/M) |
|---|---|---|
| DeepSeek R1 0528 | 0.70 | 2.50 |
| Gemini 2.5 Pro | 1.25–2.50 | 10–15 |
| OpenAI o3-pro | 20.00 | 80.00 |
DeepSeek R1‑0528 vs 다른 모델: 성능
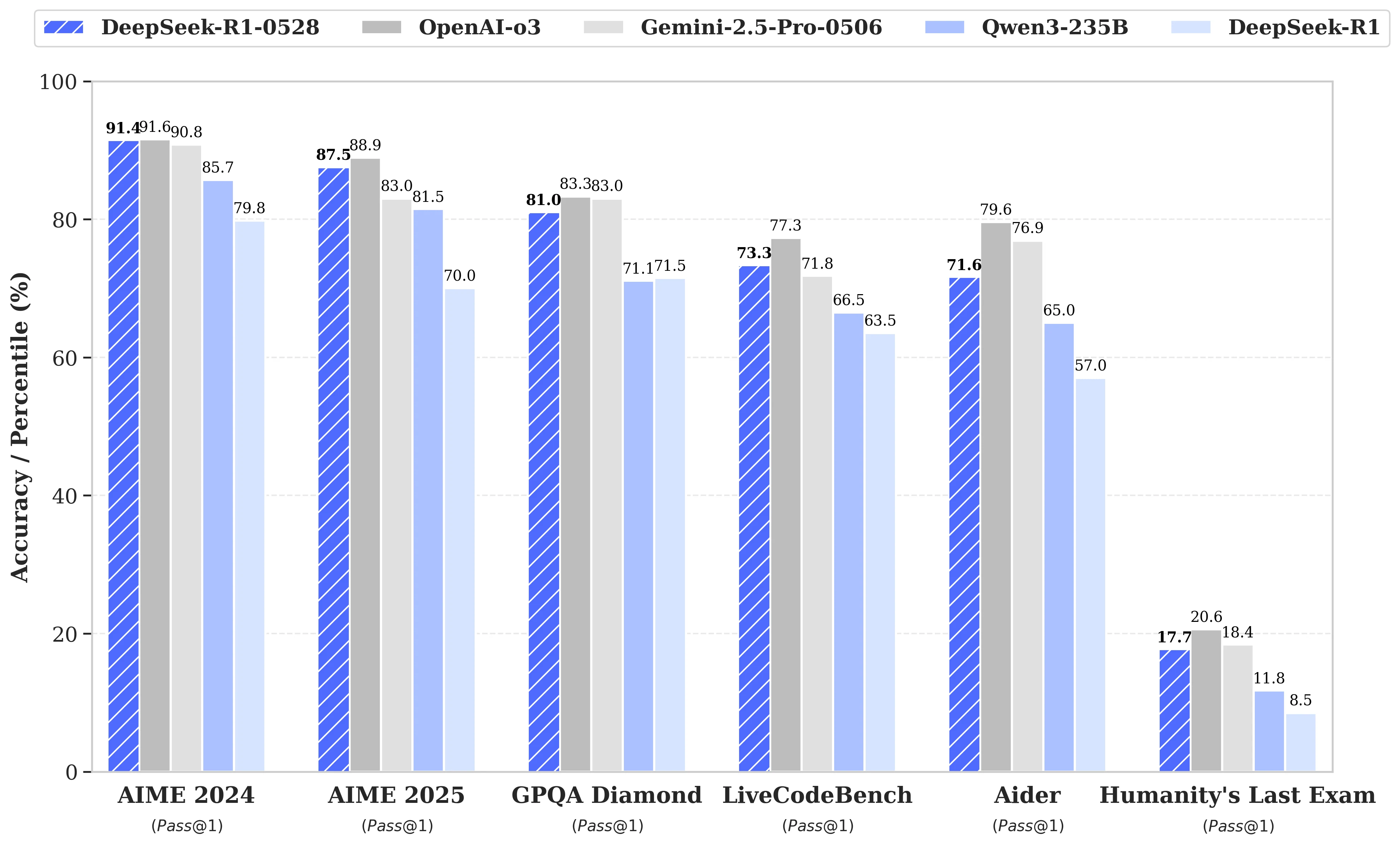
DeepSeek R1 0528은 최고 수준의 모델에 가까운 성능을 제공하면서 최대 32배의 가격 인하를 달성하여 현재 시장에서 가장 비용 효율적인 선택입니다.
결론
확장 가능한 AI 파이프라인을 구축하든, 모델을 파인튜닝하든, 프로덕션에서 LLM을 배포하든, Novita AI의 DeepSeek R1 0528은 인프라 부담 없이 가장 비용 효율적이고 유연한 솔루션을 제공합니다.
| 사용 사례 | 최적의 선택 | 이유 |
|---|---|---|
| 배치 추론 / 토큰 효율성 | Novita AI API | 가장 저렴한 입력/출력 요금 |
| 장기 실행 / 파인튜닝 작업 | Novita AI GPU | 가장 낮은 시간당 GPU 임대료 |
| 비공개, 안전한 대규모 운영 | 온프레미스 (예산 허용 시) | 완전한 제어, 높은 복잡성 |
| 높은 정확도 및 비용 제어 필요 | DeepSeek R1 0528 | 가격 면에서 Gemini/OpenAI를 능가 |
자주 묻는 질문
DeepSeek R1 0528을 파인튜닝하는 비용은 얼마인가요?
자체 인프라를 구축하는 데 드는 예상 비용은 약 $5.89M 입니다. 그러나 Novita AI의 클라우드 GPU를 사용하면 초기 비용이 크게 절감되며, H100 GPU는 시간당 $2.41 부터 시작합니다.
파인튜닝된 모델이 내 요구 사항을 충족하는지 어떻게 확인할 수 있나요?
**깨끗하고 관련성 높은 데이터셋 ** 을 준비하고 **LoRA 어댑터 ** 또는 PEFT 방법 을 사용하여 모델의 특정 레이어를 효율적으로 파인튜닝하세요. 이렇게 하면 과적합 없이 높은 성능을 보장할 수 있습니다.
파인튜닝된 모델을 Novita AI에 배포할 수 있나요?
네, Novita AI는 파인튜닝된 모델을 전용 엔드포인트 로 배포하는 것을 지원하며, 자동 확장, 멀티 LoRA 설정 및 애플리케이션에서 원활하게 사용할 수 있는 API 통합 옵션을 제공합니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 하면서, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.



