

Qwen3’s diversity is intentional: it lets developers pick the right trade-off between accuracy, cost, memory, and hardware, while maintaining a unified core ability—hybrid reasoning. This guide helps you understand the differences and find which Qwen3 model is most suitable for your specific needs—whether you’re building a chatbot, coding assistant, or AI research agent.
Why does the Qwen 3 series have so many models?
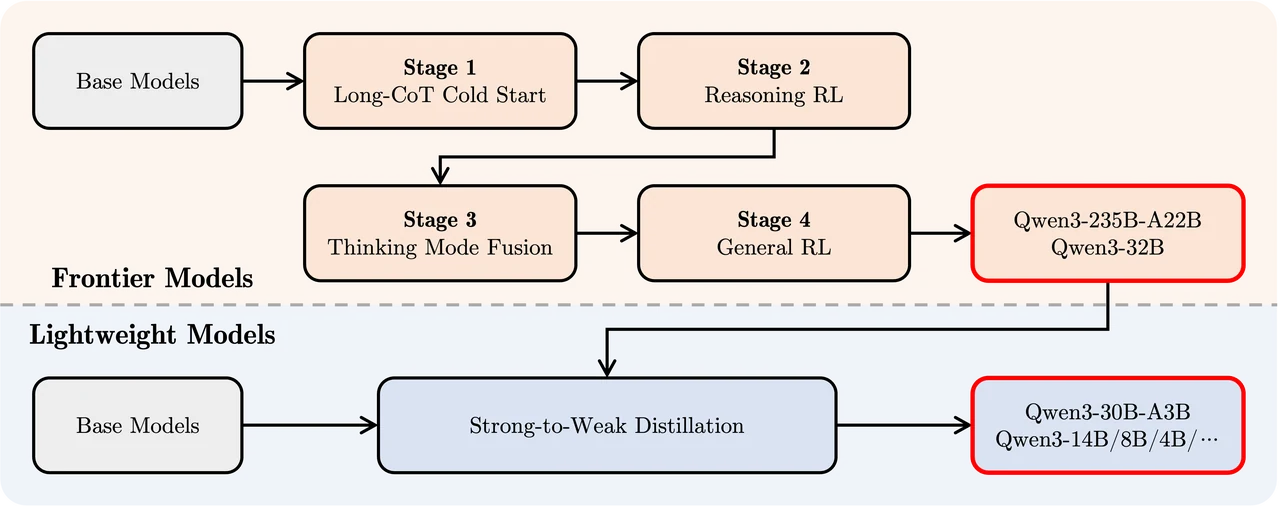
From Qwen
Qwen3 235B A22B/Qwen3 32B
- Base Models
This is the starting point of training, representing the original base models. - Stage 1: Long-CoT Cold Start
Long-chain reasoning (Long-CoT) is used as the cold start phase to help the model acquire initial capabilities for complex reasoning tasks. - Stage 2: Reasoning RL
Through Reasoning Reinforcement Learning (Reasoning RL), the model’s reasoning ability for tasks is further enhanced. - Stage 3: Thinking Mode Fusion
Different thinking modes (e.g., logical reasoning, intuitive judgment) are fused to improve the model’s generality and flexibility. - Stage 4: General RL
General Reinforcement Learning (General RL) is applied to enable the model to adapt to broader tasks.
Qwen3 30B A3B;Qwen3 14B/8B/4B/1.7B/0.6B
- Base Models
Similarly, this also starts with the base models. - Strong-to-Weak Distillation
Strong-to-Weak Distillation transfers knowledge from frontier models to lightweight models, ensuring that these models maintain efficiency while retaining strong reasoning capabilities.
Qwen 3 Models Basic Introduction
Qwen 3 MOE Models
| Feature | Qwen3 235B A22B | Qwen3 30B A3B |
|---|---|---|
| Model Size | 235B/22B (activated) | 30.5B/3.3B (activated) |
| Architecture | 94 layers, 64 attention heads for queries, and 4 for key-values | 48 layers, 32 attention heads for queries, and 4 for key-values |
| Ability | Supports function calling | Supports function calling |
| Context | 32,768 tokens | 32,768 tokens |
| Language Support | 119 languages and dialects | 119 languages and dialects |
| Multimodal Capability | Text to text | Text to text |
Qwen 3 Dense Models
| Model | Model Size | Layers | Attention Heads (Q / KV) | Context Length | Multilingual Support |
|---|---|---|---|---|---|
| Qwen3 32B | 32.8B | 64 | 64 / 8 | 32K / up to 128K | 119 languages & dialects |
| Qwen3 14B | 14.8B | 40 | 40 / 8 | 32K / up to 128K | 119 languages & dialects |
| Qwen3 8B | 8.2B | 36 | 32 / 8 | 32K / up to 128K | 119 languages & dialects |
| Qwen3 4B | 4.0B | 36 | 32 / 8 | 32K | 119 languages & dialects |
| Qwen3 1.7B | 1.7B | 28 | 16 / 8 | 32K | 119 languages & dialects |
| Qwen3 0.6B | 0.6B | 28 | 16 / 8 | 32K | 119 languages & dialects |
The point is all models in the Qwen3 series — including Qwen3 0.6B, 1.7B, 4B, 8B, 14B, 32B, as well as the MoE variants Qwen3 30B A3B and Qwen3 235B A22B — support the “Hybrid Reasoning Mode.
- Thinking Mode: Designed for complex problems that require in-depth analysis. The model reasons step-by-step and delivers carefully considered answers.
- Non-Thinking Mode: Suitable for simple tasks. The model provides fast, nearly instantaneous responses.
Additionally, the Qwen3 models introduce a “thinking budget” mechanism, allowing users to set a maximum token usage during reasoning. This helps control the depth of reasoning and manage computational resource consumption.
From Qwen
Qwen 3 Benchmark
Qwen 3 Reasoning Benchmark
| Test | Qwen3 235B | Qwen3 32B | Qwen3 30B | Qwen3 14B | Qwen3 8B | Qwen3 7B | Qwen3 4B | Qwen3 0.6B |
|---|---|---|---|---|---|---|---|---|
| MMLU-Pro | 83% | 80% | 78% | 77% | 74% | 57% | 35% | - |
| GPQA Diamond | 70% | 67% | 62% | 60% | 59% | 36% | 24% | - |
| Humanity’s Last Exam | 11.7% | 8.3% | 6.6% | 5.7% | 5.1% | 4.3% | 4.2% | - |
| LiveCodeBench | 62% | 55% | 52% | 51% | 47% | 41% | 31% | 12% |
| SciCode | 40% | 35% | 32% | 28% | 23% | 4% | 4% | 3% |
| MATH-500 | 96% | 96% | 96% | 93% | 93% | 90% | 89% | 75% |
| AIME 2024 | 84% | 81% | 76% | 75% | 75% | 66% | 51% | 10% |
Qwen 3 No Reasoning Benchmark
| Test | Qwen3 235B | Qwen3 32B | Qwen3 30B | Qwen3 14B | Qwen3 8B | Qwen3 7B | Qwen3 4B | Qwen3 0.6B |
|---|---|---|---|---|---|---|---|---|
| MMLU-Pro | 76% | 73% | 71% | 68% | 64% | 41% | 23% | - |
| GPQA Diamond | 61% | 54% | 52% | 47% | 45% | 40% | 28% | 23% |
| Humanity’s Last Exam | 5.2% | 5.2% | 4.7% | 4.6% | 4.3% | 3.7% | 2.8% | - |
| LiveCodeBench | 34% | 32% | 29% | 28% | 23% | 20% | 13% | 7% |
| SciCode | 30% | 28% | 27% | 26% | 17% | 17% | 7% | 4% |
| MATH-500 | 90% | 87% | 87% | 86% | 84% | 83% | 72% | 52% |
| AIME 2024 | 33% | 30% | 28% | 26% | 24% | 21% | 10% | 2% |
Humanity’s Last Exam tests extreme reasoning and knowledge. All models perform poorly.
- For high-stakes tasks requiring top-tier performance (e.g., scientific research, advanced coding), Qwen3 235B is the best choice.
- For cost-effective solutions where computational resources are limited, Qwen3 30B or Qwen3 32B offer a good balance of performance and efficiency.
- Smaller models like Qwen3 0.6B are more suited for lightweight applications but may struggle with complex tasks.
Qwen 3 Hardware Requirements
| Model Name | Memory Required (GB) |
| Qwen3 0.6B | 3.01GB |
| Qwen3 1.7B | 5.75GB |
| Qwen3 4B | 10.99GB |
| Qwen3 8B | 19.82GB |
| Qwen3 14B | 33.48GB |
| Qwen3 30B A3B | 74.21GB |
| Qwen3 32B | 73.5GB |
| Qwen3 235B A22B | 553.96GB |
0.6B–4B: Local apps, chatbots, lightweight edge use.
8B–14B: Strong generalist models for mid-size inference servers.
32B: High-performance use cases needing creative output and deeper reasoning.
235B: Research-grade or enterprise-scale deployment, not cost-efficient for most users.
Which Qwen 3 Meets Your Needs?
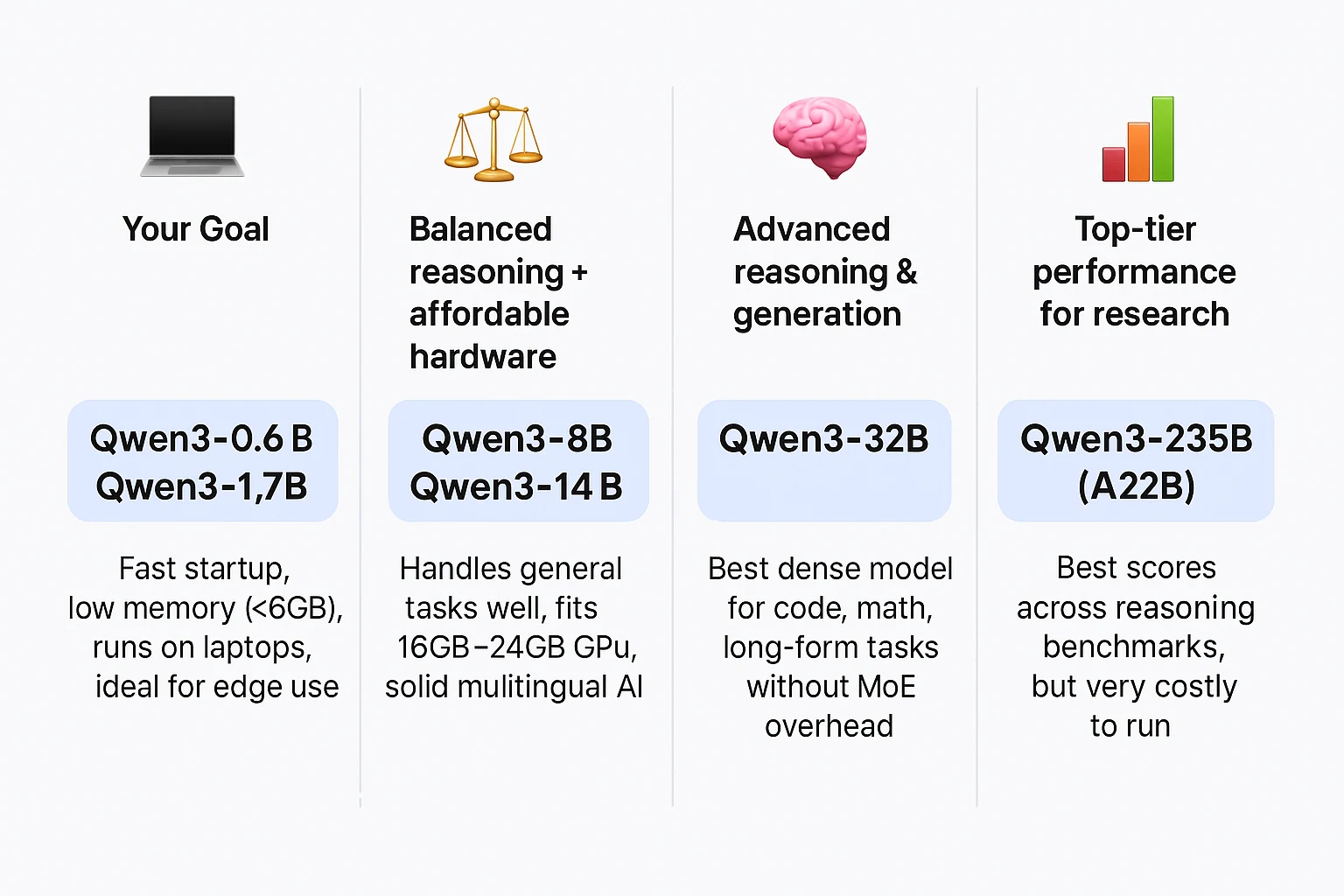
| Your Goal | Recommended Model(s) | Why |
|---|---|---|
| Local lightweight tasks / chatbots | Qwen3-0.6B / Qwen3-1.7B | Fast startup, low memory (<6GB), runs on laptops, ideal for edge use |
| Balanced reasoning + affordable hardware | Qwen3-8B / Qwen3-14B | Handles general tasks well, fits 16GB–24GB GPUs, solid multilingual AI |
| Advanced reasoning & generation | Qwen3-32B | Best dense model for code, math, long-form tasks without MoE overhead |
| Top-tier performance for research | Qwen3-235B (A22B) | Best scores across reasoning benchmarks, but very costly to run |
| Efficient but capable MoE option | Qwen3-30B (A3B) | Strong output using ~3B active params; better scaling per GPU memory |
How to Access Qwen 3 Models in A Cost-Effectively Way?
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
In addition to Qwen 3 Reranker 8B and Embedding 8B , Novita AI also provides free Qwen 3 (0.6B, 1.7B, 4B) to support development of open source community!
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model and Start a Free Trail
Browse through the available options and select the model that suits your needs.
Step 3: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 4: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_nkvtuVXXxS-LlR7txjZ3Rox8GhLMuv1R8IrIySNwTPN7xHJ0SVErFx3kNwJgkUEpcSM4F8c6zmcvyfuc1h59gw==",
)
model = "qwen/qwen3-32b-fp8"
stream = True # or False
max_tokens = 2048
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Whether you’re building a chatbot on a laptop or deploying a large-scale scientific agent, Qwen3 has a model tailored to your resources and goals. Smaller models (0.6B–4B) are lightweight and fast; mid-sized models (8B–14B) balance power and efficiency; and larger models (32B, 235B) lead in reasoning benchmarks. For developers seeking cost-effective access, Novita AI offers seamless deployment of Qwen3 models through API—with some available entirely for free.
Frequently Asked Questions
Which Qwen3 model is best for local applications?
Qwen3-0.6B or Qwen3-1.7B. These models run on basic PCs or Apple Silicon and are ideal for lightweight tasks and chatbots.
What should I choose for strong reasoning without high GPU cost?
Qwen3-8B or Qwen3-14B. They provide great reasoning ability and fit on GPUs with 16–24GB VRAM.
When should I use Qwen3-32B?
Use Qwen3-32B when you need advanced logic, coding, and long-form generation—without relying on a MoE structure..
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



